2019年ICLR论文BA-NET: DENSE BUNDLE ADJUSTMENT NETWORKS论文阅读笔记
这篇博客分享的是2019年发表于ICLR的《BA-NET: DENSE BUNDLE ADJUSTMENT NETWORKS》。该论文提出了一种可以端到端训练的深度学习SfM框架,其最大贡献是将BA部分的LM优化算法变成可微的,从而使得端到端的训练成为可能。
- 论文地址:https://arxiv.org/abs/1806.04807
- 论文代码:https://github.com/frobelbest/BANet

1 INTRODUCTION
论文介绍了一种通过特征度量BA(bundle adjustment)来解决运动恢复结构(SfM)问题的网络体系结构,它以特征度量误差的形式明确地强制多视图几何约束。整个流程是可微的,因此网络可以学习到使BA问题更易于处理的合适特征。此外,这项工作引入了一种新的深度参数化来恢复密集的逐像素深度。该网络首先根据输入图像生成若干个基础深度图,并通过特征度量BA将最终深度优化为这些基础深度图的线性组合。基础深度图生成器也可以进行端到端的训练。整个系统将领域知识(即硬编码的多视图几何约束)和深度学习(即特征学习和基础深度图学习)巧妙地结合起来,以解决具有挑战性的稠密SfM问题。在大规模实际数据上的实验证明了该方法的有效性。
论文将BA描述为一个可微层,即BA层,以弥补经典方法和最近的基于深度学习的方法之间的差距。论文使用前馈多层感知器(Multilayer Perceptron, MLP)来预测LM算法中的阻尼因子,从而使得所有涉及的计算都是可微的。此外,与最小化几何或光度误差的传统BA不同,论文的BA层最小化的是对齐的CNN特征图之间的距离。这个新的特征度量BA将多幅图像的CNN特征作为输入,并对场景结构和相机运动进行优化。该特征度量BA层可以从场景结构和相机运动中反向传播损失,从运动和BA中学习最适合结构的适当特征。通过这种方式,所提出的网络硬编码BA层中的多视图几何约束,并从训练数据中学习合适的特征表示。
论文所提出的网络努力估计逐像素的密集深度,因为密集深度对于许多任务(如目标检测和机器人导航)至关重要。解决恢复密集逐像素深度的一个主要挑战是找到一个紧凑的参数化方式。直接的逐像素深度的计算代价很高,这使得网络训练很困难。因此,作者使用网络来为任意输入图像生成一组基础深度图,并将结果深度图表示为这些基础深度图的线性组合。组合的系数将与相机运动一起在BA层中进行优化。这种新颖的参数化方式可以获得保持良好物体边界的平滑深度图,具有良好的一致性。此外,它还减少了未知参数的数量,使网络中的密集BA成为可能。
最近的一项工作CodeSLAM中介绍了类似的深度学习参数化方法。主要区别在于,论文的方法的通过从BA层反向传播的梯度来学习基础深度图生成器,而CodeSLAM则是单独学习生成器,并将其结果用于独立的优化组件。因此,论文的基础深度图生成器有机会针对SfM问题进行更好的训练。此外,作者使用了不同的网络结构来生成基础深度图。CodeSLAM使用了一个可变自动编码器(Variational Auto-Encoder, VAE),而作者使用的是一个标准的编码器-解码器架构。这种设计使得作者能够使用相同的主干网络进行特征学习和基础深度图学习,从而使整个网络的联合训练成为可能。
2 RELATED WORK
Monocular Depth Estimation Networks 从单目图像估计深度是一个ill-posed的问题,同一张图像可以对应有无限多种可能的场景。在基于深度学习的方法提出之前,一些工作基于MRF、语义分割或手动设计的特征从单个图像预测深度。相比之下,作者利用单目图像深度估计网络进行深度参数化,只生成一组基础深度图,通过优化最终结果将得到进一步改善。
Structure-from-Motion Networks 最近,一些研究利用CNN来解决SfM问题。与以前的所有工作不同,作者提出了BA层来同时从CNN特征预测场景深度和相机运动,这明确地强制了多视图几何约束。硬编码的多视图几何约束使得该方法能够重建两个以上的图像,而大多数深度学习方法只能处理两个图像。此外,作者建议应该最小化特征度量误差,而不是光度误差,以增强鲁棒性。
3 BUNDLE ADJUSTMENT REVISITED
BA可以分为几何BA和光度BA两大类。其中,几何BA通过最小化重投影误差,联合优化相机位姿和3D场景点坐标。它将场景点重新投影到图像平面,计算该投影点与其原始像素坐标之间的欧式距离,然后使用非线性最小二乘的方法去最小化这一距离。这种带有重投影误差的几何BA是过去二十年中SfM的黄金标准,但是它存在两个主要缺点:
- 仅利用了检测出来的图像特征点信息,通常为图像角点、斑点或线段等。
- 特征必须是相互匹配的,这通常会产生大量的异常值。即使是使用了像RANSAC这样有效的异常值去除方式也不能保证完全正确的结果。
这两个缺点的存在推动了直接方法的最新发展,该方法提出了光度BA算法。光度BA算法不考虑特征匹配,而是直接最小化对齐像素的光度误差(像素强度差)。直接方法的优点是可以利用具有足够梯度大小的所有像素,而不止是局限于特征角点。它们表现出了优异的性能,尤其是在缺乏纹理的场景下。但是,这些方法也有一些缺点:
- 它们对初始化敏感,因为光度误差增加了非凸性。
- 它们对相机曝光和白平衡变化敏感。需要进行自动光度校准。
- 它们对异常值(如移动对象)更敏感。
4 THE BA-NET ARCHITECTURE
为了应对上述挑战,论文提出了一种特征度量BA算法,该算法估计与光度BA相同的场景深度和相机运动参数X,但最小化对齐像素的特征度量差异:
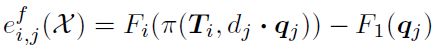
其中Fi是图像Ii的特征金字塔;待优化参数X={T1, T2, ……, TNi, d1, d2, ……, dNj},即所有相机外参和三维点的集合;函数π表示将场景点投影到图像平面上;dj是图像I1上的像素qj对应的深度值,dj·qj则是将qj(是一个齐次坐标,形如[x, y, 1]T)变换到其三维点坐标(在相机坐标系下)中。与光度BA类似,特征度量BA考虑的像素数量是多于角点或斑点的。此外,它还有可能学习到SfM处理曝光变化、移动物体等更合适的特征。
该网络通过反向传播学习适合SfM的特征,而不是使用预先训练好的CNN特征进行图像分类。因此,设计一个可微的优化层(即这里的BA层)来解决优化问题至关重要,这样损失信息就可以反向传播。BA层预测相机姿态T,在向前传播和向后传播期间,密集深度图D将损失从T和D传播到特征金字塔F进行训练。
4.1 OVERVIEW

如图1所示,论文所提出的BA网络接收多个图像,然后将它们输入到主干网络DRN-54中。使用DRN-54是因为它用卷积层代替了最大池化层,并生成了更平滑的特征图,这对于BA优化是有利的。但是,由于膨胀卷积生成的高分辨率特征图导致了原始DRN内存效率低下,因此,作者用普通卷积代替了膨胀卷积。在DRN-54之后,为每个输入图像构造特征金字塔,这些图像是BA层的输入。
同时,基础深度图生成器为图像I1生成多个基础深度图,且最终深度图表示为这些基础深度图的线性组合。
最后,BA层通过最小化特征度量误差来联合优化相机位姿和密集深度图,从而使整个流程是端到端可训练的。
4.2 FEATURE PYRAMID
特征金字塔为BA层学习合适的特征。与用于目标检测的特征金字塔网络(FPN)类似,作者利用深度卷积网络固有的多尺度层次结构来构建特征金字塔。采用具有横向连接的自顶向下体系结构,将更丰富的上下文信息从较粗的尺度传播到较细的尺度。因此,该特征度量BA将具有更大的收敛半径。
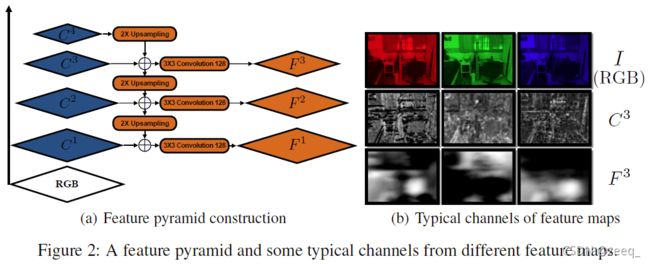
如图2(a)所示,从主干DRN-54构建一个特征金字塔。将DRN-54的conv1、conv2、conv3、conv4后的残差块表示为{C1、C2、C3、C4},其步长分别为{1、2、4、8}。使用双线性插值将特征图Ck+1上采样2倍,并在下一级将上采样的特征图与Ck连接(concatenate)起来。此过程将一直迭代到最精细(finest)的级别。最后,对concatenated的特征图进行3×3卷积,将其维数降低到128,以平衡表达能力和计算复杂性,从而得到图像Ii的最终特征金字塔Fi。
从图2(b)可以看出,在使用BA层进行训练后,特征金字塔变得更加平滑,每个通道对应于图像中的不同区域。这里,特征金字塔比FPN具有更高的分辨率,以便于精确对齐。
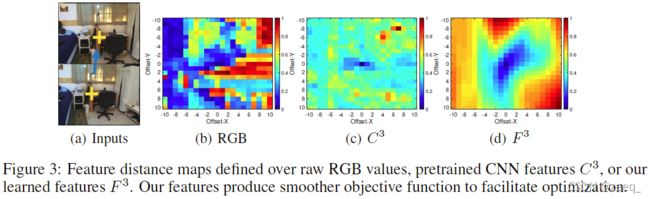
为了更好地了解BA优化在多大程度上受益于所学的特性,作者在图3中显示了不同的距离。评估图3(a)上图中黄色十字标记的像素与图3(a)下图中对应点附近的所有像素之间的距离。根据原始RGB值、预训练特征C3和学习特征F3评估的距离分别在(b)、(c )和(d)中进行了可视化。所有距离均标准化为[0,1],并可视化为热图。x轴和y轴是到真值对应点的偏移。从图3可以看出,(b)中的RGB距离没有明确的全局最小值,这使得光度BA对初始化敏感;而由预训练特征C3测量的距离具有全局和局部最小值;最后,由本文网络学习的特征F3测量的距离具有清晰的全局最小值和平滑的盆地,这有助于基于梯度的优化,如LM算法。
4.3 BUNDLE ADJUSTMENT LAYER
在为所有图像构建特征金字塔之后,通过最小化特征度量误差来优化相机位姿和密集深度图。遵循传统的BA原理,作者使用Levenberg-Marquardt(LM)算法来优化误差方程。然而,由于两个困难,原始LM算法是不可微的:
- 当达到指定的收敛阈值时,迭代计算终止。这种基于if-else的终止策略使得输出解X相对于输入F不可微。
- 在每次迭代中,它根据目标函数的当前值更新阻尼系数λ。如果一个步骤未能减小目标函数的值,则λ会增大;否则λ将减小。这个if-else判定也使得X相对于F是不可微的。
当解X相对于F不可微时,通过反向传播进行特征学习也变得不可能。对于第一个困难,可以通过固定迭代次数来解决,这称为“不完全优化”。除了让优化变得可微,这种“不完全优化”技术还可以减少内存消耗,因为迭代次数通常固定在一个较小的值上。
第二个困难尚未被研究过。以前的工作主要集中在梯度下降或二次最小化问题上。在本节中,作者提出了一种简单而有效的方法来软化这个if-else决策,并给出了一个可微的LM算法:通过将当前目标值输入到MLP网络以预测λ。这种技术不仅使优化可微,而且还可以学习预测更好的阻尼因子λ,这有助于优化在有限的迭代中获得更好的解。

首先, 通过将中间变量解释为网络节点,将LM优化的单个迭代如图4所示。在向前传播时,根据如下步骤从特征金字塔F和当前解空间X中计算解空间的更新∆X:
- 对所有图像和像素点计算特征度量误差E(X);
- 然后计算雅可比矩阵J(X),海塞矩阵J(X)TJ(X)及其对角矩阵D(X);
- 为了预测阻尼因子λ,使用全局平均池化对每个特征通道的所有像素上的E(X)的绝对值进行聚合,获得一个128维的特征向量。然后将其输入到MLP子网络以预测λ;
- 最后,使用标准LM来计算当前解空间的更新∆X。
通过这种方式,可以把λ作为一个中间变量,并且可以将每个LM步骤记为关于特征金字塔F和来自先前迭代的解空间X的函数g。即∆X=g(X; F)。因此,第k次迭代后的解为:
![]()
这里,◦ 表示参数更新,这是对经过SE(3)指数映射的相机位姿和深度的加法。上式相对于特征金字塔F是可微的,这使得反向传播能够通过整个特征学习流程。预测λ的MLP如图4所示。堆叠了四个全连接层,从输入的128维向量中预测λ。使用ReLU作为激活函数来保证λ是非负的。继光度BA之后,作者使用从粗到精的策略解决了特征度量BA,并在每次迭代时对特征图进行warp。作者在每个金字塔级别应用可微LM算法进行5次迭代,总共则是15次迭代。所有相机位姿均初始化为单位旋转和零平移。
4.4 BASIS DEPTH MAPS GENERATION
通过逐像素深度值参数化密集深度图是不切实际的。首先,它引入了太多的优化参数。例如,320×240像素的图像产生76.8k参数。其次,在训练开始时,由于深度或运动预测不佳,许多像素将在其他视图中不可见。因此,只有很少的信息可以反向传播以改进网络,这使得训练变得困难。
为了解决这些问题,作者将卷积网络作为一种紧凑的参数化方法来进行单目图像深度估计,而不是将其用作初始化。作者使用了标准的编码器-解码器架构来进行单目深度学习。使用了DRN-54作为编码器,与特征金字塔共享相同的主干特征。对于解码器,将Laina等人(2016)所提出的网络最后的卷积特征图修改为128个通道,并使用这些特征图作为用于优化的基础深度图。最终的深度图是这些基础深度图的线性组合,即:
![]()
这里,D是包含所有像素深度值的h·w的深度图,B是128×h·w的矩阵,表示从网络生成的128个基础深度图,w是这些基础深度图的线性组合权重。权重w将在BA层进行优化。ReLU激活函数确保最终深度为非负。从网络生成B后,固定B并在BA优化中使用w作为紧凑的深度参数化,那么,特征度量距离变为:
![]()
其中,B[j]是B的第j列,并且ReLU(wTB[j])是qj对应的深度。为了进一步加快收敛速度,网络学习初始权重w0作为任意图像的一维卷积滤波器,即D0=ReLU(w0TB) 。
4.5 TRAINING
BA网络以有监督的方式学习特征金字塔、阻尼因子预测器和基础深度图生成器。将以下常用损失应用于训练过程中,尽管可以设计出更复杂的损失函数。
相机位姿损失:相机的旋转损失是定义为旋转四元数向量之间的距离。类似地,平移损失是在度量尺度下预测值和真值之间的欧几里德距离。
深度图损失:对于每个密集深度图,作者采用了berHu损失(如这里所述)。
作者从DRN-54开始初始化主干网络,其他组件由ADAM从头开始训练,初始学习率为0.001。
5 EVALUATION
5.1 DATASET
ScanNet ScanNet是一个大型室内数据集,在706个不同场景中有1513个序列。其提供的相机位姿和深度图并不完美,因为它们是通过BundleFusion估计的。在ScanNet的所有数据中,尺度都是已知的,因为数据是用深度相机记录的,该相机返回绝对深度值。
为了采样图像对进行训练,作者应用了一个简单的过滤过程。首先过滤掉具有较大光度一致性错误的图像对,以避免具有较大位姿或深度错误的图像对。如果一幅图像中的像素在另一幅图像中的可见率低于50%,也会被过滤掉。此外,如果roundness得分小于0.001,也会被舍弃,这避免了基线过短的配对。
作者将整个数据集分为训练集和测试集。训练集包含前1413个序列,测试集包含其余100个序列。分别从训练序列和测试序列中抽取547991个训练对和2000个测试对。
KITTI KITTI是一个广泛使用的基准数据集,由车载摄像头和激光雷达传感器收集的街道数据。它包含61个场景,属于“城市”、“住宅”或“道路”类别。Eigen等人(2014年)选择28个场景进行测试,并从剩余场景中选择28个场景进行训练。作者使用了相同的数据分割方式,以便于与其他学者曾提出的方法进行公平的比较。由于原始KITTI数据集无法提供位姿真值,作者通过LibVISO2来计算相机位姿,并在丢弃错误较大的位姿后将其作为位姿真值。
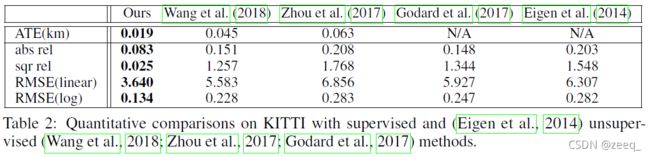
5.2 COMPARISONS WITH OTHER METHODS
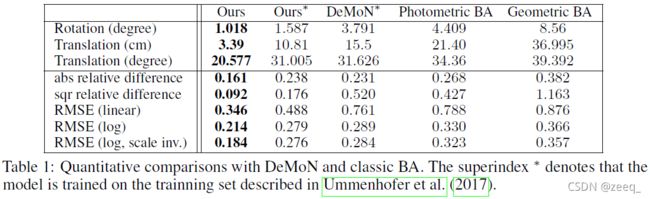
6 CONCLUSIONS AND FUTURE WORKS
论文介绍了BA网络,这是一种根据特征度量误差明确实施多视图几何约束的网络。它通过特征度量BA来联合优化场景深度和相机运动。整个过程是可微分的,因此可以进行端到端的训练,这样就可以从数据中学习特征,以便于从运动中构造结构。密集深度被参数化为网络生成的几个基础深度图的线性组合。该BA网络将领域知识(硬编码的多视图几何约束)与深度学习(学习到的特征表示和基础深度图生成器)很好地结合起来。它优于传统的BA和最近提出的基于深度学习的方法。
7 APPENDIX
7.1 IMPLEMENTATION DETAILS
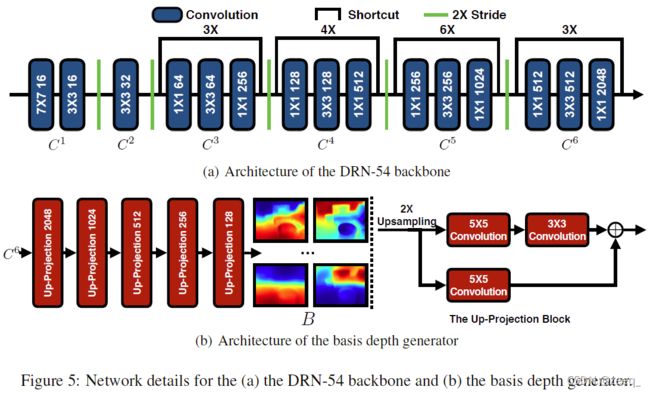
Network Architecture Details 图5展示了骨干网络DRN-54和深度基准生成器的详细网络体系结构。特征金字塔的架构如图2(a)所示。作者将原始DRN-54的膨胀卷积修改为带步长的卷积,并丢弃了conv7和conv8,如图5(a)所示。C1到C6是具有{1,2,4,8,16,32}步长和{16,32,256,512,1024,2048}通道的层,其中C1和C2是基础的卷积层,而C3到C6则是ResNet中的标准瓶颈块。
图5(b)展示了采用Laina等人(2016)提出的up-projection结构的深度基准生成器。深度基准生成器是一个标准的解码器,它将C6的输出作为输入,并将五个投影块堆叠起来以生成128个基础深度图,每个基础深度图的分辨率为输入图像的一半。up-projection块如图5(b)右侧所示,它将输入上采样2倍,然后使用带投影连接的卷积。
Evaluation Time 为了评估作者提出的方法的运行时间,使用Tensorflow profiler工具检索所有网络节点的时间(以毫秒为单位),然后总结网络中每个组件对应的结果。如表3所示,所提出的方法需要95.21ms来重建两张320×240的图像,比DeMoN的速度稍快,DeMoN处理两个256×192图像需要110毫秒。

当前的计算瓶颈是BA层,该层包含大量的矩阵运算,可通过直接使用CUDA来实现进一步的加速。由于在BA层中明确硬编码多视图几何约束,因此可以将主干DRN-54与其他高级视觉任务(如语义分割和目标检测)共享,以最大限度地重用网络的结构并最小化额外的计算成本。
7.2 ABLATION STUDIES
Learned Features vs Pre-trained Features 论文提出的可学习的特征金字塔提高了目标函数的凸性,这有助于优化。作者将学习到的特征与在ImageNet上为分类任务预先训练的特征进行比较。如表4所示,预训练的特征(即w/o特征学习)产生了较大的误差,这证明了第4.2节中的讨论。

Bundle Adjustment Optimization vs SE(3) Pose Estimation 论文的BA层联合优化深度和相机位姿。作者将其与具有固定深度图的SE(3)相机位姿估计(例如第4.4节中的初始深度D0)进行比较。为了进行公平的比较,作者还将学习到的特征金字塔用于SE(3)相机的位姿估计。如表4所示,在没有BA优化(即w/o联合优化)的情况下,深度图和相机位姿都会更差,因为深度估计中的误差会降低相机位姿估计的精度。
Differentiable Levenberg-Marquardt vs Gauss-Newton 为了使整个网络是端到端可训练的,作者通过从网络中学习阻尼因子使LM算法可微。首先将论文的方法与无阻尼因子λ(即λ=0)的普通高斯-牛顿法进行比较。由于特征度量BA的目标函数是非凸的,因此Hessian矩阵J(X)TJ(X)可能不是正定的,这使得通过Cholesky分解进行的矩阵求逆失败。
为了解决这个问题,作者使用QR分解代替高斯-牛顿训练。如表4所示,高斯-牛顿算法(即w/oλ)产生更大的误差,因为BA优化是非凸的,高斯-牛顿算法没有保证收敛性,除非初始解足够接近最优解。这种比较表明,与传统的BA类似,论文提出的可微LM算法在特征度量BA方面优于高斯-牛顿算法。

Predicted vs Constant λ 另一种使LM算法可微的方法是在迭代过程中固定λ。作者对此策略进行比较。如图6(a)所示,增加λ使旋转和平移误差减小,直到λ=0.5,然后误差开始增加。原因是一个小的λ使算法接近高斯-牛顿算法,该算法存在收敛问题。较大的λ则导致每次迭代时的更新较小,这使得在有限的迭代中很难获得一个好的解。
而在图6(b)中,增加λ总是会使深度误差减小,这可能是因为较大的λ会导致较小的更新,并使最终深度接近初始深度,这比具有较小常数λ的优化深度要好。
与使用从MLP网络中预测的λ相比,使用常数λ值始终会产生更糟糕的结果,因为没有针对所有数据的最佳λ,它应该适应不同的数据和不同的迭代。作为比较,本文的方法在图6(a)和图6(b)中用虚线进行了绘制。
7.3 EVALUATION ON DEMON DATASET
表5总结了本文所提出的网络在DeMoN数据集上的结果。为了进行比较,作者还引用了DeMoN和LS-Net的最新研究成果。此外,还进一步引用了DeMoN中报告的一些传统方法的结果,分别表示为Oracle、SIFT、FF和Matlab。在这里,Oracle使用相机真值通过SGM来解决多视图立体几何问题,而SIFT、FF和Matlab进一步分别使用稀疏特征、光流和KLT跟踪进行特征匹配,通过八点算法解决相机位姿问题。
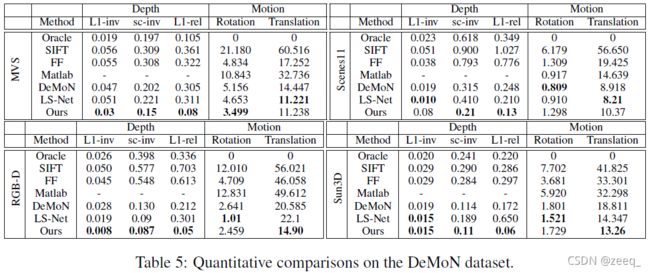
从表5中可以看出,本文的方法在相机运动和场景深度的估计方面始终优于DeMoN,除了“场景11”,因为作者在BA层中实施多视图几何约束,而“场景11”的图像是用ShapeNet中的随机对象合成的,没有物理上正确的比例。此设置与实际数据不一致,使得论文的方法更难去训练基础深度图生成器。与LS-Net相比,论文的方法在相机位姿估计上实现了相似的精度,但场景深度估计的更好。证明了论文提出的可以学习特征的特征度量BA优于LS-Net中的光度度量BA。
7.4 MULTI-VIEW STRUCTURE-FROM-MOTION
论文的方法可以很容易地扩展到重建多幅图像。作者在ScanNet数据集的多视图配置中进行了评估。为了对多视图图像进行采样以进行训练,作者随机选择了具有公共图像的两视图图像对来构造N视图序列。由于GPU内存有限(12G),作者将N限制为5。
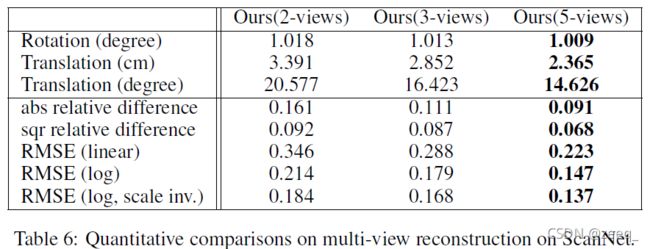
如表6所示,当包含更多视图时,精度会不断提高,这表明了多视图几何约束的益处。相反,大多数现有的深度学习方法一次只能处理两个视图,这在结构上是次优的。
7.5 QUANTITATIVE COMPARISONS WITH CODESLAM
作者将论文的方法与CodeSLAM进行比较,后者采用了类似的深度参数化思想。但不同之处在于,CodeSLAM单独学习带条件的深度自动编码器,并在独立的光度BA组件中使用深度编码,而论文的方法通过特征度量BA端到端学习特征金字塔和基础深度图生成器。由于CodeSLAM没有公开代码,作者直接引用了他们论文中的结果。为了获得论文的方法在EuroC MH02序列上的轨迹,作者每四帧选择一帧,并连接每个包含五帧的重建组。然后,作者使用与CodeSLAM相同的评估指标,该指标测量对应于不同旅行距离的平移误差。

如图7所示,论文的方法优于CodeSLAM,其中值误差小于CodeSLAM误差的一半,即CodeSLAM在9m的行程中显示出约1m的误差,而论文的方法的误差约为0.4m。这一比较表明,使用特征金字塔和特征度量BA的端到端学习优于仅使用可学习的深度参数化的端到端学习。
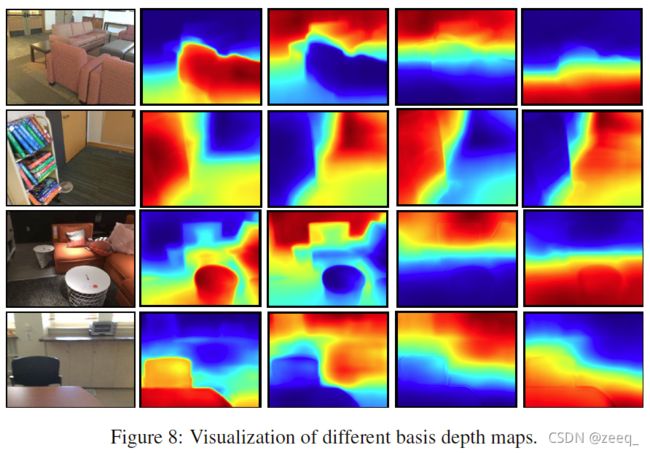
7.6 VISUALIZATION OF BASIS DEPTH MAPS
在图8中,作者将四幅典型的基础深度图可视化为四幅图像中每幅图像的热图。一个有趣的观察结果是,一个基础深度图对近距离物体有较高的响应,而另一个基础深度图对远距离背景有较高的响应。其他一些基础深度图具有平滑变化的响应,并对应于场景的布局。这一观察结果表明,学习的基础深度图已经捕捉到了场景的潜在结构。
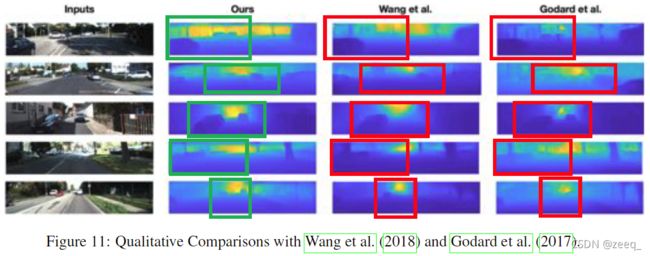
7.7 QUALITATIVE COMPARISONS WITH OTHER METHODS
最后,作者与之前学者提出的一些方法进行了一些定性比较。图9展示了论文的方法和DeMoN在ScanNet数据上恢复的深度图。可以从红色圆圈突出显示的区域中看到,论文的方法恢复了更多的形状细节,这与表1中的定量结果是一致的。图11分别展示了Wang等人和Godard等人通过本文的方法恢复的深度图。同样,可以在结果中观察到更多的形状细节,如表2中的定量结果所示。


*部分翻译或理解可能会存在偏差,仅供参考,欢迎讨论。