深度强化学习CS285-Lec17 Distributed RL
Transfer Learning 与 Distributed RL
- 概述
- 一、分布式RL架构
-
- 1.1 DQN
- 1.2 GORILA
- 1.3 A3C
- 1.4 IMPALA
- 1.5 Ape-X
- 1.6 R2D3
- 二、其它引用较高的分布式RL架构
-
- 2.1 QT-Opt
- 2.2 AlphaZero
- 2.3 提升性能的Trick——PBT
- 三、开源分布式架构——RLlib
- 后记
概述
RL与监督学习的训练过程的区别在于,RL需要与环境进行交互获得样本来估计更新中的梯度,然后更新policy,而policy本身又会影响后续获得的样本。
这样导致的问题有两个:
- policy影响后续样本的特性,会导致轨迹空间中一些high reward的部分没被探索到,即可能只得到sub-optimal的轨迹,而没有得到最优轨迹
- 与环境交互是在CPU中进行的,无法用GPU并行加速,导致RL训练起来特别慢,因此在基本RL算法的基础上,还要分布式训练的系统。
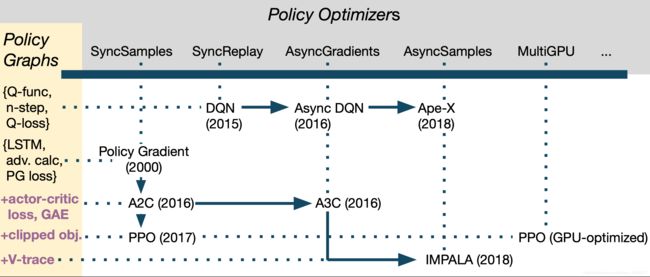
本文将依据此图进行组织:

一、分布式RL架构
1.1 DQN
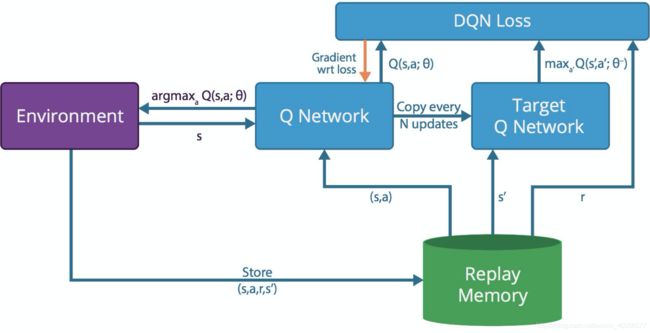

稍微说一下:
- DQN三要素:Q-Network与Environment的交互、Replay Memory、Double Q-Network
- 环境交互:环境状态反馈 s s s、探索与利用 a r g m a x a Q ( s , a ; θ ) argmax_aQ(s,a;\theta) argmaxaQ(s,a;θ)
- Replay Buffer:存储样本 ( s , a , r , s ′ ) (s,a,r,s') (s,a,r,s′)、提供样本,有可能涉及Importance Sampling
- Double Q-Network:计算Q-target value与Q-Current value的loss以及gradient
1.2 GORILA
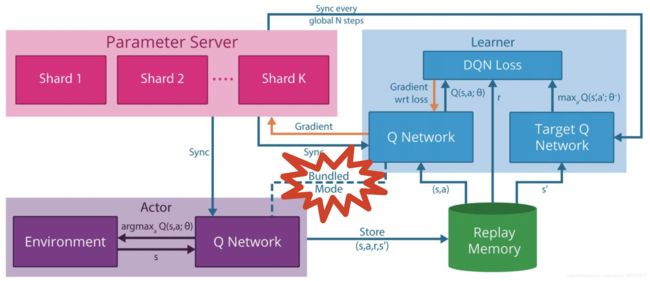
GORILA这里比DQN多了一个Parameter Sever,其它改了下名称,稍微说一下:
- GORILA的四要素:Parameter Server、Learner、Actor、Replay Memory
- Actor:Policy(此处为Q-Network)与环境交互,同样涉及探索与利用,而此处多了一个Bundled Mode即Actor的Policy与Learner中实时更新的Q-Network是捆绑的
- Learner:Double Q-Network的结构、Loss与Gradient的计算
- Replay Memory:在Actor与Learner之间接收样本与提供样本的样本池
- Parameter Server:存储Q-Network中参数的Gradient变化,好处是可以让Q-Network进行回滚,并且可以通过多个Gradient(即历史信息)来使训练过程更加稳定。
1.3 A3C
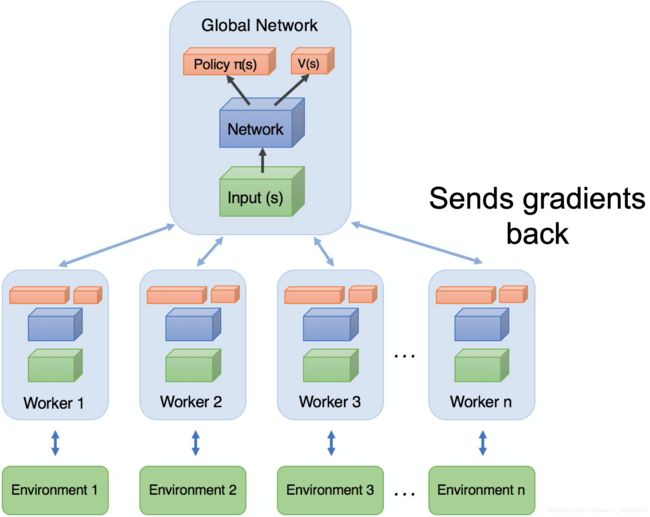
A3C的最大特点:Online、没有Parameter Server、没有公用的Replay Buffer
稍微说一下:
- 每一个Worker实际上包含一个Actor、一个Learner还有一个小Buffer
- 每一个Worker中Learner计算得出Gradient后都发送给Master即Global Network
- 每一个Worker中Actor都可以用不同的探索策略与Environment进行交互,这些样本可以存在一个Worker里的小Buffer中
- Master接收多个Gradient后再更新参数,再把参数copy给所有Worker
优点:
- 每一个Actor与环境的探索策略多样性,使得Samples更多样性,探索到的状态空间更大
- Master等所有Worker都传递了Gradient后再更新,使训练更稳定
- Master更新后的参数copy给所有Actor初始化
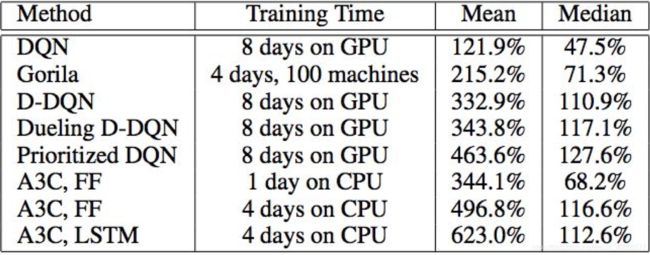
通过性能对比图,再深入理解一下A3C。
因为DQN及其相应Variant与GORILA都有Replay Buffer,里面有大量的样本数据,然后从中取mini-batch来计算更新Learner的参数,Gorila还需要存储网络参数在Parameter Server,因此需要在GPU中并行加速。
而A3C实际上是Actor-Critic的模式,即与环境交互部分是在CPU中进行的,因此每一个Worker都在CPU中与环境进行交互,然后计算Gradient并回传给Master,并不更新自身网络参数,因此只是充当一个Actor的作用,而Critic即为Master,收到Gradient后对网络参数进行更新,然后reset给所有worker。
由于A3C没有replay buffer,不需要从中sample mini-batch实现batch update,因此不需要GPU,也没有Parameter Server来存储之前的网络参数,更容易在CPU中并行~
1.4 IMPALA

IMPALA全称为:Importance Weighted Actor-Learner Architectures
A3C有多个Actor却只有一个Learner即Critic,所以IMPALA把Learner扩充了一下,然后每个Learner都从多个Actor中利用Importance Sampling来sample mini-batch实现自身的更新,更新完后把自身参数传给多个actor中的其中一些。
IMPALA与A3C具体的区别在于:
- 每一个Actor执行的Policy不再是只来自一个Learner,可以来自多个Learner
- 每一个Actor前后设置如果是不同的Learner的话,可以用Importance Sampling来解决
共同点:
- 并没有引入replay buffer,整个分布式系统仍然是online的
1.5 Ape-X

DQN、GORILA有Replay Buffer是off-line的,而A3C与IMPALA去掉了Replay Buffer是on-line的,而Ape-X又引入了Replay Buffer,此处称为Replay Experiences。
由图中可以看到,Ape-X重用了A3C的架构,只不过多了一个Replay Experiences,还有一个Priority Experience Replay。
IMPALA中多个Learner实际上也是为了增加Diversity,探索更大的状态空间,倒不如还是维持一个Replay Buffer,用 ( s , a , r , s ′ ) (s,a,r,s') (s,a,r,s′)样本来冲淡一下轨迹的correlation,而且off-policy对样本利用率更高,因此Ape-X还是引回Replay Buffer的模块。
而且对Experience的Bellman Error来确定一个样本的重要性,实际上与TD Error差不多,虽然为每一个样本计算Bellman Error耗内存与计算资源,但效果好呀,知道哪些样本更重要一点。下面是目前为止分布式RL系统的性能对比图。

1.6 R2D3

之前的RL系统:DQN、GORILA、A3C、IMPALA、Ape-X都是从0 经验开始探索的,这样一开始的训练会比较慢,俗称“冷启动问题”。而19年最新的R2D3则在Ape-X的基础上,增加了一个expert demonstration的replay buff,在Learner Sample Batch的时候,以 p p p的概率从expert demo中采样, 1 − p 1-p 1−p的概率从Agent replay buffer中采样,这样就能比较好解决一开始的冷启动问题,其它与Ape-X一模一样。
为什么Ape-X可以称为R2D2,而这个称为R2D3呢?
R2D2:两个R是Actor,Learner;两个D是Distributed DQN
R2D3:两个R是Actor,Learner;三个D是Distributed DQN with Demonstrations
二、其它引用较高的分布式RL架构
2.1 QT-Opt
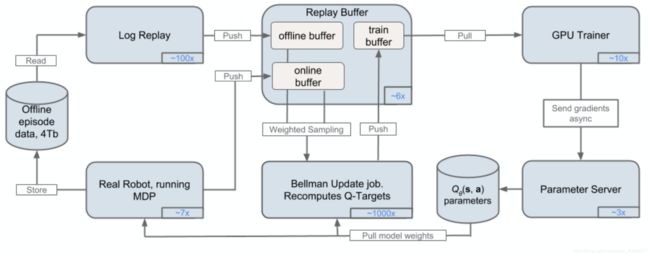
其实QT-Opt没什么特别要讲的,之所以引用较高,是因为Google用了上千台Real Robot去跑,而不是之前在Simulation里面得到的样本,如游戏、仿真环境等,所以这个分布式系统可以看看,是真实robot实践训练哦~
2.2 AlphaZero
AlphaZero要介绍起来比较长,所用技术就是Self-Play与MCTS。
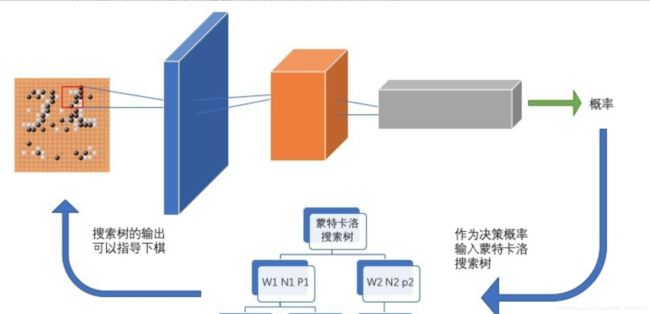
稍微说一下AlphaZero大致架构,如下图:
-
基于当前棋谱的image通过CNN给出落棋的概率
-
然后经过MCTS搜索(涉及很多细节,此处不谈)给出下棋策略
想深入一点点的可以看知乎专栏
想看Paper的,必看David Silver的震惊四部曲- Mastering the game of Go with deep neural networks and tree search.
- Mastering the game of go without human knowledge
- Mastering chess and shogi by self-play with a general reinforcement learning algorithm
- A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play
2.3 提升性能的Trick——PBT


PBT Paper
大致解释下PBT,用来搜索网络的超参数。一般搜索网络的超参数有两种,一是图a的人为手工设计即Sequential Optimisation,人为经验的尝试,串行去尝试网络超参数;二是图b的随机搜索即Grid Search,随机选取一些超参数,并行独立训练多个网络,尝试出把网络性能最好的超参数;
这两者的缺点都比较明显,人工设计比较漫长,Grid Search比较耗费计算资源,所以就出现了图c的PBT。
PBT技术与随机搜索类似,都是从用随机超参数并行训练很多神经网络开始。但是,给个网络不会被独立训练,而是用其他神经网络群的信息来精炼超参数并协调模型间的计算资源。随着神经网络群训练地进行,开发和探索过程为周期性的,确保群中的所有“工作者”基础性能良好。此外,新的超参数也在不断探索中。也就是说,PBT可以快速利用好的超参数,将更多的训练时间投入到有最好的模型中。更重要的是,它可以在整个训练过程中调整超参数值,自动学习最佳结构。
三、开源分布式架构——RLlib
RLlib: Abstractions for Distributed Reinforcement Learning (ICML’18)
然后Eric Liang, Richard Liaw在2018的ICML上提出了一下,关于RL的一个开源框架


有兴趣还是直接去看文档: https://ray.readthedocs.io/en/latest/rllib.html
后记
这节课介绍的东西,可以说是一些基础RL算法的分布式实现。
六个较为关键的系统
- DQN
- GORILA
- A3C
- IMPALA
- Ape-X/R2D2
- R2D3
两个额外的系统
- QT-Opt
- Alpha-Zero
最后一个关于RL的开源框架Ray,集成了很多开源有效的算法,如PBT,后续做实验的时候确实可以研究研究~