yolov3-tiny训练+openvino调用
yolov3-tiny训练+openvino调用
- yolov3-tiny模型训练
-
- darknet GPU环境配置
- 数据集制作
- yolov3-tiny模型的训练
- yolov3-tiny模型的测试
- Openvino调用YOLOV3模型
-
- openvino在ubuntu16.04上环境配置
- 编译build_demos.sh
- YOLOV3-TINY模型转IR
-
- yolov3-tiny模型转tf模型
- tf模型转IR模型
- 运行object_detection_demo_yolov3_async
- openvino使用感受
本人环境:ubuntu16.04 + opencv3.4.5 + cuda9.0 + cudnn7
显卡:GeForce GTX 1050/PCIe/SSE2
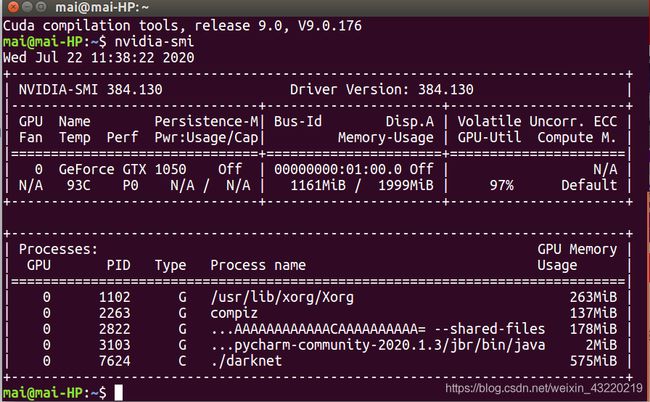
yolov3-tiny模型训练
darknet GPU环境配置
链接:link
数据集制作
数据集的制作参照的博客:链接:link里面讲的很详细
1、获取训练图片
由于我们的目的是做垃圾分类的识别,所以我们的数据集用我们实物上的的摄像头拍摄。
我们用摄像头拍出来图片是这样的:

虽然像素有点低,但是还是可以用的。
训练集的照片尽量可以多拍一点。
2、制作图片标签
然后使用标注工具labelimg标注图片(这个软件百度一搜就有,我就不把链接打出来了)

选择你图片存放的文件夹打开,然后框出自己感兴趣的部分打上标签,记得每次标注完保存一下。这样就会在你选择保存的路径下生成对应的.xml标签文件了。
生成了标签文件可以打开看看大概是这样子的
可以检查一下name就是你打上的标签
bndbox就是你框住的位置
3、准备数据集
文件的目录如下:

Annotations-存放你全部的.xml文件
ImageSets-存放训练集、测试集(如果按照本文执行到这一步,这个文件夹里面应当创建一个名为Main的文件夹,Main里面的文件在后面通过.py文件生成)
JPEGImages-存放你所有的图片文件
刚刚提到的ImageSets/Main文件夹里面的文件通过下面的.py文件执行
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
自己在myData目录下创建一个.py文件,在终端输入
python3 xxx.py #xxx.为你文件的名字
然后打开你的ImageSets/Main/就看到生成了4个文件
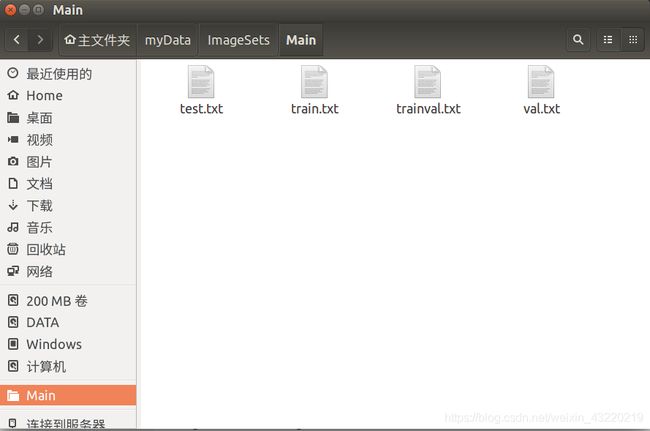
这4个文件我们都可以打开看一下
例如我打开其中的train.txt

发现他把标签文件的名字(没有后缀)一个个地写了进去,而且他随机选了我标签文件总数的90%作为训练集,剩下的10%作为测试集写在了另一个文件里面。当然这个比例可以调整,看到上面的
trainval_percent = 0.1
train_percent = 0.9
可以自己调成自己喜欢的。
下面在copy一个新的.py文件
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
#源代码sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
sets=[('myData', 'train')] # 改成自己建立的myData如果要生成训练数据 sets=[('myData', 'train')] 改为sets=[('myData', 'train'), ('myData', 'test')]
classes = ["person", "foot", "face"] # 改成自己的类别
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('myData/Annotations/%s.xml'%(image_id)) # 源代码VOCdevkit/VOC%s/Annotations/%s.xml
out_file = open('myData/labels/%s.txt'%(image_id), 'w') # 源代码VOCdevkit/VOC%s/labels/%s.txt
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('myData/labels/'): # 改成自己建立的myData
os.makedirs('myData/labels/')
image_ids = open('myData/ImageSets/Main/%s.txt'%(image_set)).read().strip().split()
list_file = open('myData/%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/myData/JPEGImages/%s.jpg\n'%(wd, image_id))
convert_annotation(year, image_id)
list_file.close()
这个文件没什么好说的,看着备注把该改的地方改一下就好了,也许会有因为文件目录问题报错的情况发生,看一下报错他找不到哪个文件你就改一下自己的文件目录就可以了。
同样在终端运行这个程序:
python3 xxx.py #xxx.为你文件的名字
然后会在myData目录下再生成一个myData文件夹,里面会有一个labels文件夹和两个.txt文件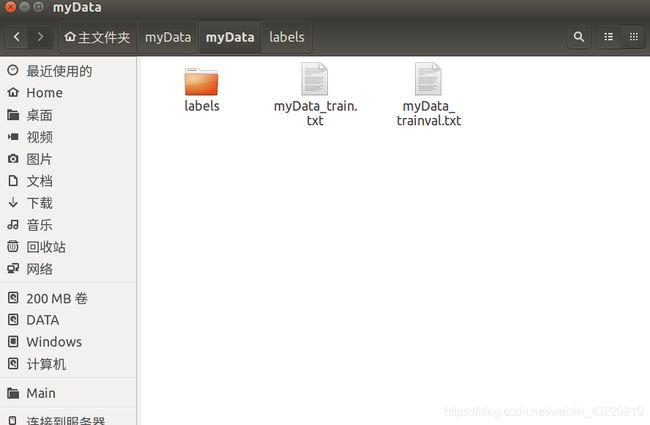
先看labels文件
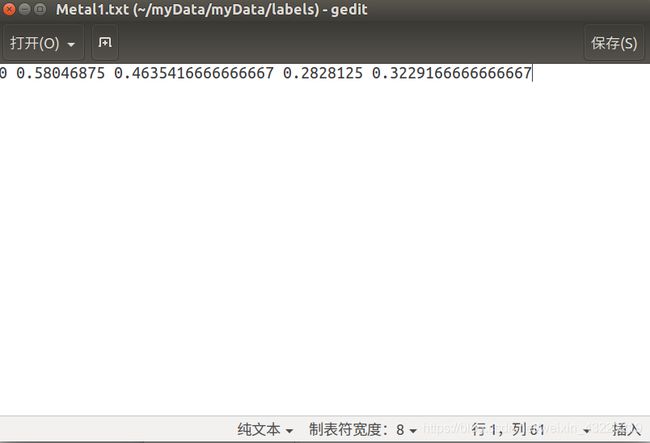
从左到右分别是:
类别的名字(后面会创建一个.names文件第1行的位置就是0,所以这一类的名字应该要写在.names的第一行)
归一化的中心点x坐标
归一化的中心点y坐标
宽度
高度
只要这个文件不是空的一般都没有太大问题,如果这个是空的,那你训练的时候就会看到全是nan
然后是myData_train.txt文件,打开他是这样的
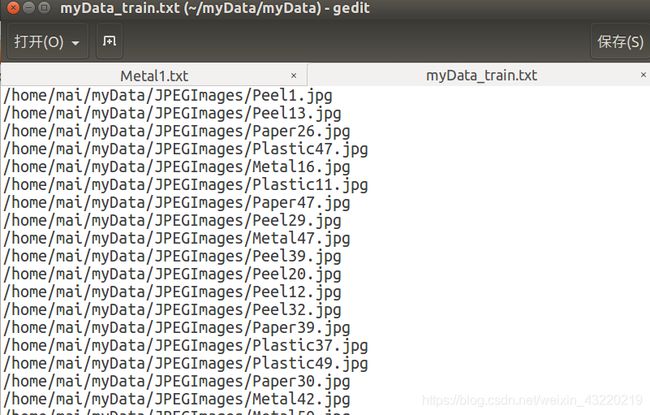
我没记错的话他就是根据前面生成的全是名字的文件把你图片在你电脑中的绝对路径写进去,到时候会根据这个寻找到你训练用的图片
到这里,我们的数据集就基本算是制作完成了
yolov3-tiny模型的训练
1、配置文件的修改
这时打开darknet文件,里面有一个cfg文件夹,打开,找到voc.data。你可以直接改这个文件夹,我为了保守起见把他copy下来并且重新命名为my_data.data
打开my_data.data
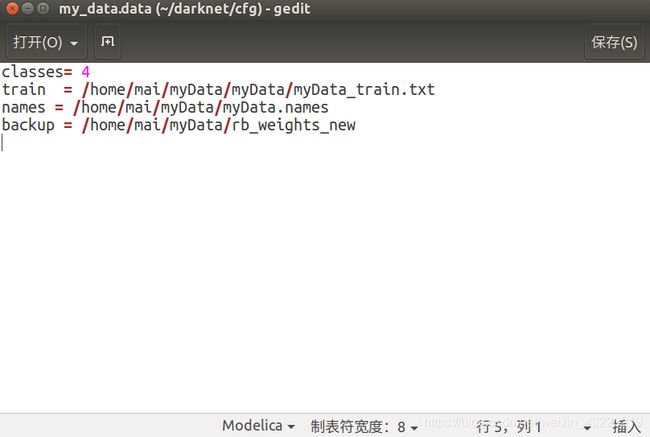
这里需要修改的
class:就是你识别类型的总数
train:刚才说到的myData_train.txt的位置
names:存放标签名称的文件,需要自己创建
bakup:模型存放的路径,要自己创建,如果没有创建模型将无法保存
.names文件我以coco为例,大概就是这样子写,一行就是一类的名字,哪一行对应哪一个名字自己看labels文件夹里面的文件。0就对应第一行,1就是第二行以此类推。
修改完这些之后保存,同时打开cfg文件夹下的yolov3-tiny.cfg,推荐使用vim打开
[net]
# Testing
#batch=1
#subdivisions=1
# Training
batch=64 #训练的时候把Training的batch和subdivisions的注释去掉同时把Testing的打上注释,就像这样,测试的时候相反
subdivisions=16
width=320
height=320
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
learning_rate=0.00001
burn_in=1000
max_batches = 500200
policy=steps
steps=400000,450000
scales=.1,.1
[convolutional]
batch_normalize=1
filters=16
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=1
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
###########
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=27 #这里有计算公式:3*(5+类数)
activation=linear
[yolo]
mask = 3,4,5
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
classes=4 #设置成自己的类数
num=6
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1 #训练时候出现内存溢出可以设为0
[route]
layers = -4
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[upsample]
stride=2
[route]
layers = -1, 8
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=27 #这里有计算公式:3×(5+类数)和上面一样
activation=linear
[yolo]
mask = 0,1,2
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
classes=4 #改成自己的类数
num=6
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1 #训练出现内存溢出可以设为0
上面改类数和filters不是全都改,如果你是用vim打开的直接/yolo找到含yolo的地方才改,tiny需改两处,yolov3模型需改3处
我训练过两种模型:yolov3和yolov3-tiny,感觉就是tiny的速度比普通的快很多,但是准确度我觉得不如yolov3。其实yolov3和yolov3-tiny训练的步骤几乎一样,就是到上一步改的文件是yolov3.cfg而不是yolov3-tiny.cfg。感兴趣的朋友也可以试试。
2、预训练模型下载
回到darknet目录下打开终端
//yolov3-tiny预训练模型下载
wget https://pjreddie.com/media/files/yolov3_tiny.weights
//然后执行
./darknet partial cfg/yolov3-tiny.cfg yolov3-tiny.weights yolov3-tiny.conv.15 15
// yolov3预训练模型下载
wget https://pjreddie.com/media/files/yolov3.weights
执行后就可以看到darknet下多了对应的预训练模型文件了
3、训练
同样在darknet文件目录下打开终端输入
// 格式就是./darknet train .data的路径 .cfg的路径 预训练模型
./darknet detector train cfg/my_data.data cfg/my_yolov3.cfg darknet53.conv.74 -gpus 0,1,2,3
等待一下,出现

![]()
5599为当前训练的次数
0.446273是当前的损失值
0.441749 avg是平群损失值
我们的损失值一般到0.06就可以停止训练了
0.000010 rate是学习率
xxx senconds是当前训练批次的时间
最后一个是训练到目前为止参与训练的总图片数
![]()
同一批次出现多少个Region16或23取决于.cfg里面的subdivisions
训练的时候重点检查nan,可以有nan但是不能全都是nan
Avg IOU:0.675016 表示在当前subdivision内的图片的平均IOU,代表预测的矩形框和真实目标的交集与并集之比,这里是67.5%
Class:0.982978 标注物品分类的正确率,这个值越趋近于1越好
Obj:0.982988 这个值越趋近于1越好
No Obj:0.004581 这个值越趋近于0越好,但不能为0
我们关注的信息大概是这些
保存模型方面,前1000次每迭代100次保存一个模型,超过1000次每10000次保存一次模型。
训练过程中经常会遇到的问题:CUDA Error: out of memory
1、subdivisions改大一点,但要是2的倍数。subdivisions就是将你的图片分几次放进网络,所以subdivisons越小,一次放进去的图片越多,越容易发生out of memory的情况
2、将cfg的random改为0
另外,训练可以停止,只要用训练的代码,模型哪里不要选预训练模型,选择最后生成的.backup文件或者.weights文件即可从最后一次保存的地方继续训练。
./darknet detector train cfg/my_data.data cfg/my_yolov3.cfg xxx.backup -gpus 0,1,2,3
yolov3-tiny模型的测试
测试之前打开对应的.cfg文件将训练的batch和subdivisons注释掉,换成测试的。否则会出现识别不出结果的情况
在darknet文件夹下打开终端执行
// 测试视频格式./darknet detector demo .data路径 .cfg的路径 模型的路径 视频的路径
./darknet detector demo cfg/my_data.data cfg/my_yolov3.cfg /home/mai/myData/weights/my_yolov3_xxx.weights home/mai/xxx.mp4
//测试图片格式 ./darknet detect .cfg路径 模型路径 图片路径
./darknet detect cfg/my_yolov3.cfg weights/my_yolov3.weights 1.jpg
训练初期生成的模型,如我100次生成的模型全屏都是各种框,然后200次到900次生成的模型检测不出任何东西。这些情况都很正常。关键要看训练时输出的损失值那类信息。如果当损失值已经降到很小了,还是检测不出来东西,那就可以检查前面的步骤是否有出错的地方或者降低检测的阈值观测现象。
// 就是在检测的最后面加上-thresh xx
darknet.exe detector test mydata/obj.data mydata/yolo-obj.cfg backup/yolo.weights -i 0 -thresh 0.25
Openvino调用YOLOV3模型
openvino在ubuntu16.04上环境配置
点击一下链接进入官网
link:
注册账号下载好后GUI安装
sudo ./install_GUI.sh
一直往下安装就行了,少了什么后面再装上就可以了
安装好后自动跳转到这个网站link:按照官方文档一步步安装即可
编译build_demos.sh
cd到build_demos.sh所在文件夹
//openvino的版本号要根据自己的做改变
cd /opt/intel/openvino_2020.3.194/deployment_tools/inference_engine/demos
终端直接运行build_demos.sh
./build_demos.sh
等待一下即可,他会在/home/xxx/目录下生成一个omz_demos_build的文件夹
我们cd进去里面的intel64/Release/
/home/xxx/omz_demos_build/intel64/Release
里面有很多demo,只要在model_downloader这个文件夹里面执行downloader.py就可以下载到对应的模型,并运行对应的demo。
// cd到model_downloader文件夹
cd /opt/intel/openvino/deployment_tools/tools/model_downloader
//执行downloader.py
python3 ./downloader.py --name 对应模型的名字
以上不做详细的介绍
YOLOV3-TINY模型转IR
很遗憾openvino没有提供直接把yolov3-tiny的模型转为IR模型的方法,但是openvino可以将tensorflow模型转为IR模型,所以我们的思路是现将yolov3-tiny模型转为tf,再由tf转成IR模型。
参考博客链接link:
yolov3-tiny模型转tf模型
clone一个开源项目
// cd到你想存放该项目的位置,执行下面命令
git clone https://gitee.com/hackerTeam2019/OpenVINO-YoloV3
其实不仅仅是这个开源项目,另外还有几个不同版本的,都能实现同样的功能。我随便找了一个写的比较清晰的README.md。下面下面可以对照着参考一下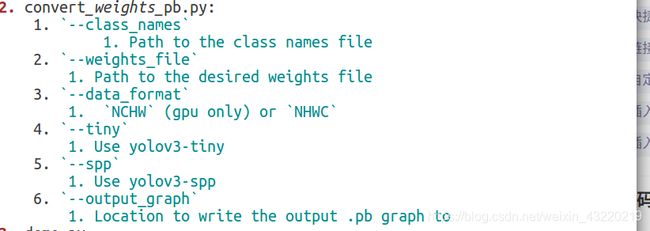
因为我们的模型是yolov3-tiny所以只看这一部分即可,如果用的是其他模型的可以自由变通。
首先将我们目录下的coco.names的内容改成之前的myData.names
然后把我们最后生成的.weights或者是.backup文件copy过来
然后执行下列命令
// 根据README.md按自己需求填写
python3 convert_weights_pb.py --class_name coco.names --tiny --weights_file yolov3-tiny.backup --data_format NHWC
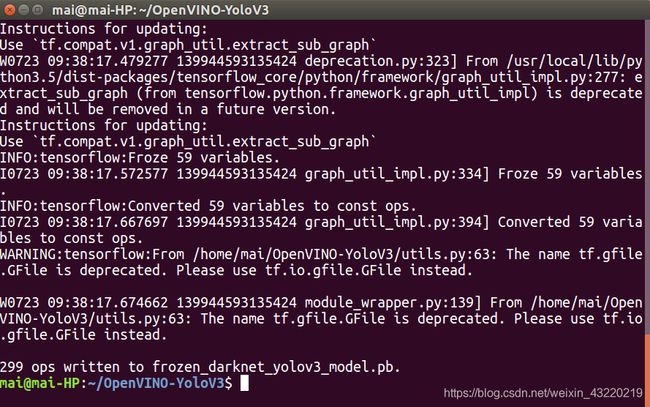
然后可以看到data文件夹下生成了一个.pb文件,那么到这里为止,我们就顺利地将yolov3-tiny的模型转化为tf模型了。本人习惯将这个文件改名为yolov3-tiny.pb。
tf模型转IR模型
现将我们刚刚生成的.pb文件用sudo copy到model_optimizer
sudo cp yolov3-tiny.pb /opt/intel/openvino_2020.3.194/deployment_tools/model_optimizer/
上面那一步很重要,我试过不copy过去结果失败了
同时model_optimizer文件夹下
cd ./extensions/front/tf/
找到一个叫yolo_v3_tiny.json的文件,sudo打开
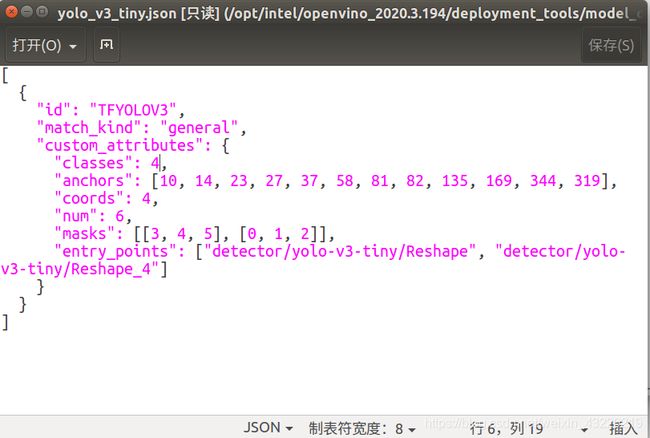
重点修改class,其他的基本不用管或者看着你的.cfg文件改
回到model_optimizer打开终端,执行下列命令
sudo python3 mo_tf.py --input_model ./yolov3-tiny.pb --tensorflow_use_custom_operations_config extensions/front/tf/yolo_v3_tiny.json --batch 1

出现以上SUCCESS即为成功,然后就可以在目录下发现3个新的文件
运行object_detection_demo_yolov3_async
cd到这个demos所在位置
cd /opt/intel/openvino_2020.3.194/deployment_tools/inference_engine/demos/python_demos/object_detection_demo_yolov3_async
打开README.md查看一下

打开终端执行
python3 object_detection_demo_yolov3_async.py -m /home/mai/myData/rb_model/yolov3-tiny.xml -i /home/mai/test.mp4
上述.xml与.bin文件需要放在同一目录下。
成功运行

openvino使用感受
本人初次接触openvino,之前有使用过opencv直接用dnn模块调用yolov3-tiny的模型,openvino给我的感觉就是很实用。虽然同样是在cpu下运行,但是openvino的性能是肉眼可见地比单纯cpu运行快得多。希望以后还是可以深入研究一下openvino,希望能将openvino运用到更多的项目作品上。
本人第一次写博客,本篇博客为完成项目后通过回忆所写,部分地方可能有误或疏漏,大家参考即可。我尽量将参考到的博客链接都写在了上面,如有侵权行为,请联系我删除。