MindSpore实现生成对抗网络(3)
MindSpore实现生成对抗网络-GAN (2)
啦啦啦啦,好久没写文章了。今天来兑现诺言,CGAN的MindSpore实现它来了~~~
在前面两篇博文中,我介绍了MindSpore实现GAN的方法,并使用DCGAN实现了手写数字的生成:
- MindSpore实现生成网络(1)
- MindSpore实现生成网络(2)
但是它生成的内容是随机。自然地,就有人开始想:能不能让GAN生成我们想要的内容呢?于是乎,就有了CGAN。
简单的CGAN说明
CGAN的核心在于将属性y作为输入,融入到判别器和生成器中。如下图所示(图源于网络):
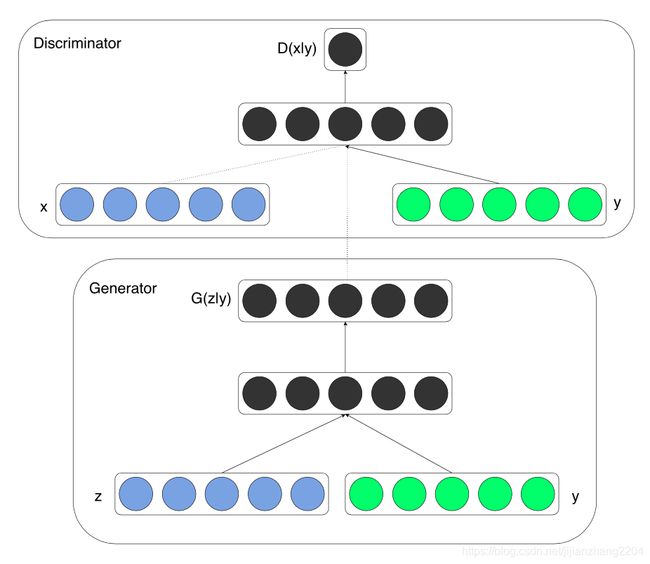
从这个图中可以看到,判别器的输入除了样本x,还多了属性标签y(在手写数字生成中,y可以是数字标签的onehot编码)。这样一来,判别器和生成器的学习目标就变成了条件y下的条件概率分布。在判别器中,无论输入的是真样本还是假样本,都需要加上条件y。
还有一点需要注意的是,输入的标签y不但要在输入时和z、x融合,在判别器和生成器的每一层特征里都要和特征融合。否则可能“学不好标签y”。
接下来,就是令人激动的代码展示环节
代码实现
首先,导入所需要的包
import os
import numpy as np
from numpy.core.fromnumeric import size
import matplotlib.pyplot as plt
from mindspore import nn
import mindspore.dataset as ds
import mindspore.dataset.transforms.c_transforms as CT
import mindspore.ops.operations as P
import mindspore.ops.functional as F
import mindspore.ops.composite as C
from mindspore.train.dataset_helper import DatasetHelper, connect_network_with_dataset
from mindspore.parallel._utils import (_get_device_num, _get_gradients_mean,
_get_parallel_mode)
from mindspore.context import ParallelMode
from mindspore.nn.wrap.grad_reducer import DistributedGradReducer
from mindspore import Tensor
from mindspore.common import dtype as mstype
from mindspore import context
from cells import SigmoidCrossEntropyWithLogits ##cells是前两篇博文定义的一个py文件
然后,定义判别器和生成器。与之前介绍的相比,主要的不同是输入和construct函数。
生成器的输入除了隐码z,还有标签y。生成器同样。正如前面所说,每一层的输入都要和标签融合一下,所以使用了P.concat(1)对特征和y进行连接。代码中的+10是因为我所使用的标签是onehot编码,是一个10维的向量。也可以直接使用原先的编码。
class Discriminator(nn.Cell):
def __init__(self, input_dims, auto_prefix=True):
super().__init__(auto_prefix=auto_prefix)
self.fc1 = nn.Dense(input_dims + 10, 256)
self.fc2 = nn.Dense(256 + 10, 128)
self.fc3 = nn.Dense(128 + 10, 1)
self.lrelu = nn.LeakyReLU()
self.concat = P.Concat(1)
def construct(self, x, label):
x = self.concat((x, label))
x = self.fc1(x)
x = self.lrelu(x)
x = self.concat((x, label))
x = self.fc2(x)
x = self.lrelu(x)
x = self.concat((x, label))
x = self.fc3(x)
return x
class Generator(nn.Cell):
def __init__(self, input_dims, output_dim, auto_prefix=True):
super().__init__(auto_prefix=auto_prefix)
self.fc1 = nn.Dense(input_dims + 10, 128)
self.fc2 = nn.Dense(128 + 10, 256)
self.fc3 = nn.Dense(256 + 10, output_dim)
self.relu = nn.ReLU()
self.tanh = nn.Tanh()
self.concat = P.Concat(1)
def construct(self, x, label):
x = self.concat((x, label))
x = self.fc1(x)
x = self.relu(x)
x = self.concat((x, label))
x = self.fc2(x)
x = self.relu(x)
x = self.concat((x, label))
x = self.fc3(x)
x = self.tanh(x)
return x
既然判别器和生成器的做了修改,那么DisWithLossCell和GenWithLossCell也要修改,同理,TrainOneStepCell也是。主要的改变就是输入加入label,相应的地方做出修改就可,没有什么特别要说的。
class DisWithLossCell(nn.Cell):
def __init__(self, netG, netD, loss_fn, auto_prefix=True):
super(DisWithLossCell, self).__init__(auto_prefix=auto_prefix)
self.netG = netG
self.netD = netD
self.loss_fn = loss_fn
def construct(self, real_data, latent_code, label):
real_out = self.netD(real_data, label)
real_loss = self.loss_fn(real_out, F.ones_like(real_out))
fake_data = self.netG(latent_code, label)
fake_out = self.netD(fake_data, label)
fake_loss = self.loss_fn(fake_out, F.zeros_like(fake_out))
loss_D = real_loss + fake_loss
return loss_D
class GenWithLossCell(nn.Cell):
def __init__(self, netG, netD, loss_fn, auto_prefix=True):
super(GenWithLossCell, self).__init__(auto_prefix=auto_prefix)
self.netG = netG
self.netD = netD
self.loss_fn = loss_fn
def construct(self, latent_code, label):
fake_data = self.netG(latent_code, label)
fake_out = self.netD(fake_data, label)
loss_G = self.loss_fn(fake_out, F.ones_like(fake_out))
return loss_G
class TrainOneStepCell(nn.Cell):
def __init__(self,
netG,
netD,
optimizerG: nn.Optimizer,
optimizerD: nn.Optimizer,
sens=1.0,
auto_prefix=True):
super(TrainOneStepCell, self).__init__(auto_prefix=auto_prefix)
self.netG = netG
self.netG.set_grad()
self.netG.add_flags(defer_inline=True)
self.netD = netD
self.netD.set_grad()
self.netD.add_flags(defer_inline=True)
self.weights_G = optimizerG.parameters
self.optimizerG = optimizerG
self.weights_D = optimizerD.parameters
self.optimizerD = optimizerD
self.grad = C.GradOperation(get_by_list=True, sens_param=True)
self.sens = sens
self.reducer_flag = False
self.grad_reducer_G = F.identity
self.grad_reducer_D = F.identity
self.parallel_mode = _get_parallel_mode()
if self.parallel_mode in (ParallelMode.DATA_PARALLEL,
ParallelMode.HYBRID_PARALLEL):
self.reducer_flag = True
if self.reducer_flag:
mean = _get_gradients_mean()
degree = _get_device_num()
self.grad_reducer_G = DistributedGradReducer(
self.weights_G, mean, degree)
self.grad_reducer_D = DistributedGradReducer(
self.weights_D, mean, degree)
def trainD(self, real_data, latent_code, label, loss, loss_net, grad,
optimizer, weights, grad_reducer):
sens = P.Fill()(P.DType()(loss), P.Shape()(loss), self.sens)
grads = grad(loss_net, weights)(real_data, latent_code, label, sens)
grads = grad_reducer(grads)
return F.depend(loss, optimizer(grads))
def trainG(self, latent_code, label, loss, loss_net, grad, optimizer,
weights, grad_reducer):
sens = P.Fill()(P.DType()(loss), P.Shape()(loss), self.sens)
grads = grad(loss_net, weights)(latent_code, label, sens)
grads = grad_reducer(grads)
return F.depend(loss, optimizer(grads))
def construct(self, real_data, latent_code, label):
loss_D = self.netD(real_data, latent_code, label)
loss_G = self.netG(latent_code, label)
d_out = self.trainD(real_data, latent_code, label, loss_D, self.netD,
self.grad, self.optimizerD, self.weights_D,
self.grad_reducer_D)
g_out = self.trainG(latent_code, label, loss_G, self.netG, self.grad,
self.optimizerG, self.weights_G,
self.grad_reducer_G)
return d_out, g_out
接下来就是训练的部分了,和之前的几乎一样。每训练一个epoch,我都进行一次测试,生成4列0到9。从结果可以看到,通过控制输入的标签y,可以得到想要的数字。
def create_dataset(data_path,
flatten_size,
batch_size,
repeat_size=1,
num_parallel_workers=1):
mnist_ds = ds.MnistDataset(data_path)
type_cast_op = CT.TypeCast(mstype.float32)
onehot_op = CT.OneHot(num_classes=10)
mnist_ds = mnist_ds.map(input_columns="label",
operations=onehot_op,
num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(input_columns="label",
operations=type_cast_op,
num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(input_columns="image",
operations=lambda x:
((x - 127.5) / 127.5).astype("float32"),
num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(input_columns="image",
operations=lambda x: (x.reshape((flatten_size, ))),
num_parallel_workers=num_parallel_workers)
buffer_size = 10000
mnist_ds = mnist_ds.shuffle(buffer_size=buffer_size)
mnist_ds = mnist_ds.batch(batch_size, drop_remainder=True)
mnist_ds = mnist_ds.repeat(repeat_size)
return mnist_ds
def one_hot(num_classes=10, arr=[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]):
return np.eye(num_classes)[arr]
context.set_context(mode=context.GRAPH_MODE, device_target="GPU")
batch_size = 128
input_dim = 100
epochs = 100
lr = 0.001
ds = create_dataset(os.path.join("./data/MNIST_Data", "train"),
flatten_size=28 * 28,
batch_size=batch_size,
num_parallel_workers=2)
netG = Generator(input_dim, 28 * 28)
netD = Discriminator(28 * 28)
loss = SigmoidCrossEntropyWithLogits()
netG_with_loss = GenWithLossCell(netG, netD, loss)
netD_with_loss = DisWithLossCell(netG, netD, loss)
optimizerG = nn.Adam(netG.trainable_params(), lr)
optimizerD = nn.Adam(netD.trainable_params(), lr)
net_train = TrainOneStepCell(netG_with_loss, netD_with_loss, optimizerG,
optimizerD)
dataset_helper = DatasetHelper(ds, epoch_num=epochs, dataset_sink_mode=True)
net_train = connect_network_with_dataset(net_train, dataset_helper)
netG.set_train()
netD.set_train()
for epoch in range(epochs):
step = 1
for data in dataset_helper:
imgs = data[0]
label = data[1]
latent_code = Tensor(np.random.normal(size=(batch_size, input_dim)),
dtype=mstype.float32)
dout, gout = net_train(imgs, latent_code, label)
if step % 100 == 0:
print(
"epoch {} step {}, d_loss is {:.4f}, g_loss is {:.4f}".format(
epoch, step, dout.asnumpy(), gout.asnumpy()))
step += 1
for digit in range(10):
for i in range(4):
latent_code = Tensor(np.random.normal(size=(1, input_dim)),
dtype=mstype.float32)
label = Tensor(one_hot(arr=[digit]), dtype=mstype.float32)
gen_imgs = netG(latent_code, label).asnumpy()
gen_imgs = gen_imgs.reshape((28, 28))
plt.subplot(10, 4, digit * 4 + i + 1)
plt.imshow(gen_imgs * 127.5 + 127.5, cmap="gray")
plt.axis("off")
plt.savefig("./images/{}.jpg".format(epoch))

乍一看,效果还行。如果将基本的网络结构换成DCGAN,效果将会更好,有兴趣的可以去试一下。
关于Mindspore实现GAN的教程到这里就暂时结束了(只是暂时,考虑后续继续实现别的GAN)。接下来有可能会继续实现一些有趣的项目,比如pix2pix,DQN玩flappy bird,神经风格迁移等,慢慢地丰富MindSpore的生态吧。
最近事情有点多,不知道什么时候才能开始。原计划这三个GAN是一周完成的,结果嘛。。。不谈了。。。
三个教程的代码可以从这儿得到:mindpore实现gan。
最后求个star~~~谢谢。