深度学习必会10题
目录
- 前言
- 一、sigmoid和softmax的区别和联系?
- 二、分类一般用什么损失函数?交叉熵的公式是什么?
-
- 1.0-1损失函数:
- 2.Hinge loss::
- 三、训练中出现过拟合的原因?深度学习里的正则方法有哪些/如何防止过拟合?
- 四、l1、l2原理?dropout具体实现原理,随机还是固定,训练过程和测试过程如何控制,是针对sample还是batch?
- 五、weight decay和范数正则有什么关系?
- 六、详细比较sigmoid、relu、leaky-relu等激活函数?
-
- 1.sigmoid公式:
- 2. tanh公式:
- 3. ReLU公式:
- 4. Leaky ReLU公式:
- 5. ELU公式:
- 七、说说BN,BN的全称,BN的作用,为什么能解决梯度爆炸?BN一般放在哪里?
- 八、skip connection的作用
- 九、图像分割领域常见的loss function?
- 十、BN应该放在非线性激活层的前面还是后面?
- 总结
前言
一个面试小笔记xxx
一、sigmoid和softmax的区别和联系?
答:sigmoid将一个real value映射到(0,1)的区间,用来做二分类。 而 softmax 把一个 k 维的real
value向量(a1,a2,a3,a4….)映射成一个(b1,b2,b3,b4….),其中 bi 是一个 0~1 的常数,输出神经元之和为1.0,所以相当于概率值,然后可以根据 bi 的概率大小来进行多分类的任务。
二分类问题时 sigmoid 和 softmax 是一样的,求的都是 cross entropy loss(交叉熵损失),而 softmax 可以用于多分类问题。softmax是sigmoid的扩展,因为,当类别数 k=2 时,softmax 回归退化为 logistic 回归。
二、分类一般用什么损失函数?交叉熵的公式是什么?
1.0-1损失函数:

函数曲线:

函数曲线为如上的阶梯函数。有三个特点:不连续,非凸,不平滑。由于这三个特点,损失函数的优化难度很大
2.Hinge loss::
在0-1 loss函数基础上,做了两点改动:对于正例(y[i] = 1), f(x[i])必须大于等于1;而对于负例(y[i] = -1), f(x[i])必须小于等于-1 (相比之前f(x[i])与0对比,加强条件,提高稳定性);没有达到要求的情况,视为错误。f(x[i])权值偏离越大,错误越严重。
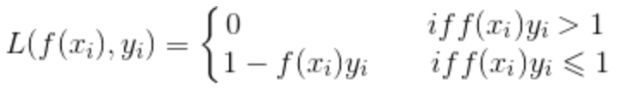
函数曲线(连续,凸,非平滑):

cross-entropy loss(log loss):
常用于多分类问题,描述了概率分布之间的不同,y是标签,p是预测概率:
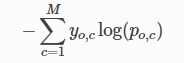
在逻辑回归也就是二分类问题中,上述公式可以写成:
![]()
这就是logistic loss。logistic loss 其实是 cross-entropy loss 的一个特例。
三、训练中出现过拟合的原因?深度学习里的正则方法有哪些/如何防止过拟合?
答:1)数据集不够;
2)参数太多,模型过于复杂,容易过拟合;
3)权值学习过程中迭代次数太多,拟合了训练数据中的噪声和没有代表性的特征。
Regularization is a technique which makes slight modifications to the learning algorithm such that the model generalizes better.正则化是一种技术,通过调整可以让算法的泛化性更好,控制模型的复杂度,避免过拟合。
1)L1&L2正则化;
2)Dropout(指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。注意是暂时,对于随机梯度下降来说,由于是随机丢弃,故而每一个mini-batch都在训练不同的网络);
3)数据增强、加噪;
4)early stopping(提前终止训练);
5)多任务联合;
6)加BN。
四、l1、l2原理?dropout具体实现原理,随机还是固定,训练过程和测试过程如何控制,是针对sample还是batch?
答:L1 正则化向目标函数添加正则化项,以减少参数的绝对值总和;而 L2 正则化中,添加正则化项的目的在于减少参数平方的总和。线性回归的L1正则化通常称为LASSO(Least Absolute Shrinkage and Selection Operator)回归。LASSO回归可以使得一些特征的系数变小,甚至还有一些绝对值较小的系数直接变为0,从而增强模型的泛化能力,因此特别适用于参数数目缩减与参数的选择,因而用来估计稀疏参数的线性模型。
dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。注意是暂时,对于随机梯度下降来说,由于是随机丢弃,故而每一个mini-batch都在训练不同的网络。训练的时候使用dropout,测试的时候不使用。
Dropout的思想是训练DNNs的整体然后平均整体的结果,而不是训练单个DNN。DNNs以概率p丢弃神经元,因此保持其它神经元概率为q=1-p。当一个神经元被丢弃时,无论其输入及相关的学习参数是多少,其输出都会被置为0。丢弃的神经元在训练阶段的前向传播和后向传播阶段都不起作用:因为这个原因,每当一个单一的神经元被丢弃时,训练阶段就好像是在一个新的神经网络上完成。大概是sample吧。(我感觉有点像非结构化稀疏剪枝)
五、weight decay和范数正则有什么关系?
答:weight decay特指神经网络的正则化,是放在正则项前的一个系数,正则项表示模型的复杂度,
weight decay的作用就是调节模型复杂度对损失函数的影响。一般用l2 正则化。
六、详细比较sigmoid、relu、leaky-relu等激活函数?
1.sigmoid公式:
![]()

它输入实数值并将其“挤压”到0到1范围内,适合输出为概率的情况,但是现在已经很少有人在构建神经网络的过程中使用sigmoid。
Sigmoid函数饱和使梯度消失。当神经元的激活在接近0或1处时会饱和,在这些区域梯度几乎为0,这就会导致梯度消失,几乎就有没有信号通过神经传回上一层。
Sigmoid函数的输出不是零中心的。因为如果输入神经元的数据总是正数,那么关于w的梯度在反向传播的过程中,将会要么全部是正数,要么全部是负数,这将会导致梯度下降权重更新时出现z字型的下降。
sigmoid的软饱和性,使得深度神经网络在二三十年里一直难以有效的训练,是阻碍神经网络发展的重要原因。具体来说,由于在后向传递过程中,sigmoid向下传导的梯度包含了一个 f′(x)f′(x) 因子(sigmoid关于输入的导数),因此一旦输入落入饱和区,f′(x)f′(x)就会变得接近于0,导致了向底层传递的梯度也变得非常小。此时,网络参数很难得到有效训练。这种现象被称为梯度消失。一般来说, sigmoid网络在 5 层之内就会产生梯度消失现象。此外,sigmoid函数的输出均大于0,使得输出不是0均值,这称为偏移现象,这会导致后一层的神经元将得到上一层输出的非0均值的信号作为输入。
---------------------------------------------------------------------------------------------------------------------from another writer
2. tanh公式:
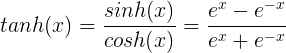
Tanh非线性函数图像如下图所示,它将实数值压缩到[-1,1]之间。
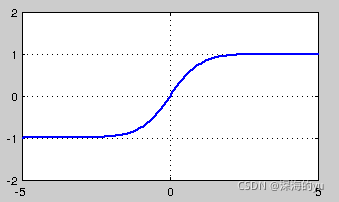
Tanh解决了Sigmoid的输出是不是零中心的问题,但仍然存在饱和问题。为了防止饱和,现在主流的做法会在激活函数前多做一步batch normalization,尽可能保证每一层网络的输入具有均值较小的、零中心的分布。
3. ReLU公式:
![]()
ReLU非线性函数图像如下图所示。
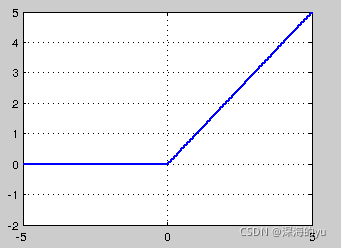
- sigmoid和tanh在求导时含有指数运算,而ReLU求导几乎不存在任何计算量。
- 单侧抑制;
- 稀疏激活性;
- ReLU单元比较脆弱并且可能“死掉”,而且是不可逆的,因此导致了数据多样化的丢失。通过合理设置学习率,会降低神经元“死掉”的概率。
4. Leaky ReLU公式:
![]()
其中α是很小的负数梯度值,比如0.01,Leaky ReLU非线性函数图像如下图所示。这样做目的是使负轴信息不会全部丢失,解决了ReLU神经元“死掉”的问题。
5. ELU公式:


融合了sigmoid和ReLU,左侧具有软饱和性,右侧无饱和性。右侧线性部分使得ELU能够缓解梯度消失,而左侧软饱能够让ELU对输入变化或噪声更鲁棒。ELU的输出均值接近于零,所以收敛速度更快。在ImageNet上,不加 Batch Normalization 30 层以上的 ReLU网络会无法收敛,PReLU网络在MSRA的Fan-in (caffe )初始化下会发散,而 ELU网络在Fan-in/Fan-out下都能收敛
ELU函数是针对ReLU函数的一个改进型,相比于ReLU函数,在输入为负数的情况下,是有一定的输出的,而且这部分输出还具有一定的抗干扰能力。这样可以消除ReLU死掉的问题,不过还是有梯度饱和和指数运算的问题。
七、说说BN,BN的全称,BN的作用,为什么能解决梯度爆炸?BN一般放在哪里?
答:Batch Normalization。归一化的作用,经过BN的归一化消除了尺度的影响,避免了反向传播时因为权重过大或过小导致的梯度消失或爆炸问题,从而可以加速神经网络训练。BN一般放在激活函数前面。
1)BN归一化的维度是[N,H,W],那么channel维度上(N,H,W方向)的所有值都会减去这个归一化的值,对小的batch size效果不好;
2)LN归一化的维度是[H,W,C],那么batch维度上(H,W,C方向)的所有值都会减去这个归一化的值,主要对RNN作用明显;
3)IN归一化的维度是[H,W],那么H,W方向的所有值都会减去这个归一化的值,用在风格化迁移;
4)GN是将通道分成G组,归一化的维度为[H,W,C//G]。

八、skip connection的作用
答:防止梯度消失;传递浅层信息,比如边缘、纹理和形状。CNNs with skip connections have been the main stream for modern network design since it can mitigate the gradient vanishing/exploding issue in ultra deep networks by the help of skip connections.
九、图像分割领域常见的loss function?
答:
第一,softmax+cross entropy loss,比如fcn和u-net。
第二,第一的加权版本,比如segnet,每个类别的权重不一样。第三,使用adversarial training,加入gan loss。
第四,sigmoid+dice loss,比如v-net,只适合二分类。
第五,online bootstrapped cross entropy loss,比如FRNN。
第六,类似于第四,sigmoid+jaccard(IoU),只适合二分类,但是可推广到多类。)
十、BN应该放在非线性激活层的前面还是后面?
答:在BN的原始论文中,BN是放在非线性激活层前面的。但是现在目前在实践中,倾向于把BN放在ReLU后面,也有评测表明BN放ReLu后面更好。还有一种观点,BN放在非线性函数前还是后取决于你想要normalize的对象,更像一个超参数。
总结
2021-11-14