推荐系统6--Wide&Deep与Deep&Cross模型(综合原始特征及交叉特征)
一,前言
记忆能力:模型直接学习并利用历史数据中物品和特征的“共现频率”的能力。
泛化能力:模型传递特征的相关性,以及挖掘稀疏甚至从未出现过的稀疏特征与最终标签相关性的能力。
二,Wide&Deep模型

单层的Wide层善于处理大量的稀疏的id类特征,Deep部分善于处理深层的特征交叉,挖掘在特征背后的数据模型。
2.1 Wide 部分
Wide部分是一个广义的线性模型,公式如下:

输入的 x = [ x 1 , x 2 , . . . , x d ] x=[x_{1},x_{2},...,x_{d}] x=[x1,x2,...,xd]包括原始特征和转换的特征,还有一些离散的id类特征(神经网络那边不喜欢这种高稀疏的离散id特征,但是wide这边喜欢)。其中一种比较重要的转换操作就是cross-product trainsformation(原始特征的交互特征),公式如下:

如果两个特征同时为1的时候,这个特征就是1,否则就是0,这是一种组合,往往我们在特征工程的时候会做一些这种特征。比如:And(gender=female, language=en)=1, 当且仅当gender=female, language=en的时候, 否则就是0.
对于wide部分训练时候使用的优化器是带正则的FTRL算法。FTRL 算法是一个稀疏性很好,精度又不错的随机梯度下降方法,该算法是非常注重模型稀疏性质的。Wide部分模型训练完之后留下来的特征都是非常重要的。模型的"记忆能力"就可以理解为发现“直接的”,“暴力的”,“显然的”关联规则的能力。
2.2 Deep部分
该部分主要是一个Embeding+MLP的神经网络模式。大规模稀疏特征通过embedding转化为低维稠密特征,然后特征进行拼接输入到MLP中,挖掘在特征背后的数据模式。

输入的特征有两类:一类是数值型特征,一类是类别型特征。DNN模型随着层数的增加,中间的特征就越抽象,也就提高了模型的泛化能力。对于Deep部分的DNN,作者使用的是AdaGrad优化器。这样做是为了使模型可以得到更加精确的解。
2.3 wide&Deep部分
W&D模型将两部分的输出的结果结合起来联合训练,将deep部分和wide部分的输出重新使用一个逻辑回归模型做最终的预测,输出概率值。联合训练的数学形式如下:

联合训练(joint)和集成训练(ensemble)的区别:
在集成训练中,单个模型分开独立训练,只是在预测阶段多个模型结合在一起。联合训练中,wide,deep,以及最后的sum层所有的参数,在训练过程中一起进行训练。
3.4 Wide&Deep工业使用经验
1,wide端和deep端接收的特征是不一样的。wide端一般会接收一些重要的交互特征,高维的稀疏离散特征,而deep端接收的是连续特征。
2,wide端和deep端使用的梯度下降方式不一样。wide端使用带L1正则的那种方式,L1有特征选择作用,更加注重特征的稀疏性;deep端使用的是普通的梯度下降方式,带L2正则。
3,wide端直接与输出连接。
4,wide & deep 是一种架构,并不一定非得是上面图中的形式,要结合具体业务进行灵活改造。有些特征如果即不适合wide也不适合deep,而是适合FM,那么就把这部分特征经过一个FM,与wide &deep 端的输出拼起来得到最后的输出。
三,Deep&Cross模型的结构原理
Wide&Deep 模型提出之后,出现了各种基于Wide或者Deep 部分进行改进的模型。其中比较经典的就是Deep&Cross模型。Deep&Cross模型针对W&D的wide部分进行了改进,用一个Cross Network替换掉之前的wide部分,来自动进行特征之间的交叉,并且网络的时间和空间复杂度都是线性的。 其网络结构如下:

3.1 Embedding and stacking layer
Embeding的作用就是把稀疏离散的类别特征转变成低维密集型特征。

X e m b e d , i X_{embed,i} Xembed,i是第i个类别特征的embedding向量。 W e m b e d , i W_{embed,i} Wembed,i是embedding矩阵, n e × n v n_{e} \times n_{v} ne×nv维度, n e n_{e} ne是embeding维度, n v n_{v} nv是该类特征的唯一取值个数。 x i x_{i} xi是该类特征的one-hot编码值。【实质上就是在训练得到的Embedding参数矩阵中找到属于当前样本对应的embedding向量】。
Stacking层是将所有的数值特征(dense)与通过Embedding转换后类别特征进行拼接:

一共K个类别特征,dense是数值特征,两者在特征维度拼接在一起。
3.2 Cross Network
这个是Deep&Cross网络的最大创新点。设计该层网络的目的是增加特征之间的交互力度。 交叉网络由多个交叉层组成,前向传播公式如下:

x l x_{l} xl代表l层的输出向量, x l + 1 x_{l+1} xl+1代表l+1层的输出向量。
交叉层的操作的二阶部分与PNN网络中的外积部分很相似,在此基础上增加了外积操作的权重向量 w l w_{l} wl,原输入向量 x l x_{l} xl和偏置向量 b l b_{l} bl。交叉层可视化如下:

每一层增加一个n维的权重向量 w l w_{l} wl(n表示输入向量的维度),并且在每一层均保留了输入向量,因此输入和输出之间的变化不会特别明显。关于CrossNet网络为什么有效,下面给出一个简单的解释:

结合上面的例子和交叉网络结构可以看到:
1, x 1 x_{1} x1中包含了所有 x 0 x_{0} x0的1,2阶特征的交互, x 2 x_{2} x2包含了所有的 x 1 x_{1} x1, x 0 x_{0} x0的1,2,3阶特征的交互。因此,交叉网络层的叉乘阶数是有限的。第l层特征的最高的叉乘阶数l+1
2,Cross网络的参数是共享的,每一层的权重特征之间共享,这样可以使模型泛化到看不见的特征交互作用,并且对噪声更具有鲁棒性。

3,假设交叉层的数量是 L c L_{c} Lc,特征x的维度是n,那么总共的参数是:

因为每一层都会有一个w和b。并且w的维度与x的维度一致。
4,交叉网络的时间和空间复杂度是线性的。这是因为,每一层都只有一个w和b,没有激活函数的存在,相对于深度学习网络,交叉网络的复杂性可以忽略不计。
5,FM模型中,一般只局限于2阶特征交叉,但是Cross Network 可以实现更高阶的特征交互,阶数由网络深度决定,并且交叉网络的参数只依据输入的维度线性增长。
6,对于每一层的计算中,都会加入 x 0 x_{0} x0,这个是原始的输入。这样能保证不管后面如何交叉,都不能偏离原始输入太远。
7, x l + 1 = f ( x l , W l , b l ) + x l x_{l+1} = f(x_{l},W_{l},b_{l}) + x_{l} xl+1=f(xl,Wl,bl)+xl 与resnet 有些类似,因此能有效缓解梯度消失的现象。
3.3 Deep Network
一般性的全连接层

3.4 组合层
这个层负责将两个网络的输出进行拼接,并且通过简单的Logistics回归完成最后的预测:
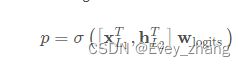
其中 x L 1 T h L 2 T x_{L_{1}}^{T}h_{L_{2}^{T}} xL1ThL2T 表示交叉网络和深度网络的输出。
最后二分类的损失函数依然是交叉熵损失:

Cross&Deep模型的核心部分是Cross Network,这一层可以进行特征的自动交叉,避免了更多基于业务理解的人工特征组合。该模型相比于Wide&Deep,cross部分的表达能力更强,使得模型具备了更强的非线性学习能力。
四,总结
Wide&Deep 以及Deep&Cross 这两个模型开启了模型组合思路的先河。这两个模型的思想其实比较简单,但是取得了非常大的成功,因为存在两大特色:
1,抓住了业务问题的本质特点,融合了传统模型的记忆能力和深度学习模型的泛化能力。
2,模型结构简单,比较容易工程实现,训练和上线。