【整理】图像配准( Image Registrition )相关知识
找了各种资料,把自己需要的整理了以下。
图像配准的概念
(1)图像配准是使用某种方法,基于某种评估标准,将一副或多副图片(局部)最优映射到目标图片上的方法。
(2)对于一组图像数据集中的两幅图像,通过寻找一种空间变换把一幅图像映射到另一幅图像,使得两图中对应于空间同一位置的点一一对应起来,从而达到信息融合的目的。
(3)图像配准是使用某种方法,基于某种评估标准,将一副或多副图片(局部)最优映射到目标图片上的方法。通常情况下,它将一副图片(源图像,Moving Image)的坐标映射到另一幅图像(目标图像,Fixed Image)上,得到配准后的图像对(Moved Image)。
在做医学图像分析时 ,经常要将同一患者几幅图像放在一起分析 ,从而得到该患者的多方面的综合信息 ,提高医学诊断和治疗的水平。对几幅不同的图像作定量分析 ,首先要解决这几幅图像的严格对齐问题 ,这就是我们所说的图像的配准。医学图像配准是指对于一幅医学图像寻求一种 (或一系列 )空间变换 ,使它与另一幅医学图像上的对应点达到空间上的一致。 这种一致是指人体上的同一解剖点在两张匹配图像上有相同的空间位置。 配准的结果应使两幅图像上所有的解剖点 ,或至少是所有具有诊断意义的点及手术感兴趣的点都达到匹配。
个人感觉第2个概念更容易理解一些。在医学图像领域,举个例子:下面是两个没有配准的器官。
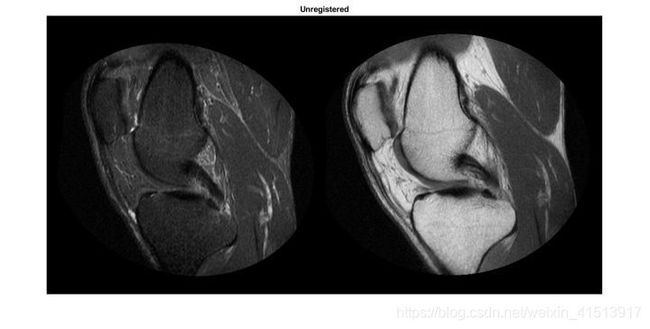
如果直接重合的话:
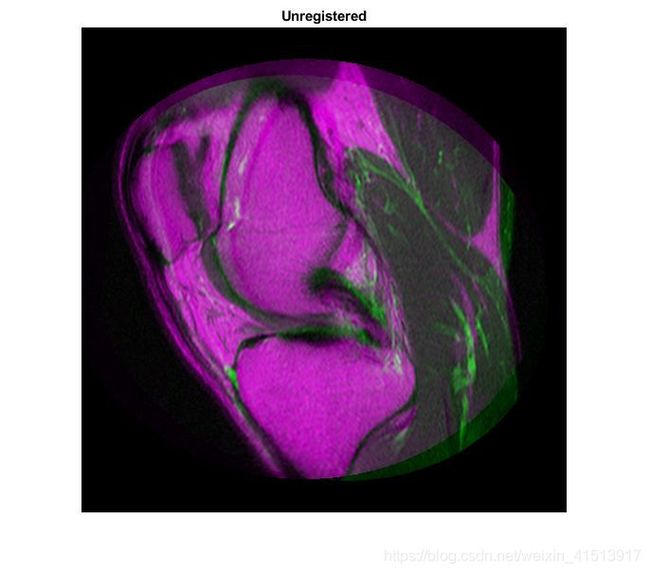
直接重合,很明显会有重影(暂时这个词吧,毕竟我也萌新不知道怎么表述)。在器官的上部尤其地明显。
如果进行了配准:
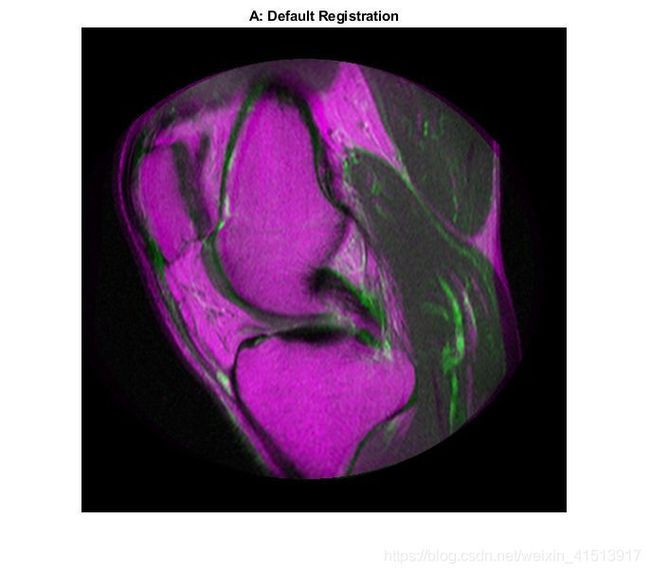
重影的范围就小了很多。 两幅图像上所有的解剖点 ,或至少是所有具有诊断意义的点及手术感兴趣的点都达到匹配。
还有一张图:
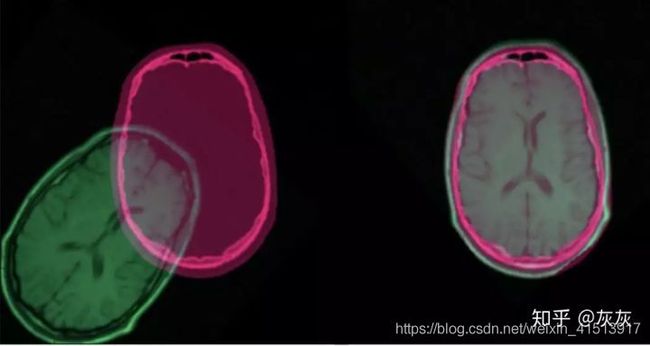
分类
(1)根据图像采集方式分:
- Multi-view Analysis: 多视图配准
同一物体在同一场景 不同视角 下的图像配准。如图像蒙太奇(拼贴),从2D图像重建3D模型等
- Multi-temporal Analysis: 多时相配准
同一物体在同一场景同视角 不同时间 的图像配准。如运动追踪,肿瘤生长情况跟踪等。
- Multi-modal Analysis: 多模配准
由于医学成像设备可以提供关于患者 不同信息不同形式 的图像(计算机断层扫描CT,核磁共振MRI,正电子发射断层成像PET,功能核磁共振fMRI等),所以根据模态又可以划分为单模态和多模态(Multi-modal)。
(2)按配准主体分 Subject of Registration
就同一个病人还是不同病人的了。
以医学图像配准为例,可分为Intrasubject(图像来自于同一病人),Intersubjective(来自不同的病人)和Atlas(病人数据和图谱的配准)三种。
(3)按配准的器官 Object of Registration
那这样看的话就很多的了。 配准物体(头、胸、腹、膝盖)
(4)按图像转换区域 Domain of transformation
分为全局/局部配准。如果需要配准的是整张图片,就是全局配准
(5)按变换性质 Type of transformation
它可以是刚性的(平移,旋转,反射),仿射变换(平移,旋转,缩放,反射,剪切),投影变换或曲线变换。
流程
通常,图像配准技术包括四个方面:变换模型、特征空间、相似性测度、搜索空间和搜索策略。依据这四个特性,图像配准的步骤一般可分为以下五个步骤:
- 根据实际应用场合选取适当的变换模型;
- 选取合适的特征空间,或者是基于灰度的或者是基于特征的;
- 根据变换模型的参数配置以及所选用的特征,确定参数可能变化的范围,并选用最优的搜索策略;
- 应用相似性测度在搜索空间中按照优化准则进行搜索,寻找最大相关点,从而求解出变换模型中的未知参数;
- 将待配准图像按照变换模型逐像素一一对应到参考图像中,实现图像间的匹配。
其中,如何选取合适的特征进行匹配是配准的关键所在。
图像配准质量评估标准(performance measures)
必须有某种方法来评估图像配准的质量,与此同时,针对不同类型的图像需要使用不同评估标准。目前没有一个绝对的金标准(gold standard)可以评估图像配准的质量。
下面仅以医学图像为例,列举两种最经典的评估方法:单模图像配准常使用相关性(Correlation Coefficient, CC)来衡量效果,而多模图像配准常使用互信息(Mutual Information , MI)衡量。
Correlation Coefficient (CC):
对于同一物体由于图像获取条件的差异或物体自身发生的小的改变而产生的图像序列,采用使图像间相似性最大化的原理实现图像间的配准,即通过优化两幅图像间相似性准则来估计变换参数,主要是刚体的平移和旋转。相关性主要限于单模图像配准,特别是对一系列图像进行比较,从中发现由疾病引起的微小改变。
Mutual Information (MI):
由于该方法不需要对两种成像模式中图像强度间关系的性质作任何假设,也不需要对图像作分割或任何预处理,所以被广泛地用于CT/MR、PET/MR等多种配准工作。最大互信息法几乎可以用在任何不同模式图像的配准,特别是当其中一个图像的数据部分缺损时也能得到很好的配准效果。
传统的配准方法
建议看这一篇 https://blog.csdn.net/fairylrt/article/details/38054857
传统的配准方法是一个迭代优化的过程,首先定义一个相似性度量(如:L2范数,互信息),通过对参数变换或非参变换进行不断迭代优化,使得配准后的源图像与目标图像相似度最大。
自21世纪初以来,图像配准主要使用基于特征的方法。
这些方法有三个步骤:关键点检测keypoint detector和特征描述feature descriptor,特征匹配feature mapping,图像变换。简单的说,我们选择两个图像中的感兴趣点,将参考图像(reference image)与感测图像(sensed image)中的等价感兴趣点进行关联,然后变换感测图像使两个图像对齐。

(1)关键点检测
关键点就是感兴趣点,它表示图像中重要或独特的内容(边角,边缘等)。每个关键点由描述符表示,关键点基本特征的特征向量。描述符应该对图像变换(定位,缩放,亮度等)具有鲁棒性。许多算法使用关键点检测和特征描述:
- SIFT^4(Scale-invariant feature transform)是用于关键点检测的原始算法,但它不能免费用于商业用途。SIFT特征描述符对于均匀缩放,方向,亮度变化和对仿射失真不变的部分不会发生变化。
- SURF^5(Speeded Up Robust Features)是一个受SIFT启发的探测器和描述符。它的优点是非常快。它同样是有专利的。
- ORB^6(Oriented FAST and Rotated BRIEF)是一种快速的二进制描述符,它基于 FAST^7(Features from Accelerated Segment Test)关键点检测和 BRIEF^8(Binary robust independent elementary features)描述符的组合。它具有旋转不变性和对噪声的鲁棒性。它由OpenCV实验室开发,是SIFT有效的免费替代品。
- AKAZE^9(Accelerated-KAZE)是KAZE^10快速版本。它为非线性尺度空间^11提供了快速的多尺度特征检测和描述方法,具有缩放和旋转不变性。
有很多种算法,尝试了一下一个AKAZE算法,cv.AKAZE_create()


hhhh,暴露粉籍。
(2)特征匹配
一旦在一对图像中识别出关键点,我们就需要将两个图像中对应的关键点进行关联或“匹配”。其中一种方法是BFMatcher.knnMatch()。这个方法计算每对关键点之间的描述符的距离,并返回每个关键点的k个最佳匹配中的最小距离。

可以看出对应点全部连线了。
(3)图像变换
在匹配至少四对关键点之后,我们就可以将一个图像转换为另一个图像,称为图像变换(image warping)。空间中相同平面的两个图像通过单应性变换(Homographies)进行关联。Homographies是具有8个自由参数的几何变换,由3x3矩阵表示图像的整体变换(与局部变换相反)。因此,为了获得变换后的感测图像,需要计算Homographies矩阵。
- 单应性
图像中的2D点(x,y)(x,y)可以被表示成3D向量的形式(x1,x2,x3)(x1,x2,x3),其中x=x1/x3x=x1/x3,y=x2/x3y=x2/x3。它被叫做点的齐次表达,位于投影平面![]() 上。所谓单应就是发生在投影平面
上。所谓单应就是发生在投影平面![]() 上的点和线可逆的映射。其它叫法包括射影变换、投影变换和平面投影变换等。典型地,可以通过图像之间的特征匹配来估计单应矩阵。
上的点和线可逆的映射。其它叫法包括射影变换、投影变换和平面投影变换等。典型地,可以通过图像之间的特征匹配来估计单应矩阵。
单应变换矩阵是一个3*3的矩阵H。这个变换可以被任意乘上一个非零常数,而不改变变换本身。所以它虽然具有9个元素,但是具有8个自由度。这意味这它里面有8个未知参数待求。
- 为什么9个元素(3*3)却有8个自由度?

其实一共只有8个k待求解。
- 单应性变换
单应性变换其实就是一个平面到另一个平面的变换关系。

如上图所示的平面的两幅图像。红点表示两幅图像中的相同物理点,我们称之为对应点。这里显示了四种不同颜色的四个对应点 - 红色,绿色,黄色和橙色。 一个Homography是一个变换(3×3矩阵),将一个图像中的点映射到另一个图像中的对应点。
有监督学习的配准
(1)标签是什么?
既然是有监督学习,那么他的标签是什么?
两个图像之间变形场。什么是变形场?就是相同像素点,这一对图像相互差了多少,即物体三维/二维空间内的位移矢量的空间分布状况。
(2)如何获取标签?
① 利用传统的经典配准方法进行配准,得到的变形场作为标签;
② 对原始图像进行模拟变形,将原始图像作为固定图像,变形图像作为移动图像,模拟变形场作为标签。
(感觉这里有点像超分辨率重建获取标签 的感觉。超分辨率重建是将一个高分辨率图向下插值到一个低分辨率,将低分辨率作为输入,高分辨率的原图作为标签)
参考
维基百科-图像配准
知乎-图像配准综述
百度百科-图像配准
阅读笔记】深度学习在医学图像分析领域的综述
图像配准:从SIFT到深度学习(含关键点检测等步骤的python-opencv代码)
单应性变换、仿射变换
【个人整理】图像配准综述
CSDN-图像配准简介
图像配准入门