- 【人工智能之深度学习】1. 深度学习基石:神经元模型与感知机的数学本质(附代码实现与收敛性证明)
AI_DL_CODE
人工智能之深度学习人工智能深度学习神经元模型感知机赫布法则深度学习基础线性可分
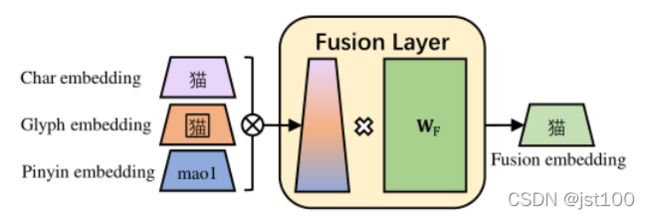
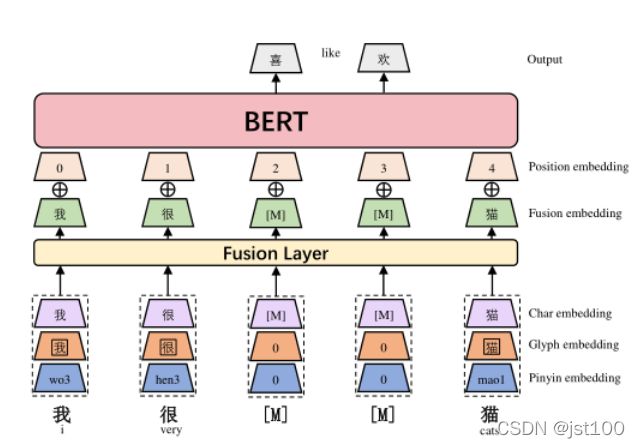
摘要:作为深度学习的基础单元,神经元模型与感知机承载着从生物智能到人工神经网络的桥梁作用。本文从生物神经元的工作机制出发,系统剖析数学建模过程:详解赫布法则的权重更新原理(Δwi=η·xi·y),推导McCulloch-Pitts神经元模型的数学表达(y=Θ(∑wixi−b)),重点证明感知机在linear可分情况下的收敛性——通过Novikoff定理严格推导迭代次数上界,揭示间隔γ对收敛速度的影
- 女性职业新趋势:揭秘未来高薪热门行业
氧惠爱高省
女生在职业选择上拥有广阔的空间,尤其是在当前快速发展的社会背景下,一些行业不仅成为了高薪热门,还提供了多样化的职业路径。以下是一些可能成为女生高薪热门选择的行业:➤推荐网购返利app“氧惠”,一个领隐藏优惠券+现金返利的平台。氧惠只提供领券返利链接,下单全程都在淘宝、京东、拼多多等原平台,更支持抖音、快手电商、外卖红包返利等。科技与互联网行业人工智能与大数据:随着人工智能和大数据技术的广泛应用,相
- 深度学习在环境感知中的应用:案例与代码实现
让机器学会“看”世界:深度学习如何赋能环境感知?关键词深度学习|环境感知|计算机视觉|传感器融合|语义分割|目标检测|自动驾驶摘要环境感知是机器与外界互动的“眼睛和耳朵”——从自动驾驶汽车识别行人,到智能机器人避开障碍物,再到城市监控系统检测异常,所有智能系统都需要先“理解”环境,才能做出决策。传统环境感知方法依赖手工特征提取,难以应对复杂场景;而深度学习通过数据驱动的方式,让机器从大量数据中自动
- 自编码器表征学习:重构误差与隐空间拓扑结构的深度解析
码字的字节
机器学习自编码器重构误差隐空间
自编码器基础与工作原理自编码器(Autoencoder)作为深度学习领域的重要无监督学习模型,其核心思想是通过模拟人类认知过程中的"压缩-解压"机制实现数据的表征学习。这种由GeoffreyHinton团队在2006年复兴的神经网络结构,本质上是一个试图通过编码-解码过程来复制其输入的系统,却在实现这一看似简单目标的过程中,意外地获得了强大的特征提取能力。基本架构与工作流程典型自编码器由对称的两部
- 基于YOLOv8的Web端交互式目标检测系统设计与实现
YOLO实战营
YOLO前端目标检测人工智能ui目标跟踪计算机视觉
1.引言目标检测是计算机视觉领域的一项重要任务,它在安防监控、自动驾驶、医疗影像分析等领域有着广泛的应用。近年来,随着深度学习技术的快速发展,YOLO(YouOnlyLookOnce)系列算法因其出色的速度和精度平衡而备受关注。本文将详细介绍如何基于最新的YOLOv8模型构建一个Web端交互式目标检测系统,包含完整的UI界面设计和数据集处理流程。本系统将实现以下功能:基于YOLOv8的高效目标检测
- 交错并联Buck+LLC变换器的建模与控制优化研究
交错并联Buck+LLC变换器的建模与控制优化研究前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家,觉得好请收藏。点击跳转到网站。摘要本文针对宽输入电压范围(200-450V)、多电压输出(12-48V)的高效DC-DC变换系统,提出了一种基于交错并联Buck预调节器和LLC谐振变换器的两级式拓扑结构。中间母线电压设定为200V,系统输出功率为1500W,要求电压和
- 基于卷积神经网络与小波变换的医学图像超分辨率算法复现
神经网络15044
python算法cnn算法人工智能图像处理开发语言神经网络深度学习
基于卷积神经网络与小波变换的医学图像超分辨率算法复现前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家,觉得好请收藏。点击跳转到网站。1.引言医学图像超分辨率技术在临床诊断和治疗规划中具有重要意义。高分辨率的医学图像能够提供更丰富的细节信息,帮助医生做出更准确的诊断。近年来,深度学习技术在图像超分辨率领域取得了显著进展。本文将复现一种结合卷积神经网络(CNN)、小波变
- 使用MMDetection中的Mask2Former和X-Decoder训练自定义数据集及结果复现
神经网络15044
算法python分类矩阵人工智能数据挖掘深度学习
使用MMDetection中的Mask2Former和X-Decoder训练自定义数据集及结果复现前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家,觉得好请收藏。点击跳转到网站。1.引言1.1研究背景实例分割是计算机视觉领域的重要任务,它要求模型不仅要检测图像中的对象,还要精确地分割出每个对象的像素级掩码。近年来,基于Transformer的模型在实例分割任务上取得
- OpenCV引擎:驱动实时应用开发的科技狂飙
芯作者
DD:计算机科学领域opencv计算机视觉
在人工智能与计算机视觉技术迅猛发展的今天,实时图像处理已成为工业自动化、自动驾驶、医疗诊断、增强现实等领域的核心技术需求。而**OpenCV(OpenSourceComputerVisionLibrary)**作为全球最活跃的开源计算机视觉库,正以其强大的算法生态、跨平台兼容性以及持续进化的架构设计,成为驱动实时应用开发的“数字引擎”。本文将深入剖析OpenCV如何通过技术创新突破实时处理的性能极
- 深度学习系列----->环境搭建(Ubuntu)
二师兄用飘柔
深度学习历程深度学习ubuntu人工智能pytorchpython
1、前言电脑基础系统硬件情况:系统:ubuntu18.04、显卡:GTX1050Ti;后续的环境搭建都在此基础上进行。此次学习选择Pytorch作为深度学习的框架,选择的原因主要由于PyTorch在研究领域特别受欢迎,较多的论文框架也是基于其开发。2、anaconda+python3安装测试在学习深度学习的过程中会涉及到使用不同版本python包的问题,而anaconda可以便捷获取包且对包能够进
- 深度学习-常用环境配置
瑶山
AIlinux人工智能windowsCUDAPyTorch
目录Miniconda安装安装NVIDIA显卡驱动安装CUDA和cnDNNCUDAcuDNNPyTorch安装手动下载测试Miniconda安装最新版Miniconda搭建Python环境_miniconda创建python虚拟环境-CSDN博客安装NVIDIA显卡驱动直接进NVIDIA官网:NVIDIAGeForce驱动程序-N卡驱动|NVIDIA在这里有GeForce驱动程序,立即下载,这是下
- 全球软件技术峰会 2025:聚焦大模型开发、智能运维与架构创新,共赴技术实战盛宴
向日葵也有悲伤
运维架构推荐算法数据结构大数据数据库架构
全球软件技术峰会2025:聚焦大模型开发、智能运维与架构创新,共赴技术实战盛宴在软件定义未来的时代,人工智能与数字化技术正以颠覆性力量重塑全球产业格局。2025年8月15-16日,以"全球专家、卓越智慧"为宗旨的全球软件技术峰会将盛大启幕,特邀全球近50位来自微软、谷歌、亚马逊、字节跳动等企业的技术领袖及一线实战专家,围绕大模型智能应用开发、AI与ML智能运维、软件开发智能化、架构设计与演进四大核
- AI产品经理面试宝典第42天:学习方法与产品流程解析
TGITCIC
AI产品经理一线大厂面试题产品经理AI面试大模型面试AI产品经理面试大模型产品经理面试AI产品大模型产品
具体问答:学习产品及AI知识的方法问:请谈谈您是如何学习产品及AI知识的,以及您认为哪些资源对您帮助最大答:我的学习体系包含三个维度:分层知识架构、实践验证闭环、资源筛选机制。在知识获取阶段,采用「理论-案例-工具」三级学习法:通过《人工智能:一种现代的方法》构建AI基础框架,用TensorFlow官方文档掌握工程实现,结合《启示录》《俞军产品方法论》理解产品逻辑。实践环节采用「项目反哺」模式,例
- 重磅!LM Studio AI编程全面免费
从今天起,LMStudio在家和工作中均可免费使用。查看更新后的条款了解详情。我们的隐私政策保持不变,您可以在此处阅读。在家免费使用,现在也可在工作场所使用LMStudio一直以来都免费供个人使用。这源于我们秉持的根本信念:人工智能应该让人们在自己的机器上轻松访问,无需依赖任何外部资源,并且完全保护隐私。此前,LMStudio应用条款规定,公司或组织若要使用LMStudio,必须联系我们并获得单独
- 在NLP深层语义分析中,深度学习和机器学习的区别与联系
在自然语言处理(NLP)的深层语义分析任务中,深度学习与机器学习的区别和联系主要体现在以下方面:一、核心区别特征提取方式机器学习:依赖人工设计特征(如词频、句法规则、TF-IDF等),需要领域专家对文本进行结构化处理。例如,传统情感分析需人工定义“情感词库”或通过词性标注提取关键成分。深度学习:通过神经网络自动学习多层次特征。例如,BERT等模型可从原始文本中捕获词向量、句法关系甚至篇章级语义,无
- 深度学习--利用梯度下降法进行多变量的二分类(感知机)
白话学生nit
深度学习分类人工智能
其实这一节涉及到了感知机的相关知识,就把这一节当作是学习感知机的引子吧。什么是二分类我们先来说一下什么是二分类,二分类指的是将结果分为两个互斥的类别,通常用来表示问题的两种可能。为什么用感知机学习二分类常见的解决问题的模型有很多,这里我们使用感知机模型。至于为什么,因为感知机模型很多地方用起来比较简便,就拿我们这一节的问题举一下例子,我们需要依照房子的价格对房子进行分类。在感知机模型中,我们可以使
- Self-Consistency:跨学科一致性的理论与AI推理的可靠性基石
大千AI助手
人工智能Python#Prompt人工智能机器学习神经网络算法大模型幻觉LLM
本文综合其在逻辑学、心理学及人工智能领域的核心定义、技术实现与前沿进展来对Self-Consistency(自洽性)进行系统性解析。本文由「大千AI助手」原创发布,专注用真话讲AI,回归技术本质。拒绝神话或妖魔化。搜索「大千AI助手」关注我,一起撕掉过度包装,学习真实的AI技术!一、核心定义与跨学科内涵基础概念逻辑学定义:指理论或系统内部逻辑自洽,无矛盾或悖论。例如物理理论中,狭义相对论的速度变换
- 人工智能学习指南:从菜鸟到大神的进击之路
橡晟
人工智能深度学习计算机视觉算法学习python
人工智能学习指南:从菜鸟到大神的进击之路前言:别慌,AI没那么可怕嘿!想学人工智能?恭喜你,你已经比90%的人更有眼光了!很多人一听到"人工智能"就开始头疼,仿佛这是什么高深莫测的巫术。其实不然,AI就像学做饭一样——刚开始可能会糊锅,但掌握了方法,你也能做出一桌好菜!目录第一章:认清现实,别被忽悠第二章:建立知识地图第三章:实战为王第四章:自检清单——你真的学会了吗?第五章:进阶之路结语:成为A
- 敏捷开发中的自然语言处理集成
项目管理实战手册
项目管理最佳实践敏捷流程自然语言处理easyuiai
敏捷开发中的自然语言处理集成:让代码与需求“说人话”关键词:敏捷开发、自然语言处理(NLP)、用户故事分析、需求自动化、持续集成优化摘要:在敏捷开发中,“快速响应变化”的核心目标常被繁琐的文本处理拖慢——需求文档像“天书”、用户故事靠“脑补”、缺陷报告整理耗时……自然语言处理(NLP)就像一位“智能翻译官”,能让开发团队与需求文档“流畅对话”。本文将用“搭积木”“翻译机”等生活化比喻,带您理解如何
- 阴谋爆仓!社科院课堂朱民ST-balance节能风电被骗揭秘!受害者亲述不能出金真相!
正义青天
随着互联网的普及,数字经济蓬勃发展,各种线上平台如雨后春笋般涌现。然而,在这些看似繁荣的平台中,不乏一些黑平台,它们以欺诈手段骗取用户的财产,给人们的财产安全带来严重威胁。因此,我们有必要提高警惕,防范黑平台诈骗。针对网上素未谋面的牛散大咖,经济学家等推荐网上投资理财、数字经济,数字体育市场,人工智能项目,数字低碳,慈善投票网站买数字的等等都是骗局若你也不幸被骗遇到此类平台一定不要打草惊蛇,早期不
- 智能喷洒机器人目标识别系统:基于NanoDet的目标检测与UI界面实现
YOLO实战营
机器人目标检测uiNanoDet计算机视觉目标跟踪深度学习
在现代农业生产中,自动化喷洒系统是实现精准农业的重要组成部分。智能喷洒机器人通过图像识别和自动控制技术,能够高效识别并精确喷洒农药、肥料等,提高农业生产效率,降低化学品使用量,减少环境污染。目标识别是智能喷洒机器人中至关重要的部分,它涉及到精准的作物和病虫害识别,确保喷洒操作的准确性。在本篇博客中,我们将构建一个基于NanoDet深度学习目标检测模型的智能喷洒机器人目标识别系统。我们将介绍如何使用
- 对标ChatGPT,「文心一言」今日亮相!AI人机时代来临,未来在何方?
AI医学
本文由「AI医学er」提供医海无涯,AI同舟。关注我们,助力高效科研。3月15日,OpenAI公布了其大型语言模型的最新版本——GPT-4。3月16日,百度文心一言人工智能聊天机器人正式上线。一个时代开始了。OpenAI在官网表示,GPT-4是一个能接受图像和文本输入,并输出文本的多模态模型,是OpenAI在扩展深度学习方面的最新成果。此前的ChatGPT,只能通过向其输入文字提问才能生成文字回答
- 【深度学习新浪潮】什么是system 1和system 2?
小米玄戒Andrew
深度学习新浪潮深度学习人工智能大模型推理模型COT模型蒸馏动态推理
在大模型研究中,System1和System2的概念源于心理学家DanielKahneman的双系统理论,用于描述人类思维的两种模式。System1代表快速、直觉、自动化的思维(如模式识别),而System2代表慢速、有意识、需要努力的逻辑推理(如复杂数学计算)。这一理论被引入AI领域后,成为理解大模型能力边界和优化方向的重要框架。一、大模型中的System1与System2的定义System1(
- 飞算科技:以原创技术为翼,赋能产业数字化转型
在数字经济浪潮席卷全球的当下,一批专注于技术创新的中国企业正加速崛起,飞算数智科技(深圳)有限公司(简称“飞算科技”)便是其中的佼佼者。作为一家国家级高新技术企业,飞算科技以自主创新为核心驱动力,凭借互联网科技、大数据、人工智能等前沿技术,为各行业客户插上数字化转型的翅膀。飞算科技的定位清晰而坚定——自主创新型数字科技公司。这一定位不仅体现在其技术研发的方向上,更融入到为客户服务的每一个环节。无论
- 警惕!北恒私募高级班周一丰,马建军不正规。不让出金,不能提现,大家远离骗局!
昌龙律法
随着互联网的普及,数字经济蓬勃发展,各种线上平台如雨后春笋般涌现。然而,在这些看似繁荣的平台中,不乏一些黑平台,它们以欺诈手段骗取用户的财产,给人们的财产安全带来严重威胁。因此,我们有必要提高警惕,防范黑平台诈骗。针对网上素未谋面的牛散大咖,经济学家等推荐网上投资理财、数字经济,数字体育市场,人工智能项目,数字低碳,慈善投票网站买数字的等等都是骗局,广大市民对此要提高警惕,若你也不幸被骗遇到此类平
- 学习人工智能开发的详细指南
Ws_
学习人工智能python
一、引言人工智能(AI)开发是一个充满挑战与机遇的领域,它融合了数学、计算机科学、统计学、认知科学等多个学科的知识。随着大数据、云计算和深度学习技术的快速发展,AI已经成为推动社会进步和产业升级的关键力量。本文将为初学者提供一份详细的学习指南,帮助大家逐步掌握AI开发的核心技能。二、基础知识准备数学基础:线性代数:理解向量、矩阵、线性变换等基本概念,掌握矩阵运算和特征值分解等技巧。概率论与统计学:
- 计算机发展史:人工智能时代的智能变革与无限可能
jdlxx_dongfangxing
计算机发展史计算机发展史
在计算机发展的漫长进程中,人工智能时代的到来无疑是最具革命性的篇章之一。它使计算机从单纯的数据处理工具,进化为能够模拟、延伸和拓展人类智能的强大系统,对科学研究、经济发展、社会生活乃至人类文明的走向,都产生了深远且不可逆转的影响。从早期对智能机器的设想,到如今人工智能技术在全球范围内的广泛应用,这一领域经历了无数次理论突破、技术迭代与实践探索,正以前所未有的速度重塑着我们的世界。人工智能的起源与早
- 使用Python调用Hugging Face Question Answering (问答)模型
墨如夜色
pythoneasyui开发语言Python
使用Python调用HuggingFaceQuestionAnswering(问答)模型在自然语言处理领域,问答系统是一种能够回答用户提出的问题的智能系统。HuggingFace是一个知名的开源软件库,提供了许多强大的自然语言处理工具和模型。其中,HuggingFace的QuestionAnswering模型可以帮助我们构建问答系统,使得我们能够从给定的文本中提取答案。本文将介绍如何使用Pytho
- 在美国,现在有超过10万台atm机允许你用借记卡购买比特币
麦田财经
在美国,通过普通自动取款机购买比特币已经成为现实。这一进展预示着Genmega和LibertyX之间最近的合作关系。通过这种合作,人们可以用借记卡从多台atm机上购买比特币。通过ATM机使用借记卡购买比特币“金融时报”2018年10月15日(星期一)发布的一份新闻稿显示,该国所有的Genmega自动取款机现在基本上都是比特币自动取款机。在合作的基础上,Genmega自动取款机现在将提供Freety
- 走进区块城市,开启你的元宇宙之旅!
口碑信息传播者
随着科技的飞速发展,虚拟现实、区块链、人工智能等前沿技术逐渐融入我们的生活。在这个大背景下,元宇宙概念应运而生,成为全球关注的焦点。本文将带领读者走进区块城市,一探元宇宙的究竟,感受这个未来世界的魅力。探索未来,触碰无限可能!国内区块链元宇宙正引领一场前所未有的科技革命,现在正是您加入这场盛宴的最佳时机!在这里,您将亲身体验到一个全新的虚拟世界,感受与现实世界无缝对接的震撼体验。加入国内区块链元宇
- 矩阵求逆(JAVA)初等行变换
qiuwanchi
矩阵求逆(JAVA)
package gaodai.matrix;
import gaodai.determinant.DeterminantCalculation;
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
/**
* 矩阵求逆(初等行变换)
* @author 邱万迟
*
- JDK timer
antlove
javajdkschedulecodetimer
1.java.util.Timer.schedule(TimerTask task, long delay):多长时间(毫秒)后执行任务
2.java.util.Timer.schedule(TimerTask task, Date time):设定某个时间执行任务
3.java.util.Timer.schedule(TimerTask task, long delay,longperiod
- JVM调优总结 -Xms -Xmx -Xmn -Xss
coder_xpf
jvm应用服务器
堆大小设置JVM 中最大堆大小有三方面限制:相关操作系统的数据模型(32-bt还是64-bit)限制;系统的可用虚拟内存限制;系统的可用物理内存限制。32位系统下,一般限制在1.5G~2G;64为操作系统对内存无限制。我在Windows Server 2003 系统,3.5G物理内存,JDK5.0下测试,最大可设置为1478m。
典型设置:
java -Xmx
- JDBC连接数据库
Array_06
jdbc
package Util;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class JDBCUtil {
//完
- Unsupported major.minor version 51.0(jdk版本错误)
oloz
java
java.lang.UnsupportedClassVersionError: cn/support/cache/CacheType : Unsupported major.minor version 51.0 (unable to load class cn.support.cache.CacheType)
at org.apache.catalina.loader.WebappClassL
- 用多个线程处理1个List集合
362217990
多线程threadlist集合
昨天发了一个提问,启动5个线程将一个List中的内容,然后将5个线程的内容拼接起来,由于时间比较急迫,自己就写了一个Demo,希望对菜鸟有参考意义。。
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.CountDownLatch;
public c
- JSP简单访问数据库
香水浓
sqlmysqljsp
学习使用javaBean,代码很烂,仅为留个脚印
public class DBHelper {
private String driverName;
private String url;
private String user;
private String password;
private Connection connection;
privat
- Flex4中使用组件添加柱状图、饼状图等图表
AdyZhang
Flex
1.添加一个最简单的柱状图
? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
<?xml version=
"1.0"&n
- Android 5.0 - ProgressBar 进度条无法展示到按钮的前面
aijuans
android
在低于SDK < 21 的版本中,ProgressBar 可以展示到按钮前面,并且为之在按钮的中间,但是切换到android 5.0后进度条ProgressBar 展示顺序变化了,按钮再前面,ProgressBar 在后面了我的xml配置文件如下:
[html]
view plain
copy
<RelativeLa
- 查询汇总的sql
baalwolf
sql
select list.listname, list.createtime,listcount from dream_list as list , (select listid,count(listid) as listcount from dream_list_user group by listid order by count(
- Linux du命令和df命令区别
BigBird2012
linux
1,两者区别
du,disk usage,是通过搜索文件来计算每个文件的大小然后累加,du能看到的文件只是一些当前存在的,没有被删除的。他计算的大小就是当前他认为存在的所有文件大小的累加和。
- AngularJS中的$apply,用还是不用?
bijian1013
JavaScriptAngularJS$apply
在AngularJS开发中,何时应该调用$scope.$apply(),何时不应该调用。下面我们透彻地解释这个问题。
但是首先,让我们把$apply转换成一种简化的形式。
scope.$apply就像一个懒惰的工人。它需要按照命
- [Zookeeper学习笔记十]Zookeeper源代码分析之ClientCnxn数据序列化和反序列化
bit1129
zookeeper
ClientCnxn是Zookeeper客户端和Zookeeper服务器端进行通信和事件通知处理的主要类,它内部包含两个类,1. SendThread 2. EventThread, SendThread负责客户端和服务器端的数据通信,也包括事件信息的传输,EventThread主要在客户端回调注册的Watchers进行通知处理
ClientCnxn构造方法
&
- 【Java命令一】jmap
bit1129
Java命令
jmap命令的用法:
[hadoop@hadoop sbin]$ jmap
Usage:
jmap [option] <pid>
(to connect to running process)
jmap [option] <executable <core>
(to connect to a
- Apache 服务器安全防护及实战
ronin47
此文转自IBM.
Apache 服务简介
Web 服务器也称为 WWW 服务器或 HTTP 服务器 (HTTP Server),它是 Internet 上最常见也是使用最频繁的服务器之一,Web 服务器能够为用户提供网页浏览、论坛访问等等服务。
由于用户在通过 Web 浏览器访问信息资源的过程中,无须再关心一些技术性的细节,而且界面非常友好,因而 Web 在 Internet 上一推出就得到
- unity 3d实例化位置出现布置?
brotherlamp
unity教程unityunity资料unity视频unity自学
问:unity 3d实例化位置出现布置?
答:实例化的同时就可以指定被实例化的物体的位置,即 position
Instantiate (original : Object, position : Vector3, rotation : Quaternion) : Object
这样你不需要再用Transform.Position了,
如果你省略了第二个参数(
- 《重构,改善现有代码的设计》第八章 Duplicate Observed Data
bylijinnan
java重构
import java.awt.Color;
import java.awt.Container;
import java.awt.FlowLayout;
import java.awt.Label;
import java.awt.TextField;
import java.awt.event.FocusAdapter;
import java.awt.event.FocusE
- struts2更改struts.xml配置目录
chiangfai
struts.xml
struts2默认是读取classes目录下的配置文件,要更改配置文件目录,比如放在WEB-INF下,路径应该写成../struts.xml(非/WEB-INF/struts.xml)
web.xml文件修改如下:
<filter>
<filter-name>struts2</filter-name>
<filter-class&g
- redis做缓存时的一点优化
chenchao051
redishadooppipeline
最近集群上有个job,其中需要短时间内频繁访问缓存,大概7亿多次。我这边的缓存是使用redis来做的,问题就来了。
首先,redis中存的是普通kv,没有考虑使用hash等解结构,那么以为着这个job需要访问7亿多次redis,导致效率低,且出现很多redi
- mysql导出数据不输出标题行
daizj
mysql数据导出去掉第一行去掉标题
当想使用数据库中的某些数据,想将其导入到文件中,而想去掉第一行的标题是可以加上-N参数
如通过下面命令导出数据:
mysql -uuserName -ppasswd -hhost -Pport -Ddatabase -e " select * from tableName" > exportResult.txt
结果为:
studentid
- phpexcel导出excel表简单入门示例
dcj3sjt126com
PHPExcelphpexcel
先下载PHPEXCEL类文件,放在class目录下面,然后新建一个index.php文件,内容如下
<?php
error_reporting(E_ALL);
ini_set('display_errors', TRUE);
ini_set('display_startup_errors', TRUE);
if (PHP_SAPI == 'cli')
die('
- 爱情格言
dcj3sjt126com
格言
1) I love you not because of who you are, but because of who I am when I am with you. 我爱你,不是因为你是一个怎样的人,而是因为我喜欢与你在一起时的感觉。 2) No man or woman is worth your tears, and the one who is, won‘t
- 转 Activity 详解——Activity文档翻译
e200702084
androidUIsqlite配置管理网络应用
activity 展现在用户面前的经常是全屏窗口,你也可以将 activity 作为浮动窗口来使用(使用设置了 windowIsFloating 的主题),或者嵌入到其他的 activity (使用 ActivityGroup )中。 当用户离开 activity 时你可以在 onPause() 进行相应的操作 。更重要的是,用户做的任何改变都应该在该点上提交 ( 经常提交到 ContentPro
- win7安装MongoDB服务
geeksun
mongodb
1. 下载MongoDB的windows版本:mongodb-win32-x86_64-2008plus-ssl-3.0.4.zip,Linux版本也在这里下载,下载地址: http://www.mongodb.org/downloads
2. 解压MongoDB在D:\server\mongodb, 在D:\server\mongodb下创建d
- Javascript魔法方法:__defineGetter__,__defineSetter__
hongtoushizi
js
转载自: http://www.blackglory.me/javascript-magic-method-definegetter-definesetter/
在javascript的类中,可以用defineGetter和defineSetter_控制成员变量的Get和Set行为
例如,在一个图书类中,我们自动为Book加上书名符号:
function Book(name){
- 错误的日期格式可能导致走nginx proxy cache时不能进行304响应
jinnianshilongnian
cache
昨天在整合某些系统的nginx配置时,出现了当使用nginx cache时无法返回304响应的情况,出问题的响应头: Content-Type:text/html; charset=gb2312 Date:Mon, 05 Jan 2015 01:58:05 GMT Expires:Mon , 05 Jan 15 02:03:00 GMT Last-Modified:Mon, 05
- 数据源架构模式之行数据入口
home198979
PHP架构行数据入口
注:看不懂的请勿踩,此文章非针对java,java爱好者可直接略过。
一、概念
行数据入口(Row Data Gateway):充当数据源中单条记录入口的对象,每行一个实例。
二、简单实现行数据入口
为了方便理解,还是先简单实现:
<?php
/**
* 行数据入口类
*/
class OrderGateway {
/*定义元数
- Linux各个目录的作用及内容
pda158
linux脚本
1)根目录“/” 根目录位于目录结构的最顶层,用斜线(/)表示,类似于
Windows
操作系统的“C:\“,包含Fedora操作系统中所有的目录和文件。 2)/bin /bin 目录又称为二进制目录,包含了那些供系统管理员和普通用户使用的重要
linux命令的二进制映像。该目录存放的内容包括各种可执行文件,还有某些可执行文件的符号连接。常用的命令有:cp、d
- ubuntu12.04上编译openjdk7
ol_beta
HotSpotjvmjdkOpenJDK
获取源码
从openjdk代码仓库获取(比较慢)
安装mercurial Mercurial是一个版本管理工具。 sudo apt-get install mercurial
将以下内容添加到$HOME/.hgrc文件中,如果没有则自己创建一个: [extensions] forest=/home/lichengwu/hgforest-crew/forest.py fe
- 将数据库字段转换成设计文档所需的字段
vipbooks
设计模式工作正则表达式
哈哈,出差这么久终于回来了,回家的感觉真好!
PowerDesigner的物理数据库一出来,设计文档中要改的字段就多得不计其数,如果要把PowerDesigner中的字段一个个Copy到设计文档中,那将会是一件非常痛苦的事情。