UNIMO:Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning
**本文内容仅代表个人理解,如有错误,欢迎指正**
1. Points
1) UNIMO是一个预训练模型,其输入可以有不同的形式(eg, Image collections, Text corpus, Image-Text Pairs),并且可以微调后用于单模态(Single-modal)任务与多模态(Multi-modal)任务。即不仅在预训练时利用了image-text pair的数据,还充分利用了大量单模态的数据(non-paired single-modal, like images and texts),使得不同模态之间的数据能够相互增强,从而得到更泛化的表示。
2) UNIMO利用跨模态对比学习(Cross-modal contrastive learning)的方法实现不同模态数据(eg, Image与Text)在不同层级的对齐与统一。
2. Background introduction
现有的预训练模型,大多都仅针对一种范式,即单模态或多模态,且不能有效地进行转换(即在单模态下预训练的模型难以用于多模态的任务,反之同理)。
适用于单模态的预训练模型有:
1) Computer Vision: Alexnet, VGG, ResNet, etc.
2) Natural Language Processing: BERT, RoBERTa, XLNet, UniLM, etc.
适用于多模态的预训练模型:
VilBERT(2019), VisualBERT(2019), UNITER(2020)
*UNIMO作者的动机:希望能够提出一个统一模态的预训练模型,能够同时适用于单模态与多模态的任务。
3. Main Components
3.1 Unified-Modal Transformer
从Figure 1中可以看到,UNIMO利用multi-layer self-attention Transformers来学习统一的语义表示,其
1)输入:可以是Images、Texts,也可以是Image-Text pairs。具体来说,针对图像,其首先利用Faster-RCNN从图像中提取中多个候选框(Proposals),并得到每一个候选框的特征(pooled ROI feature),然后将一系列(a sequence of proposals)候选框特征作为输入;针对文本,其首先将文本划分为一系列词(a sequence of subwords)作为输入;针对图像和文本对,就分别执行上述操作,然后将两个sequence拼接在一起。
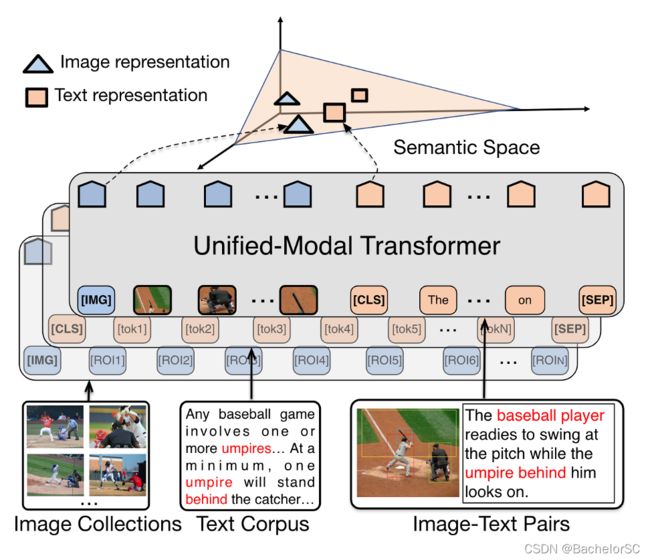
Figure 1. Illustration of the unified-modal pre-training architecture.
2)主要任务:将输入投影到同一个语义空间(Semantic Space)中。
3) Visual Learning
针对图像的学习,其参照了BERT中MASK的思路。简单而言,UNIMO通过Faster R-CNN得到了很多regions作为token输入Transformer中,现在要随机选取regions作为要进行mask的对象,并且为了防止信息泄漏(因为图像中的regions的重叠率比较高),所以将与选中的regions重叠率高于0.3的regions一并进行mask,最后利用没有mask的regions去预测mask了的regions。(如果输入是图像和本文对,那就是利用没有mask的regions和文本的信息一起去预测mask了的regions)
这里用了两个小任务去实现预测?1. feature regression 2. region classification
个人理解,预测mask的regions:通过没有mask的regions的信息,去学得一个上下文特征的表示,然后使得习得的上下文特征表示与mask的region的特征表示尽可能得相近(1)。通过这个上下文特征的表示来预测mask的regions中物体的分类(2)。
4)Language Learning
在文本的学习中,也采用了MASK的想法。值得注意的是,与其他方法不同,UNIMO在对文本进行分词的时候,是先检测语义完整的词汇,并在mask过程中将它们视为一个token。(举个例子,“Sherlock Holmes is a great detective.” 那么在进行分词的时候,会将Sherlock Holmes视为一个token。)
在language learning的时候主要采用了两个language modeling tasks
1. Bidirectional prediction: 其实做的事也就是选取token进行mask,然后利用未被mask的tokens进行预测。
2. Seq2Seq Generation: 选取段落或者句子,并将其进行拼接作为目标T,其余的本文作为上下文S,然后利用S去生成T。(不大能理解,这合理吗)
3.2 Cross-Modal Contrastive Learning

*Note:作者提到之前的工作在进行对比学习的时候,1、仅采用image-text matching作为学习目标 2、在同一个batch中选择unpaired的image或者text作为negative samples(可能本身跟anchor的差距就有些大),从而使得习得的东西就比较的粗糙。
主要思想:与对比学习常规思想差不多,就是让paired的样本在表示空间中相近,unpaired的样本在表示空间中远离。一般来说是通过构建Positive、Negative以及Hard negative sample来进行数据增强,提高模型的学习能力。
CMCL的目标:对不同模态的数据进行不同层级上的对齐。(不仅仅是在整体上图像和本文的一个对齐,更希望能够做到细粒度上的对齐)
实现方法:1. Text Rewriting 2. Image/Text Retrieval
1. Text Rewriting:
-为了增强模型在不同粒度上图像与文本的语义对齐能力,Text rewriting主要在sentence-level, phrase-level, word-level对原本的caotion/text进行改写。
Sentence-level: 主要采用了back-translation,即将句子翻译到别的语言,然后再翻译回来(降重的好方法哈哈哈)作为Positive sample。
*插播一下,同样是sentence-level。可以通过计算TF-IDF similarity来得到与原caption A相似度最高的、属于其他图像的caption B作为hard negative sample进行训练(因为caption B与caption A的相似度高,但又不完全描述了同一张图像,所以难度比较大)。
Phrase/word-level: Parse the image caption into a scene graph, then randomly replacing the object, attribute or relation nodes of the scene graph with a different object, attribute or relation from the corresponding vocabularies. 个人理解,大致意思就是随机替换相似的object, attribute, relation以生成hard negative samples吧(遇到图就开始发懵)
2. Image/Text Retrieval: 主要是为了利用单模态的数据
大概意思就是,给定一个image-text pair,通过计算visual similarities在image collections中寻找与image相似或(with highly overlapped objects)的images来提供相关的视觉信息,文本也是同理。
*值得注意的是,这些单模态的数据是利用独立的Unified- Modal Transformer学习的,而不是上文所述的Unified-Modal Transformer。
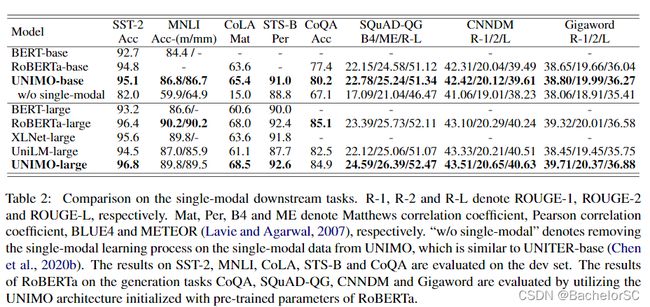
4. Experimental Results
*众所周知,能放出来的实验结果都很不错 :)


另外,UNIMO的作者还给出了一张可视化的图来证明其Unified-modal learning的有效性,但个人并不是很信服(狗头保命)。
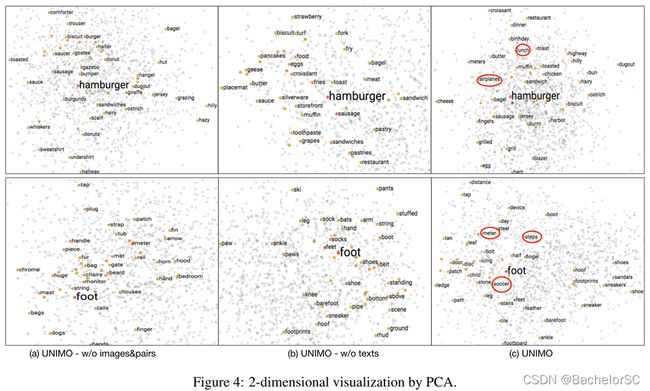
反倒是Figure 5和Figure 6更具说服力。
