YOLO v3源码详解
数据读取代码详解
传入参数:训练集txt路径和线程数
在初始化操作中,读取txt文件的图片名称,并找到相应的labels地址 ,读取图片,将图片调整为RGB格式,并进行padding操作,将图片大小调整为640*640
标签的处理
首先读取标签文件,由于图像经过了padding,首先,需要对真实框进行调整,并将真实框由(x1,y1,x2,y2)格式转变为(x,y,w,h)格式,再对图像做数据增强处理(翻转),并调整真实框
代码如下:
class ListDataset(Dataset):
def __init__(self, list_path, img_size=416, augment=True, multiscale=True, normalized_labels=True):
with open(list_path, "r") as file:
self.img_files = file.readlines()
self.label_files = [
path.replace("train2017", "trainval2017").replace(".png", ".txt").replace(".jpg", ".txt")
for path in self.img_files
]
self.img_size = img_size
self.max_objects = 100
self.augment = augment
self.multiscale = multiscale
self.normalized_labels = normalized_labels
self.min_size = self.img_size - 3 * 32
self.max_size = self.img_size + 3 * 32
self.batch_count = 0
def __getitem__(self, index):
# ---------
# Image
# ---------
img_path = self.img_files[index % len(self.img_files)].rstrip()
# img_path = 'E:\\eclipse-workspace\\PyTorch\\PyTorch-YOLOv3\\data\\coco' + img_path
#print (img_path)
# Extract image as PyTorch tensor
img = transforms.ToTensor()(Image.open(img_path).convert('RGB'))
# Handle images with less than three channels
if len(img.shape) != 3:
img = img.unsqueeze(0)
img = img.expand((3, img.shape[1:]))
_, h, w = img.shape
h_factor, w_factor = (h, w) if self.normalized_labels else (1, 1)
# Pad to square resolution
img, pad = pad_to_square(img, 0)
_, padded_h, padded_w = img.shape
# ---------
# Label
# ---------
# 取出标签文件,定位到自己的标签文件中
label_path = self.label_files[index % len(self.img_files)].rstrip()
# label_path = 'E:\\eclipse-workspace\\PyTorch\\PyTorch-YOLOv3\\data\\coco\\labels' + label_path
#print (label_path)
# ---------------
# 对真实框进行调整
# ---------------
targets = None
if os.path.exists(label_path):
boxes = torch.from_numpy(np.loadtxt(label_path).reshape(-1, 5))
# Extract coordinates for unpadded + unscaled image
x1 = w_factor * (boxes[:, 1] - boxes[:, 3] / 2)
y1 = h_factor * (boxes[:, 2] - boxes[:, 4] / 2)
x2 = w_factor * (boxes[:, 1] + boxes[:, 3] / 2)
y2 = h_factor * (boxes[:, 2] + boxes[:, 4] / 2)
# Adjust for added padding
x1 += pad[0]
y1 += pad[2]
x2 += pad[1]
y2 += pad[3]
# Returns (x, y, w, h)
boxes[:, 1] = ((x1 + x2) / 2) / padded_w
boxes[:, 2] = ((y1 + y2) / 2) / padded_h
boxes[:, 3] *= w_factor / padded_w
boxes[:, 4] *= h_factor / padded_h
targets = torch.zeros((len(boxes), 6))
targets[:, 1:] = boxes
# Apply augmentations
# 数据增强:翻转
if self.augment:
if np.random.random() < 0.5:
img, targets = horisontal_flip(img, targets)
return img_path, img, targets
def collate_fn(self, batch):
paths, imgs, targets = list(zip(*batch))
# Remove empty placeholder targets
targets = [boxes for boxes in targets if boxes is not None]
# Add sample index to targets
for i, boxes in enumerate(targets):
boxes[:, 0] = i
targets = torch.cat(targets, 0)
# Selects new image size every tenth batch
if self.multiscale and self.batch_count % 10 == 0:
self.img_size = random.choice(range(self.min_size, self.max_size + 1, 32))
# Resize images to input shape
imgs = torch.stack([resize(img, self.img_size) for img in imgs])
self.batch_count += 1
return paths, imgs, targets
def __len__(self):
return len(self.img_files)2.基于配置文件构建网络模型
YOLO v3网络结构

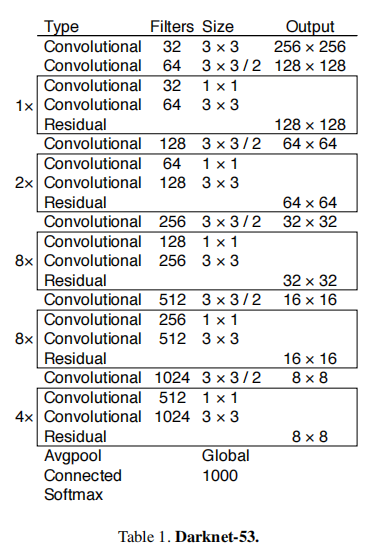
[convolutional]模块:由卷积、batchnormalization、leakey Relu激活层组成
shortcut层:即残差连接层,如上图所示,特征图经过1*1的卷积降低特征通道和3*3的卷积后使用一个残差连接,不涉及特征图缩小 route层:特征图经过上采样后与上一层的特征图相连
route层和shortcut层在初始化操作时,均先创建一个空层,等前向传播时在进行构建
YOLO层共有三层,完成对特征图网格存在物体的位置和类别的检测,并完成损失函数的构建。
代码如下:
def create_modules(module_defs):
"""
Constructs module list of layer blocks from module configuration in module_defs
"""
hyperparams = module_defs.pop(0)
output_filters = [int(hyperparams["channels"])]
module_list = nn.ModuleList()
for module_i, module_def in enumerate(module_defs):
modules = nn.Sequential()
if module_def["type"] == "convolutional":
bn = int(module_def["batch_normalize"])
filters = int(module_def["filters"])
kernel_size = int(module_def["size"])
pad = (kernel_size - 1) // 2
modules.add_module(
f"conv_{module_i}",
nn.Conv2d(
in_channels=output_filters[-1],
out_channels=filters,
kernel_size=kernel_size,
stride=int(module_def["stride"]),
padding=pad,
bias=not bn,
),
)
if bn:
modules.add_module(f"batch_norm_{module_i}", nn.BatchNorm2d(filters, momentum=0.9, eps=1e-5))
if module_def["activation"] == "leaky":
modules.add_module(f"leaky_{module_i}", nn.LeakyReLU(0.1))
elif module_def["type"] == "maxpool":
kernel_size = int(module_def["size"])
stride = int(module_def["stride"])
if kernel_size == 2 and stride == 1:
modules.add_module(f"_debug_padding_{module_i}", nn.ZeroPad2d((0, 1, 0, 1)))
maxpool = nn.MaxPool2d(kernel_size=kernel_size, stride=stride, padding=int((kernel_size - 1) // 2))
modules.add_module(f"maxpool_{module_i}", maxpool)
elif module_def["type"] == "upsample":
upsample = Upsample(scale_factor=int(module_def["stride"]), mode="nearest")
modules.add_module(f"upsample_{module_i}", upsample)
elif module_def["type"] == "route": # 输入1:26*26*256 输入2:26*26*128 输出:26*26*(256+128)
layers = [int(x) for x in module_def["layers"].split(",")]
filters = sum([output_filters[1:][i] for i in layers])
modules.add_module(f"route_{module_i}", EmptyLayer())
# 残差连接
elif module_def["type"] == "shortcut":
filters = output_filters[1:][int(module_def["from"])]
modules.add_module(f"shortcut_{module_i}", EmptyLayer())
# 构建yolo层
elif module_def["type"] == "yolo":
anchor_idxs = [int(x) for x in module_def["mask"].split(",")]
# Extract anchors 得到锚框的比例
anchors = [int(x) for x in module_def["anchors"].split(",")]
anchors = [(anchors[i], anchors[i + 1]) for i in range(0, len(anchors), 2)]
# 取anchor_idxs指定的锚框(6,7,8)
anchors = [anchors[i] for i in anchor_idxs]
num_classes = int(module_def["classes"])
img_size = int(hyperparams["height"])
# Define detection layer
yolo_layer = YOLOLayer(anchors, num_classes, img_size)
modules.add_module(f"yolo_{module_i}", yolo_layer)
# Register module list and number of output filters
module_list.append(modules)
output_filters.append(filters)
return hyperparams, module_list3.YOLO层定义解析
输出结果
对于输入的特征图,首先reshape成[图片数,网格h,网格w,一个网格锚框数,类别数+4(x,y,w,h)+1(是否存在物体)]大小,取出x,y,w,h,pred_conf,pred_cls,根据论文,对x,y,pred_conf,pred_cl输入sigmoid函数,得到最终的预测的结果,此时得到的是物体在特征图网格的存在物体的置信度,类别置信度、和相对于网格的相对位置,将相对位置转为特征图的绝对位置,并进一步得到真实位置,输出结果
损失函数的构建
取出target标签中的真实框,对每一个先验框计算IOU值,shape[num_anchors,num_gtboxs],即每一个先验框与每一个真实框的IOU,取每一个真实框IOU最大的先验框,此框必定包含物体。同时,IOU超过了指定的阈值也看做是有物体,由此可以构建包含物体的矩阵obj_mask和不包含物体的矩阵nonobj_mask。然后获得获得每个网格物体真实坐标相对于左上角的偏移量,将真实框的标签转换为one-hot编码形式,计算预测框和真实一样的索引,以及与真实框想匹配的预测框之间的iou值。
最终得到iou_scores:真实值与最匹配的anchor的IOU得分值 class_mask:分类正确的索引 obj_mask: #目标框所在位置的最好anchor置为1 noobj_mask obj_mask那里置0,还有计算的iou大于阈值的也置0,其他都为1 tx, ty, tw, th, 对应的对于该大小的特征图的xywh目标值也就是我们需要拟合的值 #tconf 目标置信度
代码如下:
def build_targets(pred_boxes, pred_cls, target, anchors, ignore_thres):
ByteTensor = torch.cuda.ByteTensor if pred_boxes.is_cuda else torch.ByteTensor
FloatTensor = torch.cuda.FloatTensor if pred_boxes.is_cuda else torch.FloatTensor
nB = pred_boxes.size(0) # batchsieze 4
nA = pred_boxes.size(1) # 每个格子对应了多少个anchor
nC = pred_cls.size(-1) # 类别的数量
nG = pred_boxes.size(2) # gridsize
# Output tensors
# 初始化操作
obj_mask = ByteTensor(nB, nA, nG, nG).fill_(0) # obj,anchor包含物体, 即为1,默认为0 考虑前景
noobj_mask = ByteTensor(nB, nA, nG, nG).fill_(1) # noobj, anchor不包含物体, 则为1,默认为1 考虑背景
class_mask = FloatTensor(nB, nA, nG, nG).fill_(0) # 类别掩膜,类别预测正确即为1,默认全为0
iou_scores = FloatTensor(nB, nA, nG, nG).fill_(0) # 预测框与真实框的iou得分
tx = FloatTensor(nB, nA, nG, nG).fill_(0) # 真实框相对于网格的位置
ty = FloatTensor(nB, nA, nG, nG).fill_(0)
tw = FloatTensor(nB, nA, nG, nG).fill_(0)
th = FloatTensor(nB, nA, nG, nG).fill_(0)
tcls = FloatTensor(nB, nA, nG, nG, nC).fill_(0)
# Convert to position relative to box
# 真实框
target_boxes = target[:, 2:6] * nG #target中的xywh都是0-1的,可以得到其在当前gridsize上的xywh
gxy = target_boxes[:, :2]
gwh = target_boxes[:, 2:]
# Get anchors with best iou
# 对每一个先验框计算IOU值,shape[num_anchors,num_gtboxs]
# 即每一个先验框与每一个真实框的IOU
ious = torch.stack([bbox_wh_iou(anchor, gwh) for anchor in anchors]) #每一种规格的anchor跟每个标签上的框的IOU得分
# print (ious.shape)
# 取每一个真实框IOU最大的先验框
best_ious, best_n = ious.max(0)
# Separate target values
# 所属图片及类别标签
b, target_labels = target[:, :2].long().t() # 真实框所对应的batch,以及每个框所代表的实际类别
gx, gy = gxy.t()
gw, gh = gwh.t()
gi, gj = gxy.long().t() #位置信息,向下取整
# Set masks
obj_mask[b, best_n, gj, gi] = 1 # 实际包含物体网格的设置成1
noobj_mask[b, best_n, gj, gi] = 0 # 实际不包含物体网格的设置成1
# Set noobj mask to zero where iou exceeds ignore threshold
# IOU超过了指定的阈值也看做是有物体
for i, anchor_ious in enumerate(ious.t()):
noobj_mask[b[i], anchor_ious > ignore_thres, gj[i], gi[i]] = 0
# Coordinates 按照论文中的公式
# 相对位置:获得每个网格物体真实坐标相对于左上角的偏移量
tx[b, best_n, gj, gi] = gx - gx.floor()
ty[b, best_n, gj, gi] = gy - gy.floor()
# Width and height
tw[b, best_n, gj, gi] = torch.log(gw / anchors[best_n][:, 0] + 1e-16)
th[b, best_n, gj, gi] = torch.log(gh / anchors[best_n][:, 1] + 1e-16)
# One-hot encoding of label
tcls[b, best_n, gj, gi, target_labels] = 1 #将真实框的标签转换为one-hot编码形式
# Compute label correctness and iou at best anchor 计算预测的和真实一样的索引
class_mask[b, best_n, gj, gi] = (pred_cls[b, best_n, gj, gi].argmax(-1) == target_labels).float()
# 与真实框想匹配的预测框之间的iou值
iou_scores[b, best_n, gj, gi] = bbox_iou(pred_boxes[b, best_n, gj, gi], target_boxes, x1y1x2y2=False)
tconf = obj_mask.float() # 真实框的置信度,也就是1
return iou_scores, class_mask, obj_mask, noobj_mask, tx, ty, tw, th, tcls, tconf损失函数公式
论文中给出的损失函数公式:
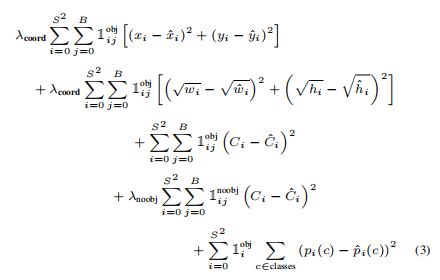
式(10-3)中, 是一个指示函数,当第i个子图像块的第j个预测框框中了目标时,=1,否则=0。因此式中
是一个指示函数,当第i个子图像块的第j个预测框框中了目标时,=1,否则=0。因此式中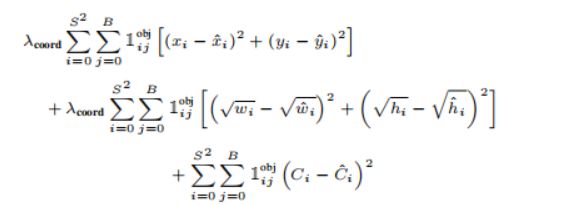
表示包含目标的框的位置损失和置信度损失,如前所述,式中x、y和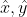 分别表示预测框和目标框的中心点相对于子图像块的归一化坐标,w、h和
分别表示预测框和目标框的中心点相对于子图像块的归一化坐标,w、h和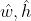 分别表示预测框和目标框相对于整幅图像的宽和高的归一化宽和高,这部分仅将框中目标的预测框的损失进行计算和梯度回传;
分别表示预测框和目标框相对于整幅图像的宽和高的归一化宽和高,这部分仅将框中目标的预测框的损失进行计算和梯度回传;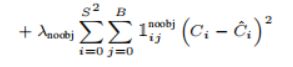 表示未包含目标的预测框的置信度损失,因为没有目标,其框中目标的置信度
表示未包含目标的预测框的置信度损失,因为没有目标,其框中目标的置信度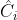 的值为0;公式中
的值为0;公式中 表示包含目标的分类损失。式中的
表示包含目标的分类损失。式中的 表示加权系数,用于平衡各部分损失的比例。
表示加权系数,用于平衡各部分损失的比例。
代码如下:
loss_x = self.mse_loss(x[obj_mask], tx[obj_mask]) # 只计算有目标的
loss_y = self.mse_loss(y[obj_mask], ty[obj_mask])
loss_w = self.mse_loss(w[obj_mask], tw[obj_mask])
loss_h = self.mse_loss(h[obj_mask], th[obj_mask])
loss_conf_obj = self.bce_loss(pred_conf[obj_mask], tconf[obj_mask])
loss_conf_noobj = self.bce_loss(pred_conf[noobj_mask], tconf[noobj_mask])
loss_conf = self.obj_scale * loss_conf_obj + self.noobj_scale * loss_conf_noobj #有物体越接近1越好 没物体的越接近0越好
loss_cls = self.bce_loss(pred_cls[obj_mask], tcls[obj_mask]) #分类损失
total_loss = loss_x + loss_y + loss_w + loss_h + loss_conf + loss_cls #总损失其中,代码中的bce损失:
![]()
总体代码如下:
class YOLOLayer(nn.Module):
"""Detection layer"""
def __init__(self, anchors, num_classes, img_dim=416):
super(YOLOLayer, self).__init__()
self.anchors = anchors # 每个网格的预设锚框(3个)
self.num_anchors = len(anchors) # 每个网格的锚框数量(3)
self.num_classes = num_classes
self.ignore_thres = 0.5
self.mse_loss = nn.MSELoss()
self.bce_loss = nn.BCELoss()
self.obj_scale = 1
self.noobj_scale = 100
self.metrics = {}
self.img_dim = img_dim
self.grid_size = 0 # grid size
def compute_grid_offsets(self, grid_size, cuda=True):
# 网格大小
self.grid_size = grid_size
g = self.grid_size
FloatTensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
# 特征图缩放大小
self.stride = self.img_dim / self.grid_size
# Calculate offsets for each grid
self.grid_x = torch.arange(g).repeat(g, 1).view([1, 1, g, g]).type(FloatTensor)
self.grid_y = torch.arange(g).repeat(g, 1).t().view([1, 1, g, g]).type(FloatTensor)
self.scaled_anchors = FloatTensor([(a_w / self.stride, a_h / self.stride) for a_w, a_h in self.anchors])
self.anchor_w = self.scaled_anchors[:, 0:1].view((1, self.num_anchors, 1, 1))
self.anchor_h = self.scaled_anchors[:, 1:2].view((1, self.num_anchors, 1, 1))
def forward(self, x, targets=None, img_dim=None):
# Tensors for cuda support
print (x.shape)
# 为cpu和gpu指定数据类型
FloatTensor = torch.cuda.FloatTensor if x.is_cuda else torch.FloatTensor
LongTensor = torch.cuda.LongTensor if x.is_cuda else torch.LongTensor
ByteTensor = torch.cuda.ByteTensor if x.is_cuda else torch.ByteTensor
# 图像大小,为了让模型适应多种图像,随机选取图像大小,但是都是32的倍数
self.img_dim = img_dim
# 一个batch有多少张图片
num_samples = x.size(0)
# 最终网格大小
grid_size = x.size(2)
# 相当于reshape操作,预测矩阵转换为:[图片数,网格h,网格w,一个网格锚框数,类别数+4(x,y,w,h)+1(是否存在物体)]
prediction = (
x.view(num_samples, self.num_anchors, self.num_classes + 5, grid_size, grid_size)
.permute(0, 1, 3, 4, 2)
.contiguous()
)
# print (prediction.shape)
# Get outputs 将预测结果进行拆分为x,y,w,h,confidence
x = torch.sigmoid(prediction[..., 0]) # Center x
y = torch.sigmoid(prediction[..., 1]) # Center y
w = prediction[..., 2] # Width
h = prediction[..., 3] # Height
# 存在物体置信度
pred_conf = torch.sigmoid(prediction[..., 4]) # Conf
# 类别置信度 YOLO v3使用多个sigmoid替换softmax
pred_cls = torch.sigmoid(prediction[..., 5:]) # Cls pred.
# If grid size does not match current we compute new offsets
# 返回网格的坐标,比如14*14的特征图网格,得到每一个网格(x,y)坐标
# 以及特征图缩小后,先验框的w,h
if grid_size != self.grid_size:
self.compute_grid_offsets(grid_size, cuda=x.is_cuda)
# Add offset and scale with anchors #特征图中的实际位置
# 相对位置得到对应的绝对位置比如之前的位置是0.5,0.5变为 11.5,11.5
# 对特征图先验框的h,w也进行调整
pred_boxes = FloatTensor(prediction[..., :4].shape)
pred_boxes[..., 0] = x.data + self.grid_x
pred_boxes[..., 1] = y.data + self.grid_y
pred_boxes[..., 2] = torch.exp(w.data) * self.anchor_w
pred_boxes[..., 3] = torch.exp(h.data) * self.anchor_h
# print(pred_boxes.shape)
# 将特征图的(x,y,w,h)还原到原始图像中,并reshape成[num_samples,num_anchors*grid_size*grid_size,4]
output = torch.cat(
(
pred_boxes.view(num_samples, -1, 4) * self.stride, #还原到原始图中
pred_conf.view(num_samples, -1, 1),
pred_cls.view(num_samples, -1, self.num_classes),
),
-1,
)
# print(output.shape)
# 没有物体
if targets is None:
return output, 0
else:
#
iou_scores, class_mask, obj_mask, noobj_mask, tx, ty, tw, th, tcls, tconf = build_targets(
pred_boxes=pred_boxes,
pred_cls=pred_cls,
target=targets,
anchors=self.scaled_anchors,
ignore_thres=self.ignore_thres,
)
# iou_scores:真实值与最匹配的anchor的IOU得分值 class_mask:分类正确的索引 obj_mask:
# 目标框所在位置的最好anchor置为1 noobj_mask obj_mask那里置0,还有计算的iou大于阈值的也置0,其他都为1
# tx, ty, tw, th, 对应的对于该大小的特征图的xywh目标值也就是我们需要拟合的值
# tconf 目标置信度
# Loss : Mask outputs to ignore non-existing objects (except with conf. loss)
loss_x = self.mse_loss(x[obj_mask], tx[obj_mask]) # 只计算有目标的
loss_y = self.mse_loss(y[obj_mask], ty[obj_mask])
loss_w = self.mse_loss(w[obj_mask], tw[obj_mask])
loss_h = self.mse_loss(h[obj_mask], th[obj_mask])
loss_conf_obj = self.bce_loss(pred_conf[obj_mask], tconf[obj_mask])
loss_conf_noobj = self.bce_loss(pred_conf[noobj_mask], tconf[noobj_mask])
loss_conf = self.obj_scale * loss_conf_obj + self.noobj_scale * loss_conf_noobj #有物体越接近1越好 没物体的越接近0越好
loss_cls = self.bce_loss(pred_cls[obj_mask], tcls[obj_mask]) #分类损失
total_loss = loss_x + loss_y + loss_w + loss_h + loss_conf + loss_cls #总损失
# Metrics
cls_acc = 100 * class_mask[obj_mask].mean()
conf_obj = pred_conf[obj_mask].mean()
conf_noobj = pred_conf[noobj_mask].mean()
conf50 = (pred_conf > 0.5).float()
iou50 = (iou_scores > 0.5).float()
iou75 = (iou_scores > 0.75).float()
detected_mask = conf50 * class_mask * tconf
precision = torch.sum(iou50 * detected_mask) / (conf50.sum() + 1e-16)
recall50 = torch.sum(iou50 * detected_mask) / (obj_mask.sum() + 1e-16)
recall75 = torch.sum(iou75 * detected_mask) / (obj_mask.sum() + 1e-16)
self.metrics = {
"loss": to_cpu(total_loss).item(),
"x": to_cpu(loss_x).item(),
"y": to_cpu(loss_y).item(),
"w": to_cpu(loss_w).item(),
"h": to_cpu(loss_h).item(),
"conf": to_cpu(loss_conf).item(),
"cls": to_cpu(loss_cls).item(),
"cls_acc": to_cpu(cls_acc).item(),
"recall50": to_cpu(recall50).item(),
"recall75": to_cpu(recall75).item(),
"precision": to_cpu(precision).item(),
"conf_obj": to_cpu(conf_obj).item(),
"conf_noobj": to_cpu(conf_noobj).item(),
"grid_size": grid_size,
}
return output, total_loss训练模型
coco数据集读取与预处理
coco数据集是采用json存储的,我们首先需要将coco数据集转为YOLO格式,如图所示:
路径放置不重要,写绝对路径就好,train2017和val2017存入训练集和验证集图片,labels放入YOLO格式的标签,val.txt与train.txt为训练集图片名称或者地址。有用的就是这些啦,其它的就不要看啦,我习惯于将一个数据集变成多种数据集格式存储在一起,coco2yolo是我写的转YOLO的代码

数据集文件做好之后,将文件的路径写入配置文件config/coco.data

参数说明
--data_config config/coco.data --pretrained_weights weights/darknet53.conv.74 --epochs:训练轮次 --batch_size:每一批次的图片数量 --gradient_accumulations:先累积梯度,每gradient_accumulations进行一次梯度下降 --model_def:模型配置文件 --data_config:数据配置文件 --pretrained_weights:预训练模型 --img_size:图像大小 --checkpoint_interval:保存模型的间隔 --evaluation_interval:在验证集验证的间隔 --compute_map:为真,每10个批次计算一次mAP --multiscale_training:多尺寸训练
训练步骤
-
按上述流程准备好数据
-
修改数据配置文件:config/coco.data
-
命令行指定参数或配置运行参数(配置形参)

测试与训练参数基本一致,不在赘述
模型的预测
模型的预测比较简单,准备好预测图片的文件夹即可
配置参数
image_folder:图片路径 model_def:模型配置yolov3.cfg/yolov3-tiny.cfg weights_path:权重文件 class_path:存储数据集所有类别的txt文件 conf_thres:置信度阈值,在非极大值抑制时,当存在物体的置信度>conf_thres才认为存在物体 nms_thres:非极大值抑制时的IOU阈值,当相同类别的预测框IOU超过nms_thres即认为表示同一物体,需要过滤 batch_size:每一批次的图片数量
运行detect.py即可