hdfs 数据迁移_Hadoop集群跨数据中心迁移实践

文|张翼 李海强 徐杰 王聪 张勋祥
01
综述
古语有云:“三军未动,粮草先行。”从战略布局的角度来看,大数据平台的建设与发展亦是如此,想要构建服务全集团的大数据综合平台,提升平台服务能力,机房容量“粮仓”至关重要。
近年来,随着零售大数据Hadoop集群的快速增长,已是负重前行的保税区机房的设计容量日渐难以承载,扩建或新建机房势在必行。经领导层决议,基于大数据未来3年的发展需求和多维度推演、论证,新建东莞数据中心,设计容量4000台,并制定Hadoop集群迁移计划。
本次迁移历时一年之久,涉及银行部门之多,从大数据到科技运营,以及业务方,甚至还牵扯供应商,以项目管理的角度来看并非易事,可以说是一个大工程。然而,工程再大,对平安人来说都是使命必达,不待扬鞭自奋蹄。自2019年下半年开始,从数据中心建设,到设备采购,再到迁移方案探讨、迁移步骤整理、演练,最后在团队的共同努力下顺利完成迁移。

02
迁移方案
好事需多磨,梅香自苦寒,迁移方案的制定并非一帆风顺,一日之功。前期脑暴,最初初步确定了3个方案;随后,从方案推演到逐一细节论证,多次修改,最终,我们选择了可行性最高且最有把握的一个。第一个方案是常规物理搬迁。拿到迁移任务之初,我们首先想到的就是最简单粗暴的物理搬迁,即把服务停掉,机器下架,装车运往东莞数据中心,机器重新上架,配置网络,恢复服务。然而,看似简单的方案,却充满了不确定性。首先,停服1~2天,业务必受影响,业务方能否接受。其次,机器搬运过程中难免会有物理损坏,数据是否会丢失,丢失了是否能恢复。再次,假使前两点都不再是问题,东莞数据中心顺利重新上架机器,恢复服务,但是否会出现新的问题影响服务效果和质量。如果出现严重问题导致服务不可用,回退的可能性为零,就算硬着头皮解决问题,也势必要影响业务开展,最重要的是,我们很难评估会对业务造成怎样的影响。最后,因不确定性太多,且可能造成不可挽回的损失,这个方案一开始就被否决。第二个方案是和Cloudera公司合作,采用最新的CDH 6.3版本建设新机房。这样的方案下,Hadoop会从2.6升级到3.0,Hive从1.1升级到2.1,Spark从2.3升级到2.4。然而,版本的升级就意味着现有的服务跟新版本的适配工作量巨大,同时也将加重数据验证比对的工作压力,调度双跑避无可避。考虑到Z+团队的工作压力以及担心版本升级导致的跑数结果异常,结果可想而知,方案最终再次被老板否决。第三个方案,也是我们最终采用的方案,即新机房继续采用当前集群的版本,不升级,这样理论上就可避免跑数异常情况的发生。迁移的大致过程如下:
向下滑动查看详细迁移过程
新机房部署一倍于现有集群(简称“保税集群”)计算力的集群,简称“东莞集群”(现有集群计算力已经不能满足需求)
在800Gbps带宽的条件下,全量同步保税集群HDFS数据到东莞集群,数据量是11PB
开启增量数据同步,确保每天新增的数据同步到东莞集群
在东莞机房新建一个Hive mysql,作为原mysql的从库,变更当天从库切换成主库,批量修改Hive表location,目标是东莞HDFS
在Z+上将一些数据团队提供的关键作业复制为迁移测试作业,专门用来在东莞集群重跑历史数据,并和保税集群跑出的历史数据全量比对
测试其它服务在东莞集群的功能是否正常,包括HUE、Z+、AICloud、Kylin、I+、HUE、SAS、B+、Presto、指标平台、交易明细、知识图谱
在功能测试和数据验证无误后,变更当天一次性将计算存储切换到东莞集群
03
迁移工具
修改Hive元数据工具
通过java调用jdbc修改元数据库中数据存放路径location,修改的元数据表有dbs、sds、func,修改方式为批量修改,如update sds set location=replace(location,'路径1','路径2'),比使用jdbc一条一条数据修改快很多倍,从几个小时提升到20分钟。
HDFS文件目录比对工具
namenode会定期产出fsimage checkpoint,利用hdfs oiv命令转换fsimage checkpoint为结构化文本数据并导入hive,再用spark sql join把缺失的文件目录筛选出来,简单过滤加工之后生成文件列表,交由数据同步工具。
HDFS文件MD5比对工具
通过比较文件MD5值判断两个集群表上文件是否一致,从数据库根据状态值取出需要比较的表和分区,以分区为单位,多线程递归比较每个分区下文件的MD5值,对比结果更新数据库中表和分区对应的状态。
数据同步工具
将保税集群数据迁移到东莞集群上,从数据类型划分为全量数据和增量数据。同时数据包含其属性特征,如:用户/组、ACL等信息。涉及到权限问题,也必须同步到新集群中。在确定数据类型及数据必备的属性的前提下,需具体分析完备的传递数据的方案。
向下滑动查看详细内容
1. 确定集群间数据传递采用distcp命令,并利用distcp命令提供的相关参数控制数据传递快慢,以达到效率最优。
2. 在distcp命令上进行一层封装,添加属性信息获取及同步功能,并对数据传输结果记录到数据库中及log中以统计成功率及失败率,对失败任务自动重新派发机制。
3. 构建一个数据传输任务管理节点,专门负责未传递数据的统计、管理、任务下发功能,以保证任务可控的动态方式进行下发和监控。
4. 提供多种数据源获取的接口,数据源途径有:从Hive meatstore中获取数仓中所有表数据路径、从执行文件中读取数据路径、从监控hdfs audit日志的Hive表中。
5. 构建一个1-N(1为数据任务控制管理node;N为消费者,真正进行数据传输及属性同步的node)架构的数据迁移工具。
6. 从步骤1~5采用python编写实现,具体是在1台机器部署数据任务控制管理application,17台机器上部署数据传输处理application,原理都是采用distcp命令真正进行数据传输(提交任务到yarn上的MR作业)
7. 在步骤6基础上,再进一步封装。直接执行shell命令这样更加简单,使得脚本工具化。
8. 通过采用步骤5中(1-N)架构,同时实现增量同步权限和多余数据的删除功能。
增量数据同步工具
解析hdfs audit log,筛选出新增和修改的文件路径,写入Hive表。数据同步工具每隔1小时从Hive表获取要同步的文件列表,同步数据到东莞集群。
采用迁移工具进行全量数据(单副本11PB)传递,在不影响原集群作业的情况下,5天就将全量数据基本都拷贝到新集群中。在进行增量数据同步时,能做到1小时处理10万条有变更数据路径的同步。这样在原集群停止对外访问情况下,高效地同步增量数据。
04
变更步骤
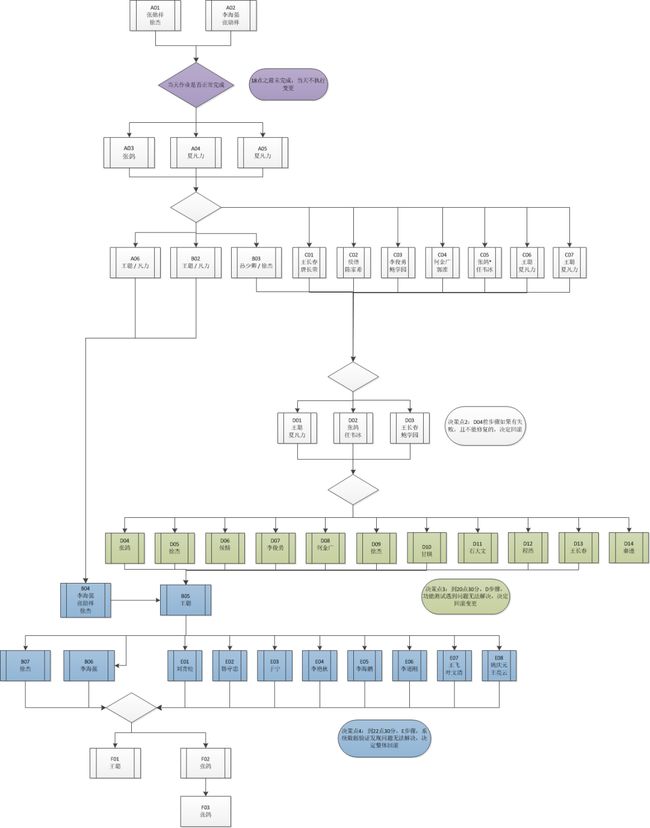
▲ 变更流程图
变更过程分为六个阶段,有些阶段时间比较长,和其它阶段交织在一起,结合图一的流程图会比较清晰。
1. 准备阶段
准备阶段主要包含小时级别的HDFS增量数据同步和文件MD5比对、fsimage全量文件比对,目的是尽量减少第二阶段需要同步的数据量,降低变更风险。 2. 数据同步、比对阶段
此阶段开始之前,需要把平台监控和服务停掉,将namenode进入safemode,禁止数据写入。然后手动触发生成fsimage checkpoint,然后执行文件目录比对工具,筛选出不一致的文件目录,交由数据同步工具,并发同步数据到东莞集群。数据同步完之后,还会触发数据MD5比对工具,比对文件的MD5值,确保数据一致。
此阶段还有一个重要任务是筛选出东莞集群多余的文件目录并删除掉,过程和同步增量数据是一样的,只是spark sql join的顺序换一下。
在第二阶段的第一次数据同步比对做完之后,我们会再重复一次相同的过程,目的是再次确认数据是否一致,理应不会再有缺失或对于的文件目录。
由于此阶段时间比较长,第三、四、五阶段是可以和第二阶段并行的。3. 配置变更阶段
此阶段完成所有用到hadoop/hive/spark配置的应用服务,包含指标平台、交易明细、知识图谱、Kylin、SAS、AICloud、I+、HUE、B+、Z+、gateway/hiveserver2/metastore/spark thriftserver/presto。gateway/hiveserver2/metastore/spark thriftserver/presto的配置跟新通过ansible统一更新,其它应用服务由各自负责人更新。4. 启动服务和功能验证阶段
此阶段恢复变更停止的应用服务,测试和hadoop/hive/spark相关的功能,测试步骤都已事先整理到变更手册。5. 数据验证阶段
事先挑选了零售数据集市关键作业列表,包含信用卡、基础零售、消金、汽融、零售风险、采集、行员、基本法。各集市开发会在Z+上跑关键作业的测试任务,比对测试任务的数据和历史数据。6. 恢复调度和作业观察阶段
恢复Z+自动调度功能,平台值班人员关注失败的作业,分析失败的原因,解决因迁移导致的问题。
05
第一次生产变更(失败)
第一次生产变更整体是比较顺利的,最后失败的原因是在删除东莞集群多余数据的时候,误删了Hive数仓目录。误删的原因是在分割待删文件列表的时候,分割错了,导致Hive数仓目录被丢进回收站。失败之后,经老板决策,决定回退。同时将东莞namenode回退到上一个checkpoint,避免了再次全量同步数据。
失败之后,团队复盘并总结了几点经验:
- 变更头一天改方案,风险比较大
- 删除操作代码要加防呆机制,避免误删
- 重要数据要double check
- 重要代码要组织review
- 危险命令行操作要double check
- 重要变更步骤要程序化,避免过多的命令行操作
06
第二次生产变更(成功)
第二次生产变更之前的数据验证过程中,发现部分用到某个特定Hive UDF作业数据验证失败。原因是自定义UDF跟Hive自带的函数重名,并且业务SQL里面使用既使用了Hive内置函数也使用了自定义UDF,函数加载的顺序不通会导致不一致的结果,最后的解决方案是修改自定义UDF,支持内置函数的输入数据类型。第二次生产变更是非常完美的,6个小时时间,完成切换。切换之后的批量作业碰到了一些问题,总结如下:
- spark创建的表,在property里包含了loction信息,变更的时候没有更新,导致部分spark作业失败
- 部分非SQL类型的作业,代码里指定了HDFS namespace,没有变更,导致部分作业失败
- 部分导数作业因为防火墙的原因失败,紧急开墙解决
07
总结
这次Hadoop集群跨数据中心的迁移是数据底层架构团队近2年来最大也是最复杂的项目,功能的验证涉及超过10个系统,数据比对涉及超过8个部门的数据开发,组织协调的工作也非常琐碎和繁杂;在统一目标的指引下,在比较合理的组织和安排下,团队的各个成员能充分调动起来,发挥各自的能力,最终顺利地完成了这次迁移,这是大家齐心协力努力的结果。在这次升级中,也有很多方面值得我们回顾和改进:
- 首先也是最重要的一点就是对生产抱有敬畏之心,在事前要充分准备,不放过每一个细小的验证点,在变更实施时严格遵循事先制定的变更流程,操作前严格做到Think Twice
- 其次我们要建立与生产环境相同的灰度测试的环境,通过事前在灰度测试环境的演练把升级风险降到最小,这块我们做得并不充分
- 最后我们未来要增强上层平台(主要是Z+)的能力,让他提供更多对于底层升级和变更支持的功能(如灰度上线,失败fallback的功能)
往期回顾
01 |【数据治理系列】数据质量治理实践 |
02 |从数据仓库到数据中台系列之二】 ----数据仓库的模型设计 |
03 |如何在前端实现人脸检测 |
| _ |
