Lesson 16.3 卷积操作
3 卷积操作
这里有两个长度为9的列表,我们让对应位置的元素相乘,之后再相加:
a ∗ 9 + b ∗ 8 + 7 ∗ c + 6 ∗ d + 5 ∗ e + f ∗ 4 + g ∗ 3 + h ∗ 2 + i ∗ 1 a * 9+b * 8+7 * c+6 * d+5 * e+f * 4+g * 3+h * 2+i * 1 a∗9+b∗8+7∗c+6∗d+5∗e+f∗4+g∗3+h∗2+i∗1如果我们把数字列表看作是权重,那以上式子就可以被看做一个加权求和的过程。现在,我们将九个数整理成如下的矩阵:
左侧的矩阵我们称之为字母矩阵,而右侧的矩阵称之为数字矩阵(也就是权重矩阵)。当表示成矩阵之后,我们可以求解两个矩阵的点积,也就是将对应位置的元素相乘再相加等到一个标量,这与我们刚才实现的加权求和运算本质一致。但此时我们发现,在变成矩阵之前,a对应的是9,i对应的是1,而现在a对应的是1,i对应的是9。如果我们还想实现刚才的加权求和,就需要将数字矩阵在平面上顺时针旋转180度,得到旋转矩阵: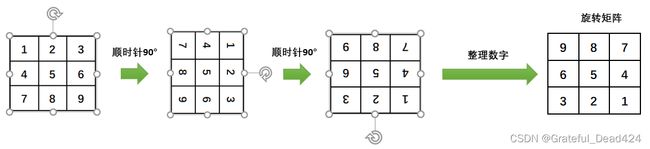
现在,将旋转矩阵与字母矩阵求点积,就可以得到与之前的加权求和一样的结果了:
dotsum = a ∗ 9 + b ∗ 8 + 7 ∗ c + 6 ∗ d + 5 ∗ e + f ∗ 4 + g ∗ 3 + h ∗ 2 + i ∗ 1 \text { dotsum }=a * 9+b * 8+7 * c+6 * d+5 * e+f * 4+g * 3+h * 2+i * 1 dotsum =a∗9+b∗8+7∗c+6∗d+5∗e+f∗4+g∗3+h∗2+i∗1现在,dotsum的结果就是字母矩阵与原始数字矩阵的卷积。
卷积操作是一种常见的数学计算,二维矩阵的卷积表示其中一个矩阵在平面上旋转180°后,与另一个矩阵求点积的结果。其中“卷”就是旋转,“积”就是点积,也就是加权求和。本质上来说,卷积就是其中一个矩阵旋转180°后,两个矩阵对应位置元素相乘再加和的结果。这个过程可以使用数学公式表示: [ x 11 x 12 ⋯ x 1 n x 21 x 22 ⋯ x 2 n ⋮ ⋮ ⋱ ⋮ x m 1 x m 2 ⋯ x m n ] ∗ [ y 11 y 12 ⋯ y 1 n y 21 y 22 ⋯ y 2 n ⋮ ⋮ ⋱ ⋮ y m 1 y m 2 ⋯ y m n ] = ∑ i = 0 m − 1 ∑ j = 0 n − 1 x ( m − i ) ( n − j ) y ( 1 + i ) ( 1 + j ) \left[\begin{array}{cccc} x_{11} & x_{12} & \cdots & x_{1 n} \\ x_{21} & x_{22} & \cdots & x_{2 n} \\ \vdots & \vdots & \ddots & \vdots \\ x_{m 1} & x_{m 2} & \cdots & x_{m n} \end{array}\right] *\left[\begin{array}{cccc} y_{11} & y_{12} & \cdots & y_{1 n} \\ y_{21} & y_{22} & \cdots & y_{2 n} \\ \vdots & \vdots & \ddots & \vdots \\ y_{m 1} & y_{m 2} & \cdots & y_{m n} \end{array}\right]=\sum_{i=0}^{m-1} \sum_{j=0}^{n-1} x_{(m-i)(n-j)} y_{(1+i)(1+j)} ⎣⎢⎢⎢⎡x11x21⋮xm1x12x22⋮xm2⋯⋯⋱⋯x1nx2n⋮xmn⎦⎥⎥⎥⎤∗⎣⎢⎢⎢⎡y11y21⋮ym1y12y22⋮ym2⋯⋯⋱⋯y1ny2n⋮ymn⎦⎥⎥⎥⎤=i=0∑m−1j=0∑n−1x(m−i)(n−j)y(1+i)(1+j)其中 x x x表示其中一个矩阵的值, y y y表示另一个矩阵的值, m m m与 n n n分别是两个矩阵的行数和列数。在其他教材或其他说明中,你可能会见到使用其他符号的二维矩阵的卷积表示,但其本质都与我们所说的“旋转再求内积”一致。你也可能会见到卷积的代数表示(就是带积分的那个)、甚至是离散卷积的表示方式,幸运的是那些与矩阵卷积有所不同,因此如果你感觉困惑,你可以不用去理会。
之前我们说过,只要我们对图像数据进行任意数学运算,且得出的结果不超出图像的像素范围[0,255],就可以生成新的图像。而卷积是一种从两个矩阵中得出新数值的方式,这个操作正好可以用于图像的变换。但图像的矩阵里动辄就几百万甚至几千万个像素,如何将卷积适用于图片来得到一张新的图片(也就是一个新的矩阵)呢?来看一个典型的操作:假设现在的权重矩阵如下:
假设现在的权重矩阵如下: [ − 1 0 1 − 2 0 2 − 1 0 1 ] \left[\begin{array}{rrr} -1 & 0 & 1 \\ -2 & 0 & 2 \\ -1 & 0 & 1 \end{array}\right] ⎣⎡−1−2−1000121⎦⎤我们让它与下图中左侧的图像进行卷积。左侧的图像是一个6X6结构的图像,其左半边的像素都为10,右半边像素都为0的图像,因此看起来,它右侧那一半是均匀的颜色,左侧那半边是另一种均匀的颜色,因此中间的竖线就是两块均匀颜色中的“边缘”。为了实现卷积,我将权重矩阵进行了180°的旋转,图中所示的是旋转矩阵。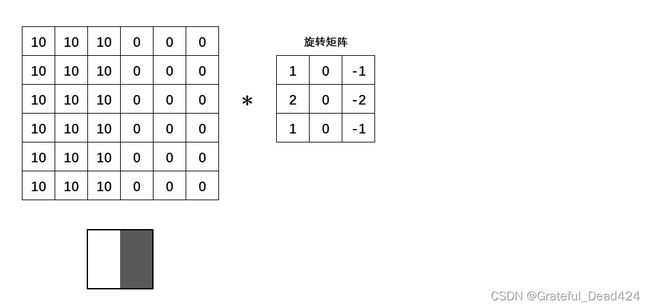
对于这张图像,卷积操作是这样进行的。首先,我们令旋转矩阵与绿色区域进行点积(对应位置元素相乘再相加),得到卷积结果0,成为新矩阵的第一个元素。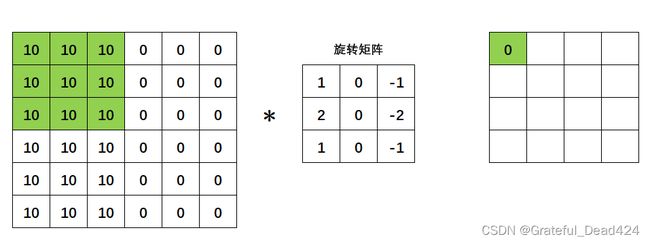 接下来,我们在图片上,将绿色区域向右移动一个像素,再令旋转矩阵与绿色区域进行点积,得到卷积结果40。
接下来,我们在图片上,将绿色区域向右移动一个像素,再令旋转矩阵与绿色区域进行点积,得到卷积结果40。
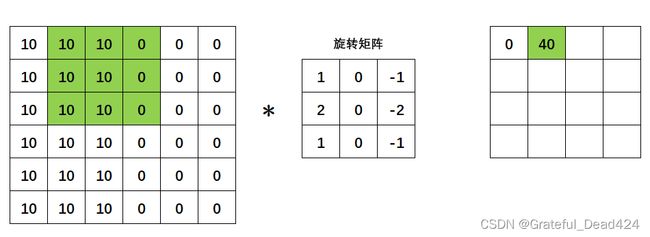
同样的,我们继续移动绿色区域,继续计算点积: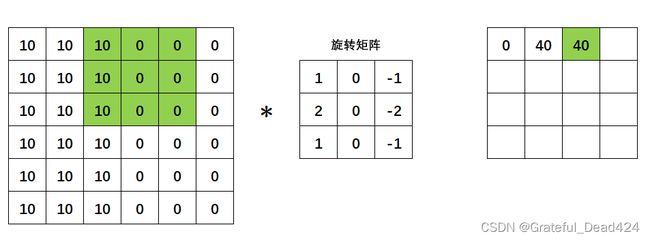
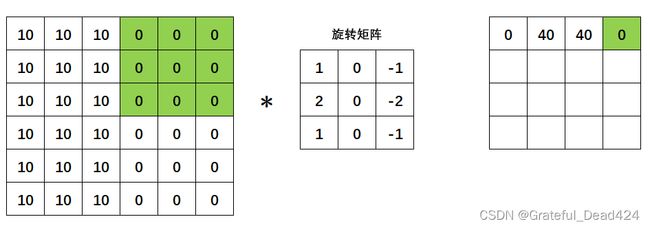
当横向区域扫描完毕之后,我们向下移动一个像素,继续从左到右扫描: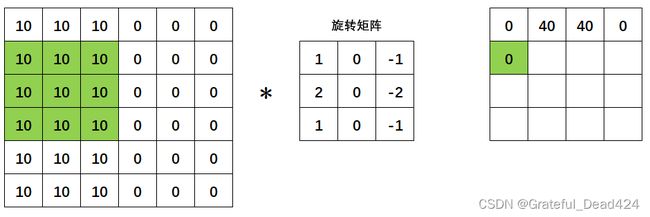
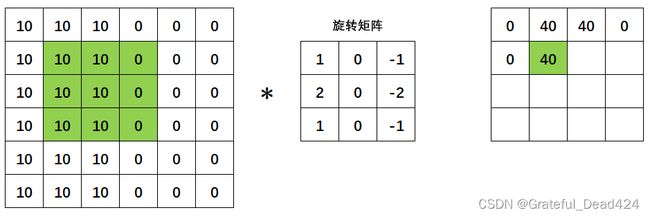
以此类推,直到绿色区域扫描完毕整张图像,得到右侧的矩阵: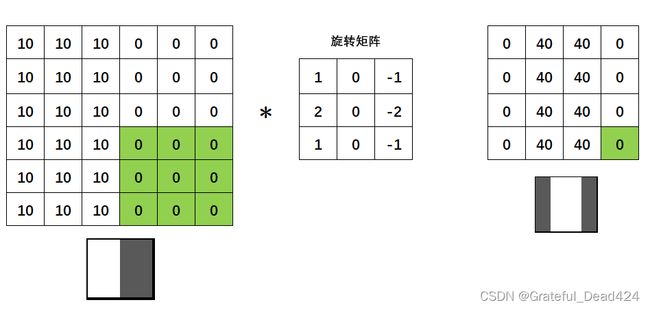
此时,右侧的矩阵就是我们在左图上使用权重矩阵 [ − 1 0 1 − 2 0 2 − 1 0 1 ] \left[\begin{array}{rrr} -1 & 0 & 1 \\ -2 & 0 & 2 \\ -1 & 0 & 1 \end{array}\right] ⎣⎡−1−2−1000121⎦⎤进行卷积计算的结果。我们得到了一张4X4尺寸的图像,且中间两列像素为40,两边为0,所以是中间较亮,两边较暗。原本的图像在中间有一条明显的“边界”,现在我们权重矩阵对这张图像进行卷积后得出的图“放大”了这个边界,让边界亮了起来,让其他地方变暗了,这就实现了对图像进行“边缘检测”。当然,由于我们现在所使用的图像非常小(像素只有6*6),所以得到的边缘检测结果看起来边缘非常粗,实际上在真实案例中,白色的线会是非常细的。
边缘检测是卷积操作的一个常见应用,我们所使用的权重矩阵其实是纵向的索贝尔算子(Sobel
Operator),用于检测纵向的边缘,我们也可以使用横向的索贝尔算子,以及拉普拉斯算子来检测边缘。在OpenCV当中我们可以很容易地实现这个操作:
import numpy as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('/Users/zhucan/Desktop/edge detection.PNG')
#索贝尔等经典卷积操作在灰度图像上表现更好,因此我们将图像导入时就转化为灰度图像
img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#查看原图
plt.figure(dpi=200)
plt.imshow(img
,cmap="gray" #colormap
)
plt.axis('off');

#两种经典算子:拉普拉斯与索贝尔
laplacian = cv2.Laplacian(img,cv2.CV_64F,ksize=5)
#cv2.CV_64F是opencv中常常使用的一种数据格式
#在这里输入之后可以保证输出数据是uint8类型
sobelx = cv2.Sobel(img,cv2.CV_64F,1,0,ksize=5) #横向的索贝尔,旋转矩阵为5X5
sobely = cv2.Sobel(img,cv2.CV_64F,0,1,ksize=5) #纵向的索贝尔,旋转矩阵为5X5
plt.figure(dpi=300)
plt.subplot(2,2,1),plt.imshow(img,cmap = 'gray')
plt.title('Original'),plt.axis('off')
plt.subplot(2,2,2),plt.imshow(laplacian,cmap = 'gray')
plt.title('Laplacian'),plt.axis('off')
plt.subplot(2,2,3),plt.imshow(sobelx,cmap = 'gray')
plt.title('Sobel X'),plt.axis('off')
plt.subplot(2,2,4),plt.imshow(sobely,cmap = 'gray')
plt.title('Sobel Y'),plt.axis('off')

除了边缘检测之外,我们还可以使用其他权重矩阵与原图卷积来修改图像,例如锐化、模糊等等。
在这些例子中,有一个值得注意的问题:我们首先确立权重矩阵,然后将矩阵旋转180°之后再与感受野进行点积,这个过程叫做“卷积”,但在实际执行计算的时候,真正发挥作用的使旋转后的旋转矩阵。为什么我们不直接定义旋转矩阵,而要先定义一个权重矩阵,再旋转它呢?
事实上,就连OpenCV中的sobel和Laplacian函数都没有进行“旋转”,而是直接定义了旋转后矩阵。或许是最初的研究者尝试了“卷积”操作,就这样流传下来,或许是原始权重矩阵的逻辑可能来源于某些理论,不旋转将会使边缘检测失效,但在今天的计算机视觉技术中,尤其是深度学习中,大部分时候我们都不再进行“旋转”这个步骤了。甚至在许多卷积相关的讲解中,会直接忽略旋转这个步骤,导致许多人无法理解“卷积”的“卷”从何而来。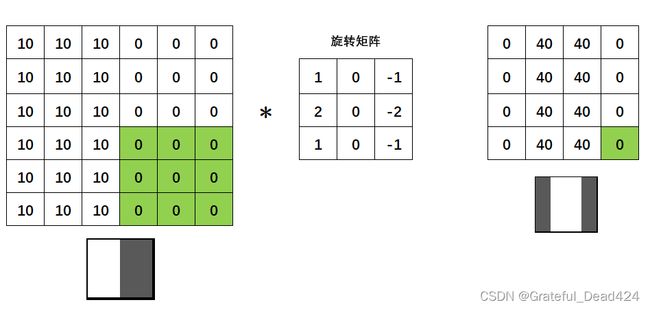
没有旋转,我们也无需在关心最初的矩阵。现在我们只关心与图像相乘的旋转矩阵,我们把旋转矩阵的值称为权重,将该矩阵称为过滤器(filter,意为可以过滤出有效的特征),也被叫做卷积核(Convolution Kernel),每个卷积核在原图上扫描的区域(被标注为绿色的区域)被称为感受野(receiptive field),卷积核与感受野轮流点积得到的新矩阵被叫做特征图(feature map)或激活图(activation map)。当没有旋转,只有点积的时候,图像与矩阵之间的运算就不是数学上的“卷积”,而是“互相关”(cross-correlation)了,但是基于历史的原因和行业习惯,我们依然把整个过程称为“卷积操作”,这个名字沿用到今天,也影响了深度学习中对卷积神经网络的称呼。
4 卷积遇见深度学习
检测边缘、锐化、模糊、图像降噪等卷积相关的操作,在图像处理中都可以被认为是在从图像中提取部分信息,因此这部分图像处理技术也被叫做“特征提取”技术。卷积操作后所产生的图像可以作为特征被输入到分类算法中,在传统计算机视觉领域,这一操作常常被认为可以提升模型表现并增强计算机对图像的识别能力。计算机视觉是研究如何让计算机从图像或图像序列中获取信息并理解其信息的学科,理解就意味着识别、判断甚至是推断,因此识别在计算机视觉中是非常核心的需求,卷积操作在传统计算机视觉中的地位就不言而喻了。数十年来,计算机视觉工程师们使用前人的经验与研究不断提取特征,再送入机器学习算法中进行识别和分类。然而,这样做是有极限的。
在边缘检测的例子中,我们看到拉普拉斯和索贝尔算子的检测是很明显的。但是,如果使用我们之前导入的孔雀图像,就会发现边缘检测的效果有些糟糕。
img = cv2.imread('/Users/zhucan/Desktop/blue-peacock.jpg')
img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
laplacian = cv2.Laplacian(img,cv2.CV_64F,ksize=5)
sobelx = cv2.Sobel(img,cv2.CV_64F,1,0,ksize=5)
sobely = cv2.Sobel(img,cv2.CV_64F,0,1,ksize=5)
plt.figure(dpi=300)
plt.subplot(2,2,1),plt.imshow(img,cmap = 'gray')
plt.title('Original'),plt.axis('off')
plt.subplot(2,2,2),plt.imshow(laplacian,cmap = 'gray')
plt.title('Laplacian'),plt.axis('off')
plt.subplot(2,2,3),plt.imshow(sobelx,cmap = 'gray')
plt.title('Sobel X'),plt.axis('off')
plt.subplot(2,2,4),plt.imshow(sobely,cmap = 'gray')
plt.title('Sobel Y'),plt.axis('off')
为什么会这样呢?这是因为,sobel和拉普拉斯算子对边缘抓取的程度较轻(从图像处理的原理上来看,他们只求取了图像上的一维导数,因此效果不够强),这样的抓取对于横平竖直的边缘、以及色彩差异较大的边缘有较好的效果,对于孔雀这样色彩丰富、线条和细节非常多的图像,这两种算子就不太够用了。所以在各种边缘检测的例子中,如果你仔细观察原图,你就会发现原图都是轮廓明显的图像。
这说明,不同的图像必须使用不同的权重进行特征提取,同时,我们还必须加深特征提取的深度。那什么样的图像应该使用什么样的权重呢?如何才能够提取到更深的特征呢?同时,如果过去的研究中提出的算子都不奏效,应该怎么找到探索新权重的方案呢?即便有效地实现了边检检测、锐化、模糊等操作,就能够提升最终分类算法的表现吗?其实不然。这些问题困扰计算机视觉工程师许久,即便在传统视觉中,我们已提出了不少对于这些问题的解决方案,但从一劳永逸的方向来考虑,如果计算机自己能够知道应该使用什么算子、自己知道应该提取到什么程度就好了。此时,深度学习登场了。