coop:Learning to Prompt for Vision-Language Models
论文链接 https://arxiv.org/pdf/2109.01134v1.pdf 源码链接https://github.com/KaiyangZhou/CoOp
https://arxiv.org/pdf/2109.01134v1.pdf 源码链接https://github.com/KaiyangZhou/CoOp
-
摘要
像CLIP这样的大型预训练视觉语言模型在学习表征方面显示出了巨大的潜力,这些表征可在广泛的下游任务中迁移。与传统的基于离散标签的表示学习不同,视觉语言的预训练将图像和文本对齐在一个共同的特征空间中,通过prompt将zero-shot转移到任何下游任务,即从描述感兴趣类的自然语言合成分类权值。在这项工作中,我们表明,部署的一个主要挑战这样的模型在实践中prompt工程,这需要专业知识,非常耗时,需要花大量的时间在单词优化(tuning)自措辞的微小变化,可能对性能产生巨大影响。受到自然语言处理(NLP)快速学习研究的最新进展的启发,我们提出了上下文优化(CoOp),这是一种简单的方法,专门用于将类似clip的视觉语言模型用于下游图像识别。具体来说,CoOp使用可学习向量对提示者的语境词进行建模,同时保持整个预训练参数不变。为了处理不同的图像识别任务,我们提供了两种CoOp实现:统一上下文和类特定上下文。通过大量的实验数据集(11个),我们证明Coop需要只有one或two-shots击败手工提示创建合适的margin,使用更多的shots时能够获得显著改善,例如,16次平均涨幅约15%(最高达到45%以上)。尽管是一种基于学习的方法,但与使用手工提示的zero-shot模型相比,CoOp获得了极佳的领域泛化性能。
一、Introduction
构建最先进的视觉识别系统的一种常见方法是训练视觉模型来预测使用离散标签的一组固定的对象类别(He et al., 2016;Dosovitskiy等,2021)。从技术角度来看,这是通过匹配图像特征(由ResNet (He et al., 2016)或ViT (Dosovitskiy et al., 2021)等视觉模型产生的)与一组固定的权重来实现的,这些权重被视为视觉概念,并随机初始化。尽管训练类别通常具有文本形式,如“金鱼”或“厕纸”,但它们将被转换为离散标签,以简化交叉熵损失的计算,使封装在文本中的语义在很大程度上未被利用。这种学习模式将视觉识别系统限制在封闭的视觉概念上,使得它们无法处理新的类别,因为学习新的分类器需要额外的数据。
最近,CLIP (Radford et al., 2021)和ALIGN (Jia et al., 2021)等视觉语言前训练已经成为视觉表征学习的一种有前途的替代方法。其主要思想是使用两个独立的编码器来对齐图像和原始文本——一个用于每个模态。例如,CLIP和ALIGN都将学习目标表述为对比损失,将图像及其文本描述组合在一起,同时将特征空间中不匹配的对排除在外。通过大规模的预训练,模型可以学习不同的视觉概念,并且可以很容易地通过提示转移到任何下游任务(Radford等人,2021;Jia等人,2021年;F¨urst等人,2021年;Li等人,2021年;辛格等人,2021年;Yuan等,2021)。特别地,对于任何新的分类任务,可以先将描述与任务相关的类别的句子给文本编码器,合成分类权重,然后与图像编码器产生的图像特征进行比较。
我们观察到,对于预先训练的视觉语言模型,文本输入,即prompt,在下游数据集中扮演着关键的角色。然而,识别正确的提示是一项艰巨的任务,这通常需要大量的时间进行文字调优——措辞上的微小变化可能会对性能产生巨大的影响。例如,对于Caltech101(图1(a),第2和第3个提示符),在类令牌之前添加“a”可以带来超过5%的准确性提高。此外,即时工程还需要对任务的先验知识,最好是语言模型的潜在机制。图1(b-d)举例说明了这一点,其中添加与任务相关的上下文可以导致显著的改进,例如,对于Flowers102,“flower”,对于DTD,“texture”和对于EuroSAT,“satellite”。调整句子结构可以带来进一步的改进,例如,将“a type of flower”放在Flowers102的类令牌之后,在DTD的上下文中只保留“texture”,以及在EuroSAT的“satellite photo”之前添加“centered”。然而,即使进行了广泛的调优,所得到的提示也不能保证对这些下游任务是最优的。
受近期自然语言处理(NLP)中的即时学习研究的启发(Shin等人,2020;Jiang et al., 2020;Zhong等人,2021),我们提出了一种简单的方法,称为上下文优化(CoOp)1,以自动化提示工程,特别是针对预训练的视觉语言模型。具体来说,CoOp用可学习向量对提示符的上下文单词进行建模,这些向量可以用随机值或预先训练的单词嵌入来初始化(见图2)。提供了两种实现来处理不同性质的任务:一种是基于统一上下文,它与所有类共享相同的上下文,并在大多数类别上运行良好;而另一种则基于特定于类的上下文,它为每个类学习一组特定的上下文标记,并被发现更适合于一些细粒度的类别。在训练过程中,我们简单地使用相对于可学习上下文向量的交叉熵损失最小化预测误差,同时保持整个预训练参数不变。梯度可以通过文本编码器反向传播,提取出与学习任务相关的上下文参数中编码的丰富知识。
为了证明CoOp的有效性,我们在11个数据集上进行了基准测试,这些数据集涵盖了一系列不同的视觉识别任务,包括对一般物体、场景、动作和细粒度类别的分类,以及识别纹理和卫星图像等特殊任务。结果表明,CoOp有效地将预训练的视觉语言模型转化为数据效率高的视觉学习者,只需一两个shot,就能比手工制作的提示更有优势。使用更多的镜头可以进一步提高表现,例如,使用16次镜头,与手工提示的平均差距约为15%,最高达到45%以上。CoOp也优于线性探测模型,后者被称为强少拍学习基线(Tian et al., 2020)。此外,尽管CoOp是一种基于学习的方法,但它对领域转移的鲁棒性要比零镜头模型(使用手动提示)强得多。
综上所述,我们做出了以下贡献:
1. 我们对最近提出的视觉语言模型在下游应用中的适应性进行了及时的研究,并确定了一个与部署效率相关的关键问题,即prompt工程。
2. 为了使预先训练的视觉语言模型的prompt工程自动化,我们提出了一种基于连续提示学习的简单方法,并提供了两种可处理不同识别任务的实现方法。
3.我们首次表明,对于大型视觉语言模型,提出的基于提示学习的方法在领域转移下的下游迁移学习性能和鲁棒性方面优于手工提示和线性探测( linear probe)模型。
我们希望这些发现一起开源代码可以激励和促进未来研究有效的适应方法对于大型视觉语言模型新兴主题与民主化的基础模型(Bommasani et al ., 2021)也就是说,使他们更容易和更便宜的适应更广泛的社区。
二、 Related Work
2.1 Vision-Language Models
视觉语言模型最近在学习一般视觉表示和允许zero-shot通过prompt转移到各种下游分类任务方面显示了巨大的潜力(Radford等人,2021;Jia等人,2021年;Zhang et al., 2020;辛格等人,2021年;Yuan等,2021)。
据我们所知,视觉语言学习的近期发展,特别是CLIP (Radford等人,2021)和ALIGN (Jia等人,2021),主要受以下三个领域的进展驱动:i)基于transformer的文本表示学习(Vaswani et al., 2017), ii)大-小批量对比表示学习(Chen et al., 2020;他等人,2020年;H´enaff等人,2020),和iii)网络规模的训练数据集- clip受益于4亿策划的图像-文本对,而ALIGN利用18亿噪声图像-文本对。
将图像和文本映射到公共嵌入空间的想法早在十年前就已经被研究过了(Socher等人,2013;Frome等人,2013年;Elhoseiny等人,2013),但采用了截然不同的技术。对于文本特征提取,早期的工作主要是利用预先训练好的词向量(Socher et al., 2013;Frome等人,2013)或手工制作的TF-IDF特征(Elhoseiny等人,2013;雷巴等,2015)。匹配图像和文本特征被表述为度量学习(Frome et al., 2013)、多标签分类(Joulin et al., 2016;Gomez等人,2017),n-gram语言学习(Li等人,2017),以及最近提出的字幕(Desai和Johnson, 2021)。
我们的工作与视觉语言模型的最新研究是正交的,旨在促进这些模型在下游数据集的适应和部署。
2.2 Prompt Learning in NLP
针对大型预训练语言模型的知识探索,Petroni等人(2019)正式定义为“填空”完形填空测试,最近引发了对NLP快速学习研究的兴趣(Shin等人,2020;Jiang et al., 2020;李和梁,2021年;Zhong等人,2021年;莱斯特等人,2021年;高等人,2020;刘等,2021b)。
知识探究的基本思想是诱导经过训练的语言模型在给定完形提示下生成答案,这对许多下游任务(如情感分析)有帮助。Jiang等人(2020)提出通过文本挖掘和释义生成候选提示,并识别出具有最高训练准确性的最佳提示。Shin等人(2020)引入了一种基于梯度的方法,该方法在标签可能性中搜索梯度变化最大的令牌。
与我们的工作最相关的是持续快速学习方法(Zhong et al., 2021;李和梁,2021年;Lester等人,2021)优化单词嵌入空间中的连续向量。与搜索离散标记相比,这种方法的缺点是缺乏一种清晰的方式来可视化向量学习到的“单词”。我们建议读者参考Liu等人(2021a)对自然语言处理中的快速学习进行全面的调查。
值得注意的是,我们是第一个将快速学习应用于计算机视觉中的大型视觉语言模型的适应的人——我们认为这是民主化基础模型的一个重要课题(Bommasani等人,并且证明了快速学习不仅在迁移学习性能方面给计算机视觉任务带来了显著的改进,而且还产生了能够处理领域转移的鲁棒模型
三、Methodology
3.1 Vision-Language Pre-training
我们简要介绍了视觉语言前训练,特别关注CLIP (Radford et al., 2021)。我们的方法适用于更广泛的类似clip的视觉语言模型。
模型:CLIP由两个编码器组成,一个用于图像,另一个用于文本。图像编码器的目标是将高维图像映射到低维嵌入空间。图像编码器的结构可以采用CNN的形式,如ResNet-50 (He et al., 2016)或ViT (Dosovitskiy et al., 2021)。另一方面,文本编码器构建在Transformer之上(Vaswani等人,2017),旨在从自然语言生成文本表示。
具体来说,给定一个单词(标记)序列,例如“一只狗的照片”,CLIP首先将每个标记(包括标点符号)转换为小写字节对编码(BPE)表示(Sennrich等人,2016),这本质上是一个唯一的数字ID。CLIP中的词汇量是49152。为了方便小批处理,每个文本序列都包含了[SOS]和[EOS]标记,并以77为固定长度。之后,将id映射为512-D单词嵌入向量,然后将其传递给Transformer。最后,对[EOS]令牌位置的特征进行层归一化处理,并由线性投影层进一步处理。
Training :CLIP被训练为分别对图像和文本学习到的两个嵌入空间进行对齐。具体来说,学习目标被表述为一种对比损失。给定一批图像-文本对,CLIP使匹配对的余弦相似度最大化,同时使所有其他不匹配对的余弦相似度最小化。为了学习更多可转移到下游任务的不同视觉概念,CLIP的团队收集了一个由4亿个图像文本对组成的大型训练数据集。
Zero-Shot Inference:由于CLIP是预先训练来预测图像是否匹配文本描述,它自然适合零镜头识别。这是通过将图像特征与文本编码器合成的分类权重进行比较来实现的,文本编码器将指定感兴趣的类作为输入文本描述。形式上,设f为图像编码器对图像x提取的图像特征,{wi}Ki=1为文本编码器生成的一组权重向量。K表示类的数量,每个wi都是从提示符派生而来,提示符的形式可能是“一个[CLASS]的照片”。,其中类令牌被特定的类名代替,例如“猫”、“狗”或“车”。然后计算预测概率为
其中τ为CLIP学习到的温度参数,<·,·>为余弦相似度。
与封闭集视觉概念从随机向量学习的传统分类器学习方法相比,视觉语言前训练允许开放集视觉概念通过高容量文本编码器进行探索,从而形成更广阔的语义空间,进而使学习到的表示更易于转移到下游任务。

3.2 Context Optimization
我们提出了上下文优化(CoOp),通过使用从数据中端到端学习的连续向量对上下文词进行建模,从而避免了手动的提示调优。概览如图所示。下面我们将提供几种不同的实现。
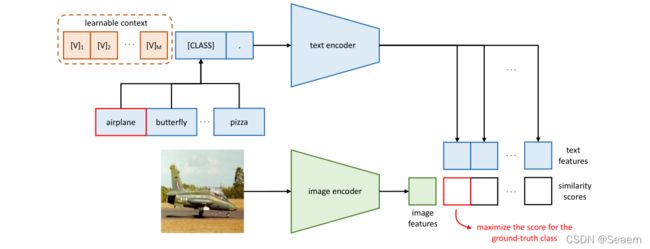
上下文优化概述(CoOp)。其主要思想是使用一组可学习向量对提示的上下文进行建模,这些向量可以通过最小化分类损失来优化。提出了两种设计:一种是统一上下文,它与所有类共享相同的上下文向量;(在需要预测的class前后都插入learnable context,这可以增加prompt的灵活性。)另一个是特定于类的上下文,它为每个类学习一组特定的上下文向量。(所有类别的prompt参数独立,在一些细粒度分类任务中效果更好。)
Unified Context:我们首先介绍统一上下文版本,它与所有类共享相同的上下文。具体来说,给文本编码器g(·)的提示符设计为如下形式:
其中每个[V]m (m∈{1,…, M})是与单词嵌入具有相同维数的向量(即CLIP为512),M是指定上下文标记数的超参数。
通过将提示符t转发给文本编码器g(·),可以得到表示视觉概念的分类权值向量。预测概率计算为
其中,每个提示符ti中的类标记被第i个类名对应的单词嵌入向量替换。
除了将类标记放在序列的末尾(如式(2)所示)外,我们还可以将它放在中间(如式)
这增加了学习的灵活性——从理论上讲,提示符可以用补充描述填充后面的单元格,或者使用终止信号(如句号)截断前面的句子。
Class-Specific Context:另一种选择是设计类特定上下文(CSC),其中上下文向量独立于每个类,即[V]i1[V]i2…[V]iM 6= [V]j 1[V]j 2 . .。[V]j M for i 6= j and i, j∈{1,…K}。作为统一上下文的替代方案,我们发现CSC对于一些细粒度的分类任务特别有用。
Training: 采用基于交叉熵的方法最小化标准分类损失,将梯度反向传播至文本编码器g(·),利用参数中编码的丰富知识来优化上下文。连续表示的设计也允许在词嵌入空间中进行充分的探索,这有利于任务相关上下文的学习。
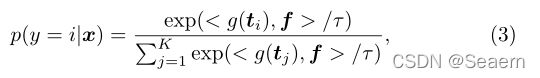
3.3 Discussion
我们的方法专门针对最近提出的大型视觉语言模型(如CLIP)的适应新出现的问题(Radford et al., 2021)。我们的方法与NLP中针对语言模型开发的快速学习方法(如GPT-3 (Brown et al., 2020))有一些区别。首先,类似clip的模型和语言模型的主干架构明显不同——前者采用视觉和文本数据作为输入,并产生用于图像识别的对齐分数,而后者只处理文本数据。第二,训练前的目标是不同的:对比学习和自回归学习。这将导致不同的模型行为,因此需要不同的模块设计。
4 Experiments
4.1 Few-Shot Learning
Datasets: 我们选择了11个公开可用的图像分类数据集在CLIP中使用:ImageNet (Deng et al., 2009), Caltech101 (Fei-Fei et al., 2004), OxfordPets (Parkhi et al., 2012), StanfordCars (Krause et al., 2013), Flowers102 (Nilsback and Zisserman, 2008), Food101 (Bossard et al., 2014), FGVCAircraft (Maji et al., 2013), SUN397 (Xiao et al., 2010), DTD (Cimpoi et al., 2014), EuroSAT (Helber et al., 2014),和UCF101 (Soomro et al., 2012)(统计数据见附录A)。这些数据集构成了一个全面的基准,涵盖了一系列不同的视觉任务,包括对一般物体、场景、动作和细粒度类别的分类,以及识别纹理和卫星图像等特殊任务。我们遵循CLIP (Radford et al., 2021)中采用的few-shot评估协议,分别使用1、2、4、8和16个shot进行训练,并在完整的测试集中部署模型。报告三次运行的平均结果以作比较。
Training Details:CoOp有四个版本:将类令牌定位在末尾或中间;统一上下文vs CSC。除非另有说明,ResNet-50 (He et al., 2016)被用作图像编码器的主干,上下文令牌的数量M被设置为16。对其他设计选择的调查将在第4.3节中讨论。所有模型都建立在CLIP的开放源代码之上通过从标准偏差等于0.02的零均值高斯分布中提取cop的上下文向量进行随机初始化。使用SGD进行训练,初始学习率为0.002,由余弦退火法则衰减。对于16/8次shot,最大历元设置为200,对于4/2次射击,最大历元设置为100,对于1次射击,最大历元设置为50(除了ImageNet,最大历元设置为50)。为了缓和早期训练迭代中观察到的爆炸性梯度,我们使用了热身技巧,在第一个阶段将学习率固定为1e−5。
Baseline Methods:我们将CoOp与两种基线方法进行比较。第一个是零镜头clip(zero-shot CLIP),它基于手工制作的prompt。我们遵循Radford等人(2021)提出的快速工程指导方针。对于一般的对象和场景,“一张[CLASS]的照片。“采用。对于细粒度的类别,任务相关的上下文被添加,比如为OxfordPets添加“一种宠物”,为Food101添加“一种食物”。当涉及到诸如识别DTD中的纹理之类的专门化任务时,提示符被定制为“[CLASS]纹理”。,类名是形容词,比如“气泡的”和“虚线的”。详见附录A。第二个基线是线性探测模型。雷德福et al .(2021)指出的,最近的一项研究few-shot学习(田et al ., 2020),训练一个线性分类器上的优质pre-trained模型的特性(如夹)可以很容易地实现性能,与先进的few-shot学习方法,通常更为复杂。我们采用与Radford et al.(2021)相同的训练方法来训练线性探测模型。
Comparison with Hand-Crafted Prompts:图3总结了结果。我们的默认模型是CLIP+CoOp,类令牌位于最后。这两种定位类令牌的不同方式实现了类似的性能,因为它们的曲线高度重叠。从左上角显示的平均表现,我们观察到CLIP+CoOp是一个强大的few-shot学习者,平均只需要两次shot就可以获得一个不错的margin超过零射的CLIP。如果有16次训练,CoOp带来的平均差距可以进一步增加到15%左右.
图4列出了CoOp在16次拍摄中获得的绝对改进,而不是手工制作的提示。在专门的任务上,即EuroSAT和DTD,可以观察到巨大的改进,性能分别提高了45%和20%以上。在大多数细粒度数据集(包括Flowers102、StanfordCars和FGVCAircraft)以及场景和动作识别数据集(即SUN397和UCF101)上,性能也有显著的提升(超过10%)。由于ImageNet是一个包含1000个类的具有挑战性的数据集,4.77%的改进也值得注意。相比之下,OxfordPets和Food101这两个细粒度数据集的增长就不那么吸引人了。通过深入研究图3中这两个数据集的CLIP+CoOp曲线,我们发现即使使用了更多的镜头,性能改进的势头也有所减弱,这似乎是一个过拟合的问题。一个潜在的解决方案是施加更高的正则化,如增加权值衰减。尽管如此,总体结果足以证明CoOp能够以高效的方式学习与任务相关的提示。
Comparison with Linear Probe CLIP:在整体性能方面(图3,左上角),CLIP+CoOp显示出明显优于线性探针模型。后者需要平均4次以上的射击才能达到零射击的效果,而CoOp在4次射击时的平均增益已经令人印象深刻了。同样明显的是,在极端低数据的情况下,如一个或两个镜头的差距要大得多,这表明CoOp比从零开始学习线性分类器的少镜头学习更有效。我们也观察到线性探针模型与clip+coop的两个专门的任务(DTD & EuroSAT)以及一些有细密纹理的数据集(Flowers102 & FGVCAircraft) -这是不太令人感到意外,因为作为pre-trained clip空间已被证明是强大的,使线性探测模型一个强大的竞争对手。尽管如此,CoOp的CSC版本在上述数据集上可以击败线性探针CLIP,而且,当更多的镜头可用时,显示出更好的潜力。结果表明,与线性探测模型相比,CoOp模型在领域泛化方面具有更强的性能。
Unified vs Class-Specific Context:一般来说,使用统一上下文可以带来更好的性能。关于何时应用CSC,何时不应用,我们有以下建议。对于一般的对象(ImageNet & Caltech101),场景(SUN397)和动作(UCF101),使用统一的上下文显然更好。统一上下文在一些细粒度的数据集上也能更好地工作,包括OxfordPets和Food101,但在其他数据集上,如StanfordCars, Flowers102和FGVCAircraft, CSC版本是首选。CSC在两个专门的任务,DTD和EuroSAT上也有更好的性能,特别是在16次射击时。然而,在具有挑战性的低数据场景(少于8个镜头)中,CSC大多表现不佳,这是有道理的,因为CSC比统一上下文有更多的参数,需要更多的数据进行训练。
4.2 Domain Generalization
正如最近的研究(Taori等人,2020年;周等,2021)。相反,zero-shot CLIP不与特定的数据分布绑定,对分布变化具有很强的鲁棒性(Radford等人,2021年)。在本节中,我们的目标是揭示CoOp对分布转移的鲁棒性,与零镜头CLIP和线性探针模型相比。
Datasets:源数据集是ImageNet。目标数据集是ImageNetV2 (Recht等人,2019),ImageNet- sketch (Wang等人,2019),ImageNet- a (Hendrycks等人,2021b)和ImageNetR (Hendrycks等人,2021a),所有这些都有与ImageNet兼容的类名,允许无缝传输CoOp学习的提示。ImageNetV2是一个复制的测试集,使用不同的数据源,同时遵循ImageNet的数据收集过程。ImageNet- sketch包含了属于相同的1000个ImageNet类的草图图像。ImageNet- a和-R都包含了从ImageNet的1000个类的一个子集派生出来的200个类。前者包含现实世界中经过对抗过滤的图像,导致当前的ImageNet分类器产生较低的结果,而后者的特点是ImageNet类的再现具有多种图像风格,如绘画、卡通和雕塑。
Results:表1总结了结果(包括各种视觉骨干)。令人惊讶的是,尽管暴露在源数据集上,CLIP+CoOp通常表现出比零拍CLIP更强的鲁棒性。这表明学习过的提示也是可泛化的。此外,有趣的是,使用更少的上下文标记会带来更好的鲁棒性。相比之下,线性探测模型在这些目标数据集上得到的结果差得多,暴露出其在领域泛化方面的弱点。
4.3 Further Analysis
Context Length:应该使用多少上下文标记?拥有更多上下文标记是否更好?4.2节的结果表明,更短的上下文长度有利于域泛化。在这里,我们研究源数据集的超参数。具体来说,我们通过将上下文长度从4到8到16的变化,对11个数据集重复实验。平均结果如图5(a)所示,这表明拥有更多的上下文令牌会带来更好的性能,并且将类令牌放置在中间会随着上下文长度的增加获得更多的动量。综上所述,没有选择完美上下文长度的黄金规则,因为需要在性能和健壮性之间平衡分布转移。
Vision Backbones:图5(b)总结了使用覆盖cnn和vit的各种视觉主干的11个数据集上的结果。结果是预期的:骨干网越先进,性能越好。在所有架构中,CoOp和手工提示符之间的差距都非常大。
Comparison with Prompt Ensembling:CLIP的作者(Radford et al., 2021)建议,通过对使用不同手工提示生成的多个零拍分类器进行集成,可以获得额外的改进,例如“大型[CLASS]的照片”。,“一张糟糕的[班级]照片。”和“折纸”。,分别反映出一幅图像的不同尺度、不同视角和不同抽象。我们很想知道,与提示合奏相比,CoOp学习的提示符是否仍然具有优势。为了进行公平的比较,我们使用Radford等人(2021)的选择提示来构建集成分类器,这些提示已经在ImageNet上进行了广泛的调优。表2显示了两者的对比,证明了CoOp的优越性。鉴于即时合奏的潜力,未来的工作可以从合奏的角度探讨如何改善合作。
Initialization:我们比较了随机初始化和手动初始化。后者使用“a的一张照片”的嵌入来初始化11个数据集的上下文向量。为了便于比较,在使用随机初始化时,我们还将上下文长度设置为4。表3建议一个“好的”初始化只会带来很小的改进。虽然进一步调优初始化字可能会有所帮助,但在实践中,我们建议使用简单的随机初始化方法。
Interpreting the Learned Prompts:这很困难,因为上下文向量是在连续空间中优化的。我们采用一种间接的方法,即在词汇表中根据欧几里德距离搜索最接近所学向量的单词。请注意CLIP (Radford et al., 2021)使用BPE表示法(Sennrich et al., 2016)进行标记化,因此词汇表包括经常出现在文本中的子词,如“hu”(包含许多单词,如“拥抱”和“人类”)。表4显示了一些数据集上的搜索结果。我们观察到一些单词与任务有些相关,例如“enjoyed”表示Food101,“fluffy”和“paw”表示OxfordPets,“pretty”表示DTD。但是当把所有最近的单词连接在一起时,提示就没有多大意义了。我们还注意到,在使用手动初始化(比如“a的照片”)时,最接近收敛向量的词大多是用于初始化的词。我们推测,学习到的向量可能编码现有词汇表之外的含义。总的来说,我们无法根据观察得出任何确定的结论,因为使用最接近的单词来解释学习的提示可能是不准确的——向量的语义不一定与最接近的单词相关。