《Semantic Stereo Matching with Pyramid Cost Volumes》
1. 研究问题
(1)现有的立体匹配网络一般构建单尺度成本量(PSMNet,StereoNet等),不足以捕获立体图像之间的空间关系。
(2)引入语义分割的信息来提高对象边界的视差精度。
2. 研究方法
本文提出了语义立体网络SSPCV-Net,提出构建金字塔成本量,同时捕获语义和多尺度空间上下文信息,以便更好的捕获立体匹配中的视差细节,显著提高立体匹配精度。语义特征由语义分割子网络推断,而空间特征由分层空间池化得出。最后,本文设计了一个 3D 多成本聚合模块来聚合提取的多尺度成本量并执行回归以获得准确的视差图。
2.1 Network architecture

首先使用使用空洞卷积的 ResNet-50 作为骨干网络从输入图像对中提取特征,然后采用自适应平均池化将特征压缩成三个尺度,然后是一个 1 ∗ 1 1*1 1∗1卷积层改变特征图的深度。生成的空间特征同时输入到网络的两个分支中:一个分支直接产生空间金字塔成本量,另一个分支是语义分割子网络,它生成语义成本量。获得的语义成本量和空间成本量构成金字塔成本量。然后将所有这些成本量输入到 3D 多成本聚合模块中进行聚合和正则化。最后,回归层产生最终的视差图。
2.2 Pyramid cost volumes
本文设计了两个分支来生成成本量:空间分支生成空间金字塔成本量,语义分支生成一个语义成本量。
2.2.1 Spatial pyramid cost volumes
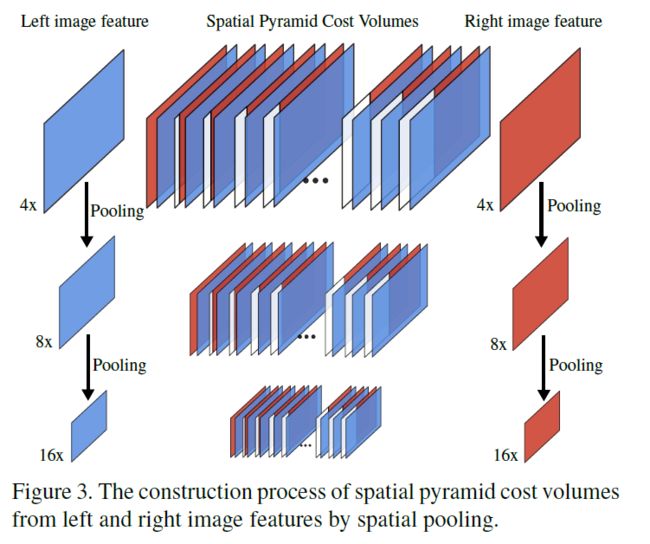
使用金字塔成本量来学习一个对象与其空间上邻域之间的关系,与PSMNet不同,PSMNet提取多尺度特征然后构建单尺度成本量,SSPCV-Net是基于多尺度特征构建多尺度成本量。
遵循GCNet,使用一元特征连接构建4D成本量,包含所有的与视差估计相关的空间上下文信息。对于三个尺度的特征图,分别形成三个尺度的成本量,形成空间金字塔成本量,成本量的尺寸是 C ∗ α W ∗ α H ∗ α D C * \alpha W * \alpha H *\alpha D C∗αW∗αH∗αD, α \alpha α属于{ 1 / 4 , 1 / 8 , 1 / 16 1/4,1/8,1/16 1/4,1/8,1/16 },级别是从高到低。
2.2.2 Semantic cost volume
语义分割遵循PSPNet,基于提取的特征图,分割子网络将低维特征图上采样到相同大小并连接所有特征图,最后接一个卷积层,生成语义分割图的最终预测。
为了形成单个语义成本量,我们使用分类层之前的特征。语义代价量的使用旨在以简单的方式捕获上下文线索,并从左右语义分割特征中学习对象像素的相似性。通过将每个一元语义特征与其对应的来自每个视差级别的相对立体图像的一元语义特征连接起来,并将它们打包成一个 4D 成本量,我们获得了一个大小为 1 / 2 C ∗ 1 / 4 W ∗ 1 / 4 H 1/2 C * 1/4 W * 1/4 H 1/2C∗1/4W∗1/4H的语义成本量,即与最大的空间成本量大小相同。
2.3 3D multi-cost aggregation module
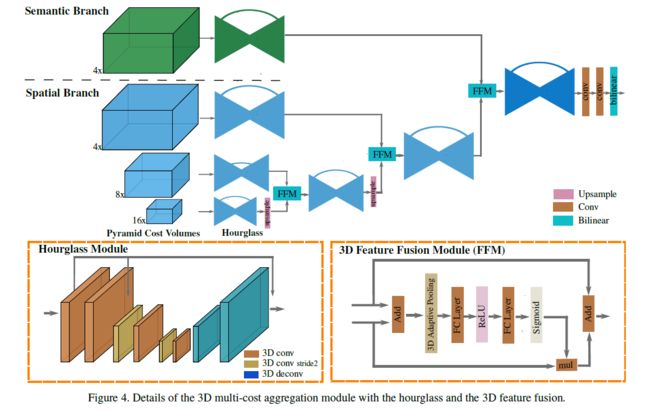
空间金字塔成本量和语义成本量都被输入到 3D 多成本聚合模块中。使用“沙漏”模块和 3D 特征融合模块 (FFM) 学习不同级别的空间上下文信息。具体来说,受到MSCI和RefineNet的启发,以递归方式将 4D 空间成本量从最低级别融合到更高级别:首先对较低级别成本量进行上采样到与其相邻更高级别相同的大小并将它们馈送到 FFM,然后融合成本量与沙漏模块之后的下一个更高级别成本量进一步融合。最后,最后一层融合的空间成本量与语义成本量融合,然后通过双线性插值将结果上采样到原始图像大小 1 ∗ D ∗ H ∗ W 1 * D * H * W 1∗D∗H∗W。
FFM模块是借鉴了SENet通道相关性捕获的思想。首先将低级成本量和高级成本量加和,然后通过自适应平均池化提取全局特征,将全局特征输入fc-relu-fc-sigmoid模块得到不同通道的权重。将低级成本量与权重进行加权,然后与高级成本量进行残差求和,完成融合过程。
2.4 Disparity regression and loss function
-
视差回归采用soft argmin
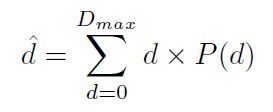
-
损失函数包括两项,视差损失和边界损失
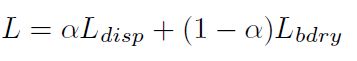
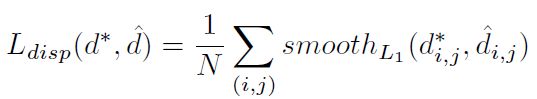

sem是语义分割图的真实标签, φ \varphi φ是梯度,N是真实视差图中的有效视差的数量。
边界项的灵感来源是:视差不连续的像素点总是在语义分割的边界处。
3. 实验结果
分两个步骤来训练SSPCV-Net: 1. 语义分割子网络的监督训练 2. 在语义分割和视差估计的监督下对整个网络进行联合训练。
数据集:
- Scene Flow
- KITTI 2015 和 KITTI 2012
- Cityscapes
训练:
- Adam优化器: β 1 = 0.9 \beta_1 = 0.9 β1=0.9, β 2 = 0.999 \beta_2 = 0.999 β2=0.999。
- 输入图像被随机裁剪成两种尺寸(
256*512和256*792)。 - SceneFlow的最大视差设置为256,KITTI的最大视差被设置为192.
- 对于SceneFlow,使用恒定的学习率0.001,batch_size=2,损失项的平衡系数 α = 0.9 \alpha=0.9 α=0.9。前40代只训练分割子网络,后40代联合训练整个网络。
- 对于KITTI,使用在SceneFlow预训练的模型进行微调。学习率初始设置为0.01,然后每100代就减少一半。语义分割子网络首先在KITTI 2015上训练300代,然后对整个网络进行联合训练,训练400代。对于KITTI 2015, α = 0.9 \alpha=0.9 α=0.9,对于KITTI 2012, α = 1 \alpha=1 α=1,因为KITTI 2012没有分割标签。
- 用两个GPU,在SceneFlow训练花费120小时,在KITTI训练花费70小时。
- CityScapes只用于测试泛化性能。
3.1 Ablation studies
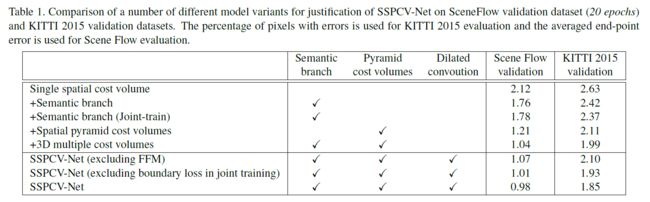
对语义分支、空间金字塔成本量、特征提取网络的空洞卷积进行了消融实验。实验表明金字塔成本量和语义信息可以提高视差估计的准确性,并且在网络中使用空洞卷积策略时,特征提取得到了改进。
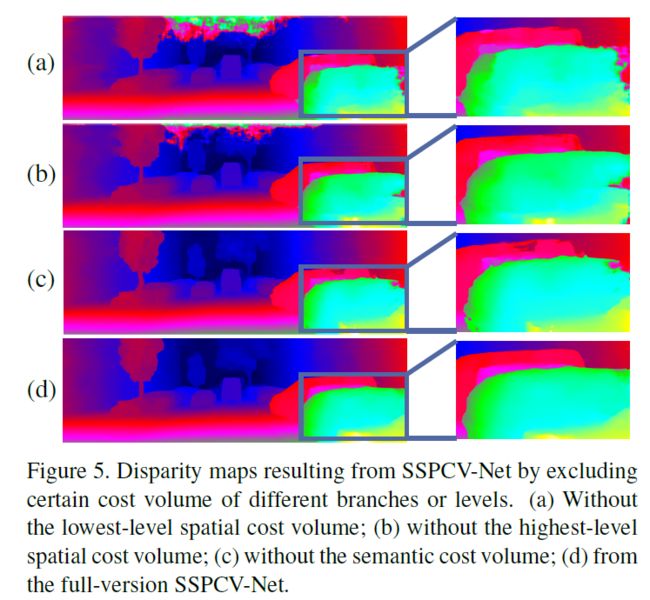
对金字塔成本量的消融实验,实验表明最低级别的空间成本量有助于提高小对象区域的准确性,最高级别的空间成本量包含更多上下文信息并有助于检测更多场景。语义成本量有助于产生更好的边缘和更好的形状线索。最后,SSPCV-Net 拥有语义成本量和空间金字塔成本量的所有优势。
3.2 Comparisons with some existing networks
SceneFlow

SSPCV-Net获得了更准确的边缘。
KITTI 2015
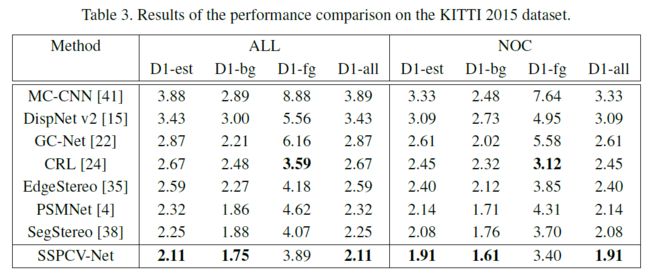
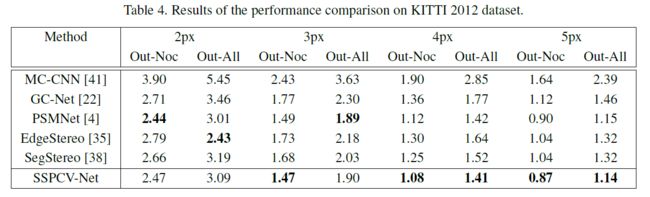
KITTI 2012

Cityscapes

SSPCVTNet的预测能够很好的捕获全局布局和对象细节(形状和边缘),泛化性能更好。
4. 结论
在SceneFlow,KITTI 2015,KITTI 2012以及Cityscapes基准数据集上表现出最先进的性能。
参考文献
[19] Squeeze-and-excitation networks
[25] Multi-scale context intertwining for semantic segmentation
[26] Refinenet: Multi-path refinement networks for highresolution semantic segmentation
[39] Bisenet: Bilateral segmentation network for real-time semantic segmentation