Transformers in Remote Sensing: A Survey
论文链接:https://arxiv.org/pdf/2209.01206v1.pdf
源码: https://github.com/VIROBO-15/Transformer-in-Remote-Sensing
在过去十年中,基于深度学习的算法在遥感图像分析的不同领域得到了广泛的应用。最初在自然语言处理中引入的Transformers的体系结构已经渗透到计算机视觉领域,在这个领域中,自注意力机制被用来代替流行的卷积算子来捕获长距离依赖。受计算机视觉最新进展的启发,遥感界也见证了对各种任务的视觉Transformers的不断探索。本文涵盖了用于遥感分领域不同遥感问题的60多种基于Transformers的最新方法:超高分辨率(VHR)、高光谱(HSI)和合成孔径雷达(SAR)图像。
一、文章概述
CNN的主要组成部分之一是卷积运算,它捕获输入图像中元素(如轮廓和边缘信息)之间的局部联系。CNN编码偏置,例如空间连接性和平移等方差。这些特征有助于构建通用高效的体系结构。然而,CNN中的局部感受野限制了对图像中长距离依赖关系的建模(例如,远距离部分关系)。此外,卷积与内容无关,因为卷积滤波器权重是稳定的,无论其性质如何,对所有输入应用相同的权重。最近,视觉Transformers(ViTs)在计算机视觉的各种任务中表现出令人印象深刻的性能。ViT基于自注意力机制,通过学习序列元素之间的关系,有效捕获全局交互性。最近的工作表明,ViT具有内容相关的远程交互建模能力,可以灵活调整其感受野,以应对数据中的干扰并学习有效的特征表示。因此,ViT及其变体已成功用于许多计算机视觉任务,包括分类、检测和分割。
随着ViT在计算机视觉领域的成功,遥感界也见证了在许多任务中使用基于Transformers的框架的显著增长(见下图),例如高分辨率图像分类、变化检测、泛锐化、建筑物检测和图像字幕。这开启了遥感研究的新浪潮,采用不同的方法,利用ImageNet预培训或使用视觉Transformers执行遥感预训练。同样,文献中存在基于纯Transformers设计的方法或基于Transformers和CNN的混合方法。因此,由于针对不同遥感问题的基于Transformers的方法迅速涌入,跟上最近的进展变得越来越具有挑战性。在这项工作中,本文的主要贡献如下:
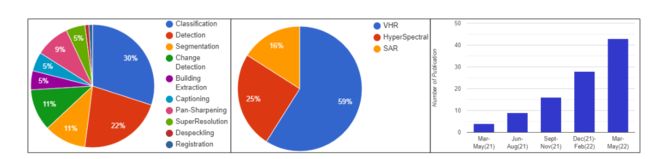
遥感成像中基于Transformers的最新技术。左边和中间:饼图代表了本调查中涉及的文章的统计数据,涉及不同的遥感成像问题和数据类型表示。右边:我们展示了一个图表,说明最近论文数量的持续增长。
1、全面概述了遥感成像中基于Transformers的模型。从而缩小了计算机视觉和遥感在这个迅速发展和流行领域的最新进展之间的差距。
2、概述了CNN和Transformers,讨论了它们各自的优缺点。
3、回顾了文献中60多个基于Transformers的研究工作,以讨论遥感领域的最新进展。
二、CNN在遥感图像领域的应用
(略)
三、Vision Transformers在遥感图像领域的应用
最近,基于Transformers的模型在许多计算机视觉和自然语言处理(NLP)任务中取得了可喜的结果。为了捕获长程相关性,Transformers使用自注意力层,而不是传统的递归神经网络,后者很难对序列元素之间的相关性进行编码。
为了有效地捕获输入图像中的长距离相关性,为图像识别任务引入了视觉变换器(ViTs),如下图所示。

ViTs将图像解释为一系列patches,并通过与NLP任务中使用的类似的传统Transformers编码器对其进行处理。ViT在通用视觉数据方面的成功不仅引起了计算机视觉不同领域的兴趣,而且也引起了遥感界的兴趣,近年来,在遥感界,针对各种任务探索了许多基于ViT的技术。
接下来,本文简要描述Transformers中自注意力的关键组成部分。
(一)、Self-Attention
略
(二)、Masked Self-Attention
所有物体都受到自注意力层的关注。Transformers模型的解码器中使用的这些自注意力块经过训练以预测序列中的下一个物体,这些自注意力模块被屏蔽,以防止关注后续的未来物体。此任务由带掩码 M ∈ R n × n M∈ R^{n×n} M∈Rn×n的逐元素乘法运算执行,其中M是上三角矩阵。在这里,Masked Self-Attention如下:

O代表Hadamard product。在Masked Self-Attention中,当预测序列中的某个实体时,未来实体的注意力评级设置为零。
(三)、多头注意力
略
(四)、Popular Transformers Backbones
ViT:在这种结构中,一个纯Transformers直接用于图像patches序列,以完成图像分类任务。ViT架构设计不采用图像特定的归纳偏差(例如,平移等方差和局部性),预训练是在大型ImageNet21k或JFT-300M数据集上执行的。
Swin:Liu等人通过引入产生分层特征的架构改进了ViT设计。Swin transformer在输入图像大小方面具有线性计算复杂性,其效率是通过将自注意力计算限制在非重叠的局部窗口,同时启用跨窗口连接来实现的。
PVT:引入了金字塔视觉Transformers(PVT)架构,用于执行像素级密集预测任务。PVT架构利用逐渐缩小的金字塔和空间缩减关注层来生成高分辨率多尺度要素特征图。与参数数目相似的CNN相比,PVT主干在目标检测和分割任务上表现出了令人印象深刻的性能。
Transformers刚提供了对不同视觉任务有用的独特特性。与计算静态滤波器的CNN中的卷积运算相比,自注意力滤波器是动态计算的。此外,输入点数量的排列和变化对自我注意力几乎没有影响。最近的研究探索了视觉Transformers的不同有感兴趣的内容,并将其与CNN进行了比较。例如,视觉Transformers对严重闭塞、移位和抖动更为稳健。接下来,本文根据下图所示的分类法对遥感中的Transformers进行了回顾。
(1)、用于解决超高分辨率(VHR)图像中不同问题的基于变压器的方法
场景分类 :遥感场景分类是一个具有挑战性的问题,其任务是自动将语义类别标签与包含真值物体和不同土地覆盖类型的给定高分辨率图像相关联。在现有的基于视觉变换器的VHR场景分类方法中,“Vision transformers for remote sensing image classification”探讨了标准视觉Transformers架构(ViT)的影响,并研究了生成附加数据的不同数据增强策略。此外,他们还评估了通过修剪层来压缩网络的影响,同时保持分类精度。
“When cnns meet vision transformer: A joint framework for remote sensing scene classification,”介绍了一个结合CNN与Transformers的框架,其中有一个CNN流和另一个ViT流,如下图所示。

两个流的特征被连接起来,整个框架使用联合损失函数进行训练,包括交叉熵和中心损失,以优化两个流结构。“Trs: Transformers for remote sensing scene classification,” 介绍了一个称为遥感Transformers(TRS)的框架,该框架通过将空间卷积替换为多头自注意力来努力结合CNN和变压器的优点。由此产生的多头自注意力瓶颈具有较少的参数,并且与其他瓶颈相比被证明是有效的。“Two-stream swin
transformer with differentiable sobel operator for remote sensing
image classification,”介绍了一个双流SwinTransformers网络(TSTNet),它包括两个流:原始和边缘。原始流提取标准图像特征,而边缘流包含可微分边缘Sobel算子模块并提供边缘信息。此外,引入加权特征融合模块,有效融合两个流的特征,提高分类性能。“Homo– heterogenous transformer learning framework for rs scene clas-
sification,”介绍了一个基于Transformers的框架,其中包含一个patch生成模块,用于生成均匀的和不均匀的patches。patches生成模块直接生成不均匀的patches,而均匀的patches则通过超像素分割方法获得 。
遥感数据预训:与上述仅使用Transformers或混合CNN与Transformers设计,主干网络预处理在ImageNet数据集上的方法不同,“An empirical study of remote sensing pretraining,”从零开始在大规模百万AID遥感数据集上调查培训视觉Transformers主干网络,如Swin。然后,针对不同的任务,包括场景分类,对生成的经过训练的主干模型进行微调。下图显示了使用Grad CAM+获得的不同ImageNet(IMP)和遥感预训练(RSP)模型的热力图。可以观察到,与IMP模型相比,RSP模型通过更加关注重要目标来学习更好的语义表示。此外,基于Transformers的主干,如Swin-T,由于自注意力机制,可以更好地捕获上下文信息。此外,ViTAEv2-S等结合了CNN和Transformers以及RSP优点的主干可以实现更好的识别性能。

下表显示了上述分类方法在最常用的VHR分类基准之一:AID数据集包含从多源传感器获取的图像。数据集具有高度的类内差异,因为图像是在不同的国家、不同的时间和季节以及不同的成像条件下采集的。数据集中总共有10000个图像和30个类别。根据所有类别的平均分类精度来衡量效果。除了RSP对Million AID数据集执行初始预训练外,这里的所有方法都使用在ImageNet基准上预先训练的模型。

(2)Object Detection
VHR成像中的目标定位是一个具有挑战性的问题,因为不同的目标类别具有极端的尺度变化和多样性。这里的任务是同时识别和定位(矩形或定向边界框)属于不同对象的所有实例。大多数现有方法采用混合策略,将CNN和Transformers的优点结合到现有的两级和单级检测器中。除了混合策略之外,最近很少有工作探索基于DETR的Transformers对象检测范式。
基于混合CNN与Transformers的方法:“An improved swin transformer-based model for remote sensing “An improved swin transformer-based model for remote sensing引入了局部感知Swin Transformers(LPSW)主干,以改进用于检测VHR图像中小型物体的标准Transformers。提出的LPSW致力于结合Transformers和CNN的优点,以提高局部感知能力,从而提高检测性能。使用不同的检测器(如mask RCNN)对所提出的方法进行评估。“Transformer with transfer cnn for remote-sensing-image object detection,”介绍了一种基于Transformers的检测体系结构,其中使用预训练的CNN提取特征,并使用Transformers处理遥感图像的特征金字塔。“Gansformer: A
detection network for aerial images with high performance com-
bining convolutional network and transformer,”介绍了一种检测框架,其中一个高效的Transformers被用作分支网络,以提高CNN编码全局特征的能力。此外,在主干网之前还使用生成模型将输入的遥感航空图像进行扩展。“Adt-det: Adaptive
dynamic refined single-stage transformer detector for arbitrary-
oriented object detection in satellite optical imagery,”提出了一种基于RetinaNet的检测框架,其中在主干网络和后处理网络之间使用特征金字塔Transformers(FPT)来生成语义上有意义的特征。FPT支持不同规模不同级别的特征之间的交互。“Few could be better than all: Feature sampling and grouping for scene text detection,”介绍了一个框架,其中使用Transformers来建模采样特征的关系,以便对其进行适当的分组。因此,无需任何后期处理操作即可获得更好的分组和边界框预测。该方法有效地消除了有助于提高检测性能的背景信息。
“Rodformer: High-precision design for rotating object detection with transformers,”介绍了一种混合架构,该架构将深度可分离卷积的局部特征与MLP的全局(通道)特征相结合。“Point rcnn: An angle-free framework for rotated object detection,”介绍了一个两级无角度检测器,其中RPN和回归都是无角度的。他们的工作还评估了基于Transformers主干的检测器(Swin Tiny)。“Hybrid network model: Transconvnet for oriented object detection in remote sensing images,”提出了一种称为TransConvNet的混合网络架构,旨在通过聚合全局和局部信息来结合CNN和transformers的优点,以更好地关注上下文,解决CNN的旋转不变性问题。此外,还设计了一个自适应特征融合网络来捕获多分辨率信息。 “Oriented reppoints for aerial object detection,”的工作介绍了一种检测框架,称为Oriented Rep Points,它使用灵活的自适应点作为表示。提出的无锚点方法学习从分类、定位和定向中选择点样本。具体而言,为了学习任意定向空中物体的几何特征,引入了一种质量评估和样本分配方案,用于测量和识别高质量的样本点以进行训练,如下图所示。此外,他们的方法利用空间约束惩罚定向框外的样本点,以便对这些点进行稳健学习。

基于DETR的检测方法:最近很少有方法研究将基于transformers的DETR检测框架用于VHR成像中的定向目标检测。“Oriented object detection with transformer,”将标准DETR用于定向目标检测。在他们的方法中,通过用深度可分离卷积代替标准注意机制,为transformer设计了高效编码器。“Ao2-detr: Arbitrary-oriented object detection transformer,”提出了一种基于transformer的检测器,称为AO2-DETR,其中使用定向建议生成方案来显式生成定向对象建议区域。此外,他们的方法包括一个自适应的面向提案细化模块,该模块旨在通过消除区域特征和对象之间的错位来计算旋转不变特征。此外,利用旋转感知匹配loss来执行直接集合预测的匹配过程,而无需重复预测。
下表显示了上述检测方法在最常用的VHR检测基准DOTA上的比较。该数据集包括2806幅大型航空图像,包括15种不同物体类别的飞机、棒球场、篮球场、足球场、桥梁、地面田径场、小型车辆、船舶、大型车辆、网球场、环岛、游泳池、港口、储罐和直升机。检测性能精度根据平均精度(mAP)进行测量。结果表明,大多数最近的方法都获得了相似的检测精度,但在使用Swin-T主干时,性能略有改善。

(3) Image Change Detection
(略)
(4)图像分割
在遥感中,通过执行像素级分类将图像自动分割为语义类别是一个具有挑战性的问题,具有广泛的应用,包括地质调查、城市资源管理、灾害管理和监测。大多数现有的基于transformer的遥感图像分割方法通常采用混合设计,旨在结合CNN和transformer的优点。 “Efficient transformer for remote sensing image segmentation,”介绍了一种基于轻量级transformer的框架Efficient-T,它包含一种隐式边缘增强技术。提议的Efficient-T采用分层Swintransformer和MLP头。“Cctnet: Coupled cnn and transformer network for crop segmentation of remote sensing images,”引入了一个耦合的CNN-transformer框架,称为CCTNet,其目的是将CNN捕获的边缘和纹理等局部细节与通过transformer获得的用于遥感图像中作物分割的全局上下文信息相结合。此外,还引入了测试时间增强和后处理步骤等不同模块,以便在推理时去除孔洞和小物体,从而恢复完整的分割图像。“Stransfuse: Fusing swin transformer and convolutional neural network for remote sensing image semantic segmentation,”中引入了一个名为STransFuse的CNN-transformers框架,其中提取了多尺度的粗粒度和细粒度特征表示,然后利用自注意力机制自适应组合。“Transformer and cnn hybrid deep neural network for semantic segmentation of very-high-resolution remote sensing imagery,”提出了一种混合架构,其中捕获远程依赖的SwinTransformer主干与U形解码器相结合,U形解码器采用基于深度可分离卷积的累加空间金字塔池块和SE模块,以更好地保存图像中的局部细节。“Transformer-based decoder designs for semantic segmentation on remotely sensed images,”利用预先训练的Swin Transformer主干以及三种解码器设计,即U-Net、特征金字塔网络和金字塔场景解析网络,对航空图像进行语义分割。
(5)、图像超分辨率
遥感图像超分辨率是从低分辨率图像中恢复高分辨率图像的任务。最近的一些工作已经为这项任务探索了transformers 。“Transformer-based multistage enhancement for remote sensing image super-resolution,”介绍了一种基于transformers的多级增强结构,它利用了不同阶段的特性。提出的多级结构可以与传统的超分辨率技术相结合,以融合多分辨率低维和高维特征。“A super-resolution method of remote sensing image using transformers,”提出了一种CNN-Transformer混合架构,用于集成局部和全局特征信息以实现超分辨率。“Tr-misr: Multiimage super-resolution based on feature fusion with transformers,”探索了多图像超分辨率问题,其中的任务是将同一场景的多个低分辨率遥感图像合并为一个高分辨率图像。这里,介绍了一种基于transformers的方法,包括具有残差块的编码器、融合模块和基于超像素卷积的解码器。
(五)、超光谱成像中的transformers
(1)、Image Classification
Image Classification任务是自动分类并为通过高光谱传感器获取的图像中的每个像素分配一个类别标签。
纯基于transformers的方法:在现有的工作中,“Hsi-bert: Hyperspectral image classification using the bidirectional en-coder representation from transformers,”引入了来自transformers的双向编码器表示,称为HSIBERT,它努力捕获全局依赖性。建议的架构非常灵活,可以从不同的地区推广,需要进行预培训。“Spectralformer: Rethinking hyperspectral image classification with transformers,”中引入了一种基于transformers的主干网络,称为SpectralFormer,它可以接收像素或拼接输入,并用于从附近的高光谱波段捕获光谱局部序列知识。SpectralFormer利用跨层跳跃连接,通过跨层学习软残差,将信息从浅层传递到深层,从而生成组级光谱嵌入。为了避免卷积核的固定几何结构问题,“Spectral-spatial transformer network for hyperspectral image classification: A factorized architecture search framework,”中提出了一种光谱-空间transformers网络,包括空间注意力和光谱关联模块。虽然空间注意力的目的是通过所有输入特征通道与空间核权重的聚合来连接局部区域,谱关联是通过整合相应的屏蔽特征图的所有空间位置来实现的。 “Dss-trm: deep spatial–spectral transformer for hyperspectral image classification,”中还探讨了transformers 的空间和光谱维度。这里,介绍了一个框架,包括学会捕捉光谱维度上的相互作用的光谱自注意力和设计用于关注空间维度上的特征的空间自注意力。然后,将光谱和空间自聚焦产生的特征组合并输入分类器。
基于CNN-transformers的混合方法:最近有几项研究将CNN和transformers的优点结合起来,以更好地捕获局部信息以及高光谱图像分类的长期相关性。为此, “Convolutional transformer network for hyperspectral image classification,”中引入了一种称为CTN的卷积变换网络,它利用中心位置编码,通过将像素位置与光谱特征以及卷积变换相结合来生成空间位置特征,以进一步获得局部全局特征,如下图所示。
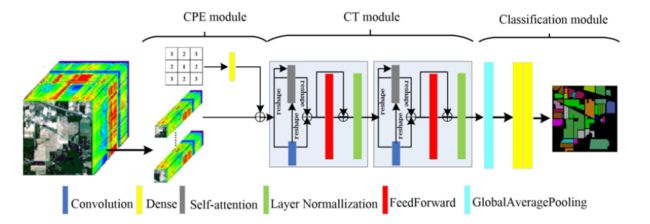
“Hyperspectral image transformer classification networks,”中提出了一种高光谱图像transformer(HiT)分类方法,其中卷积嵌入到transformers架构中,以进一步集成本地空间上下文信息。该方法包括两个主要模块,其中一个模块称为光谱自适应三维卷积投影,用于通过光谱自适应三维反积层从高光谱图像中生成空间光谱局部信息。另一个模块名为Conv Permutator,它使用深度卷积来沿着光谱、高度和宽度维度分别捕获空间-光谱表示。“Multiscale convolutional transformer with center mask pretraining for hyperspectral image classification,”介绍了一种多尺度卷积transformers,可有效捕获空间光谱信息,并可与transformer网络集成。此外,定义了一个自监督的预任务,它屏蔽编码器中中心像素的标记,而残差的标记被输入到解码器,以便重建与中心像素对应的光谱信息。“Spectral–spatial feature tokenization transformer for hyperspectral image classification,”提出了一种光谱-空间特征标记化transformer,称为SSFTT,用于生成光谱空间和语义特征。SSFTT包括一个特征提取模块,该模块通过使用3D和2D卷积来产生低级光谱和空间特征层。此外,在SSFTT中使用高斯加权特征标记器进行特征转换,然后输入transformer编码器进行特征表示。因此,使用线性层来生成样本标签。“Convolutional transformer network for hyperspectral image classification,”提出了一种卷积transformer网络(CTN),该网络采用中心位置编码来结合光谱特征和像素位置。该架构引入了卷积变换块,有效地整合了高光谱图像补丁的局部和全局特征。 “Hyperspectral image transformer classification networks”介绍了一种高光谱图像变换器(HiT)框架,其中卷积运算嵌入到变换器设计中,用于整合局部空间上下文信息。HiT框架由光谱自适应3D卷积投影组成,用于捕获本地空间光谱信息。此外,HiT框架使用了一个conv置换器模块,该模块使用深度卷积来明确捕获沿不同维度(高度、宽度和光谱)的空间光谱信息。“Spectral–spatial feature tokenization transformer for hyperspectral image classification,”介绍了一种称为SSFTT的光谱-空间特征标记化transformer,它包括用于编码浅光谱空间特征的光谱空间特征提取方案,以及一个特征转换模块,该模块生成转换后的特征,用作编码器的输入。
(六)、SAR图像中的transformer
(1)、SAR Image Interpretation
分类:对SAR图像中的目标类别进行准确分类是一个具有挑战性的问题,有许多实际应用。最近,人们探索了transformer在SAR图像自动判读和目标识别中的应用。“Exploring vision transformers for polarimetric sar image classification,”探索了用于极化SAR(PolSAR)图像分类的视觉transformer。在此框架中,图像patches的像素值被视为标记,并使用自注意力机制捕获长距离依赖关系,然后使用多层感知器(MLP)和可学习类标记来集成特征。在框架内使用对比学习技术以减少冗余并执行分类任务。下图显示了框架的概述。

除了上述基于纯transformer的方法外,文献中还存在利用CNN和transformer的混合方法。“High resolution sar image classification using global-local network structure based on vision transformer and cnn,”引入了一个全局-局部网络结构(GLNS)框架,该框架结合了CNN和SAR图像分类transformer的优点。提出的GLNS使用一个轻型CNN和一个高效的视觉transformer来捕获局部和全局特征,这些特征随后被融合以执行分类任务。除了标准的完全监督学习之外,transformer还可以在有限的监督机制中进行探索,例如,少镜头SAR图像分类。“St-pn: A spatial transformed prototypical network for few-shot sar image classification,” 介绍了一种称为ST-PN的少数热点SAR分类方法,其中利用空间transformer网络对基于CNN的特征进行空间对齐。
分割和检测:SAR图像中的检测和分割对于物体识别、目标检测和地形测绘等不同应用至关重要。在SAR图像中,由于斑点的出现,分割可能具有挑战性,斑点是一种随后向散射雷达幅度增加的倍增噪声。在最近的基于transformer的方法中,“Gcbanet: A global context boundary-aware network for sar ship instance segmentation,”引入了一个名为GCBANet的框架, 用于SAR船舶实例分割。在GCBANet框架内,使用全局上下文块来编码空间整体长距离依赖。此外,还引入了一种边界感知框预测技术来预测船舶的边界。“Crtranssar: A visual transformer based on contextual joint representation learning for sar ship detection,”介绍了一种名为CRTransSar的方法,它结合了CNN和transformer的优点,以捕获局部和全局信息,用于SAR目标检测。提议的CRTransSar通过构建一个具有注意力和卷积块的主干来工作。“Geospatial
transformer is what you need for aircraft detection in sar imagery,”介绍了一种地理空间变换器框架,包括图像分解、多尺度地理空间上下文关注和重组步骤,用于在SAR图像中检测飞机。“Sfre-net: Scattering feature relation enhancement network for aircraft detection in sar images,” 中提出了用于SAR图像中飞机检测的特征关系增强框架。该框架采用融合金字塔结构,结合不同层次和尺度的特征。此外,还使用了上下文注意增强技术来提高复杂背景下的定位精度。
大多数现有方法通常使用混合架构,其目的是结合卷积和自注意力的优点。然而,transformer通常具有较高的计算成本来计算全局自注意力。最近的几项工作探索了在以下方面的不同改进transformer设计,如减少计算开销、高效混合CNN-transformer主干和图像和视频分类的统一架构。此外,由于transformer使用了更多的训练数据,因此需要在遥感成像中构建更大规模的数据集。对于本工作中讨论的大多数问题,特别是在目标检测的情况下,通常使用重型主干来实现更好的检测精度。然而,这大大降低了空中探测器的速度。一个有趣的开放方向是设计基于轻型transformer的主干,以对遥感图像中的探测目标进行分类。另一个开放的研究方向是探索基于transformer的模型对异构图像源的适应性,例如SAR和UAV(例如变化检测)。
作者还观察了几种现有的方法,以即插即用的方式利用transformer进行遥感。这就需要设计有效的领域特定架构组件和损失函数,以进一步提高性能。此外,研究基于遥感基准预先训练的视觉transformer模型的对抗特征空间及其可转移性也很有意思。