【语音识别】高斯混合模型(GMM)说话人识别【含Matlab源码 574期】
⛄一、高斯混合模型简介
GMM基本框架
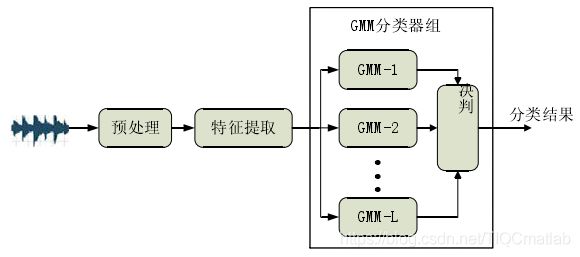
类似的还有GMM-UBM(Universal background model)算法,其与GMM的区别在于:对L类整体样本训练一个大的GMM,而不像GMM对每一类训练一个GMM模型。SVM的话MFCC作为特征,每一帧作为一个样本,可以借助VAD删除无效音频段,直接训练分类。近年来也有利用稀疏表达的方法:

⛄二、部分源代码
function mix=gmm_init(ncentres,data,kiter,covar_type)
%% 输入:
% ncentres:混合模型数目
% train_data:训练数据
% kiter:kmeans的迭代次数
%% 输出:
% mix:gmm的初始参数集合
[dim,data_sz]=size(data’);
mix.priors=ones(1,ncentres)./ncentres;
mix.centres=randn(ncentres,dim);
switch covar_type
case ‘diag’
% Store diagonals of covariance matrices as rows in a matrix
mix.covars=ones(ncentres,dim);
case ‘full’
% Store covariance matrices in a row vector of matrices
mix.covars=repmat(eye(dim),[1 1 ncentres]);
otherwise
error(['Unknown covariance type ', mix.covar_type]);
end
% Arbitrary width used if variance collapses to zero: make it ‘large’ so
% that centre is responsible for a reasonable number of points.
GMM_WIDTH=1.0;
%kmeans算法
% [mix.centres,options,post]=k_means(mix.centres,data);
[mix.centres,post]=k_means(mix.centres,data,kiter);
% Set priors depending on number of points in each cluster
cluster_sizes = max(sum(post,1),1); % Make sure that no prior is zero
mix.priors = cluster_sizes/sum(cluster_sizes); % Normalise priors
switch covar_type
case ‘diag’
for j=1:ncentres
% Pick out data points belonging to this centre
c=data(find(post(:,j));
diffs=c-(ones(size(c,1),1)*mix.centres(j,:));
mix.covars(j,:)=sum((diffs.diffs),1)/size(c,1);
% Replace small entries by GMM_WIDTH value
mix.covars(j,:)=mix.covars(j,:)+GMM_WIDTH.(mix.covars(j,:)
case ‘full’
for j=1:ncentres
% Pick out data points belonging to this centre
c=data(find(post(:,j));
diffs=c-(ones(size(c,1),1)*mix.centres(j,:));
mix.covars(:,:,j)=(diffs’diffs)/(size(c,1)+eps);
% Add GMM_WIDTHIdentity to rank-deficient covariance matrices
if rank(mix.covars(:,:,j))
end
end
otherwise
error(['Unknown covariance type ', mix.covar_type]);
end
mix.ncentres=ncentres;
mix.covar_type=covar_type;
%=============================================================
function [centres,post]=k_means(centres,data,kiter)
[dim,data_sz]=size(data’);
ncentres=size(centres,1); %簇的数目
[ignore,perm]=sort(rand(1,data_sz)); %产生任意顺序的随机数
perm = perm(1:ncentres); %取前ncentres个作为初始簇中心的序号
centres=data(perm,:); %指定初始中心点
id=eye(ncentres); %Matrix to make unit vectors easy to construct
for n=1:kiter
% Save old centres to check for termination
old_centres=centres; %存储旧的中心,便于计算终止条件
% Calculate posteriors based on existing centres
d2=(ones(ncentres,1)sum((data.^2)‘,1))’+…
ones(data_sz,1) sum((centres.^2)‘,1)-2.(data(centres’)); %计算距离
% Assign each point to nearest centre
[minvals, index]=min(d2’, [], 1);
post=id(index,:);
num_points = sum(post, 1);
% Adjust the centres based on new posteriors
for j = 1:ncentres
if (num_points(j) > 0)
centres(j,:) = sum(data(find(post(:,j)), 1)/num_points(j);
end
end
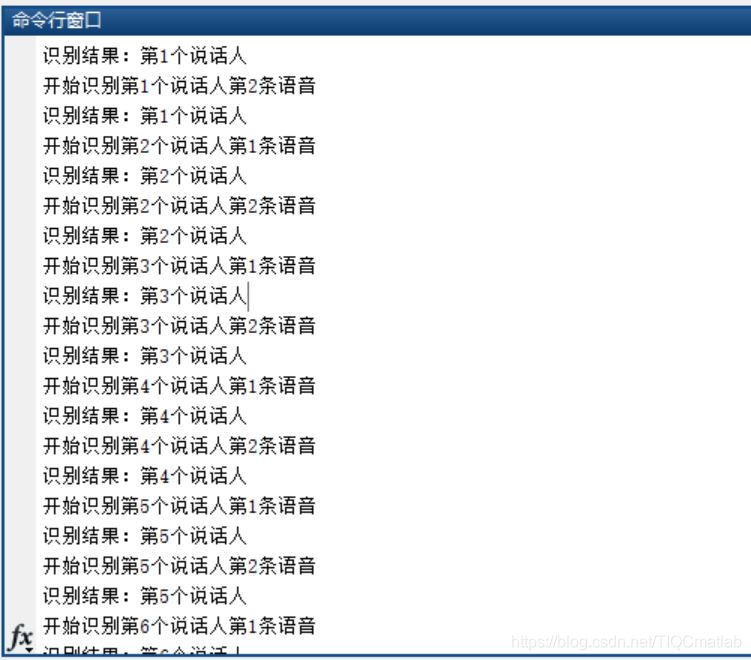
## ⛄三、运行结果
## ⛄四、matlab版本及参考文献
**1 matlab版本**
2014a
**2 参考文献**
[1]韩纪庆,张磊,郑铁然.语音信号处理(第3版)[M].清华大学出版社,2019.
[2]柳若边.深度学习:语音识别技术实践[M].清华大学出版社,2019.
**3 备注**
简介此部分摘自互联网,仅供参考,若侵权,联系删除