从YOLOv5源码yolo.py详细介绍Yolov5的网络结构
深度学习笔记:从YOLOv5源码yolo.py详细介绍Yolov5的网络结构
- 前言
- 一、网络结构:yolov5s.yaml
- 二、class Model(nn.Module)主要代码解析
-
- 1.__init__函数
- 2.parse_model函数
- 三、class Detect(nn.Module)代码解析
- 四、具体模块源码解析
-
- 1 BackBone
-
- 1.1 Focus
- 1.2 Conv
- 1.3 C3/C3_False
- 2 Neck
-
- 2.1 SPP
- 2.2 PANet
- 五、总结
前言
源码的版本是tagV5.0。
一、网络结构:yolov5s.yaml
YOLOv5有s,m,l,x版本,分别代表不同的网络大小,在yaml中,分别有depth_multiple和width_multiple来控制C3模块中BottleNeck模块(会在后续介yolov5中的bottleneck)的个数(>=1)和模块的输出通道数。
# parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, C3, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
YOLOv5s(depth_multiple: 0.33 width_multiple: 0.50)的网络结构如下:
from n params module arguments
0 -1 1 3520 Focus [3, 32, 3]
1 -1 1 18560 Conv [32, 64, 3, 2]
2 -1 1 18816 C3 [64, 64, 1]
3 -1 1 73984 Conv [64, 128, 3, 2]
4 -1 1 156928 C3 [128, 128, 3]
5 -1 1 295424 Conv [128, 256, 3, 2]
6 -1 1 625152 C3 [256, 256, 3]
7 -1 1 1180672 Conv [256, 512, 3, 2]
8 -1 1 656896 SPP [512, 512, [5, 9, 13]]
9 -1 1 1182720 C3 [512, 512, 1, False]
10 -1 1 131584 Conv [512, 256, 1, 1]
11 -1 1 0 Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 Concat [1]
13 -1 1 361984 C3 [512, 256, 1, False]
14 -1 1 33024 Conv [256, 128, 1, 1]
15 -1 1 0 Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 Concat [1]
17 -1 1 90880 C3 [256, 128, 1, False]
18 -1 1 147712 Conv [128, 128, 3, 2]
19 [-1, 14] 1 0 Concat [1]
20 -1 1 296448 C3 [256, 256, 1, False]
21 -1 1 590336 Conv [256, 256, 3, 2]
22 [-1, 10] 1 0 Concat [1]
23 -1 1 1182720 C3 [512, 512, 1, False]
24 [17, 20, 23] 1 67425 Detect [80, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
对应的结构图如下,每个模块的详细介绍会放在最后:
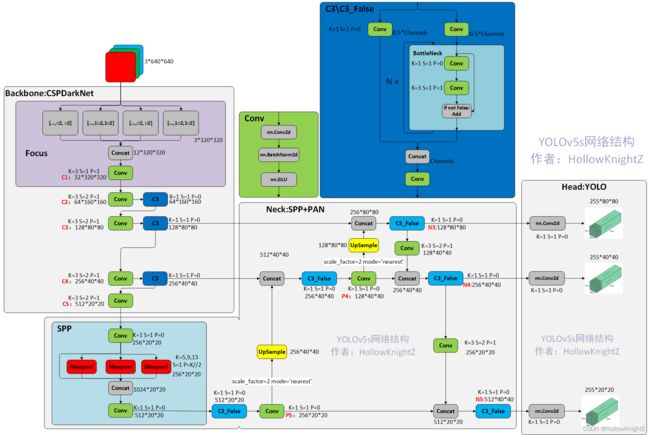
虽然yaml里把SPP包括在Backbone里,但是按yolov4论文中所写的,SPP属于Neck的附加模块。

二、class Model(nn.Module)主要代码解析
1.__init__函数
__init__函数主要功能为从yaml中初始化model中各种变量包括网络模型model、通道ch,分类数nc,锚框anchor和三层输出缩放倍数stride等。
def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, anchors=None): # model, input channels, number of classes
super(Model, self).__init__()
'''
首先去加载yaml文件
'''
if isinstance(cfg, dict):
self.yaml = cfg # model dict
else: # is *.yaml
import yaml # for torch hub
self.yaml_file = Path(cfg).name
with open(cfg) as f:
self.yaml = yaml.load(f, Loader=yaml.SafeLoader) # model dict
'''
接着判断yaml中是否有设置输入图像的通道ch,如果没有就默认为3。
接着判断分类总数nc和anchor与yaml中是否一致,如果不一致,则使用init函数参数中指定的nc和anchor。
'''
# Define model
ch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channels
if nc and nc != self.yaml['nc']:
logger.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")
self.yaml['nc'] = nc # override yaml value
if anchors:
logger.info(f'Overriding model.yaml anchors with anchors={anchors}')
self.yaml['anchors'] = round(anchors) # override yaml value
'''
读取yaml中的网络结构并实例化
'''
self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelist
self.names = [str(i) for i in range(self.yaml['nc'])] # default names
# print([x.shape for x in self.forward(torch.zeros(1, ch, 64, 64))])
'''
最后来计算图像从输入到输出的缩放倍数和anchor在head上的大小
'''
# Build strides, anchors
'''
1,获取结构最后一层Detect层
'''
m = self.model[-1] # Detect()
if isinstance(m, Detect):
'''
2.定义一个256*256大小的输入
'''
s = 256 # 2x min stride
'''
3.将[1, ch, 256, 256]大小的tensor进行一次向前传播,得到3层的输出,
用输入大小256分别除以输出大小得到每一层的下采样倍数stride,
因为P3进行了3次下采样,所以P3.stride=2^3=8,同理P4.stride=16,P5.stride=32。
'''
m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forward
'''
4.分别用最初的anchor大小除以stride将anchor线性缩放到对应层上
'''
m.anchors /= m.stride.view(-1, 1, 1)
check_anchor_order(m)
self.stride = m.stride
self._initialize_biases() # only run once
# print('Strides: %s' % m.stride.tolist())
# Init weights, biases
initialize_weights(self)
self.info()
logger.info('')
2.parse_model函数
parse_model函数的功能为把yaml文件中的网络结构实例化成对应的模型。
def parse_model(d, ch): # model_dict, input_channels(3)
'''
打印表头(即最开始展示的网络结构表的表头)
'''
logger.info('\n%3s%18s%3s%10s %-40s%-30s' % ('', 'from', 'n', 'params', 'module', 'arguments'))
'''
获取anchors,nc,depth_multiple,width_multiple,这些参数在介绍yaml时已经介绍过
'''
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
'''
计算每层anchor的个数na,anchor.shape=[3,6]
'''
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
'''
yolo输出格式中的通道数
'''
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
'''
将对应的字符串通过eval函数执行成模块,如‘Focus’,'Conv'等
'''
m = eval(m) if isinstance(m, str) else m # eval strings
for j, a in enumerate(args):
try:
'''
将对应的字符串通过eval函数执行放入args中,如‘None’,‘nc’,‘anchors’等。
'''
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except:
pass
'''
将C3中的BottleNeck数量乘以模型缩放倍数,
如模型第一个C3的Number属性为3,乘上yolov5s.yaml中的depth_multiple(0.33),通过下行代码计算得到为1
'''
n = max(round(n * gd), 1) if n > 1 else n # depth gain
'''
将m实例化成同名模块,目前只用到Conv,SPP,Focus,C3,nn.Upsample
'''
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP,
C3, C3TR]:
'''
输入通道为f指向的层的输出通道,输出通道为yaml的args中的第一个变量
'''
c1, c2 = ch[f], args[0]
'''
如果输出通道不等于255即Detect层的输出通道,
则将通道数乘上width_multiple,并调整为8的倍数。
'''
if c2 != no: # if not output
'''
make_divisible代码如下:
# 使得X能够被divisor整除
def make_divisible(x, divisor):
return math.ceil(x / divisor) * divisor
'''
c2 = make_divisible(c2 * gw, 8)
'''
args初始化为[输入通道,输出通道,其他参数1,其他参数2,...]的格式
'''
args = [c1, c2, *args[1:]]
'''
如果模块时C3,则args为[输入通道,输出通道,模块个数,...]
n在insert之前代表的是BottleNeck模块个数,
n=1之后表示的是C3模块的个数,之后打印列表时显示C3个数为1
'''
if m in [BottleneckCSP, C3, C3TR]:
args.insert(2, n) # number of repeats
n = 1
elif m is nn.BatchNorm2d:
args = [ch[f]]
'''
如果是模块是concat,则输出通道是f中索引指向层数的输出通道之和
'''
elif m is Concat:
c2 = sum([ch[x] for x in f])
'''
如果模块是Detect,则把f索引指向层数的输出通道以列表的形式加入到模块参数列表中,
f分别指向17, 20, 23层,查看后输出通道为128,256,512
Detect在yaml中的args=[nc,anchors],append之后为[nc,anchors,[128,256,512]]
'''
elif m is Detect:
args.append([ch[x] for x in f])
if isinstance(args[1], int): # number of anchors
'''
如果args[1]不是list而是int类型,则以该int数生成anchors的list
'''
args[1] = [list(range(args[1] * 2))] * len(f)
elif m is Contract:
c2 = ch[f] * args[0] ** 2
elif m is Expand:
c2 = ch[f] // args[0] ** 2
else:
c2 = ch[f]
'''
如果n>1则重复加入n个该模块,yolov5的5.0版本此处n都为1,C3的n之前为3,但也在模块实例化中被赋值为1
'''
m_ = nn.Sequential(*[m(*args) for _ in range(n)]) if n > 1 else m(*args) # module
'''
打印时显示的模块名称
'''
t = str(m)[8:-2].replace('__main__.', '') # module type
'''
打印时显示的模块参数
'''
np = sum([x.numel() for x in m_.parameters()]) # number params
m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
logger.info('%3s%18s%3s%10.0f %-40s%-30s' % (i, f, n, np, t, args)) # print
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
'''
将该层添加到网络中
'''
layers.append(m_)
if i == 0:
ch = []
'''
将第i层的输出通道加入到ch列表中
'''
ch.append(c2)
return nn.Sequential(*layers), sorted(save)
至此,模块实例化的工作就完成了。下面详细介绍一下各个模块。
三、class Detect(nn.Module)代码解析
class Detect(nn.Module):
stride = None # strides computed during build
export = False # onnx export
def __init__(self, nc=80, anchors=(), ch=()): # detection layer
super(Detect, self).__init__()
'''
nc:分类数量
no:每个anchor的输出数,为(x,y,w,h,conf) + nc = 5 + nc 的总数
nl:预测层数,此次为3
na:anchors的数量,此次为3
grid:格子坐标系,左上角为(1,1),右下角为(input.w/stride,input.h/stride)
'''
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.grid = [torch.zeros(1)] * self.nl # init grid
'''
anchors.shape=[3,6],a.shape=[3,3,2]
'''
a = torch.tensor(anchors).float().view(self.nl, -1, 2)
'''
将a写入缓存中,并命名为anchors
等价于self.anchors = a
'''
self.register_buffer('anchors', a) # shape(nl,na,2)
'''
anchor_grid.shape = [3,1,3,1,1,2]
此处是为了计算loss时使用
'''
self.register_buffer('anchor_grid', a.clone().view(self.nl, 1, -1, 1, 1, 2)) # shape(nl,1,na,1,1,2)
'''
将输出通过卷积到 self.no * self.na 的通道,达到全连接的作用
'''
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
def forward(self, x):
# x = x.copy() # for profiling
z = [] # inference output
self.training |= self.export
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
'''
x[i].shape = [bs,3,20,20,85]
'''
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
'''
向前传播时需要将相对坐标转换到grid绝对坐标系中
'''
if not self.training: # inference
'''
生成坐标系
grid[i].shape = [1,1,ny,nx,2]
[[[[1,1],[1,2],...[1,nx]],
[[2,1],[2,2],...[2,nx]],
...,
[[ny,1],[ny,2],...[ny,nx]]]]
'''
if self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
'''
按损失函数的回归方式来转换坐标
'''
y = x[i].sigmoid()
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
z.append(y.view(bs, -1, self.no))
return x if self.training else (torch.cat(z, 1), x)
@staticmethod
def _make_grid(nx=20, ny=20):
yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()
下面具体说说最后这段代码:
y = x[i].sigmoid()
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
可以先翻看yolov3论文中对于anchor box回归的介绍:
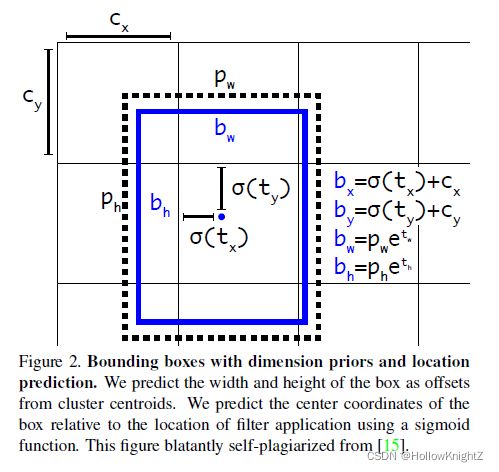
这里的bx∈[Cx,Cx+1],by∈[Cy,Cy+1],bw∈(0,+∞),bh∈(0,+∞)
而yolov5里这段公式变成了:

使得bx∈[Cx-0.5,Cx+1.5],by∈[Cy-0.5,Cy+1.5],bw∈[0,4pw],bh∈[0,4ph]
这是因为在对anchor box回归时,用了三个grid的范围来预测,而并非1个,可以从loss.py的代码看出:
g = 0.5 # bias
off = torch.tensor([[0, 0],
[1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
# [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
], device=targets.device).float() * g # offsets
# Offsets
gxy = t[:, 2:4] # grid xy
gxi = gain[[2, 3]] - gxy # inverse
j, k = ((gxy % 1. < g) & (gxy > 1.)).T
l, m = ((gxi % 1. < g) & (gxi > 1.)).T
j = torch.stack((torch.ones_like(j), j, k, l, m))
t = t.repeat((5, 1, 1))[j]
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
loss.py的代码的讲解可阅读博客深度学习笔记:从YOLOv5源码loss.py详细介绍Yolov5的损失函数。这段代码的大致意思是,当标签在grid左侧半部分时,会将标签往左偏移0.5个grid,在上、下、右侧同理。具体如图所示:

grid B中的标签在右上半部分,所以标签偏移0.5个gird到E中,A,B,C,D同理,即每个网格除了回归中心点在该网格的目标,还会回归中心点在该网格附近周围网格的目标。以E左上角为坐标(Cx,Cy),所以bx∈[Cx-0.5,Cx+1.5],by∈[Cy-0.5,Cy+1.5],而bw∈[0,4pw],bh∈[0,4ph]应该是为了限制anchor的大小。
这一策略可以提高召回率(因为每个grid的预测范围变大了),但会略微降低精确度,总体提升mAP。
四、具体模块源码解析
1 BackBone
1.1 Focus
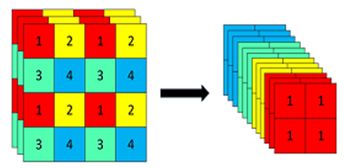
以下是Focus的源码:
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
# self.contract = Contract(gain=2)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
# return self.conv(self.contract(x))
代码可画成如下结构:

从卷积的过程上来看如下所示:
1.2 Conv
以下是Conv及autopad的代码
def autopad(k, p=None): # kernel, padding
# Pad to 'same'
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
autopad根据卷积核大小自动计算Padding,因为c2 = (c1+2k-p)/2 + 1,所以使得C2=C1/2,代替池化层达到下采样的目的。
画成结构图如下:
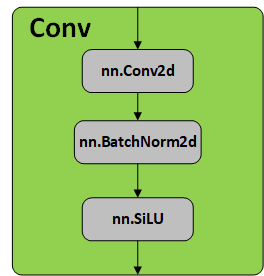
其中SiLU (x)=x∗ sigmoid(x)。
1.3 C3/C3_False
C3/C3_False在源码中为C3,代码如下:
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super(Bottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(C3, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
C3/C3_False的区别在于Botttleneck是否使用shortcut,其结构如下图:
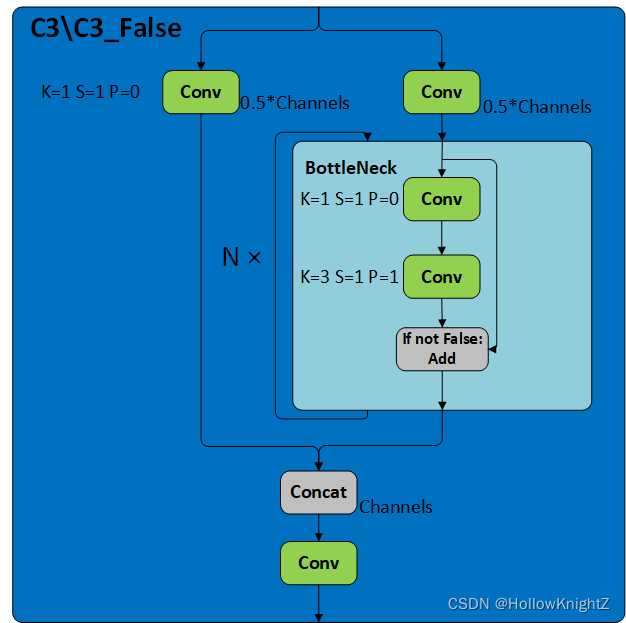
C3采用的是CSP结构,CSP的思想是将通道拆分成两个部分,分别走上图左右两条路,而源码中是将全部的输入特征利用两路1x1进行transition,比直接划分通道能够进一步提高特征的重用性,并且在输入到resiudal block之前也确实通道减半,减少了计算量。
2 Neck
2.1 SPP
SPP源码如下:
class SPP(nn.Module):
# Spatial Pyramid Pooling (SPP) layer https://arxiv.org/abs/1406.4729
def __init__(self, c1, c2, k=(5, 9, 13)):
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
画成网络结构图如下:
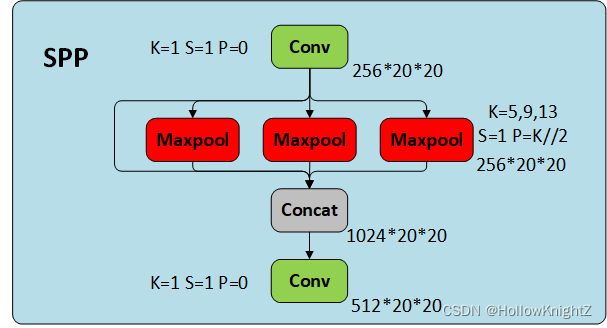
SPPNet可以增加多尺度的特征融合。
2.2 PANet
PANet整体结构如下:
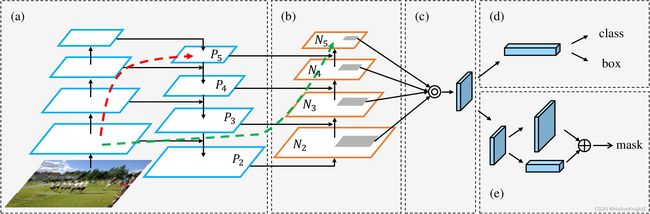
具体介绍可以看文章【CV中的特征金字塔】四,CVPR 2018 PANet。YOLOv5算法将融合的方法由add变为concat。
总之,PANet是一种结构思想,源码中通过concat某两个层来实现,在v5可以看完整结构图。
五、总结
YOLOv5的网络结构部分就学习到这里,损失函数部分在后面的文章介绍。