Flink1.11.0读取kafka数据动态写入hive中(更新-解决hive查询不到数据问题)
一、主要流程
flink 1.11.0 hive 2.3.4 kafka 2.11 hadoop 2.7.2 scala 2.1.11
流批混合,读取kafka 数据量写入到hive中
主要参考官网: https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/table/hive/hive_streaming.html
flink写入hive,hive查询不到数据解决方案分析在另一文章:https://blog.csdn.net/m0_37592814/article/details/108296458
完整代码已提交到github上:https://github.com/tianyadaochupao/crawler
二、主要步骤
1.在flink sql 客户端中创建hive 分区表
flink sql 客户端配置在上一篇文章: https://blog.csdn.net/m0_37592814/article/details/108038823
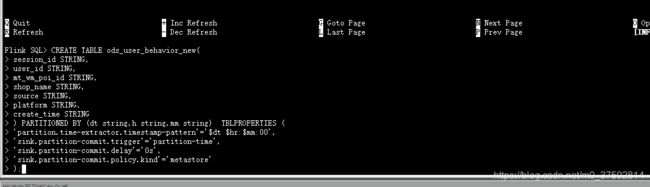
建表语句 ---更新 ---添加 自定义分区时间抽取类
以 天、小时、分钟 三级hive分区
use wm;
CREATE TABLE ods_user_behavior_new(
session_id STRING,
user_id STRING,
mt_wm_poi_id STRING,
shop_name STRING,
source STRING,
platform STRING,
create_time STRING
) PARTITIONED BY (dt string,hr string,mm string) TBLPROPERTIES (
'partition.time-extractor.kind'='custom',
'partition.time-extractor.timestamp-pattern'='$dt $hr:$mm:00',
'partition.time-extractor.class'='com.tang.crawler.flink.MyPartTimeExtractor',
'sink.partition-commit.trigger'='partition-time',
'sink.partition-commit.delay'='0s',
'sink.partition-commit.policy.kind'='metastore'
);2.添加自定义分区抽取类
package com.tang.crawler.flink;
import org.apache.flink.table.data.TimestampData;
import org.apache.flink.table.filesystem.PartitionTimeExtractor;
import javax.annotation.Nullable;
import java.time.*;
import java.time.format.*;
import java.time.temporal.ChronoField;
import java.util.List;
import static java.time.temporal.ChronoField.*;
import static java.time.temporal.ChronoField.DAY_OF_MONTH;
import static java.time.temporal.ChronoField.MONTH_OF_YEAR;
public class MyPartTimeExtractor implements PartitionTimeExtractor {
private static final DateTimeFormatter TIMESTAMP_FORMATTER = new DateTimeFormatterBuilder()
.appendValue(YEAR, 1, 10, SignStyle.NORMAL)
.appendLiteral('-')
.appendValue(MONTH_OF_YEAR, 1, 2, SignStyle.NORMAL)
.appendLiteral('-')
.appendValue(DAY_OF_MONTH, 1, 2, SignStyle.NORMAL)
.optionalStart()
.appendLiteral(" ")
.appendValue(HOUR_OF_DAY, 1, 2, SignStyle.NORMAL)
.appendLiteral(':')
.appendValue(MINUTE_OF_HOUR, 1, 2, SignStyle.NORMAL)
.appendLiteral(':')
.appendValue(SECOND_OF_MINUTE, 1, 2, SignStyle.NORMAL)
.optionalStart()
.appendFraction(ChronoField.NANO_OF_SECOND, 1, 9, true)
.optionalEnd()
.optionalEnd()
.toFormatter()
.withResolverStyle(ResolverStyle.LENIENT);
private static final DateTimeFormatter DATE_FORMATTER = new DateTimeFormatterBuilder()
.appendValue(YEAR, 1, 10, SignStyle.NORMAL)
.appendLiteral('-')
.appendValue(MONTH_OF_YEAR, 1, 2, SignStyle.NORMAL)
.appendLiteral('-')
.appendValue(DAY_OF_MONTH, 1, 2, SignStyle.NORMAL)
.toFormatter()
.withResolverStyle(ResolverStyle.LENIENT);
@Nullable
private String pattern ="$dt $hr:$mm:00";
public MyPartTimeExtractor(@Nullable String pattern) {
if(null!=pattern){
this.pattern = pattern;
}
}
public MyPartTimeExtractor() {
}
@Override
public LocalDateTime extract(List partitionKeys, List partitionValues) {
String timestampString;
if (pattern == null) {
timestampString = partitionValues.get(0);
System.out.println("时间戳:"+timestampString);
} else {
timestampString = pattern;
for (int i = 0; i < partitionKeys.size(); i++) {
timestampString = timestampString.replaceAll(
"\\$" + partitionKeys.get(i),
partitionValues.get(i));
}
}
return toLocalDateTime(timestampString).plusHours(-8);
}
public static LocalDateTime toLocalDateTime(String timestampString) {
try {
return LocalDateTime.parse(timestampString, TIMESTAMP_FORMATTER);
} catch (DateTimeParseException e) {
return LocalDateTime.of(
LocalDate.parse(timestampString, DATE_FORMATTER),
LocalTime.MIDNIGHT);
}
}
public static long toMills(LocalDateTime dateTime) {
return TimestampData.fromLocalDateTime(dateTime).getMillisecond();
}
public static long toMills(String timestampString) {
return toMills(toLocalDateTime(timestampString));
}
}
3.读取kafka数据写入到hive表中
hive 开启 hive --service metastore

kafka 数据格式如下:
{"createTime":"2020-08-16 16:10:57","mtWmPoiId":"123456","platform":"3","sessionId":"3444444","shopName":"店名","source":"shoplist","userId":"268193426"}
读取kafka 写入到hive表中
package com.tang.crawler.flink
import java.text.SimpleDateFormat
import java.time.Duration
import java.util.Properties
import com.alibaba.fastjson.{JSON, JSONObject}
import org.apache.flink.api.common.eventtime.{SerializableTimestampAssigner, WatermarkStrategy}
import org.apache.flink.api.common.functions.MapFunction
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.{CheckpointingMode, TimeCharacteristic}
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011
import org.apache.flink.table.api.bridge.scala.StreamTableEnvironment
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.catalog.hive.HiveCatalog
object UserBeheviorFlink {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val tableEnv = StreamTableEnvironment.create(env)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.enableCheckpointing(1000,CheckpointingMode.EXACTLY_ONCE)
//kafka属性
val properties = new Properties()
properties.setProperty("bootstrap.servers", "ELK01:9092")
properties.setProperty("group.id", "consumer-group")
properties.setProperty("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("auto.offset.reset", "latest")
//flink 一般由三部分组成 1.source 2.算子 3.sink
//1.source输入---kafka作为source
//入参 topic SimpleStringSchema--读取kafka消息是string格式 properties kafka的配置
val kafkaSource = new FlinkKafkaConsumer011[String]("user_behavior", new SimpleStringSchema(), properties)
val inputStream = env.addSource( kafkaSource)
val stream: DataStream[UserBehavior] = inputStream.map(new MapFunction[String,UserBehavior] {
override def map(value: String): UserBehavior = {
val jsonObject: JSONObject = JSON.parseObject(value)
val sessionId = jsonObject.getString("sessionId")
val userId = jsonObject.getString("userId")
val mtWmPoiId = jsonObject.getString("mtWmPoiId")
val shopName = jsonObject.getString("shopName")
val platform = jsonObject.getString("platform")
val source = jsonObject.getString("source")
val createTime = jsonObject.getString("createTime")
val dt = formatDateByFormat(createTime,"yyyy-MM-dd")
val hr = formatDateByFormat(createTime,"HH")
val mm = formatDateByFormat(createTime,"mm")
UserBehavior(sessionId,userId,mtWmPoiId,shopName,platform,source,createTime,dt,hr,mm)
}
}).assignTimestampsAndWatermarks(WatermarkStrategy.forBoundedOutOfOrderness[UserBehavior](Duration.ofSeconds(20))
.withTimestampAssigner(new SerializableTimestampAssigner[UserBehavior] {
val dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
override def extractTimestamp(element: UserBehavior, recordTimestamp: Long): Long = {
val create_time = element.create_time
val date = dateFormat.parse(create_time)
date.getTime
}
}))
val name = "myHive"
val defaultDatabase = "wm"
val hiveConfDir = "D:\\tang-spark2\\crawler\\src\\main\\resources"
val version = "2.3.4"
val hive = new HiveCatalog(name, defaultDatabase, hiveConfDir, version)
tableEnv.registerCatalog("myHive", hive)
tableEnv.useCatalog("myHive")
//流转为表
tableEnv.createTemporaryView("user_behavior",stream)
/*tableEnv.executeSql("""
|INSERT INTO ods_user_behavior_new
|SELECT session_id, user_id,mt_wm_poi_id,shop_name,source,platform,create_time,dt,hr,mm
|FROM user_behavior
""".stripMargin)*/
tableEnv.executeSql("INSERT INTO ods_user_behavior_new SELECT session_id, user_id,mt_wm_poi_id,shop_name,source,platform,create_time,dt,hr,mm FROM user_behavior")
print("执行成功")
env.execute()
}
def formatDateByFormat (dateString:String,format: String ): String = {
val sourceDateFormat: SimpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
val date = sourceDateFormat.parse(dateString)
val targetDateFormat: SimpleDateFormat = new SimpleDateFormat(format)
val time = targetDateFormat.format(date)
time
}
case class UserBehavior(session_id: String,user_id: String,mt_wm_poi_id: String,shop_name: String,source: String,platform: String,create_time:String,dt:String,hr:String,mm:String)
}3.验证
hdfs验证

hive查询验证:

有个小坑:代码写入hive 时没有往
metastore更新分区信息,造成hive查询不到scala代码写入hive表中的数据
我这里是在hive执行 : 创建分区后才查询出数据
msck repair table ods_user_behavior_new;
------------------------小坑解决-------------------------更新------metastore不更新分区信息解决方案--------------------------------------------------
方案分析参考下一篇文章:https://blog.csdn.net/m0_37592814/article/details/108296458
1.hive建表语句添加配置项使用自定义分区时间抽取类 ---参考上面主要步骤中的建表语句

2. 自定义分区抽取类 ---参考上面主要步骤中的添加自定义分区抽取类
3.部署(更新)。自定义的分区时间抽取类部署,把该类打成jar包,放到flink 的lib目录下(每台集群都放)
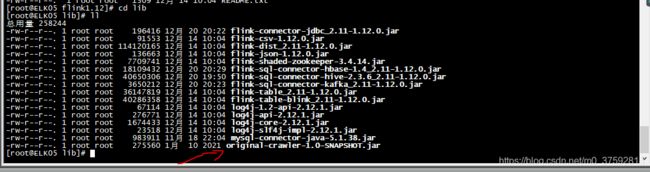
这样在sqlClient中也可以使用添加此类的表
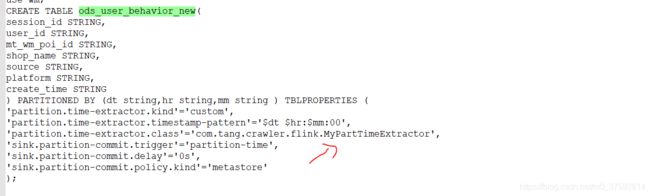
插入语句

查询语句结果

提交到集群上
