【论文简述】Cascade Cost Volume for High-Resolution Multi-View Stereoand Stereo Matching(CVPR 2020)
一、论文简述
1. 第一作者:Xiaodong Gu、Zhiwen Fan
2. 发表年份:2020
3. 发表期刊:CVPR
4. 关键词:MVS、立体匹配、级联、深度学习、CNN
5. 探索动机:目前基于深度学习的立体匹配和MVS方法构建的3D代价体需要3D卷积进行代价聚合/正则化消耗显存非常大,随着分辨率的增加时间和内存以立方级别增长,因此为了节省内存一般网络输出的深度图或者视差图分辨率限制为输入的1/4,再使用其他方式(上采样或后改进)恢复至原始分辨率。R-MVSNet使用循环神经网络,将代价体沿深度切成不同的代价图,利用GRU结构进行正则化处理,相比较MVSNet,能减少GPU内存的消耗。可是循环神经网络会涉及一个遗忘的过程,导致网络不能很好地保留像素周围的纹理信息,所以点云完整度不能得到很好地保留。
6. 工作目标:是否可以用新的结构来,解决MVS和立体匹配中提出的3D代价体正则化消耗过大的问题,并保留有用信息?
7. 核心思想:本文提出了一种级联corse to fine的思想,基于3D代价体构造一种利用级联式代价体,解决MVSNet在深度估计过程中的GPU消耗过大问题、点云完整度不高的深度学习方法。首先,我们提出的代价体是建立在一个能在逐渐增加的合适的尺度上编码几何和上下文信息特征金字塔。其次,我们可以通过前一阶段预测出的结果来缩小深度值或视差的范围。随着逐渐增大的代价体的分辨率和自适应调整的深度或视差间隔,输出以从粗到细的方式恢复。
8. 实验结果:该方法在现有的MVSNet框架下,能以较小的GPU消耗,得到较高精度的深度估计结果,同时也能保留较高的完整度。在MVS上,相对于MVSNet,模型在DTU上精度提升35.6%,GPU 内存使用量降低50.6%,运行时间降低59.3%。在公开的benchmark上:DTU上性能排名第一,在Tank and Temples所有深度模型效果排名第一。在KITTI Stereo上使用Cascade Cost Volume的形式将GwcNet从 29名提升到17名。
9.论文&代码下载:
https://openaccess.thecvf.com/content_CVPR_2020/papers/Gu_Cascade_Cost_Volume_for_High-Resolution_Multi-View_Stereo_and_Stereo_Matching_CVPR_2020_paper.pdf
https: //github.com/alibaba/cascade-stereo
二、实现过程
1.代价体计算
MVS:通过单应性矩阵构建
Stereo Matching:连接体、作差、相关体、组相关、构建
代价体
构建目的:构造三维代价体来度量相应图像块之间的相似度并判断它们是否匹配。
主要步骤:
- 假设离散的深度平面。
- 将每个视图提取的特征图变换到假设平面上,构造特征体;
- 将不同视角的特征体融合在一起,形成三维代价体。
一个标准的代价体如下图,体积为W x H x D x F, 其中W× H为空间分辨率,D为平面假设数,I为平面间隔,F为特征图通道数。右:影响效率(运行时和GPU内存)和精度的因素
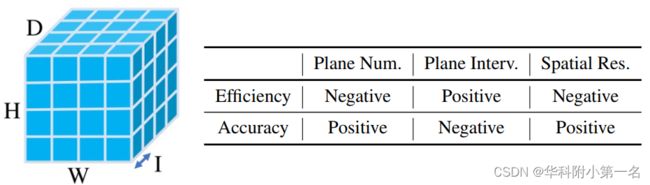
3D 正则化/聚合的意义
Pixelwise cost calculation is generally ambiguous in inherently ill-posed regions such as occlusion areas, repeated patterns, textureless regions, and reflective surfaces. To solve this, 3D CNNs at multiple scales are generally introduced to aggregate contextual information and regularize the possibly noise-contaminated cost volumes.
2. 实现过程
本文提出的级联代价体在MVSNet上的网络结构如下,记为MVSNet+Ours
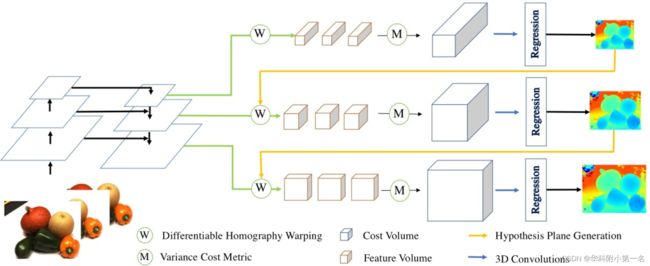
2.1. 特征提取:以前的工作通常为了节省内存和时间使用分辨率较低的代价体生成深度(或视差)图,然后使用2D卷积对其进行上采样和改进以获得高分辨率深度(或视差)图。代价体通常是使用金字塔顶层特征图构建的,顶层特征图包含高级语义特征,但缺乏低级细节的表示。本文使用特征金字塔网络FPN提取三个不同维度的特征图,它们对应的空间分辨率是输入图像大小的1/16、1/4、1。
2.2. 特征体构建:将分辨率为1/16的N张source images的特征利用单应性变换,类似极线搜索,转换到reference image前的视锥体上构建N个三D特征体。
2.3. 首个代价体构建:将N个特征体通过计算方差,聚合至一个代价体,因此提出了一个N-视图的相似性度量的代价指标。方差越小,说明在该深度上置信度越高。
2.4. 首个深度图:通过将代价体转换为概率体,再使用softmax计算深度图。
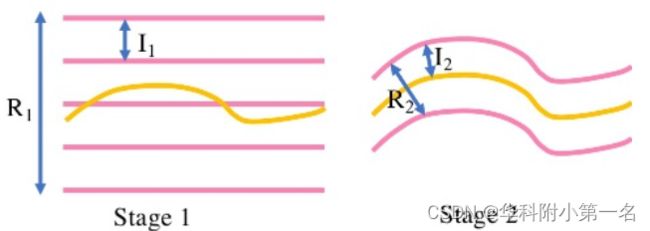
2.5. 级联代价体:深度假设是代价体构建的重要步骤,以往的代价体构建都是使用固定的深度假设范围,如MVSNet中使用192,且深度的间距为定值。
- 级联代价体通过上一次深度图预测的情况(首个代价体及首个深度图)缩小本次深度假设范围,如上图。因为在第一阶段,没有上一阶段的深度假设,在本文中使用范围较大且间隔相对较大的深度假设,R1是深度估计范围,I1是间距,粉色的线是假设深度,以生成更大的深度图,深度估计范围将包含整个场景的深度(或视差)范围。有了这个值进入下一阶段,就可以降低深度间隔和假设范围了。
- 在第二阶段,黄线是上一阶段深度预测值,R2是第二次的深度假设范围,I2是间隔,易知深度假设范围越小,相同分辨率的代价体内存消耗越少,越小的深度估计间隔也代表着越精细的深度估计精度。
- 重复以上步骤,完成第三阶段。因此,构建三个级别的代价体(1/4 → 1/2 → 1),生成三个级别的深度图。
- 在级联式代价体构造过程中,每个阶段的图像的分辨率是之前的两倍。总结,就是把模型中单一的代价体加正则化的形式更换为一种级联代价体,并且越靠后阶段的代价体其深度/视差图越少,空间分辨率越高,使用更高分辨率的特征来恢复更多细节。
级联代价体之后的阶段学习的是残差深度/视差,而不是整个深度。第二及第三阶段的单应性变换矩阵为:
其中,dmk表示在第k级处的第m像素的预测深度,∆mk+1是要在k+1阶段学习的第m像素的残差深度。即,用不同的∆构造更多(或更精细)的深度平面。自适应的深度采样确保了计算和内存资源用在更有意义的区域上,可以显著减少计算时间和GPU内存消耗。
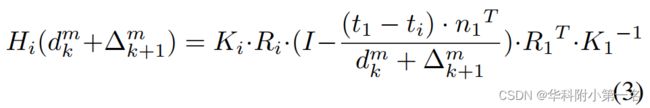
深度采样参考:https://blog.csdn.net/double_ZZZ/article/details/123459065
2.6. 损失:和MVSNet中的L1相同,只是将不同阶段的loss计算加权级联式的学习策略,定义为:
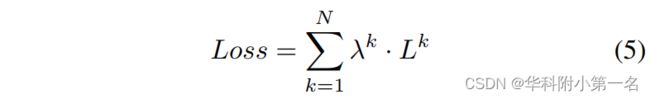
其中,Lk指的是第k个阶段的Loss,λk则表示当前阶段的权重。一般来说,分辨率越高,设置的权重越大。
2.7.不进行refinement
2.8. 后处理:光度一致性滤波,几何一致性滤波和深度融合。
3. 实验
3.1. MVS
数据集:DTU Dataset、Tanks and Temples Benchmark
DTU is a large-scale MVS dataset consisting of 124 different scenes scanned in 7 different lighting conditions at 49 or 64 positions. Tanks and Temples dataset contains realistic scenes with small depth ranges. More specifically, its intermediate set is consisted of 8 scenes including Family, Francis, Horse, Lighthouse, M60, Panther, Playground, and Train.
训练:训练图像大小设置为W × H = 640 × 512,输入视图数N = 3,深度假设数:48,32,8,深度间隔:4倍,2倍,1倍,特征图:原始图像的1/16,1/4,1。
评价基准:accuracy、completeness、overall score,
结果:MVSNet with cascade cost volume outperforms other methods in both completeness and overall quality and rank the 1st place on DTU dataset, with the improvement of 35.6%, and the decrease of memory, run-time reduction of 50.6% and 59.3%. The qualitative results are shown in Figure 5. We can see that MVSNet+Ours generates more complete point clouds with finer details.
3.2. Stereo Matching
数据集:Scene Flow、KITTI 2015、Middlebury
训练:在Scene Flow中,将PSMNet,GwcNet和GANet11扩展为PSMNet+Ours,GwcNet+Ours和GANet11+Ours。为了平衡准确性和效率,采用了两阶段级联代价体,且视差假设数为12。相应的视差间隔分别设置为4和1像素。特征图的空间分辨率从原始输入图像尺寸的1/16提高到1/4。最大视差设置为192。在KITTI 2015基准中,主要比较GwcNet和GwcNet+Ours。
评价基准:EPE、 D1
结果:都提升了。
The obvious improvement on >1px indicates that small errors are suppressed with the introduction of high-resolution cost volumes.
3.3. Ablation Studies
Cascade Stage Number:overall质量先显著增加,后平稳,最终选择的是3阶段模型,深度假设数:96,48,48,深度间隔:2,2,1
Parameter Sharing:级联代价体不同阶段分别学习效果更好
Spatial Resolution:空间分辨率越高效果越好,更高的空间分辨率也会增加GPU内存和运行时间
feature pyramid:通过特征图金字塔增加代价体分辨率,空间分辨率的提高对重建结果的影响大
参考
CasMVSNet理解 https://blog.csdn.net/qq_43027065/article/details/118519223?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromBaidu~Rate-1-118519223-blog-127420555.pc_relevant_3mothn_strategy_and_data_recovery&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromBaidu~Rate-1-118519223-blog-127420555.pc_relevant_3mothn_strategy_and_data_recovery&utm_relevant_index=2
https://blog.csdn.net/qq_43027065/article/details/118519223?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromBaidu~Rate-1-118519223-blog-127420555.pc_relevant_3mothn_strategy_and_data_recovery&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromBaidu~Rate-1-118519223-blog-127420555.pc_relevant_3mothn_strategy_and_data_recovery&utm_relevant_index=2