图像识别神经网络常用层概述(暂时停更==)
第一部分 常用主干网络模型概述
一、LeNet5 模型
1.概述
LeNet5 诞生于 1994 年,是最早的卷积神经网络之一,并且推动了深度学习领域的发展。可以看做是其他深度模型的基础。
2.结构

3.创新点
LeNet5特征能够总结为如下几点:
1)卷积神经网络使用三个层作为一个系列: 卷积,池化,非线性
2) 使用卷积提取空间特征
3)使用映射到空间均值下采样(subsample)
4)双曲线(tanh)或S型(sigmoid)形式的非线性
5)多层神经网络(MLP)作为最后的分类器
6)层与层之间的稀疏连接矩阵避免大的计算成本
4.参考文献
CNN经典模型汇总_ChasingdreamLY的博客-CSDN博客_cnn模型
二、AlexNet 模型
1.概述
2012年,Hinton的学生Alex Krizhevsky提出了深度卷积神经网络模型AlexNet,它可以算是LeNet的一种更深更宽的版本。AlexNet包含了6亿3000万个连接,6000万个参数和65万个神经元,拥有5个卷积层,其中3个卷积层后面连接了最大池化层,最后还有3个全连接层。
2.结构
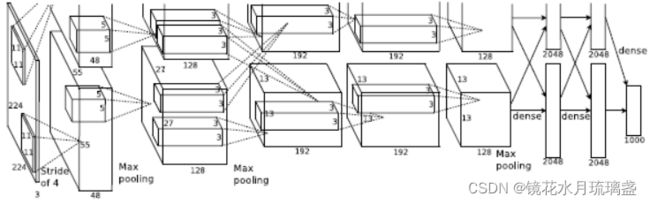
3.创新点
(1)使用Relu函数
(2)使用Dropout随机忽略一部分神经元
(3)在CNN中使用重叠的最大池化。
(4)提出了LRN(局部响应归一化)层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
(5)使用CUDA加速深度卷积网络的训练
(6)数据增强,随机地从256´256的原始图像中截取224´224大小的区域(以及水平翻转的镜像)同时,对图像的RGB数据进行PCA处理,并对主成分做一个标准差为0.1的高斯扰动,增加一些噪声,这个Trick可以让错误率再下降1%
补充:LRN局部响应归一化:

局部归一化,就是让这一层的每个点(x,y)除以附近的几层(x,y)的值(一般为五层),并求平均值。不同于普通归一化,这里只有附近几层对其归一化产生影响
4.参考文献
AlexNet 中的 LRN(Local Response Normalization) 是什么 - 知乎 (zhihu.com)
三、VGG 模型
1.概述
来自牛津大学的 VGG 网络(参见:Very Deep Convolutional Networks for Large-Scale Image Recognition)是第一个在各个卷积层使用更小的 3×3 过滤器(filter),并把它们组合作为一个卷积序列进行处理的网络。
2.结构

3.创新点
(1)LRN层作用不大。
(2)用的卷积核更小。
4.参考文献
CNN经典模型汇总_ChasingdreamLY的博客-CSDN博客_cnn模型
四、GoogleNet(Inception)模型
1、概述
在每一个卷积层,并行使用1*1卷积核,3*3卷积核,5*5卷积核和池化,同时提取不同尺度的特征,然后通过1*1的卷积核对每一个分支进行降维后,最后将结果合并拼接在一起。
在这个结构中,1*1卷积扮演了非常重要地角色,1*1卷积并没有对图像本身产生什么影响,在数学上仅仅是最简单地矩阵乘法操作,其最重要的作用在于降低特征图的数量以达到降维的目的。由于有了1*1卷积的存在,才使得网络可以在不增加参数数量级的情况下可以增加复杂度。
2、结构
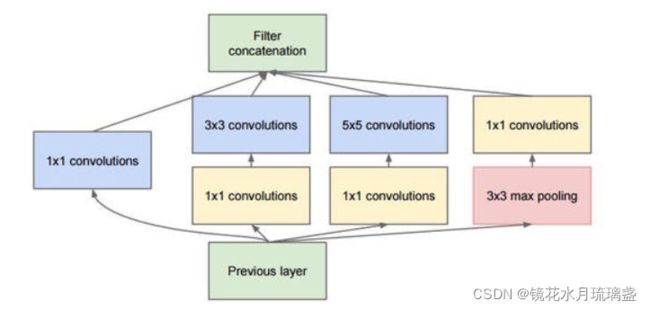
3.创新点
用多种不同尺度的卷积核运算并拼接
4.其他版本
Inception项目的其它几个版本这里做一下简要的概述,不过多讨论:
1.Inception-v2是在第一代的GoogleNet基础上加入了批标准化(Batch Normalization)技术。其具体做法是,对mini-batch中所有的信号量进行统一的归一化,使得一个批次中所有的信号量符合均值为0,方差为1的高斯分布。需要注意的是,在tensorflow中,使用批标准化技术要在激活函数之前,否则作用会打一定的折扣;
2.Inception-v3在之前的版本上又有提高。其最核心的思想是将卷积核操作继续分解成更小的卷积核。首先,比如,借鉴VGGNets的思路,5*5的卷积可以由连续2层3*3卷积所替代,这样既减少了参数数量,也进一步加快了计算速度。这样的好处是,在经过这样的转换后,不但参数数量进一步减少,计算速度更快,而且网络的深度也加深了,增加了非线性表达能力。
3.Inception-v4 相当于融合了Inception和Resnet(Resnet讲解在下文),如下
5.参考文献
CNN经典模型汇总_ChasingdreamLY的博客-CSDN博客_cnn模型
深度学习中的highway network、ResNet、Inception_博客堂-CSDN博客_highway网络
6.训练效果
(Inception-v4)20.0%
五、Highway network
1. 概述
由于网络每层之间进行的是非线性变换,因此当层数增加时,网络难以保证恒等变换,从而导致误差累加,引起错误增多的问题,因此该方法提出通过一个门来控制参数传递,将部分信息直接映射到下层网络。
2.结构
highway network 借鉴了自然语言处理中的 LSTM思想,通过一个“门”:T (x,WT)来尽可能保留原信息,如下图:![]()
其中,H(x,WH)代表非线性变换部分。T∈(0,1)
由上式可以看出,当T取得0或1时,y可简化如下
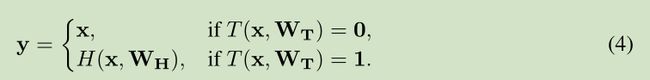
、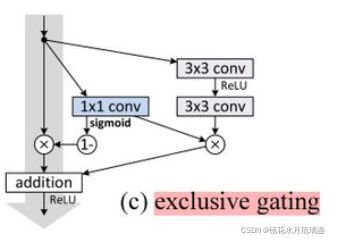
3.创新点
将部分上层信息不经过修改直接传入下一层,一定程度上解决了层数增多,误差增多的问题。
4.参考文献
高速网络(Highway net)和残差网络(Residual Network)各有什么优劣? - 知乎 (zhihu.com)
深度学习中的highway network、ResNet、Inception_博客堂-CSDN博客_highway网络
六、ResNet模型(残差神经网络)
1.概述
微软研究院的何恺明、张祥雨、任少卿、孙剑等人提出的残差神经网络,解决了网络层数加深,导致误差累加,引起错误增多的问题。某种意义上讲,ResNet模型可以看做是Highway network模型的一种简化版本。这里不通过门来控制参数,而是直接将上一层的全部信息通过支路,不修改直接传给下一层。
2.结构
)
可以看出,该网络结构类似Highway network的变种,只是x支路的权重始终为1。

3.创新点
通过边上的支路x,将上一层的大部分信息直接传入下一层,同时通过中间的主干路对信息进行小幅度修改(即W和b基本上都是0,输出结果很小,这样和支路相加之后相当于对信息进行小幅度修改),从而大幅提高网络深度。
该网络较Highway network比更为简单,但实际效果却更好。一方面是由于计算量更小,产生的误差更小。另一方面Highway network中用到了sigmiod,而sigmiod层数一多收敛性就会很差。
4.训练效果
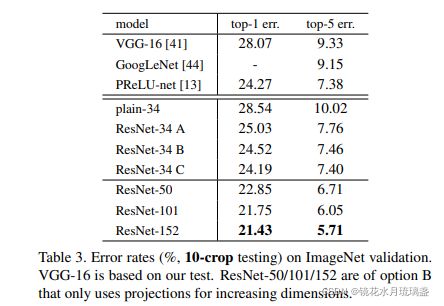
5.参考文献
高速网络(Highway net)和残差网络(Residual Network)各有什么优劣? - 知乎 (zhihu.com)
深度学习中的highway network、ResNet、Inception_博客堂-CSDN博客_highway网络
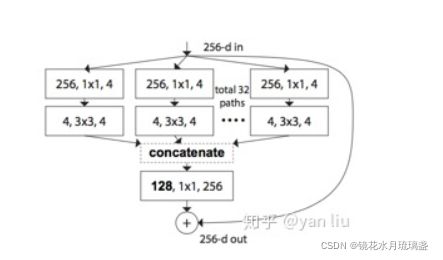
七、ResNeXt模型
1.概述
ResNeXt是模型是ResNet的变种,他和Inception-v4模型非常类似,也是ResNet与GoogleNet二者的融合。
2.结构

3. 与 Inception-v4模型比较
1.ResNeXt的分支的拓扑结构是相同的(就是每条支路相同),Inception V4需要人工设计;
2.ResNeXt是先进行卷积然后相加,Inception V4是先拼接再执行卷积。
4.训练效果
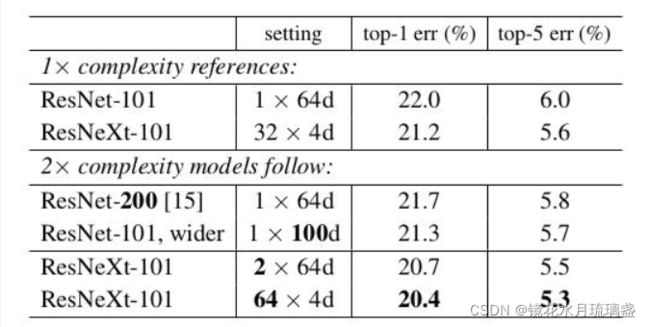

5. 参考文献
ResNeXt详解 - 知乎 (zhihu.com)
八、SENet模型
1. 概述
SENet模型全称 Squeeze-and-Excitation Networks,是由自动驾驶公司Momenta在2017年公布的一种全新的图像识别结构,它通过对特征通道间的相关性进行建模(即对特征通道执行注意力机制),把重要的特征进行强化来提升准确率。
2. 结构
SENet结构如下(图中WH是宽高,C是通道数,即特征图数):
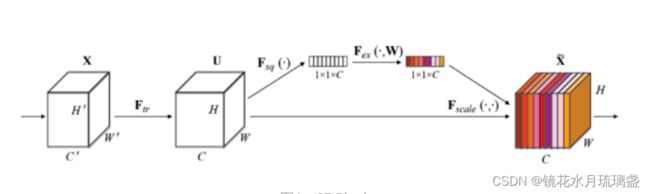
Squeeze部分:对应图中Fsq(·),这里采用最简单的求平均的方法将空间上所有点的信息都平均成了一个值,如下:
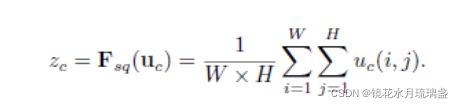
Excitation部分:对应图中Fex(·,W),用2个全连接来实现 ,第一个全连接把C个通道压缩成了C/r个通道来降低计算量(后面跟了RELU),第二个全连接再恢复回C个通道(后面跟了Sigmoid)。经试验,r取16。
后处理:将上一步得到的值sigmoid(就是上文说的那个)后,作为权重乘到源特征模块上。
3.原理
通过Squeeze部分提取了每张特征图的信息,又通过Excitation部分将所有特征图的信息杂糅到一起,这样就得到了原特征模块中各特征图的重要程度,并将其作为权重乘到源特征模块上。
4.应用
该方法可以融合到resnet或inspection中:

5.训练效果
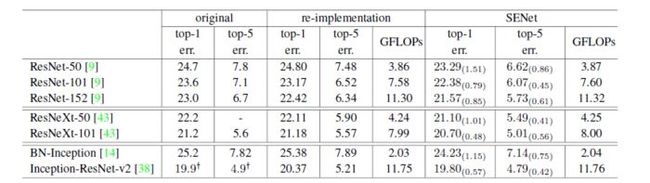
6.参考文献
解读Squeeze-and-Excitation Networks(SENet) - 知乎 (zhihu.com)
九、SKNet模型
1.概述
SKNet全称Selective Kernel Networks,类似SENet是对通道执行注意力机制,而SKNet则是对卷积核执行注意力机制,即让网络自己选择合适的卷积核。
2.结构
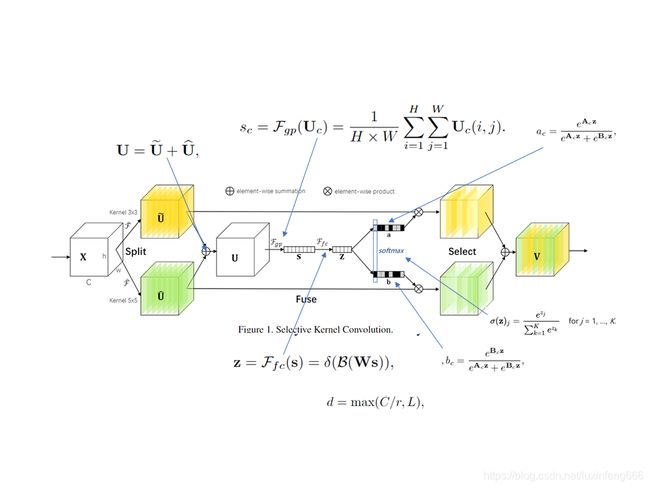
SKNet模块如上图所示。Split操作是将原feature map分别通过一个3×3的分组/深度卷积和3×3的空洞卷积(感受野为5×5)生成两个feature map :U1(图中黄色)和U2(图中绿色)。然后将这两个feature map进行相加,生成U。生成的U通过Fgp函数(全局平均池化)生成1×1×C的feature map(图中的s),该feature map通过Ffc函数(全连接层)生成d×1的向量(图中的z),公式如图中所示(δ表示ReLU激活函数,B表示Batch Noramlization,W是一个d×C的维的)。d的取值是由公式d = max(C/r,L)确定,r是一个缩小的比率(与SENet中相似),L表示d的最小值,实验中L的值为32。
生成的z通过ac和bc两个函数生成两个值,并将生成的函数值与原先的U1和U2相乘。由于ac和bc生成的函数值相加等于1,因此能够实现对分支中的feature map设置权重,因为不同的分支卷积核尺寸不同,因此实现了让网络自己选择合适的卷积核(ac和bc中的A、B矩阵均是需要在训练之前初始化的,其尺寸均为C×d)
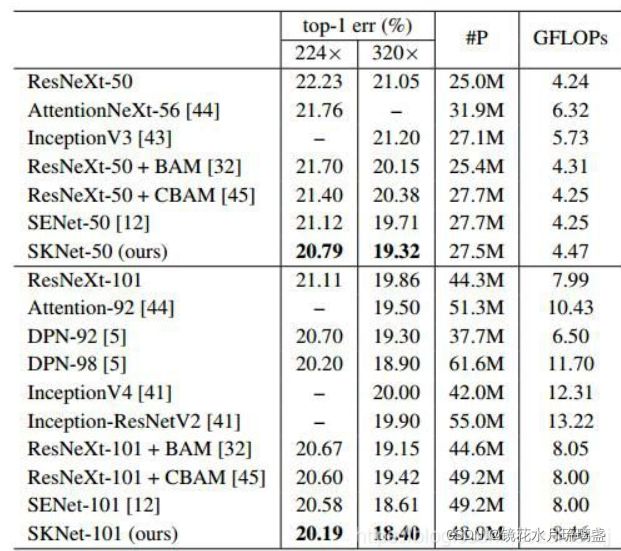
3. 参考文献
SKNet解读_luxinfeng的博客-CSDN博客_sknet
4.源码参考
SKNet学习和使用-pytorch_zahidzqj的博客-CSDN博客_sknet
十、ResNeSt模型
1.概述
ResNeSt模型本质就是将ResNeXt模型和SkNet模型相融合。
2.结构

其中split attetion结构如下:

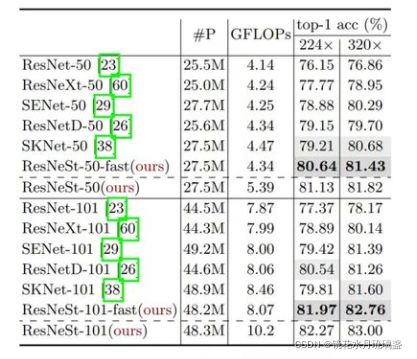
3.参考文献
ResNet最强改进版来了!ResNeSt:Split-Attention Networks - 知乎 (zhihu.com)
十一、DenseNet模型
1.概述
基本思路与ResNet一致,但是它建立的是前面所有层与后面层的密集连接(dense connection)
2.结构

3.创新点
(1)DenseBlock中,各个层的特征图大小一致,可以在channel维度上连接
(2)由于密集连接方式,DenseNet提升了梯度的反向传播,使得网络更容易训练。由于每层可以直达最后的误差信号,实现了隐式的“deep supervision”;
(3)参数更小且计算更高效,这有点违反直觉,由于DenseNet是通过concat特征来实现短路连接(也就是说并没有什么权重,大家都是摞一起的,两层256的特征图concat后变成512而已),实现了特征重用,并且采用较小的growth rate,每个层所独有的特征图是比较小的;
(4)由于特征复用,最后的分类器使用了低级特征。
4.训练效果
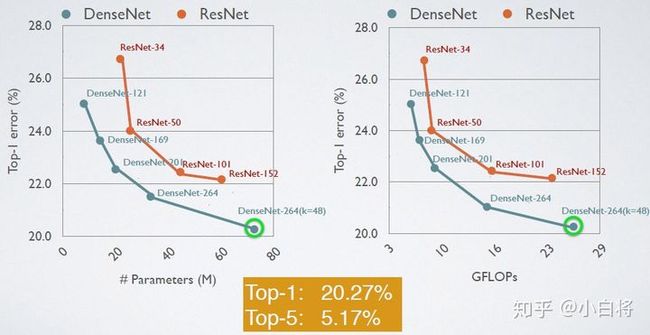
5.参考文献
DenseNet:比ResNet更优的CNN模型 - 知乎 (zhihu.com)
十二、NASNet模型(强化学习)
1.概述
不仅仅学习模型参数,同时学习模型结构(但这种方法需要大量的GPU资源)。
2.原理
要介绍NASNet模型,首先要介绍NAS原理。NAS的原理是给定一个称为搜索空间的候选神经网络结构集合,用某种策略从中搜索出最优网络结构。神经网络结构的优劣即性能用某些指标如精度、速度来度量,称为性能评估。换句话说,NAS不仅仅是学习神经网络的参数,还要学习神经网络的结构。
3.训练效果

4.参考文献
NASNet论文详解_逆熵而行-CSDN博客_nasnet论文
十三、AmoebaNet模型
1.概述
同样也是学习模型结构,只是优化了学习模型结构的策略(同样需要大量的GPU资源)。
2.原理
AmoebaNet模型的优化是基于如下事实的:
a.优秀的父代更容易留下后代;
b.年轻人比岁数大的更受欢迎;
c.无论多么优秀的人都会有死去的一天。
基于如下事实,AmoebaNet提出了一种模型的优化策略,即让优秀的网络结构复制的可能性更高,同时让较早产生的网络删除的可能性较高。具体实现可查阅参考文献
3.训练效果

4.参考文献
AmoebaNet详解 - 知乎 (zhihu.com)
十四、EfficientNet网络模型
1.概述
同样是基于NAS的思想,但优化的角度从修改整个网络模型变为仅修改网络深度,宽度和输入图片分辨率三个参数(这三个参数是影响显存的关键因素)。更为准确的说法是,EfficientNet不是一个网络模型,而是一种对模型的扩展策略。即深度:宽度:分辨率=1.2:1.1:1.15
2.结构
这里只介绍EfficientNet网络模型的基本模块:MBConv。其结构如下:

3.训练效果
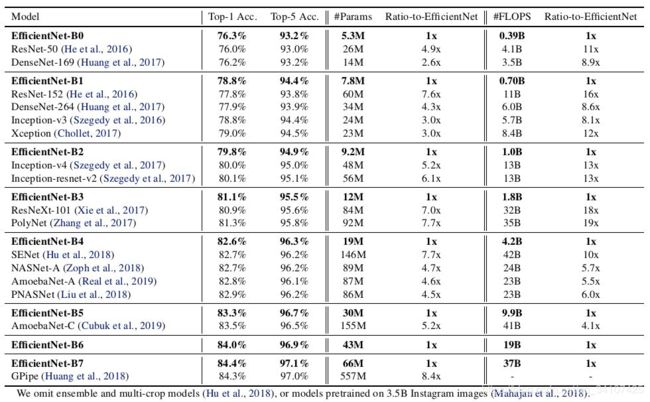
4.参考文献
EfficientNet网络详解_霹雳吧啦Wz-CSDN博客_efficient网络
十三、BoTNet网络模型
1.概述
BoTNet(Bottleneck Transformer Network):一种基于Transformer的新骨干架构。BoTNet同时使用卷积和自注意力机制,即在ResNet的最后3个bottleneck blocks中使用全局多头自注意力(Multi-Head Self-Attention, MHSA)替换3 × 3空间卷积
2.结构
要介绍BoTNet,必须先介绍一下Transformer。Transformer是自然语言处理的一种架构,其核心是引入了attention机制
84.7%!BoTNet:视觉识别的Bottleneck Transformers - 知乎 (zhihu.com)
十四、CoTNet网络模型
1.概述
CoTNet-重磅开源!京东AI Research提出新的主干网络CoTNet,在CVPR上获得开放域图像识别竞赛冠军..._我爱计算机视觉-CSDN博客
DCGAN(卷积生成对抗网络)
4.参考文献
DCGAN原理分析与pytorch实现 - 知乎 (zhihu.com)
第二部分 特征输出常用层概述
一、FPN层
1.概述
fpn,即特征金字塔,用于神经网络末端。简单来说,就是把底层的特征和高层的特征进行融合,便于细致检测。从实际层面上讲,
2.结构
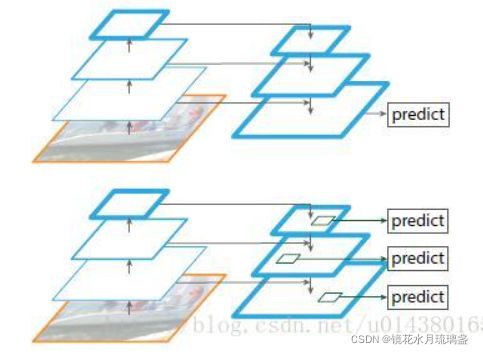
3.创新点
在边卷积边对图像进行缩小的过程中,将尺度不同的层抽出来,然后再通过上采样等方式将他们融合起来,从而实现在不同尺度上都包含强语义特征的结果
4.参考文献
mask-rcnn解读_u010901792的专栏-CSDN博客_maskrcnn
二、FCN层
1.概述
FCN是全卷积网络是CNN在语义分割领域一次重大的突破,图像语义分割,简而言之就是对一张图片上的所有像素点进行分类
2.结构
- 不含全连接层(fc)的全卷积(fully conv)网络。可适应任意尺寸输入。(用于替换神经网络最后的全连接层,因为全连接层输出结果是一维的,一般包含标签等信息,而实例分割要求输出结果是二位的,包含每个像素点的信息)
- 增大数据尺寸的反卷积(deconv)层。能够输出精细的结果。反卷积的思路如下,具体理论推导可查阅参考文献
- 结合不同深度层结果的跳级(skip)结构。同时确保鲁棒性和精确性。跳级结构利用浅层信息辅助逐步升采样,有更精细的结果
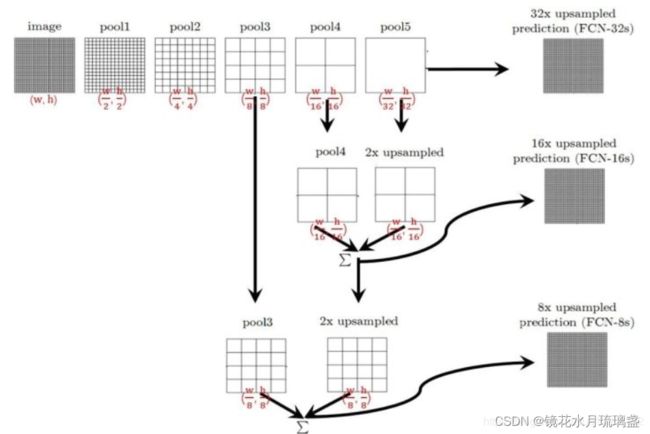
注意,这里的跳级结构和前面提到的FPN很类似,但二者不是一个东西。FPN是用来输出pred的,而跳级结构的输入是pred。也就是说,FPN在跳级结构前面
3.参考文献
mask-rcnn解读_u010901792的专栏-CSDN博客_maskrcnn
三、R-FCN:基于区域的全卷积网络目标检测
1.概述
主要贡献在于解决了“分类网络的位置不敏感性(translation-invariance in image classification)”与“检测网络的位置敏感性(translation-variance in object detection)”之间的矛盾,在提升精度的同时利用“位置敏感得分图(position-sensitive score maps)”提升了检测速度。
四、focal_loss(2017.8)
由于one-stage(如yolo等)在得到特征图后,会产生密集的目标候选区域,而这些大量的候选区域中只有很少一部分是真正的目标,这样就造成了机器学习中经典的训练样本正负不平衡的问题。它往往会造成最终算出的training loss为占绝对多数但包含信息量却很少的负样本所支配,少样正样本提供的关键信息却不能在一般所用的training loss中发挥正常作用。
对于这种类别不均衡问题常用的方法是引入一个权重因子 α ,对于类别1的使用权重α ,对于类别-1使用权重(1-α) ,但采用这种加权方式可以平衡正负样本的重要性,但无法区分容易分类的样本与难分类的样本。
因此论文中提出在交叉熵前增加一个调节因子![]() ,可以让hard examples贡献更多的loss,从而可以在训练时给与hard examples部分更多的优化。
,可以让hard examples贡献更多的loss,从而可以在训练时给与hard examples部分更多的优化。
目标检测算法 - RetinaNet - 知乎
第三部分 特殊层概述
一、空洞卷积
空洞卷积与标准卷积相比,增大了感受野。一般情况下,卷积之后的池化操作缩小feature map的尺寸也能达到增加感受野的效果,但是池化过程会导致信息的丢失,所以引入了空洞卷积操作。下图为Dilation=2时的卷积效果图,当Dilation=2时,3×3的卷积核的感受野为5×5。空洞卷积与标准卷积相比,在不增加参数量的同时增大了感受野。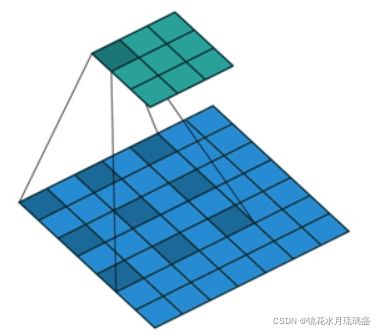
参考文献:SKNet解读_luxinfeng的博客-CSDN博客_sknet