毕业设计-机器学习图像卡通动漫化图像风格迁移
前言
大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
对毕设有任何疑问都可以问学长哦!
本次分享的课题是
机器学习图像卡通动漫化图像风格迁移
课题背景和意义
人工智能技术,不仅在常规领域能够大放异彩,在一些神奇的领域也会得到意想不到的“妙用”。4月初,就有谷歌利用深度学习探索如何区分日本拉面连锁店中的1170份拉面,并取得了95%的识别度。
如果将这样的技术运用至二次元,又将会有怎样的火花。对于身居重度宅属性但又手残不会画画的二次元来说,有了机器学习,不仅能够AI下棋、开车、吟诗作对,还能将人脸转化成漫画风格的图片。次元壁内的人轻松转化属性,而壁外的小伙伴也可以一窥究竟。本文将介绍如何通过科学的触角,轻叩次元壁,让AI把现实中的人脸转换成漫画风格的图片?
实现技术思路
1 图像风格迁移基础
1.1 图像风格化
首先我们来看图像风格化,所谓风格化的重点就在于风格,它一定不是普通的图片,而是对普通图片进行处理后,得到的拥有特殊风格的作品,以Photoshop软件为例,很早就内置了非常多的滤镜风格,可以分为两大类。
第一类是基于基于边缘的风格化,可以突出轮廓,创建出特殊的效果,如下图1。

图1 PS的边缘风格
上图展示了Photoshop中几种常见的基于边缘的风格化效果,从左到右分别是原图,查找边缘,等高线,浮雕效果,虽然各自效果有所不同,但是其中最核心的技术仍然是寻找到主体的边缘。为了实现以上的风格,首先要检测到主体边缘,可以使用传统的边缘检测方法,如Sobel、Canny检测算子,也可以采用深度学习方法进行检测。
第二类风格就是基于颜色的风格化,它通过更改像素值或者像素的分布,可以创造出特殊的风格,如油画、波纹,下图2从左到右分别是原图,波纹,凸出,油画效果。

图2 PS的颜色风格
以上的风格化,基于特定的图像算法规则,模式固定,只能处理特定数量的风格。而随着深度学习技术的发展,基于深度学习的风格化方法被广泛研究并且取得了非常好的效果,开启了一个新的研究领域,风格迁移。
1.2 风格迁移
风格迁移的重点在于迁移,它是将一幅图中的风格,迁移到另一幅图中。2015年德国图宾根大学科学家在论文《A Neural Algorithm of Artistic Style》[1]中提出了使用深层卷积神经网络进行训练,创造出了具有高质量艺术风格的作品。
该网络将一幅图作为内容图,从另外一幅画中抽取艺术风格,两者一起合成新的艺术画,从而使得神经网络风格迁移领域( Neural Style Transfer)诞生。

图3 Neural Style Transfer
图3中A图就是内容图,B图左下角就是风格图,B图大图就是融合了A图的内容和风格图的风格,从而可以实现任意风格的迁移,不必局限于特定的算法,下图4展示了一些案例,每一种风格都有着独特的美感,主体和背景的处理都非常好。

图4 多种Neural Style Transfer风格
1.3 风格迁移算法原理
生物学家证明了人脑处理信息具有不同的抽象层次,人的眼睛看事物可以根据尺度调节抽象层次,当仔细在近处观察一幅图时,抽象层次越低,我们看到的是清晰的纹理,而在远处观察时则看到的是大致的轮廓。实际上卷积神经网络就是实现和证明了这样的分层机制的合理性。将各个神经元看做是一个图像滤波器,输出层就是由输入图像的不同滤波器的组合,网络由浅到深,内容越来越抽象。
研究者基于此特点提出图片可以由内容层(content)与风格层(style)两个图层描述,内容层描述图像的整体信息,风格层描述图像的细节信息。
所谓内容,指得是图像的语义信息,即图里包含的目标及其位置,它属于图像中较为底层的信息,可以使用灰度值,目标轮廓等进行描述。
而风格,则指代笔触,颜色等信息,是更加抽象和高层的信息。
图像风格可以用数学式子来描述,其中常用的是格拉姆矩阵(Gram Matrix),它的定义为n维欧氏空间中任意k个向量的内积所组成的矩阵,如下:
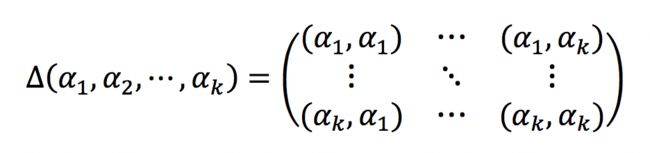
基于图像特征的Gram矩阵计算方法如下:
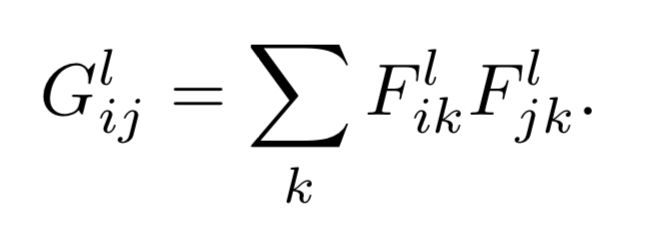
Glij向量化后的第l个网络层的特征图i和特征图j的内积,k即向量的长度。
格拉姆矩阵可以看做特征之间的偏心协方差矩阵,即没有减去均值的协方差矩阵。内积之后得到的矩阵的对角线元素包含了不同的特征,而其他元素则包含了不同特征之间的相关信息。因此格拉姆矩阵可以反应整个图像的风格,如果我们要度量两个图像风格的差异,只需比较他们Gram Matrix的差异即可。
假设我们有两张图,一张是欲模仿的风格图s,一张是内容图c,想要生成图x,风格迁移转换成数学问题,就是最小化下面这个函数。
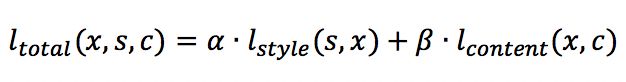
因此当我们要实现一个滤镜算法时,只需要提取风格图的风格,提取要使用滤镜的图的内容,然后合并成最终的效果图。
基于图像的风格迁移算法
基于图像优化的方法是在图像像素空间做梯度下降来最小化目标函数,以Gary等人提出的经典算法[1]为例,下图5是该算法的原理图。
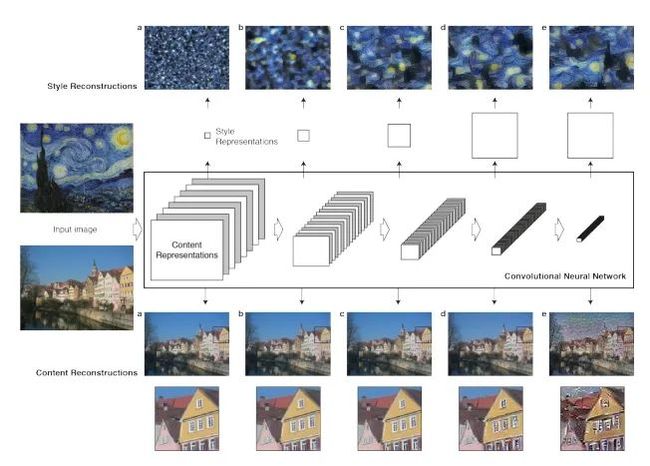
图5 Neural Style Transfer算法原理
图中包含了2个输入通道,分别用于进行内容重建(Content construction)和风格重建(Style construction)。
(1) 内容重建通道。选择某一个抽象级别较高的特征层计算内容损失,它的主要目标是保留图像主体的内容和位置,损失计算如下,使用了特征的欧式距离,Fijl和Pijl分别是第l层生成图和内容图的特征值。
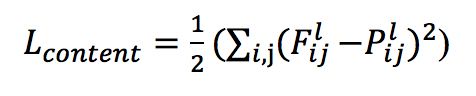
内容重建之所以不使用多尺度,是因为内容图本身只需要维持可识别的内容信息,多尺度不仅会增加计算量,还引入噪声,抽象层次较低的低尺度关注了像素的局部信息,可能导致最终渲染的结果不够平滑。
(2) 风格重建通道。与内容重建不同,CNN从底层到高层的每一层都会对风格有贡献,因为风格采用格拉姆矩阵进行表述,所以损失也是基于该矩阵计算,每一层加权相加,第l层的损失定义如下。
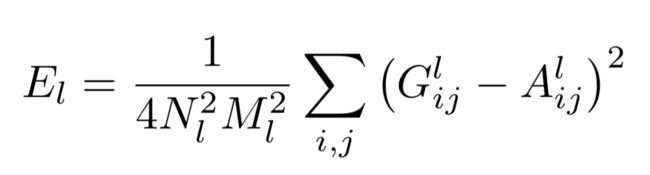
整个的风格损失函数就是各层相加,
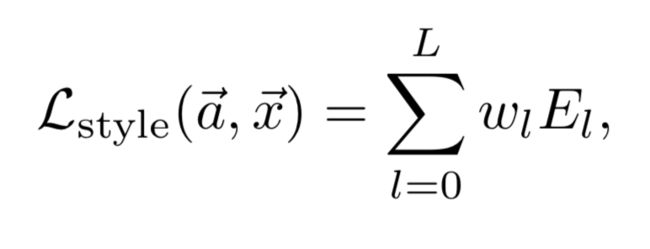
风格重建使用多尺度不仅有利于模型的收敛,而且兼顾了局部的纹理结构细节和整体的色彩风格。
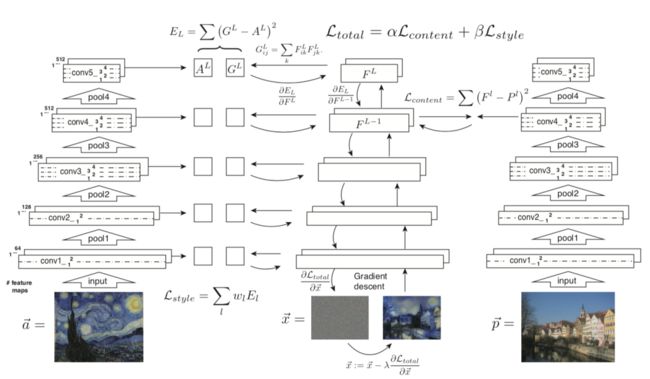
图6 Neural Style Transfer算法优化
当然最原始的迁移算法也存在着一些固有的缺陷,包括无法保持目标的颜色,纹理比较粗糙,无法识别语义内容导致目标风格不完整,或者出现错乱,比如将天空的风格迁移到大地等,后续的研究者们对其提出了许多的改进,其中最具有代表性的是Adobe公司[2]的真实场景风格转换,它们只迁移图像的颜色而不改变纹理,作者称之为照片风格迁移(photo style transfer)。

目前风格迁移主要有两大类方法,基于图像优化的风格迁移算法和基于模型优化的风格迁移算法。
基于模型优化的风格迁移算法
基于图像优化的方法由于每个重建结果都需要在像素空间进行迭代优化,这种方式无法实时,因此研究人员开始研究更加高效的方法,即基于模型优化的方法,它的特点是首先使用数据集对某一种风格的图进行训练得到一个风格化模型,然后在使用的时候只需要将输入图经过一次前向传播就可以得到结果图,根据模型与风格数量可以分为许多方向,下面分别介绍。
3.1 单模型单风格及其改进
Justin Johnson等人提出的方法[3]是一个典型的单模型单风格框架,通过图像转换层(Image Transform Net)来完成整个的渲染过程,在损失网络(VGG16 Loss Network)的约束下,分别学习内容和风格。该模型用于训练的风格图数据集必须属于同一种风格,而内容图则可以任意选择。
与基于图像优化的方法相比,基于模型优化的方法不需要反复地迭代,速度快了两三个数量级,下图8所示是它的模型结构。
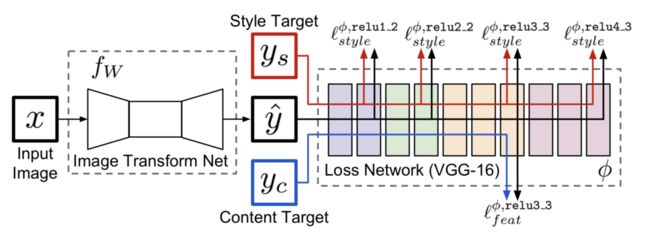
图8 基于模型的风格化
这个模型可以分为两部分,Image Transform Net是图像转换网络,VGG16是损失网络。图像转换网络输入x,输出y,它和风格图ys,内容图yc经过同样的网络,分别计算风格损失和内容损失,注意这里的yc实际上就是输入图x。
内容损失采用的是感知损失,风格损失与基于图像优化的方法一样采用Gram矩阵来定义,都已经介绍过许多次了,就不再赘述。
3.2 单模型多风格
单模型单风格对于每一种风格都必须重新训练模型,这大大限制了它们的实用性,因此研究人员很快便开始研究单模型多风格框架。Style bank[4]是其中的一个典型代表,它使用了一个滤波器组来代表多个风格,原理如下图9:

图9 Style bank框架
从图可以看出,输入图I首先输入一个编码器得到特征图,然后和StyleBank相互作用。StyleBank包括n个并行的滤波器组,分别对应n个不同的风格。每一个滤波器组中的每一个通道可以被看作是某一种风格元素,比如纹理类型,笔触类型。
模型总共包含两个分支,第一个是从编码器到解码器,它要求重建的图像O和输入图像I在内容上一致,因此采用的损失函数就是逐个像素的均方误差损失。
另一个分支是从编码器到风格化滤波器到解码器,它要求对于不同的风格生成不同的风格输出。对于这一个分支,包括一个内容损失,一个风格损失,以及一个平滑损失, 具体的内容损失和风格损失与Gatys论文中一样。
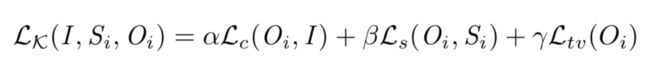
在具体训练的时候,针对K个不同的风格,首先固定编解码器分支,对风格化分支训练K轮。然后固定风格化分支,对编码器分支训练1轮。
StyleBank方法的特点是:
(1) 多个风格可以共享一个自编码器(Auto-encoder)。
(2) 可以在不更改自编码器(Auto-encoder)的情况下对新的风格进行增量学习。
另外还有的方法通过学习实例归一化(Instance Normalization)后的仿射变换系数的方法[5]来控制不同风格的图像,实例归一化表达式如下:

取对应某风格的缩放系数和偏移系数就实现了对应风格的归一化。

图10 Instance Normalization
3.3 单模型任意风格
单模型多风格框架在增加新的风格时总需要重新训练模型,单模型多风格算法可以通过学习实例归一化的仿射变换系数来控制多种风格的转换,研究表明[6]这种仿射参数其实可以由风格图本身的统计信息来替代,用风格图图像的方差和均值分别替代,就可以生成任意风格的图像,该层被称为AdaIN层,其定义如下式。
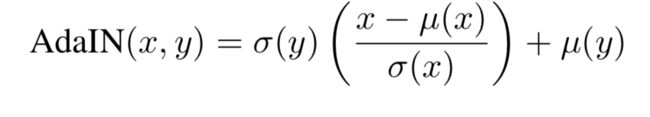
其中x是内容图,y是风格图,可以看出使用了内容图的均值和方差进行归一化,使用风格图的均值和方差作为偏移量和缩放系数,整个模型原理图如下图。
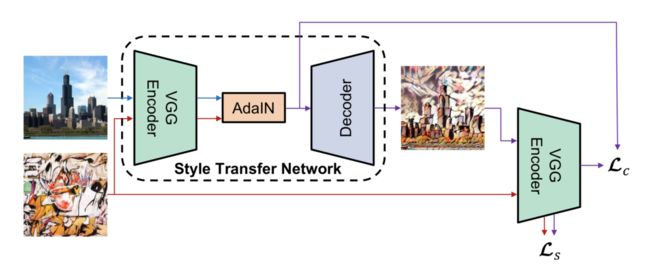
图11 基于AdaIN的风格迁移
损失包括内容损失和风格损失两部分。内容损失的计算是比较AdaIN层的输出与最终的输出图之间的L2损失,风格损失则使用了VGG不同特征层的均值和方差的L2损失而不是使用基于Gram矩阵的损失,形式更加简单。
3.4 小结
目前AdaIN层已经在图像风格化,图像生成等领域中被广泛应用,属于图像风格迁移的标配技术,单模型任意风格在实际应用中也更加有效。
1.下载预训练的vgg网络,并放入到项目的根目录中,选定风格图片和内容图片
# 内容图片路径
CONTENT_IMAGE = 'images/content.jpg'
# 风格图片路径
STYLE_IMAGE = 'images/style.jpg'
# 输出图片路径
OUTPUT_IMAGE = 'output/output'
# 预训练的vgg模型路径
VGG_MODEL_PATH = 'imagenet-vgg-verydeep-19.mat'
# 图片宽度
IMAGE_WIDTH = 450
# 图片高度
IMAGE_HEIGHT = 300
# 定义计算内容损失的vgg层名称及对应权重的列表
CONTENT_LOSS_LAYERS = [('conv4_2', 0.5),('conv5_2',0.5)]
# 定义计算风格损失的vgg层名称及对应权重的列表
STYLE_LOSS_LAYERS = [('conv1_1', 0.2), ('conv2_1', 0.2), ('conv3_1', 0.2), ('conv4_1', 0.2), ('conv5_1', 0.2)]
# 噪音比率
NOISE = 0.5
# 图片RGB均值
IMAGE_MEAN_VALUE = [128.0, 128.0, 128.0]
# 内容损失权重
ALPHA = 1
# 风格损失权重
BETA = 500
# 训练次数
TRAIN_STEPS = 3000生成图片
def loss(sess, model):
"""
定义模型的损失函数
:param sess: tf session
:param model: 神经网络模型
:return: 内容损失和风格损失的加权和损失
"""
# 先计算内容损失函数
# 获取定义内容损失的vgg层名称列表及权重
content_layers = settings.CONTENT_LOSS_LAYERS
# 将内容图片作为输入,方便后面提取内容图片在各层中的特征矩阵
sess.run(tf.assign(model.net['input'], model.content))
# 内容损失累加量
content_loss = 0.0
# 逐个取出衡量内容损失的vgg层名称及对应权重
for layer_name, weight in content_layers:
# 提取内容图片在layer_name层中的特征矩阵
p = sess.run(model.net[layer_name])
# 提取噪音图片在layer_name层中的特征矩阵
x = model.net[layer_name]
# 长x宽
M = p.shape[1] * p.shape[2]
# 信道数
N = p.shape[3]
# 根据公式计算损失,并进行累加
content_loss += (1.0 / (2 * M * N)) * tf.reduce_sum(tf.pow(p - x, 2)) * weight
# 将损失对层数取平均
content_loss /= len(content_layers)
# 再计算风格损失函数
style_layers = settings.STYLE_LOSS_LAYERS
# 将风格图片作为输入,方便后面提取风格图片在各层中的特征矩阵
sess.run(tf.assign(model.net['input'], model.style))
# 风格损失累加量
style_loss = 0.0
# 逐个取出衡量风格损失的vgg层名称及对应权重
for layer_name, weight in style_layers:
# 提取风格图片在layer_name层中的特征矩阵
a = sess.run(model.net[layer_name])
# 提取噪音图片在layer_name层中的特征矩阵
x = model.net[layer_name]
# 长x宽
M = a.shape[1] * a.shape[2]
# 信道数
N = a.shape[3]
# 求风格图片特征的gram矩阵
A = gram(a, M, N)
# 求噪音图片特征的gram矩阵
G = gram(x, M, N)
# 根据公式计算损失,并进行累加
style_loss += (1.0 / (4 * M * M * N * N)) * tf.reduce_sum(tf.pow(G - A, 2)) * weight
# 将损失对层数取平均
style_loss /= len(style_layers)
# 将内容损失和风格损失加权求和,构成总损失函数
loss = settings.ALPHA * content_loss + settings.BETA * style_loss
return loss
实现效果图样例

我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!