DenseNet原理及代码
大家好,我是灿视。
介绍下DenseNet
1. 介绍
在以往的网络都是从要么深(比如ResNet,解决了网络深时候的梯度消失问题)要么宽(比如GoogleNet的Inception)的网络,而作者则是从feature入手,通过对feature的极致利用达到更好的效果和更少的参数。
DenseNet网络有以下优点:
- 由于密集连接方式,DenseNet提升了梯度的反向传播,使得网络更容易训练。
- 参数更小且计算更高效,这有点违反直觉,由于DenseNet是通过concat特征来实现短路连接,实现了特征重用,并且采用较小的growth rate,每个层所独有的特征图是比较小的;
- 由于特征复用,最后的分类器使用了低级特征。
为了解决随着网络深度的增加,网络梯度消失的问题,在ResNet网络
之后,科研界把研究重心放在通过更有效的跳跃连接的方法上。DenseNet系列网络延续这个思路,并做到了一个极致,就是直接将所有层都连接起来。DenseNet层连接方法示意图如图所示。
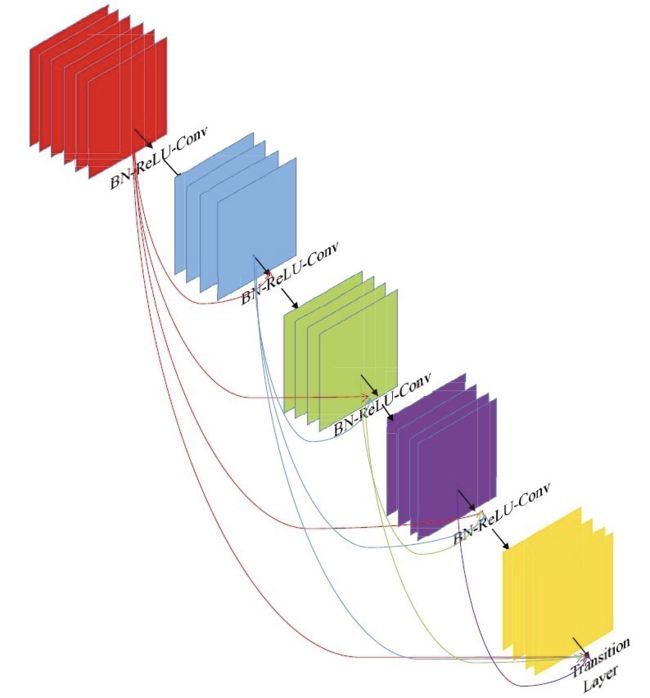
VGG系列网络,如果有 L L L层,则就会有 L L L个连接,而在DenseNet网络中,有 L L L层,则会有 L ( L + 1 ) 2 \frac{L(L+1)}{2} 2L(L+1) 个连接,即每一层的输入来自该层前面所有层的输出叠加。
DenseNet系列网络中的Dense Block 中每个卷积层输出的feature map的数量都很小,而不是像其他网络那样几百上千的数量,Dense Block 输出的feature map 数量一般在 100 100 100以下。
DenseNet 中每个层都直接和损失函数的梯度和原始输入信息相连接,这样可以更好地提升网络的性能。论文中还提到Dense具有正则化的效果,所以对过拟合有一定的抑制作用,理由是
ConnectionDenseNet的参数量相比之前的网络大大减少,所以会类似正则化的作用,减轻过拟合现象。
论文中给出的带有三个Dense Block 的DenseNet 结构图如下图所示,其中pooling层减少了特征的尺寸。同时,每个Block都需要维度上面对齐。

其中 x l x_{l} xl是需要将 x 0 , x 1 , … x l − 1 x_{0}, x_{1},…x_{l-1} x0,x1,…xl−1的特征中进行通道concatenation,就是在通道那一个维度进行合并处理。
x l = H l ( [ x 0 , x 1 , . . . , x l − 1 ] ) x_{l}=H_{l}([x_{0}, x_{1},...,x_{l-1}]) xl=Hl([x0,x1,...,xl−1])
DenseNet 具有比传统卷积网络更少的参数,因为它不需要重新学习多余的feature map。传统的前馈神经网络可以视作在层与层之间传递状态的
算法,每一层接收前一层的状态,然后将新的状态传递给下一层。这会改变状态,但是也传递了需要保留的信息。ResNet通过恒等映射来直接传递
需要保留的信息,因此层之间只需要传递状态的变化。DenseNet 会将所有层的状态全部保存到集体知识中,同时每一层增加很少数量的feature map
到网络的集中知识中。
2. 网络结构中的细节部分
从上图我们可以知道,DenseNet主要是由DenseBlock,BottleNeck与Transition层组成。
其中DenseBlock长下面这样:
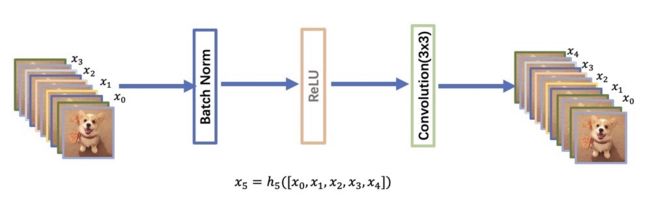
在DenseBlock中,各个层的特征图大小一致,可以在channel维度上连接。DenseBlock中的非线性组合函数 H ( ⋅ ) H(\cdot) H(⋅)采用的是BN+ReLU+3x3 Conv的结构,所有DenseBlock中各个层卷积之后均输出 k k k 个特征图,即得到的特征图的channel数为 k k k,或者说采用 k k k 个卷积核。 其中, k k k 在DenseNet称为growth rate,这是一个超参数。一般情况下使用较小的 k k k(比如12),就可以得到较佳的性能。假定输入层的特征图的channel数为 k 0 k_{0} k0 ,那么 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AJuU69FE-1620615009447)(https://www.zhihu.com/equation?tex=l)]$。
因为随着DenseNet不断加深,后面的输入层就是变得很大,在DenseNet中,我们使用了BottleNeck来减少计算量,其中主要就是加入了1 x 1卷积。如即BN+ReLU+1x1 Conv+BN+ReLU+3x3 Conv,称为DenseNet-B结构。其中1x1 Conv得到 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OFHGxZAl-1620615009449)(https://www.zhihu.com/equation?tex=4k)] 个特征图它起到的作用是降低特征数量,从而提升计算效率。
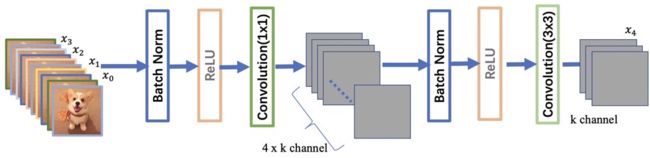
对于Transition层,它主要是连接两个相邻的DenseBlock,并且降低特征图大小。Transition层包括一个1x1的卷积和2x2的AvgPooling,结构为BN+ReLU+1x1 Conv+2x2 AvgPooling。另外,Transition层可以起到压缩模型的作用。假定Transition的上接DenseBlock得到的特征图channels数为 m m m,Transition层可以产生 ⌊ θ m ⌋ \lfloor\theta m\rfloor ⌊θm⌋个特征(通过卷积层),其中 θ ∈ ( 0 , 1 ] \theta \in(0,1] θ∈(0,1] 是压缩系数(compression rate)。当 θ = 1 \theta=1 θ=1 时,特征个数经过Transition层没有变化,即无压缩,而当压缩系数小于1时,这种结构称为DenseNet-C,文中使用 θ = 0.5 \theta=0.5 θ=0.5 。对于使用bottleneck层的DenseBlock结构和压缩系数小于1的Transition组合结构称为DenseNet-BC。
3. 代码
首先实现DenseBlock中的内部结构,这里是BN+ReLU+1x1 Conv+BN+ReLU+3x3 Conv结构,最后也加入dropout层以用于训练过程。
class _DenseLayer(nn.Sequential):
"""Basic unit of DenseBlock (using bottleneck layer) """
def __init__(self, num_input_features, growth_rate, bn_size, drop_rate):
super(_DenseLayer, self).__init__()
self.add_module("norm1", nn.BatchNorm2d(num_input_features))
self.add_module("relu1", nn.ReLU(inplace=True))
self.add_module("conv1", nn.Conv2d(num_input_features, bn_size*growth_rate,
kernel_size=1, stride=1, bias=False))
self.add_module("norm2", nn.BatchNorm2d(bn_size*growth_rate))
self.add_module("relu2", nn.ReLU(inplace=True))
self.add_module("conv2", nn.Conv2d(bn_size*growth_rate, growth_rate,
kernel_size=3, stride=1, padding=1, bias=False))
self.drop_rate = drop_rate
def forward(self, x):
new_features = super(_DenseLayer, self).forward(x)
if self.drop_rate > 0:
new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)
return torch.cat([x, new_features], 1)
再实现DenseBlock模块,内部是密集连接方式(输入特征数线性增长):
class _DenseBlock(nn.Sequential):
"""DenseBlock"""
def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate):
super(_DenseBlock, self).__init__()
for i in range(num_layers):
layer = _DenseLayer(num_input_features+i*growth_rate, growth_rate, bn_size,
drop_rate)
self.add_module("denselayer%d" % (i+1,), layer)
此外,我们实现Transition层,它主要是一个卷积层和一个池化层:
class _Transition(nn.Sequential):
"""Transition layer between two adjacent DenseBlock"""
def __init__(self, num_input_feature, num_output_features):
super(_Transition, self).__init__()
self.add_module("norm", nn.BatchNorm2d(num_input_feature))
self.add_module("relu", nn.ReLU(inplace=True))
self.add_module("conv", nn.Conv2d(num_input_feature, num_output_features,
kernel_size=1, stride=1, bias=False))
self.add_module("pool", nn.AvgPool2d(2, stride=2))
最后,整个DenseNet网络代码:
class DenseNet(nn.Module):
"DenseNet-BC model"
def __init__(self, growth_rate=32, block_config=(6, 12, 24, 16), num_init_features=64,
bn_size=4, compression_rate=0.5, drop_rate=0, num_classes=1000):
"""
:param growth_rate: (int) number of filters used in DenseLayer, `k` in the paper
:param block_config: (list of 4 ints) number of layers in each DenseBlock
:param num_init_features: (int) number of filters in the first Conv2d
:param bn_size: (int) the factor using in the bottleneck layer
:param compression_rate: (float) the compression rate used in Transition Layer
:param drop_rate: (float) the drop rate after each DenseLayer
:param num_classes: (int) number of classes for classification
"""
super(DenseNet, self).__init__()
# first Conv2d
self.features = nn.Sequential(OrderedDict([
("conv0", nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)),
("norm0", nn.BatchNorm2d(num_init_features)),
("relu0", nn.ReLU(inplace=True)),
("pool0", nn.MaxPool2d(3, stride=2, padding=1))
]))
# DenseBlock
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = _DenseBlock(num_layers, num_features, bn_size, growth_rate, drop_rate)
self.features.add_module("denseblock%d" % (i + 1), block)
num_features += num_layers*growth_rate
if i != len(block_config) - 1:
transition = _Transition(num_features, int(num_features*compression_rate))
self.features.add_module("transition%d" % (i + 1), transition)
num_features = int(num_features * compression_rate)
# final bn+ReLU
self.features.add_module("norm5", nn.BatchNorm2d(num_features))
self.features.add_module("relu5", nn.ReLU(inplace=True))
# classification layer
self.classifier = nn.Linear(num_features, num_classes)
# params initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def forward(self, x):
features = self.features(x)
out = F.avg_pool2d(features, 7, stride=1).view(features.size(0), -1)
out = self.classifier(out)
return out
大家好,我是灿视。目前是位算法工程师 + 创业者 + 奶爸的时间管理者!
我曾在19,20年联合了各大厂面试官,连续推出两版《百面计算机视觉》,受到了广泛好评,帮助了数百位同学们斩获了BAT等大小厂算法Offer。现在,我们继续出发,持续更新最强算法面经。
我曾经花了4个月,跨专业从双非上岸华五软工硕士,也从不会编程到进入到百度与腾讯实习。
欢迎加我私信,点赞朋友圈,参加朋友圈抽奖活动。如果你想加入<百面计算机视觉交流群>,也可以私我。
