dropout层的作用_15. 详解dropout原理与代码实现
1. 为什么使用dropout?——因为DL中容易过拟合与训练速度慢
在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象。在训练神经网络的时候经常会遇到过拟合的问题,过拟合具体表现在:模型在训练数据上损失函数较小,预测准确率较高;但是在测试数据上损失函数比较大,预测准确率较低。
过拟合是很多机器学习的通病。如果模型过拟合,那么得到的模型几乎不能用。为了解决过拟合问题,一般会采用模型集成的方法,即训练多个模型进行组合。此时,训练模型费时就成为一个很大的问题,不仅训练多个模型费时,测试多个模型也是很费时。
综上所述,训练深度神经网络的时候,总是会遇到两大缺点:
(1)容易过拟合
(2)费时
Dropout可以比较有效的缓解过拟合的发生,在一定程度上达到正则化的效果。
2. 什么是dropout?—— Dropout 会随机删除一些神经元,以在不同批量上训练不同的神经网络架构。
在训练时,每次随机(如50%概率)忽略隐层的某些节点;这样,我们相当于随机从2^H个模型中采样选择模型;同时,由于每个网络只见过一个训练数据(每次都是随机的新网络),所以类似 bagging 的做法,这就是我为什么将它分类到「结合多种模型」中;
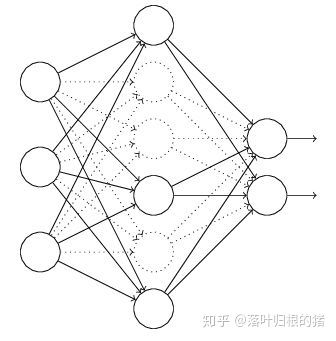
此外,而不同模型之间权值共享(共同使用这 H 个神经元的连接权值),相当于一种权值正则方法,实际效果比 L2 regularization 更好。
我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征。
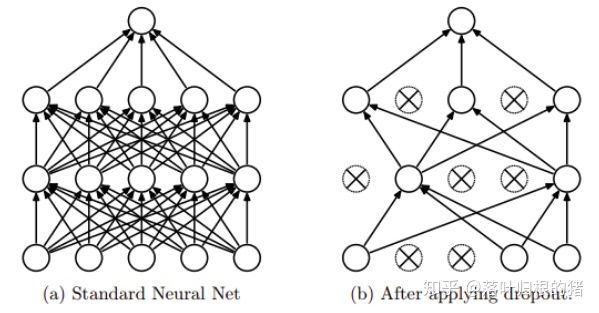
3. dropout如何工作的?
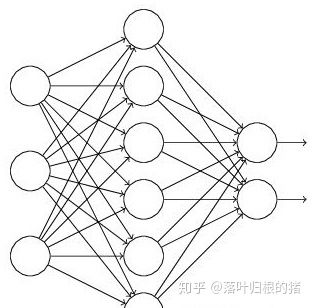
输入是x输出是y,正常的流程是:我们首先把x通过网络前向传播,然后把误差反向传播以决定如何更新参数让网络进行学习。使用Dropout之后,过程变成如下:
(1)首先随机(临时)删掉网络中一半的隐藏神经元,输入输出神经元保持不变(图中虚线为部分临时被删除的神经元)
(2) 然后把输入x通过修改后的网络前向传播,然后把得到的损失结果通过修改的网络反向传播。一小批训练样本执行完这个过程后,在没有被删除的神经元上按照随机梯度下降法更新对应的参数(w,b)。
(3)然后继续重复这一过程:
a. 恢复被删掉的神经元(此时被删除的神经元保持原样,而没有被删除的神经元已经有所更新)
b. 从隐藏层神经元中随机选择一个一半大小的子集临时删除掉(备份被删除神经元的参数)。
c. 对一小批训练样本,先前向传播然后反向传播损失并根据随机梯度下降法更新参数(w,b) (没有被删除的那一部分参数得到更新,删除的神经元参数保持被删除前的结果)。
不断重复这一过程。
4. 为什么dropout可以解决过拟合:
(1)取平均的作用: 先回到标准的模型即没有dropout,我们用相同的训练数据去训练5个不同的神经网络,一般会得到5个不同的结果,此时我们可以采用 “5个结果取均值”或者“多数取胜的投票策略”去决定最终结果。例如3个网络判断结果为数字9,那么很有可能真正的结果就是数字9,其它两个网络给出了错误结果。这种“综合起来取平均”的策略通常可以有效防止过拟合问题。因为不同的网络可能产生不同的过拟合,取平均则有可能让一些“相反的”拟合互相抵消。dropout掉不同的隐藏神经元就类似在训练不同的网络,随机删掉一半隐藏神经元导致网络结构已经不同,整个dropout过程就相当于对很多个不同的神经网络取平均。而不同的网络产生不同的过拟合,一些互为“反向”的拟合相互抵消就可以达到整体上减少过拟合。
(2)减少神经元之间复杂的共适应关系: 因为dropout程序导致两个神经元不一定每次都在一个dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅在其它特定特征下才有效果的情况 。迫使网络去学习更加鲁棒的特征 ,这些特征在其它的神经元的随机子集中也存在。换句话说假如我们的神经网络是在做出某种预测,它不应该对一些特定的线索片段太过敏感,即使丢失特定的线索,它也应该可以从众多其它线索中学习一些共同的特征。从这个角度看dropout就有点像L1,L2正则,减少权重使得网络对丢失特定神经元连接的鲁棒性提高。
(3)Dropout类似于性别在生物进化中的角色:物种为了生存往往会倾向于适应这种环境,环境突变则会导致物种难以做出及时反应,性别的出现可以繁衍出适应新环境的变种,有效的阻止过拟合,即避免环境改变时物种可能面临的灭绝。
代码:
import tensorflow as tf
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelBinarizer
# load data
digits = load_digits()
X = digits.data # 从0-9的图片data
y = digits.target # 十个长度,是一个binary,在哪个长度上放上1就代表是哪个数
y = LabelBinarizer().fit_transform(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.3)
def add_layer(inputs, in_size, out_size, layer_name, activation_function=None, ):
# add one more layer and return the output of this layer
Weights = tf.Variable(tf.random_normal([in_size, out_size]))
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1, )
Wx_plus_b = tf.matmul(inputs, Weights) + biases
# here to dropout、
# dropout是要加载到Wx_plus_b这个结果上的。该结果的50%舍弃,50%保留
# 输出为更新的dropout的结果
Wx_plus_b = tf.nn.dropout(Wx_plus_b, keep_prob) # 这就是实现dropout
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b, )
tf.summary.histogram(layer_name + '/outputs', outputs)
return outputs
# define placeholder for inputs to network
keep_prob = tf.placeholder(tf.float32) # 这个作用是保持多少不被drop掉
xs = tf.placeholder(tf.float32, [None, 64]) # 8x8
ys = tf.placeholder(tf.float32, [None, 10])
# add output layer
l1 = add_layer(xs, 64, 50, 'l1', activation_function=tf.nn.tanh)
prediction = add_layer(l1, 50, 10, 'l2', activation_function=tf.nn.softmax)
# the loss between prediction and real data
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction),
reduction_indices=[1])) # loss
tf.summary.scalar('loss', cross_entropy)
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
sess = tf.Session()
merged = tf.summary.merge_all()
# summary writer goes in here
train_writer = tf.summary.FileWriter("/home/anaconda2/logs/train", sess.graph)
test_writer = tf.summary.FileWriter("/home/anaconda2/logs/test", sess.graph)
# tf.initialize_all_variables() no long valid from
# if using tensorflow >= 0.12
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
init = tf.initialize_all_variables()
else:
init = tf.global_variables_initializer()
sess.run(init)
for i in range(500):
# here to determine the keeping probability
# keep_prob在这里加载,一般选择0.5被drop掉。若想保留60%不被drop掉,那么就写0.6
# keep_prob = 1 就意味着保留全部,不被drop
sess.run(train_step, feed_dict={xs: X_train, ys: y_train, keep_prob: 0.5})
if i % 50 == 0:
# record loss
train_result = sess.run(merged, feed_dict={xs: X_train, ys: y_train, keep_prob: 1})
test_result = sess.run(merged, feed_dict={xs: X_test, ys: y_test, keep_prob: 1})
train_writer.add_summary(train_result, i)
test_writer.add_summary(test_result, i)
下图为无dropout(除去代码中有dropout部分即可,也可以将sess.run中的keep_prob改为 1. 也是意味着不进行dropout):
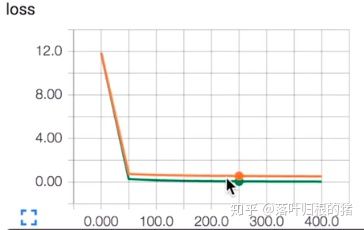
下图为经过dropout处理后的:
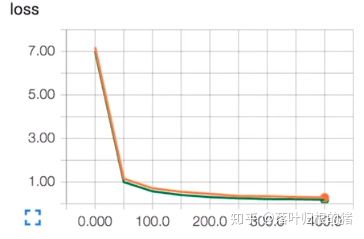
经过dropout处理后的training data和testing data就非常接近了。