EPNet论文解读
EPNet论文解读
-
- 1.背景
- 2.网络架构
-
- 2.1 Image Stream
- 2.2 Geometric Stream
-
- 2.2.1 SA模块
- 2.2.2 FP模块
- 2.3 FI-Fusion
-
- 2.3.1 Grid Generator
- 2.3.2 Image Sampler
- 2.3.3 LI-Fusion Layer
- 2.4 Consistency Enforcing Loss
- 2.5 OVerall Loss Function
论文链接:https://arxiv.org/pdf/2007.08856.pdf
代码链接:happinesslz/EPNet: EPNet: Enhancing Point Features with Image Semantics for 3D Object Detection(ECCV 2020) (github.com)
1.背景
如何利用多个传感器来解决定位和分类之间的不一致性是3D检测任务中的关键问题。该论文提出了EPNet这种算法,以逐点方式增强具有语义图像特征的点,而无需任何图像注释。采用一致强制损失来解决定位与分类一致性的问题。

(a)、(b)图中由于遮挡、光照等因素产生的干扰信息减弱了目标检测的性能,©图中表示的就是定位得分高但是分类分数低,从而可能导致在NMS的过程中过滤掉该检测框。
常用的传感器融合方式:(1)在不同阶段使用传感器的级联方法,例如F-Pointnet等;(2)联合推理多传感器输入的融合方法,例如ContFuse等。
其中,级联的方法不能利用不同传感器之间的互补性,它们的性能受每个阶段的限制;融合方法需要透过透视投影和体素化生成BEV,不可避免的存在信息丢失,它只能近似的在体素特征和语义图像特征之间建立一个相对粗略的对应关系。
2.网络架构

该网络架构是由Image Stream和Geometric Stream两部分组成的two-stream RPN。
2.1 Image Stream
图像流前面先经过四个卷积块来进行特征提取,每一块由两个3*3的卷积层+批量归一化层+ReLU激活函数组成,其中每个块的第二个卷积的步长为2,可以扩大感受野,同时减少参数量,(每经过一个卷积块后就送入LI-Fusion)从上面的图片中可以看出,经过卷积块后,汽车的全貌逐渐呈现出来。在经过下采样之后,对这四个图像特征Fi(1,2,3,4)采用并行转置卷积来恢复图像分辨率,从而生成与原始图像大小相同的特征图。然后将这四个特征图进行级联(concatenation),接着在通过一个卷积块,得到的特征图送入LI-Fusion。
2.2 Geometric Stream
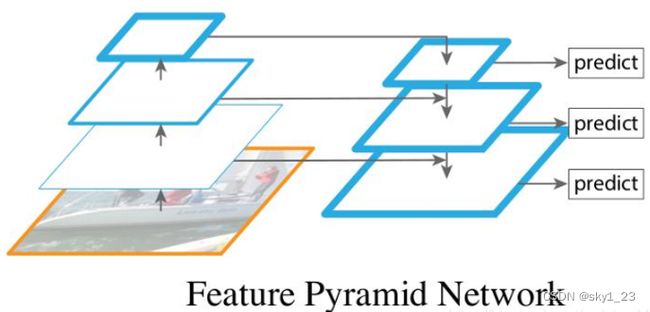
激光雷达点云数据经过一个SA(Set Abstraction)模块时,LI-Fusion的输出结果就会送入SA模块中与激光点云数据进行结合,得到的结果传入到下一个SA模块中,同时还要传入到FP(Feature Propagation)模块中。其中这里的SA模块和FP模块出自于(PointNet++),SA模块就是下采样,FP模块就是上采样,上面的虚线将下采样与上采样进行连接的结构类似于FPN(特征图像金字塔)结构。
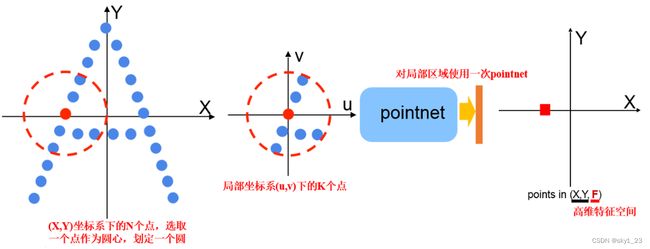
2.2.1 SA模块
借鉴了传统CNN的采样思路,采用分层特征学习,即在小区域中使用点云采样+成组+提取局部特征的方式:
- sampling(采样):随机选择一个初始点,然后依次利用FPS(最远点采样)进行采样,直到达到目标点数;
- Grouping(成组):以采样点为中心,利用Ball Query划一个R为半径的球,将里面包含的点云作为一簇成组;
- Pointnet(提取局部特征): 对Sampling+Grouping以后的点云进行局部的全局特征提取。
大致过程:
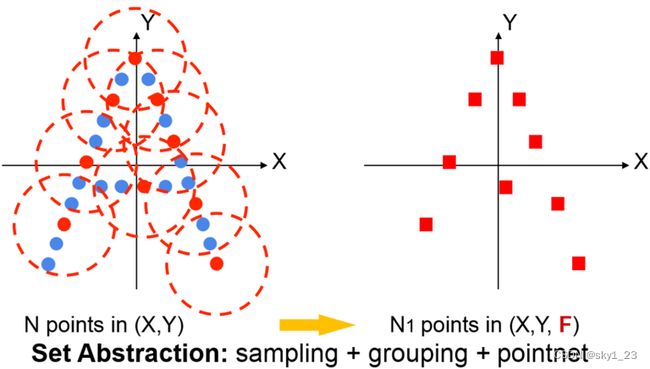
每层新的中心点都是从上一层抽取的特征子集,中心点的个数就是成组的点集数,随着层数增加,中心点的个数也会逐渐降低,抽取到点云的局部结构特征。
其中对于点云采样时出现非均匀分布时所采取的两种措施:
多尺度成组 (MSG)
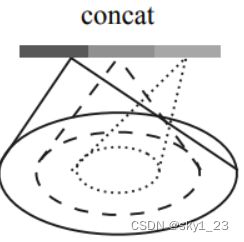
对同一个中心点采用不同的半径来提取局部的特征,但是这种做法会产生很多的特征重叠,不同范围内的权值很难共享,而且计算量会变大。
多分辨率成组(MRG)

这种方法采用的是不同分辨率进行点云的特征提取,然后进行级联,类似于特征金字塔网络(FPN),检测能力会增强。
2.2.2 FP模块
借鉴的也是PointNet++中的结构,进行上采样步骤,也就是将前一层的激光点云通过双线性插值到下一层以增加点云数量。

大致流程:
1)利用NL-1层和NL层的坐标计算任意两个点之间的距离,则会得到一个距离矩阵,假设大小为512x128,意思是NL-1(低维)中的每个点与NL(高维)中的每个点的距离。
2)将距离矩阵进行排序,找到NL层中与NL-1层中距离最近的三个点,并记录其值和索引,标记为dist和idnex,注意,此时的索引、距离矩阵大小是512x3,即NL-1中与NL距离最近的三个点的索引。
3)将idnex在NL层的特征中进行查询,得到512x3x(c+d)的特征矩阵。将128上采样到512,这里会进行重复采样,因为前面得到的idnxe矩阵是512x3,这个里面的每一行的三个元素都是在128个点中的索引。
4)前面已经将特征进行上采样,但本质还是原来128个点对应的特征,如果不进行变换,那么这个上采样将毫无意义。所以,我们需要按前面距离矩阵进行插值,来改变特征的值。前面在dist矩阵里面保留的就是距离值,因此,只需要将它与特征进行扩维相乘就可以了(因为特征维数要大于距离维数),也就等同于加权了。
2.3 FI-Fusion

2.3.1 Grid Generator
网格生成器是用来将激光雷达点云通过映射矩阵M投射到图像,输出LiDAR点与相机图像的逐点对应关系。
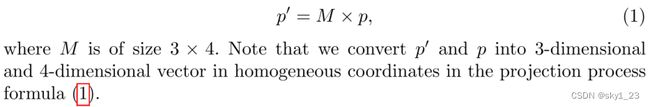
2.3.2 Image Sampler
图像采样器,将采样位置p’和图像特征图F作为输入,为每个采样位置生成图像特征V。

2.3.3 LI-Fusion Layer
当环境中存在光照强或弱、遮挡的问题而引入干扰信息,该层利用LiDAR特征以逐点的方式自适应的估计图像特征。
首先将 LiDAR 特征 FP 和逐点特征 FI 馈送到全连接层,并将它们映射到同一通道。然后我们将它们加在一起形成一个紧凑的特征表示,然后通过另一个全连接层将其压缩成具有单通道的权重图 w。我们使用 sigmoid 激活函数将权重图 w 归一化到 [0, 1] 的范围内。
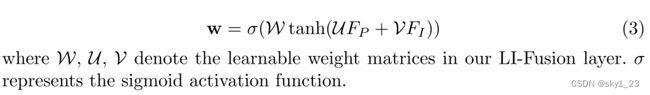
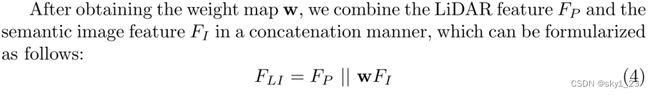
2.4 Consistency Enforcing Loss
一致性强制损失用来确保定位和分类置信度之间的一致性,使具有高定位置信度的框具有高分类置信度,反之亦然。

其中,D表示预测的边界框,G表示真值框,c表示D的分类置信度。
2.5 OVerall Loss Function

