机器学习课程讲义·第四章,支持向量机
本文是中央财经大学机器学习课程系列讲义第四篇,持续更新,不足之处敬请指正!
机器学习课程讲义·第四章,支持向量机
- 上期回顾
- 本期导读
- 符号形式
- 引言
- 硬间隔支持向量机
-
- 模型形式
- 补充:拉格朗日乘子法
-
- 一般形式
- 几何意义
- 应用举例
-
- 课后练习题
- 拉格朗日对偶(弱对偶和强对偶)
-
- 弱对偶问题
- 强对偶问题
- KKT条件
- 模型求解
- 模型解析
- 软间隔支持向量机
-
- 模型形式
- 模型求解
- 模型解析
- 支持向量机的核技巧
-
- 模型形式
- 核函数性质
- 核函数示例
- 支持向量回归机
-
- 模型形式
- 模型求解
- 模型解析
上期回顾
上期我们一起学习了决策树模型,重点介绍了决策树模型的基本思想、相关的损失函数以及为什么使用这样的损失函数;我们还讨论了如何使用决策树模型来解决回归问题;此外,我们借助决策树模型讲解了机器学习中的一种非常重要的思想:集成学习思想,并由此引出现在目前使用较为广泛的随机森林模型。
本期导读
本章我们将来学习机器学习基础核心算法中最复杂的模型:支持向量机,我们将首先针对线性可分的问题介绍支持向量机的基本思想,并引出硬间隔支持向量机。在讨论硬间隔支持向量机的过程中,我们将重点讲解一种常用的优化算法-拉格朗日乘子法。之后我们进一步放松线性可分的假设,讨论软间隔支持向量机模型。
本章我们还将学习到一种机器学习中十分重要的处理技巧:核技巧,讨论它在支持向量机中的应用。
最后,本章由分类问题到回归问题,讨论支持向量回归机模型。
符号形式
遵循第二章约定的符号形式。
假定 N N N个数据集合,记为 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) } \mathcal{D}=\{(x_1, y_1),(x_2, y_2),\cdots,(x_N, y_N)\} D={(x1,y1),(x2,y2),⋯,(xN,yN)},其中输入空间 x i ∈ R P x_i \in R^P xi∈RP,输出空间 y i ∈ R y_i \in R yi∈R;输入矩阵记为 X = ( x 1 , x 2 , ⋯ , x N ) T X=(x_1,x_2,\cdots,x_N)^T X=(x1,x2,⋯,xN)T,输出矩阵记为 Y = ( y 1 , y 2 , ⋯ , y N ) T Y=(y_1,y_2,\cdots,y_N)^T Y=(y1,y2,⋯,yN)T,即 X ∈ R N × P X \in R^{N \times P} X∈RN×P, Y ∈ R N × 1 Y \in R^{N \times 1} Y∈RN×1。
引言
第二章我们学习了使用一般线性回归模型处理回归问题,对于分类问题,我们可以将线性回归模型得到的连续值通过映射函数映射到0到1的区间内,即得到逻辑回归模型。逻辑回归模型使用的映射函数是sigmoid函数,除此之外,我们还可以使用简单的符号函数进行映射,即: f ( x ) = sign ( w T x + b ) (4-1) f(x)=\operatorname{sign}(\boldsymbol{w}^T\boldsymbol{x}+b)\tag{4-1} f(x)=sign(wTx+b)(4-1)这就是感知机模型。关于感知机的历史和更多内容我们将在神经网络的章节中介绍,本章我们只从图形上来认识感知机模型。
如图4-1,感知机模型实际上是找到一个超平面,将线性可分的正负样本分成两部分,超平面的法向量是 w w w(之后用 w w w代表该超平面),超平面上的点满足 w T x + b = 0 \boldsymbol{w}^T\boldsymbol{x}+b=0 wTx+b=0,正样本满足 w T x + b ⩾ 0 \boldsymbol{w}^T\boldsymbol{x}+b\geqslant0 wTx+b⩾0,负样本满足 w T x + b ⩽ 0 \boldsymbol{w}^T\boldsymbol{x}+b\leqslant0 wTx+b⩽0。
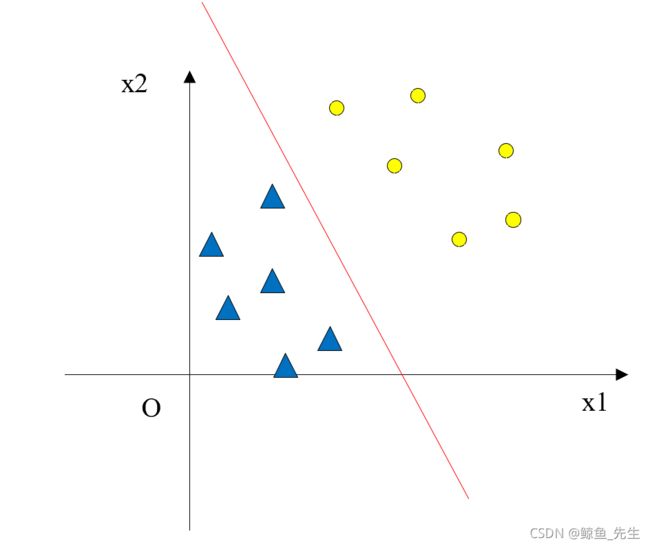
观察超平面 w T x + b = 0 \boldsymbol{w}^T\boldsymbol{x}+b=0 wTx+b=0,如果对其稍微进行旋转,只要依然保证正负样本分别在超平面的上方和下方都是可以的,也就是说感知机拥有无穷多个解。那么哪个解(超平面)才是最优的呢?容易想到,最优超平面应该“尽可能”地将正负样本分开,以确保模型的泛化性能最好。
观察图4-2,找到一条超平面,使得其到正类样本最近的距离和到负类样本最近的聚类最大且相等,这样的超平面能够最大程度地将正负样本分开,这个超平面就是最优超平面,此时距离超平面最近的点(包括正类和负类)对超平面的确定有决定性作用,叫做支持向量,这就是支持向量机最初的构想。
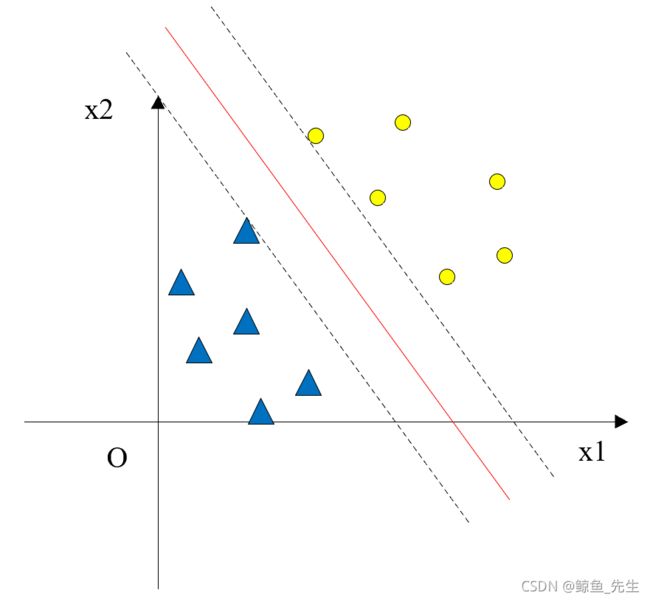
支持向量机(Support Vector Machine,SVM)是Cortes和Vapnik于1995年提出的一种基于统计的分类模型,可以说在深度学习流行之前,支持向量机是最有效的一类统计机器学习模型。直至今天,对支持向量机算法的研究和应用依然是相关领域的热点。同时支持向量机也是机器学习经典算法中涉及数理知识最多的模型之一,掌握支持向量机的推导始末,其他机器学习模型的学习就自然不在话下了。
我们首先来总结支持向量机的主要内容。俗话说得好,SVM有三宝:间隔、对偶、核技巧。第一宝即上述对最大间隔的设定,第二宝是为了求解支持向量的优化目标,由于这个优化目标的原问题难以求解,我们可以引入拉格朗日对偶方法进行求解,第三宝“核技巧”一方面实现了输入空间向高维空间的映射,大大提高了模型的泛化性能,另一方面利用核函数的优良性质可以大大简化运算。由易到难,支持向量机分为硬间隔支持向量机、软间隔支持向量机以及核支持向量机,上述模型是分类模型,此外还有解决回归问题的支持向量回归机,接下来我们就逐一来认识她们。
硬间隔支持向量机
模型形式
首先介绍硬间隔支持向量机(hard-margin SVM)。硬间隔支持向量机解决线性可分问题,如引言中所述,最优的超平面应该是距离支持向量(距离超平面最近的点,包括正类的支持向量和负类的支持向量)最远的那个,设某支持向量点为 w \boldsymbol{w} w,根据点到平面的距离公式,此距离可表示为: r = ∣ w T x + b ∣ ∥ w ∥ (4-2) r=\frac{\left|\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}+b\right|}{\|\boldsymbol{w}\|}\tag{4-2} r=∥w∥∣∣wTx+b∣∣(4-2)不妨设输出空间 y i ∈ { − 1 , + 1 } y_{i} \in\{-1,+1\} yi∈{−1,+1},对于线性可分的数据集合,对数据进行完美分类的超平面应该满足以下条件:对于任意 x i x_i xi有 { w T x i + b ⩾ 0 , y i = + 1 w T x i + b ⩽ 0 , y i = − 1 (4-3) \left\{\begin{array}{ll}\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b \geqslant0, & y_{i}=+1 \\ \boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b \leqslant0, & y_{i}=-1\end{array}\right.\tag{4-3} {wTxi+b⩾0,wTxi+b⩽0,yi=+1yi=−1(4-3)我们可以将公式4-3统一记作: y i ( w T x i + b ) ⩾ 0 (4-4) y_i(\boldsymbol{w}^T\boldsymbol{x}_{i}+b) \geqslant0\tag{4-4} yi(wTxi+b)⩾0(4-4)对于 w T x + b \boldsymbol{w}^T\boldsymbol{x}+b wTx+b,对 w 和 b \boldsymbol{w}和b w和b同时乘以一个不为0的数得到的超平面同原超平面一致,因此对 w \boldsymbol{w} w和 b b b进行缩放不影响求解。 我们可以适当缩放这两个参数,令距离超平面最近的支持向量点满足 w T x + b = 1 \boldsymbol{w}^T\boldsymbol{x}+b=1 wTx+b=1,于是公式4-4变为: y i ( w T x i + b ) ⩾ 1 (4-5) y_{i}\left(\boldsymbol{w}^{T} \boldsymbol{x}_{i}+b\right) \geqslant 1\tag{4-5} yi(wTxi+b)⩾1(4-5)同时,公式4-2中的距离可以写成: r = 1 ∥ w ∥ (4-6) r=\frac{1}{\|\boldsymbol{w}\|}\tag{4-6} r=∥w∥1(4-6)于是,支持向量机的模型形式可以表达如下:寻找超平面 w \boldsymbol{w} w,使得所有的样本点均满足 y i ( w T x i + b ) ⩾ 1 y_{i}\left(\boldsymbol{w}^{T} \boldsymbol{x}_{i}+b\right) \geqslant 1 yi(wTxi+b)⩾1,并且支持向量到该平面的距离 r = 1 ∥ w ∥ r=\frac{1}{\|\boldsymbol{w}\|} r=∥w∥1最大。使用数学公式可以表达为: max w , b 1 ∥ w ∥ s.t. y i ( w T x i + b ) ⩾ 1 , i = 1 , 2 , … , N (4-7) \begin{array}{l}\max _{\boldsymbol{w}, b} \frac{1}{\|\boldsymbol{w}\|} \\ \text { s.t. } y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right) \geqslant 1, \quad i=1,2, \ldots, N\end{array}\tag{4-7} maxw,b∥w∥1 s.t. yi(wTxi+b)⩾1,i=1,2,…,N(4-7)等价于: min w , b 1 2 ∥ w ∥ 2 s.t. y i ( w T x i + b ) ⩾ 1 , i = 1 , 2 , … , N (4-8) \begin{array}{l}\min _{\boldsymbol{w}, b} \frac{1}{2}\|\boldsymbol{w}\|^{2} \\ \text { s.t. } y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right) \geqslant 1, \quad i=1,2, \ldots, N\end{array}\tag{4-8} minw,b21∥w∥2 s.t. yi(wTxi+b)⩾1,i=1,2,…,N(4-8)这是一个带约束的优化问题,优化目标是凸函数(黑塞矩阵正定),约束条件是线性约束(仿射约束),可行域是凸集,是一个典型的带约束凸优化问题,可以直接使用一些二次规划的套件(QP)进行求解。
同时我们注意到,由于 w \boldsymbol w w是 p p p维的,这是一个变量个数为 p + 1 p+1 p+1个,约束条件有 N N N个的优化问题,当 p p p比较大时,问题求解相对困难;更重要的是,很多时候原始的 x \boldsymbol x x不能直接求解(如线性不可分等),我们通常需要将其映射到其它空间,该空间维度不确定(有些时候会达到无限大),这样求解就十分不易。为了解决这个问题,我们可以使用拉格朗日乘子法中的对偶方法。
补充:拉格朗日乘子法
一般形式
拉格朗日乘子法(Lagrange Multiplier Method)解决带约束的优化问题。首先从等式约束开始,设待优化的问题的标准形式为: min x f ( x ) h i ( x ) = 0 , i = 1 , ⋯ , p (4-9) \begin{array}{l}\min _{\boldsymbol{x}} f(\boldsymbol{x}) \\ h_{i}(\boldsymbol{x})=0, i=1, \cdots, p\end{array}\tag{4-9} minxf(x)hi(x)=0,i=1,⋯,p(4-9)即求使 f ( x ) f(\boldsymbol{x}) f(x)最小的 x \boldsymbol{x} x,有 p p p个等式约束。如果目标是求最大值,取相反数变换成最小值即可。
勾走拉格朗日函数: L ( x , λ ) = f ( x ) + ∑ i = 1 p λ i h i ( x ) (4-10) L(\boldsymbol{x}, \boldsymbol{\lambda})=f(\boldsymbol{x})+\sum_{i=1}^{p} \boldsymbol{\lambda}_{i} h_{i}(\boldsymbol{x})\tag{4-10} L(x,λ)=f(x)+i=1∑pλihi(x)(4-10)可以去掉等式约束,转化成求拉格朗日函数的最小值,其中 λ \boldsymbol{\lambda} λ是新引入的自变量,成为拉格朗日乘子。对所有自变量导,可以得到4-11所示方程组: ∇ x f ( x ) + ∑ i = 1 p λ i ∇ x h i ( x ) = 0 h i ( x ) = 0 (4-11) \begin{array}{r}\nabla_{\boldsymbol{x}} f(\boldsymbol{x})+\sum_{i=1}^{p} \lambda_{i} \nabla_{\boldsymbol{x}} h_{i}(\boldsymbol{x})=\boldsymbol{0} \\ h_{i}(\boldsymbol{x})=0\end{array}\tag{4-11} ∇xf(x)+∑i=1pλi∇xhi(x)=0hi(x)=0(4-11)求解该方程组即可得到最优解。这就是拉格朗日乘子法的一般形式。
几何意义
我们尝试从几何意义上理解拉格朗日乘子法。如图4-3所示,我们在二维中观察目标函数,画出其等高线(每条闭合线上的目标函数值相同)以及约束条件所在的曲线(如果 x x x是二维的,有一个等式约束时可行域为曲线上的点,有两个以上等式约束时,可行域为不同曲线的交点或者没有交点时为空集),那么如果存在最优解,优解一定出现在等高线和约束曲线相切的地方。因为如果最优点在约束曲线和等高线的割点上,一定会存在另外两个割点,一个在原割点下方,其目标函数值比原割点小/大,一个在原割点上方,其目标函数值比原割点大/小,如图中矩形框中所示。(回忆:第二章LASSO回归最优解容易取得稀疏解的几何意义)
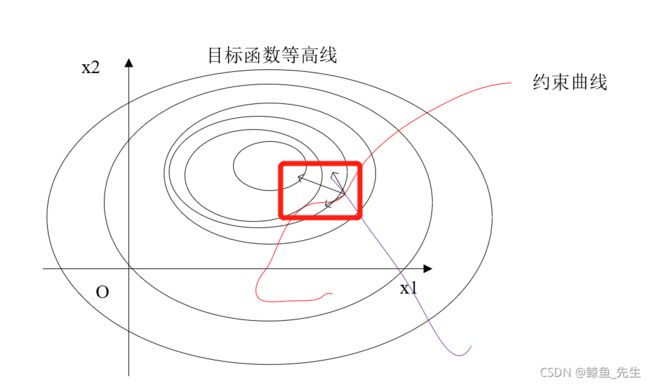
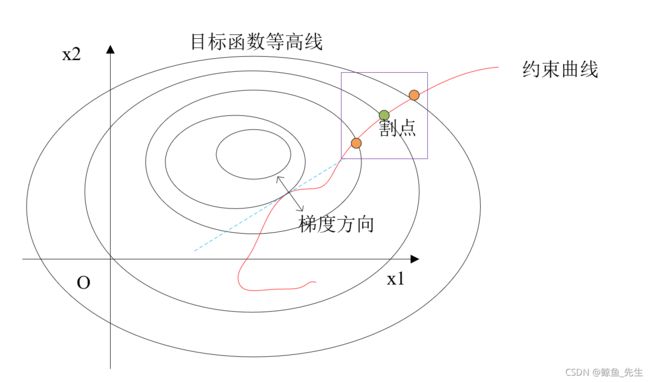 明确了最优解在切点处后,容易想到,在切点处,等高线和约束曲线的法向量是共线的,而梯度向量正是曲线的法线。因此,在最优解处,目标函数的梯度和约束曲线的梯度共线(只有一个约束条件)。如果约束条件有多个,如图4-4,容易得出,此时目标函数的梯度是两条约束曲线梯度的线性组合。这就是公式4-11中第一个方程的含义,即: ∇ x f ( x ) = − ∑ i = 1 p λ i ∇ x h i ( x ) (4-12) \nabla_{\boldsymbol{x}} f(\boldsymbol{x})=-\sum_{i=1}^{p} \lambda_{i} \nabla_{\boldsymbol{x}} h_{i}(\boldsymbol{x})\tag{4-12} ∇xf(x)=−i=1∑pλi∇xhi(x)(4-12)
明确了最优解在切点处后,容易想到,在切点处,等高线和约束曲线的法向量是共线的,而梯度向量正是曲线的法线。因此,在最优解处,目标函数的梯度和约束曲线的梯度共线(只有一个约束条件)。如果约束条件有多个,如图4-4,容易得出,此时目标函数的梯度是两条约束曲线梯度的线性组合。这就是公式4-11中第一个方程的含义,即: ∇ x f ( x ) = − ∑ i = 1 p λ i ∇ x h i ( x ) (4-12) \nabla_{\boldsymbol{x}} f(\boldsymbol{x})=-\sum_{i=1}^{p} \lambda_{i} \nabla_{\boldsymbol{x}} h_{i}(\boldsymbol{x})\tag{4-12} ∇xf(x)=−i=1∑pλi∇xhi(x)(4-12)
应用举例
回顾第二章讲的线性判别分析(LDA),我们的目标是最大化广义瑞利商,即: J = w T S b w w T S w w (4-13) J=\frac{\boldsymbol{w}^{\mathrm{T}} \mathbf{S}_{b} \boldsymbol{w}}{\boldsymbol{w}^{\mathrm{T}} \mathbf{S}_{w} \boldsymbol{w}}\tag{4-13} J=wTSwwwTSbw(4-13)同支持向量机中对参数的处理一致,因为 w \boldsymbol w w可以缩放,不妨设 w T S w w = 1 \boldsymbol{w}^{\mathrm{T}} \mathbf{S}_{w} \boldsymbol{w}=1 wTSww=1,于是上述目标可以表达成以下最优化问题: min w − w T S b w s.t. w T S w w − 1 = 0 (4-14) \begin{array}{l}\min _{\boldsymbol{w}}-\boldsymbol{w}^{\mathrm{T}} \mathbf{S}_{b} \boldsymbol{w} \\ \text { s.t. } \boldsymbol{w}^{\mathrm{T}} \mathbf{S}_{w} \boldsymbol{w}-1=0\end{array}\tag{4-14} minw−wTSbw s.t. wTSww−1=0(4-14)使用拉格朗日乘子法,有拉格朗日函数 L ( w , λ ) = w T S B w + λ ( w T S W w − 1 ) L(\boldsymbol{w}, \boldsymbol{\lambda})=\boldsymbol{w}^{\mathrm{T}} \boldsymbol{S}_{B} \boldsymbol{w}+\lambda\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{S}_{W} \boldsymbol{w}-1\right) L(w,λ)=wTSBw+λ(wTSWw−1),对其求梯度令梯度为0,容易得到: w = 1 λ S W − 1 S B w (4-15) \boldsymbol{w}=\frac{1}{\lambda} \boldsymbol{S}_{W}^{-1} \boldsymbol{S}_{B} \boldsymbol{w}\tag{4-15} w=λ1SW−1SBw(4-15)这与之前我们得到的结论: w ∝ S w − 1 S b w = S w − 1 ( x c 1 ‾ − x c 2 ‾ ) ( x c 1 ‾ − x c 2 ‾ ) T w ∝ S w − 1 ( x c 1 ‾ − x c 2 ‾ ) w \propto S_{w}^{-1} S_{b} w=S_{w}^{-1}\left(\overline{x_{c 1}}-\overline{x_{c 2}}\right)\left(\overline{x_{c 1}}-\overline{x_{c 2}}\right)^{T} w \propto S_{w}^{-1}\left(\overline{x_{c 1}}-\overline{x_{c 2}}\right) w∝Sw−1Sbw=Sw−1(xc1−xc2)(xc1−xc2)Tw∝Sw−1(xc1−xc2)一致。
进一步分析,公式4-15可以有: S W − 1 S B w = λ w \boldsymbol{S}_{W}^{-1} \boldsymbol{S}_{B} \boldsymbol{w}=\lambda \boldsymbol{w} SW−1SBw=λw,即 λ \lambda λ是 S W − 1 S B \boldsymbol{S}_{W}^{-1} \boldsymbol{S}_{B} SW−1SB的特征值, w \boldsymbol w w是对应的特征向量。进而可以对广义瑞利商写成如下形式: w T S B w w T S W w = w T ( λ S W w ) w T S W w = λ (4-16) \frac{\boldsymbol{w}^{\mathrm{T}} \boldsymbol{S}_{B} \boldsymbol{w}}{\boldsymbol{w}^{\mathrm{T}} \boldsymbol{S}_{W} \boldsymbol{w}}=\frac{\boldsymbol{w}^{\mathrm{T}}\left(\lambda \boldsymbol{S}_{W} \boldsymbol{w}\right)}{\boldsymbol{w}^{\mathrm{T}} \boldsymbol{S}_{W} \boldsymbol{w}}=\lambda\tag{4-16} wTSWwwTSBw=wTSWwwT(λSWw)=λ(4-16)也就是最优目标值实际上是矩阵 S W − 1 S B \boldsymbol{S}_{W}^{-1} \boldsymbol{S}_{B} SW−1SB的最大特征值,对应的最优解是最大特征值对应的特征向量。
课后练习题
利用拉格朗日乘子法证明周长一定时,等边三角形的面积最大。
提示:优化目标为求三角形面积的海伦公式。
拉格朗日对偶(弱对偶和强对偶)
弱对偶问题
上述讨论的拉格朗日乘子法的约束条件为等式约束,那对于不等式约束我们应该如何求解呢?
考虑以下优化问题: min x f ( x ) g i ( x ) ⩽ 0 i = 1 , ⋯ , m h i ( x ) = 0 i = 1 , ⋯ , p (4-17) \begin{array}{l}\min _{\boldsymbol{x}} f(\boldsymbol{x}) \\ g_{i}(\boldsymbol{x}) \leqslant 0 \quad i=1, \cdots, m \\ h_{i}(\boldsymbol{x})=0 \quad i=1, \cdots, p\end{array}\tag{4-17} minxf(x)gi(x)⩽0i=1,⋯,mhi(x)=0i=1,⋯,p(4-17)我们写出它的拉格朗日函数,如下: L ( x , λ , ν ) = f ( x ) + ∑ i = 1 m λ i g i ( x ) + ∑ i = 1 p ν i h i ( x ) (4-18) L(\boldsymbol{x}, \boldsymbol{\lambda}, \boldsymbol{\nu})=f(\boldsymbol{x})+\sum_{i=1}^{m} \lambda_{i} g_{i}(\boldsymbol{x})+\sum_{i=1}^{p} \nu_{i} h_{i}(\boldsymbol{x})\tag{4-18} L(x,λ,ν)=f(x)+i=1∑mλigi(x)+i=1∑pνihi(x)(4-18)称为广义拉格朗日函数,其中 λ i ⩾ 0 \lambda_{i} \geqslant 0 λi⩾0。相应的优化问题可以写为: min x max λ , ν , λ i ⩾ 0 L ( x , λ , ν ) (4-19) \min _{\boldsymbol{x}} \max _{\boldsymbol{\lambda}, \boldsymbol{\nu}, \lambda_{i} \geqslant 0} L(\boldsymbol{x}, \boldsymbol{\lambda}, \boldsymbol{\nu})\tag{4-19} xminλ,ν,λi⩾0maxL(x,λ,ν)(4-19)也就是说首先固定 x \boldsymbol x x,找到使得 L ( x , λ , ν ) L(\boldsymbol{x}, \boldsymbol{\lambda}, \boldsymbol{\nu}) L(x,λ,ν)最大的 λ , ν \lambda, \boldsymbol \nu λ,ν,然后求使得 L ( x , λ ∗ , ν ∗ ) L(\boldsymbol{x}, \boldsymbol{\lambda_*}, \boldsymbol{\nu_*}) L(x,λ∗,ν∗)最小的 x \boldsymbol x x。
我们来简单证明一下为什么优化4-19和优化4-17会得到相同的解。
证明如下,分两种情况讨论:
- 如果 x \boldsymbol x x是可行解,也就是满足公式4-17中的约束条件,我们有 L ( x , λ , ν ) = f ( x ) + ∑ i = 1 m λ i g i ( x ) L(\boldsymbol{x}, \boldsymbol{\lambda}, \boldsymbol{\nu})=f(\boldsymbol{x})+\sum_{i=1}^{m} \lambda_{i} g_{i}(\boldsymbol{x}) L(x,λ,ν)=f(x)+∑i=1mλigi(x),因为有 h i ( x ) = 0 h_{i}(\boldsymbol{x})=0 hi(x)=0,第三项为0;同时我们要求 λ i ⩾ 0 \lambda_{i} \geqslant 0 λi⩾0,并且 g i ( x ) ⩽ 0 g_{i}(\boldsymbol{x}) \leqslant 0 gi(x)⩽0,第二项的最大值为0,因此 L ( x , λ , ν ) L(\boldsymbol{x}, \boldsymbol{\lambda}, \boldsymbol{\nu}) L(x,λ,ν)的最大值为第一项,即 f ( x ) f(\boldsymbol x) f(x)。 min x max λ , ν , λ i ⩾ 0 L ( x , λ , ν ) \min _{\boldsymbol{x}} \max _{\lambda, \nu, \lambda_{i} \geqslant 0} L(\boldsymbol{x}, \boldsymbol{\lambda}, \boldsymbol{\nu}) minxmaxλ,ν,λi⩾0L(x,λ,ν)等价于 min x f ( x ) \min _{x} f(\boldsymbol{x}) minxf(x)。也就是4-17的优化目标。
- 如果 x \boldsymbol x x不是可行解,即存在 g i ( x ) > 0 g_{i}(\boldsymbol{x}) > 0 gi(x)>0或者 h i ( x ) ≠ 0 h_{i}(\boldsymbol{x}) \not = 0 hi(x)=0,因为 λ i ⩾ 0 \lambda_{i} \geqslant 0 λi⩾0, ν \nu ν没有限制,因此 L ( x , λ , ν ) L(\boldsymbol{x}, \boldsymbol{\lambda}, \boldsymbol{\nu}) L(x,λ,ν)的最大值是 + ∞ +\infty +∞(令 λ i \lambda_{i} λi取 + ∞ +\infty +∞或 ν \nu ν取 s i g n ( h i ( x ) ) ∞ sign(h_{i}(\boldsymbol{x}))\infty sign(hi(x))∞,无法求解最小值。
证毕。
我们已经证明4-19的优化问题与4-17的优化问题等价,下面介绍拉格朗日对偶。
首先定义4-19所示的优化问题为原问题,原问题首先固定 x \boldsymbol x x,找到使得 L ( x , λ , ν ) L(\boldsymbol{x}, \boldsymbol{\lambda}, \boldsymbol{\nu}) L(x,λ,ν)最大的 λ , ν \lambda, \boldsymbol \nu λ,ν,然后求使得 L ( x , λ ∗ , ν ∗ ) L(\boldsymbol{x}, \boldsymbol{\lambda_*}, \boldsymbol{\nu_*}) L(x,λ∗,ν∗)最小的 x \boldsymbol x x。原问题的对偶问题定义如下: max λ , ν , λ i ⩾ 0 min x L ( x , λ , ν ) (4-20) \max _{\lambda, \nu, \lambda_{i} \geqslant 0} \min _{\boldsymbol{x}} L(\boldsymbol{x}, \boldsymbol{\lambda}, \boldsymbol{\nu})\tag{4-20} λ,ν,λi⩾0maxxminL(x,λ,ν)(4-20)即首先固定 λ , ν \lambda, \boldsymbol \nu λ,ν,找到使得 L ( x , λ , ν ) L(\boldsymbol{x}, \boldsymbol{\lambda}, \boldsymbol{\nu}) L(x,λ,ν)最小的 x \boldsymbol x x,然后求使得 L ( x , λ ∗ , ν ∗ ) L(\boldsymbol{x}, \boldsymbol{\lambda_*}, \boldsymbol{\nu_*}) L(x,λ∗,ν∗)最大的 λ , ν \lambda, \boldsymbol \nu λ,ν。
在后面支持向量机的学习中我们可以发现,对偶问题往往比原问题更容易求解。
下面介绍关于原问题和对偶问题的弱对偶定理(Weak Duality),如下: max λ , ν , λ i ⩾ 0 min x L ( x , x , λ , ν ) ⩽ min x max λ , ν , λ i ⩾ 0 L ( x , λ , ν ) \max _{\boldsymbol{\lambda}, \boldsymbol{\nu}, \lambda_{i} \geqslant 0} \min _{\boldsymbol{x}} L(\boldsymbol{x}, \boldsymbol{x}, \boldsymbol{\lambda}, \boldsymbol{\nu}) \leqslant \min _{\boldsymbol{x}} \max _{\boldsymbol{\lambda}, \boldsymbol{\nu}, \lambda_{i} \geqslant 0} L(\boldsymbol{x}, \boldsymbol{\lambda}, \boldsymbol{\nu}) λ,ν,λi⩾0maxxminL(x,x,λ,ν)⩽xminλ,ν,λi⩾0maxL(x,λ,ν)即对偶问题目标函数的值小于等于原问题目标函数的值。证明起来也比较容易,设 x 1 , λ 1 , ν 1 \boldsymbol{x}_{1}, \boldsymbol{\lambda}_{1}, \boldsymbol{\nu}_{1} x1,λ1,ν1是原问题的最优解, x 2 , λ 2 , ν 2 \boldsymbol{x}_{2}, \boldsymbol{\lambda}_{2}, \boldsymbol{\nu}_{2} x2,λ2,ν2是对偶问题的最优解,容易有 : L ( x 1 , λ 1 , ν 1 ) ⩾ L ( x 1 , λ 2 , ν 2 ) ⩾ L ( x 2 , λ 2 , ν 2 ) L\left(\boldsymbol{x}_{1}, \boldsymbol{\lambda}_{1}, \boldsymbol{\nu}_{1}\right) \geqslant L\left(\boldsymbol{x}_{1}, \boldsymbol{\lambda}_{2}, \boldsymbol{\nu}_{2}\right)\geqslant L\left(\boldsymbol{x}_{2}, \boldsymbol{\lambda}_{2}, \boldsymbol{\nu}_{2}\right) L(x1,λ1,ν1)⩾L(x1,λ2,ν2)⩾L(x2,λ2,ν2)证毕。
强对偶问题
即便是有了弱对偶定理,我们可以保证对偶问题的解对应的目标函数是原问题目标函数值的下界,但是依然无法准确求出原问题的解和对应的目标函数值。强对偶(Strong Duality)帮我们解决了这个问题,强对偶的定义是原问题和对偶问题有相同的最优解。
首先介绍强对偶的一个充分条件-Slater条件,它指出:一个凸优化问题如果存在一个解使得所有不等式约束都是严格满足的,也就是 g i ( x ) ⩽ 0 g_{i}(\boldsymbol{x}) \leqslant 0 gi(x)⩽0中等号总是不满足,那么在不等式约束趋于内至少存在一个可行点 ( x ∗ , λ ∗ , ν ∗ ) \left(\boldsymbol{x}^{*}, \boldsymbol{\lambda}^{*}, \boldsymbol{\nu}^{*}\right) (x∗,λ∗,ν∗)既是对欧问题的最优解,也是原问题的最优解。
这里我们不再对Slater条件进行进一步的讨论,但是补充一下什么事凸优化问题,见板书。
关于强对偶问题的例题见课件。
KKT条件
KKT条件(Karush-Kuhn-Tucker)给出了带约束优化问题取极值的一阶必要条件。对于4-17表示的优化问题,对应的拉格朗日函数为公式4-18,则最优解 x \boldsymbol x x满足4-21所述条件: { ∇ f + ∑ j p λ j ∇ h i + ∑ i q μ i ∇ g i = 0 h j = 0 , j = 1 , 2 , ⋯ , n g i ≤ 0 , i = 1 , 2 , ⋯ , m μ i ≥ 0 μ i g i = 0 (4-21) \left\{\begin{array}{l}\nabla f+\sum_{j}^{p} \lambda_{j} \nabla h_{i}+\sum_{i}^{q} \mu_{i} \nabla g_{i}=0 \\ h_{j}=0, j=1,2, \cdots, n \\ g_{i} \leq 0, i=1,2, \cdots, m \\ \mu_{i} \geq 0 \\ \mu_{i} g_{i}=0\end{array}\right.\tag{4-21} ⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧∇f+∑jpλj∇hi+∑iqμi∇gi=0hj=0,j=1,2,⋯,ngi≤0,i=1,2,⋯,mμi≥0μigi=0(4-21)下面分别对这五个方程进行介绍:
- 第一个方程说明目标函数的梯度是等式和不等式约束梯度的线性组合(参见上述讨论);
- 第二个方程对应原优化问题的等式约束;
- 第三个方程对应原优化问题的非等式约束;
- 第四个方程式引入拉格朗日乘子(此处成为KKT乘子)需要满足的条件,成为对偶松弛条件;
- 第五个方程成为互补松弛条件,如果对于第 k k k个不等式约束,对应的 u i u_{i} ui为0,则该条件称为非活跃约束,最优解不在该条件的边界上;如果对于第 k k k个不等式约束,对应的 u i u_{i} ui不为0,则 g i = 0 g_{i}=0 gi=0,则该条件称为活跃约束,最优解在该条件的边界上。
对于一般优化问题,KKT条件是去机制的必要条件,如果最优化问题是一个凸优化问题,则KKT条件是取得极值的充要条件。
补充知识完毕。
模型求解
我们回到问题的求解上来。考虑硬间隔支持向量机的优化目标公式4-8:
min w , b 1 2 ∥ w ∥ 2 s.t. y i ( w T x i + b ) ⩾ 1 , i = 1 , 2 , … , N (4-8) \begin{array}{l}\min _{w, b} \frac{1}{2}\|\boldsymbol{w}\|^{2} \\ \text { s.t. } y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right) \geqslant 1, \quad i=1,2, \ldots, N\end{array}\tag{4-8} minw,b21∥w∥2 s.t. yi(wTxi+b)⩾1,i=1,2,…,N(4-8)首先观察优化问题的目标函数是一个二次函数,二次函数的黑塞矩阵正定,为凸函数,约束条件是仿射函数,可行域为凸集,因此这是一个典型的凸优化问题;由于硬间隔支持向量机假设数据是线性可分的,因此一定存在解,假设 w 0 \boldsymbol w_0 w0和 b 0 \boldsymbol b_0 b0是一组解,有 y i ( w 0 T x i + b 0 ) ⩾ 1 y_{i}\left(\boldsymbol{w}_0^{\mathrm{T}} \boldsymbol{x}_{i}+b_0\right) \geqslant 1 yi(w0Txi+b0)⩾1,则一定有 α w 0 \alpha \boldsymbol w_0 αw0和 α b 0 \alpha \boldsymbol b_0 αb0是另一组解, α \alpha α不为0。且当 α > 1 \alpha>1 α>1时,不等式约束严格满足。 因此该优化问题满足Slater条件,强对偶关系成立。
容易写出它对应的拉格朗日函数: L ( w , b , α ) = 1 2 w T w − ∑ i = 1 N α i ( y i ( w T x i + b ) − 1 ) (4-22) L(\boldsymbol{w}, b, \boldsymbol{\alpha})=\frac{1}{2} \boldsymbol{w}^{\mathrm{T}} \boldsymbol{w}-\sum_{i=1}^{N} \alpha_{i}\left(y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right)-1\right)\tag{4-22} L(w,b,α)=21wTw−i=1∑Nαi(yi(wTxi+b)−1)(4-22)
根据拉格朗日乘子法,最优化问题应该是:
min w , b max α i ⩾ 0 L ( w , b , α ) (4-23) \min _{\boldsymbol{w},b} \max _{\alpha_{i} \geqslant 0} L(\boldsymbol{w}, b, \boldsymbol{\alpha}) \tag{4-23} w,bminαi⩾0maxL(w,b,α)(4-23)注意 L ( w , b , α ) L(\boldsymbol{w}, b, \boldsymbol{\alpha}) L(w,b,α)是一个关于 α \alpha α的一次方程,如果先以 α \alpha α为自变量求梯度,令梯度为0向量的话,无法求解处最优的 α \alpha α。由于强对偶成立,因此求解其对偶问题: max α i ⩾ 0 min w , b L ( w , b , α ) (4-24) \max _{\alpha_{i} \geqslant 0}\min _{\boldsymbol{w}, b} L(\boldsymbol{w}, b, \boldsymbol{\alpha})\tag{4-24} αi⩾0maxw,bminL(w,b,α)(4-24)令梯度为0向量,有 ∇ w L = w − ∑ i = 1 N α i y i x i = 0 \nabla_{w} L=\boldsymbol{w}-\sum_{i=1}^{N} \alpha_{i} y_{i} \boldsymbol{x}_{i}=\mathbf{0} ∇wL=w−∑i=1Nαiyixi=0和 ∂ L ∂ b = ∑ i = 1 N α i y i = 0 \frac{\partial L}{\partial b}=\sum_{i=1}^{N} \alpha_{i} y_{i}=0 ∂b∂L=∑i=1Nαiyi=0,求解得到: ∑ i = 1 N α i y i = 0 (4-25) \sum_{i=1}^{N} \alpha_{i} y_{i}=0\tag{4-25} i=1∑Nαiyi=0(4-25) w = ∑ i = 1 N α i y i x i (4-26) \boldsymbol{w}=\sum_{i=1}^{N} \alpha_{i} y_{i} \boldsymbol{x}_{i}\tag{4-26} w=i=1∑Nαiyixi(4-26)
将4-25和4-26带入到朗格朗日函数中可以消除 w \boldsymbol{w} w和 b b b: L = 1 2 w T w − ∑ i = 1 N α i ( y i ( w T x i + b ) − 1 ) = 1 2 w T w − ∑ i = 1 N ( α i y i w T x i + α i y i b − α i ) = 1 2 w T w − ∑ i = 1 N α i y i w T x i − ∑ i = 1 N α i y i b + ∑ i = 1 N α i = 1 2 w T w − w T ∑ i = 1 N α i y i x i − b ∑ i = 1 N α i y i + ∑ i = 1 N α i = 1 2 w T w − w T w + ∑ i = 1 N α i = − 1 2 w T w + ∑ i = 1 N α i = − 1 2 ( ∑ i = 1 N α i y i x i ) T ( ∑ j = 1 N α j y j x j ) + ∑ i = 1 N α i (4-27) \begin{array}{l}L=\frac{1}{2} \boldsymbol{w}^{\mathrm{T}} \boldsymbol{w}-\sum_{i=1}^{N} \alpha_{i}\left(y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right)-1\right)=\frac{1}{2} \boldsymbol{w}^{\mathrm{T}} \boldsymbol{w}-\sum_{i=1}^{N}\left(\alpha_{i} y_{i} \boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+\alpha_{i} y_{i} b-\alpha_{i}\right) \\ =\frac{1}{2} \boldsymbol{w}^{\mathrm{T}} \boldsymbol{w}-\sum_{i=1}^{N} \alpha_{i} y_{i} \boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}-\sum_{i=1}^{N} \alpha_{i} y_{i} b+\sum_{i=1}^{N} \alpha_{i}=\frac{1}{2} \boldsymbol{w}^{\mathrm{T}} \boldsymbol{w}-\boldsymbol{w}^{\mathrm{T}} \sum_{i=1}^{N} \alpha_{i} y_{i} \boldsymbol{x}_{i}-b \sum_{i=1}^{N} \alpha_{i} y_{i}+\sum_{i=1}^{N} \alpha_{i} \\ =\frac{1}{2} \boldsymbol{w}^{\mathrm{T}} \boldsymbol{w}-\boldsymbol{w}^{\mathrm{T}} \boldsymbol{w}+\sum_{i=1}^{N} \alpha_{i}=-\frac{1}{2} \boldsymbol{w}^{\mathrm{T}} \boldsymbol{w}+\sum_{i=1}^{N} \alpha_{i}=-\frac{1}{2}\left(\sum_{i=1}^{N} \alpha_{i} y_{i} \boldsymbol{x}_{i}\right)^{\mathrm{T}}\left(\sum_{j=1}^{N} \alpha_{j} y_{j} \boldsymbol{x}_{j}\right)+\sum_{i=1}^{N} \alpha_{i}\end{array}\tag{4-27} L=21wTw−∑i=1Nαi(yi(wTxi+b)−1)=21wTw−∑i=1N(αiyiwTxi+αiyib−αi)=21wTw−∑i=1NαiyiwTxi−∑i=1Nαiyib+∑i=1Nαi=21wTw−wT∑i=1Nαiyixi−b∑i=1Nαiyi+∑i=1Nαi=21wTw−wTw+∑i=1Nαi=−21wTw+∑i=1Nαi=−21(∑i=1Nαiyixi)T(∑j=1Nαjyjxj)+∑i=1Nαi(4-27)
同时别忘了我们还有两个约束条件,即所有的 α i \alpha_{i} αi大于等于0以及我们得到的关系式4-25。最后我们的优化问题变成: min α ( 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j x i T x j − ∑ i = 1 N α i ) α i ⩾ 0 , i = 1 , 2 , … N ∑ i = 1 N α i y i = 0 (4-28) \begin{array}{l}\min _{\alpha}\left(\frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j} \boldsymbol{x}_{i}^{\mathrm{T}} \boldsymbol{x}_{j}-\sum_{i=1}^{N} \alpha_{i}\right) \\ \alpha_{i}\geqslant0,i=1,2,\dots N\\\sum_{i=1}^{N} \alpha_{i} y_{i}=0\end{array}\tag{4-28} minα(21∑i=1N∑j=1NαiαjyiyjxiTxj−∑i=1Nαi)αi⩾0,i=1,2,…N∑i=1Nαiyi=0(4-28)
对于熟悉优化问题的同学们而言,这是一个典型的凸二次优化问题,可以用一些求解QP问题的套件来具体求解,也可以直接使用SMO算法求解(SMO算法挖坑)。
求出 α \alpha α后,可以利用公式4-26求解 w \boldsymbol w w,再利用互补松弛条件找到一个不为0的 α i \alpha_i αi求 b b b(可以求得 b = y p − w T x p b=y_{p}-\boldsymbol{w}^{T} \boldsymbol{x}_{p} b=yp−wTxp,其中 x p \boldsymbol{x}_{p} xp是第 p p p个 α p \alpha_{p} αp不为0的数据)。
模型解析
通过对硬间隔支持向量机的图形化分析,我们知道对分类起到关键作用的实际上是“支持向量”,也就是前面图中虚线上的数据点。在实际的模型求解中,这些数据也起到至关重要的作用。
考虑互补松弛条件 α i ( 1 − y i ( w T x i + b ) ) = 0 \alpha_{i}\left(1-y_{i}\left(\boldsymbol {w}^{T} \boldsymbol {x}_{i}+b\right)\right)=0 αi(1−yi(wTxi+b))=0,实际上有大量的 α i \alpha_i αi求解出来是0,这些 α i \alpha_i αi对应的数据点就是“支持向量”以外的点,这些点对模型的求解没有作用。换句话说,不管添加多少个数据点,只要这些数据点不是支持向量,SVM的最优解不变。
上述特性通过求解过程也很容易理解。因为我们对 w \boldsymbol w w的求解依赖的是公式4-26,而公式4-26中的 α i \alpha_i αi为0对应的 y i x i y_{i} \boldsymbol{x}_i yixi起不到任何作用。对 b b b的求解也是如此。
此外,我们发现,新的优化问题跟原问题相比,变量的个数为 N N N个,约束条件有 N + 1 N+1 N+1个, N N N是数据 的数量,也就是说现在问题的求解难度只跟数据集大小有关,跟自变量(或者经过特征转换过的自变量)的空间大小无关。
软间隔支持向量机
模型形式
硬间隔支持向量机有一个基本假设是数据是线性可分的,这在实际情况中很难出现,因此需要对其进行改进。
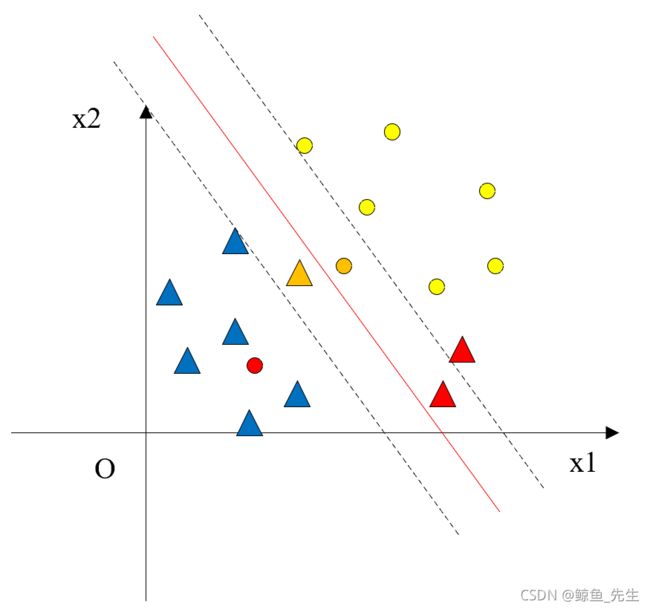
软间隔支持向量机设置松弛变量,以此来放松对线性可分的限制。在硬间隔支持向量机中,我们假设支持向量到超平面的距离为1,因此有约束条件: y i ( w T x i + b ) ⩾ 1 y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right) \geqslant 1 yi(wTxi+b)⩾1,设松弛变量 ξ i \xi_{i} ξi是一个大于等于0的实数,那些支持向量以外的点(图4-5中的橙色点)以及不能被正确分类的点(图4-6中的红色点)到超平面的距离记作 1 − ξ i 1-\xi_{i} 1−ξi,同时我们应该在目标函数中对不能正确划分的数据进行惩罚,惩罚系数为 C > 0 C> 0 C>0。于是,新的优化问题变成了如下形式: min w , b , ξ ( 1 2 w T w + C ∑ i = 1 N ξ i ) y i ( w T x i + b ) ⩾ 1 − ξ i ξ i ⩾ 0 , i = 1 , ⋯ , N (4-29) \begin{array}{l}\min _{\boldsymbol{w}, b, \boldsymbol{\xi}}\left(\frac{1}{2} \boldsymbol{w}^{\mathrm{T}} \boldsymbol{w}+C \sum_{i=1}^{N} \xi_{i}\right) \\ y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right) \geqslant 1-\xi_{i} \\ \xi_{i} \geqslant 0, i=1, \cdots, N\end{array}\tag{4-29} minw,b,ξ(21wTw+C∑i=1Nξi)yi(wTxi+b)⩾1−ξiξi⩾0,i=1,⋯,N(4-29)
另外需要说明的是,松弛变量和折页损失函数效果相同,后者可以写作:
可以证明,4-29所示的优化问题满足Slater条件,强对偶关系成立。因此可以使用拉格朗日对偶方法,求解如下最优化问题:
max α i ⩾ 0 , ξ i ⩾ 0 , β min w , b L ( w , b , α , ξ , β ) ) (4-30) \max _{\alpha_{i} \geqslant 0, \xi_{i} \geqslant 0, \boldsymbol \beta} \min _{\boldsymbol{w},b} L(\boldsymbol{w}, b, \boldsymbol{\alpha}, \boldsymbol{\xi}, \boldsymbol{\beta})) \tag{4-30} αi⩾0,ξi⩾0,βmaxw,bminL(w,b,α,ξ,β))(4-30)其中拉格朗日函数:
L ( w , b , α , ξ , β ) = 1 2 w T w + C ∑ i = 1 N ξ i − ∑ i = 1 N α i ( y i ( w T x i + b ) − 1 + ξ i ) − ∑ i = 1 N β i ξ i (4-31) L(\boldsymbol{w}, b, \boldsymbol{\alpha}, \boldsymbol{\xi}, \boldsymbol{\beta})=\frac{1}{2} \boldsymbol{w}^{\mathrm{T}} \boldsymbol{w}+C \sum_{i=1}^{N} \xi_{i}-\sum_{i=1}^{N} \alpha_{i}\left(y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right)-1+\xi_{i}\right)-\sum_{i=1}^{N} \beta_{i} \xi_{i}\tag{4-31} L(w,b,α,ξ,β)=21wTw+Ci=1∑Nξi−i=1∑Nαi(yi(wTxi+b)−1+ξi)−i=1∑Nβiξi(4-31)
模型求解
首先求以 w \boldsymbol w w和 b b b为自变量的最小值,求梯度令梯度为0可得: ∇ w L = w − ∑ i = 1 N α i y i x i = 0 ∂ L ∂ b = ∑ i = 1 N α i y i = 0 (4-32) \nabla_{\boldsymbol{w}} L=\boldsymbol{w}-\sum_{i=1}^{N} \alpha_{i} y_{i} \boldsymbol{x}_{i}=\mathbf{0} \quad \frac{\partial L}{\partial b}=\sum_{i=1}^{N} \alpha_{i} y_{i}=0\tag{4-32} ∇wL=w−i=1∑Nαiyixi=0∂b∂L=i=1∑Nαiyi=0(4-32)
因此有: ∑ i = 1 N α i y i = 0 w = ∑ i = 1 N α i y i x i (4-33) \sum_{i=1}^{N} \alpha_{i} y_{i}=0 \quad \quad \boldsymbol{w}=\sum_{i=1}^{N} \alpha_{i} y_{i} \boldsymbol{x}_{i}\tag{4-33} i=1∑Nαiyi=0w=i=1∑Nαiyixi(4-33)
将4-33代入到拉格朗日函数中有: L ( w , b , α , ξ , β ) = 1 2 w T w + C ∑ i = 1 N ξ i − ∑ i = 1 N α i ( y i ( w T x i + b ) − 1 + ξ i ) − ∑ i = 1 N β i ξ i = 1 2 w T w + C ∑ i = 1 N ξ i − ∑ i = 1 N β i ξ i − ∑ i = 1 N α i ξ i − ∑ i = 1 N α i ( y i ( w T x i + b ) − 1 ) = 1 2 w T w + ∑ i = 1 N ( C − α i − β i ) ξ i − ∑ i = 1 N ( α i y i w T x i + α i y i b − α i ) = 1 2 w T w − ∑ i = 1 N α i y i w T x i − ∑ i = 1 N α i y i b + ∑ i = 1 N α i + ∑ i = 1 N ( C − α i − β i ) ξ i = 1 2 w T w − w T w + ∑ i = 1 N α i + ∑ i = 1 N ( C − α i − β i ) ξ i = − 1 2 w T w + ∑ i = 1 N α i = − 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j x i T x j + ∑ i = 1 N α i + ∑ i = 1 N ( C − α i − β i ) ξ i (4-34) \begin{aligned} L(\boldsymbol{w}, b, \boldsymbol{\alpha}, \boldsymbol{\xi}, \boldsymbol{\beta}) &=\frac{1}{2} \boldsymbol{w}^{\mathrm{T}} \boldsymbol{w}+C \sum_{i=1}^{N} \xi_{i}-\sum_{i=1}^{N} \alpha_{i}\left(y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right)-1+\xi_{i}\right)-\sum_{i=1}^{N} \beta_{i} \xi_{i} \\ &=\frac{1}{2} \boldsymbol{w}^{\mathrm{T}} \boldsymbol{w}+C \sum_{i=1}^{N} \xi_{i}-\sum_{i=1}^{N} \beta_{i} \xi_{i}-\sum_{i=1}^{N} \alpha_{i} \xi_{i}-\sum_{i=1}^{N} \alpha_{i}\left(y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right)-1\right) \\ &=\frac{1}{2} \boldsymbol{w}^{\mathrm{T}} \boldsymbol{w}+\sum_{i=1}^{N}\left(C-\alpha_{i}-\beta_{i}\right) \xi_{i}-\sum_{i=1}^{N}\left(\alpha_{i} y_{i} \boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+\alpha_{i} y_{i} b-\alpha_{i}\right) \\ &=\frac{1}{2} \boldsymbol{w}^{\mathrm{T}} \boldsymbol{w}-\sum_{i=1}^{N} \alpha_{i} y_{i} \boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}-\sum_{i=1}^{N} \alpha_{i} y_{i} b+\sum_{i=1}^{N} \alpha_{i} +\sum_{i=1}^{N}\left(C-\alpha_{i}-\beta_{i}\right) \xi_{i}\\ &=\frac{1}{2} \boldsymbol{w}^{\mathrm{T}} \boldsymbol{w}-\boldsymbol{w}^{\mathrm{T}} \boldsymbol{w}+\sum_{i=1}^{N} \alpha_{i}+\sum_{i=1}^{N}\left(C-\alpha_{i}-\beta_{i}\right) \xi_{i}=-\frac{1}{2} \boldsymbol{w}^{\mathrm{T}} \boldsymbol{w}+\sum_{i=1}^{N} \alpha_{i} \\ &=-\frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j} \boldsymbol{x}_{i}^{\mathrm{T}} \boldsymbol{x}_{j}+\sum_{i=1}^{N} \alpha_{i} +\sum_{i=1}^{N}\left(C-\alpha_{i}-\beta_{i}\right) \xi_{i}\end{aligned}\tag{4-34} L(w,b,α,ξ,β)=21wTw+Ci=1∑Nξi−i=1∑Nαi(yi(wTxi+b)−1+ξi)−i=1∑Nβiξi=21wTw+Ci=1∑Nξi−i=1∑Nβiξi−i=1∑Nαiξi−i=1∑Nαi(yi(wTxi+b)−1)=21wTw+i=1∑N(C−αi−βi)ξi−i=1∑N(αiyiwTxi+αiyib−αi)=21wTw−i=1∑NαiyiwTxi−i=1∑Nαiyib+i=1∑Nαi+i=1∑N(C−αi−βi)ξi=21wTw−wTw+i=1∑Nαi+i=1∑N(C−αi−βi)ξi=−21wTw+i=1∑Nαi=−21i=1∑Nj=1∑NαiαjyiyjxiTxj+i=1∑Nαi+i=1∑N(C−αi−βi)ξi(4-34)
通过比较可以看出,4-34比4-27仅仅多了最后一项 ∑ i = 1 N ( C − α i − β i ) ξ i \sum_{i=1}^{N}\left(C-\alpha_{i}-\beta_{i}\right) \xi_{i} ∑i=1N(C−αi−βi)ξi,我们可以继续对 ξ \boldsymbol \xi ξ求梯度,可以得到:
∂ L ∂ ξ i = C − α i − β i = 0 (4-35) \frac{\partial L}{\partial \xi_{i}}=C-\alpha_{i}-\beta_{i}=0\tag{4-35} ∂ξi∂L=C−αi−βi=0(4-35)
同时别忘了我们的两个约束条件,即所有的 α i \alpha_{i} αi大于等于0以及我们得到的关系式4-25,另外还有公式4-35以及 β i ⩾ 0 \beta_{i}\geqslant0 βi⩾0,可以得到 0 ⩽ α i ⩽ C 0 \leqslant \alpha_{i} \leqslant C 0⩽αi⩽C。于是,最终的优化问题变成: min α ( 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j x i T x j − ∑ i = 1 N α i ) 0 ⩽ α i ⩽ C , i = 1 , 2 , … N ∑ i = 1 N α i y i = 0 (4-36) \begin{array}{l}\min _{\alpha}\left(\frac{1}{2} \sum_{i=1}^{N} \sum_{j=1}^{N} \alpha_{i} \alpha_{j} y_{i} y_{j} \boldsymbol{x}_{i}^{\mathrm{T}} \boldsymbol{x}_{j}-\sum_{i=1}^{N} \alpha_{i}\right) \\0\leqslant \alpha_{i} \leqslant C,i=1,2,\dots N\\\sum_{i=1}^{N} \alpha_{i} y_{i}=0\end{array}\tag{4-36} minα(21∑i=1N∑j=1NαiαjyiyjxiTxj−∑i=1Nαi)0⩽αi⩽C,i=1,2,…N∑i=1Nαiyi=0(4-36)
模型解析
优化问题4-36进一步可以写成矩阵形式: min α 1 2 α T Q α − e T α 0 ⩽ α i ⩽ C y T α = 0 (4-37) \begin{array}{l}\min _{\alpha} \frac{1}{2} \boldsymbol{\alpha}^{\mathrm{T}} \boldsymbol{Q} \boldsymbol{\alpha}-\boldsymbol{e}^{\mathrm{T}} \boldsymbol{\alpha} \\ 0 \leqslant \alpha_{i} \leqslant C \\ \boldsymbol{y}^{\mathrm{T}} \boldsymbol{\alpha}=0\end{array}\tag{4-37} minα21αTQα−eTα0⩽αi⩽CyTα=0(4-37)
其中 Q i j = y i y j x i T x j = ( y 1 x 1 , ⋯ , y N x N ) T ( y 1 x 1 , ⋯ , y N x N ) Q_{i j}=y_{i} y_{j} \boldsymbol{x}_{i}^{\mathrm{T}} \boldsymbol{x}_{j}=\left(y_{1} \boldsymbol{x}_{1}, \cdots, y_{N} \boldsymbol{x}_{N}\right)^T\left(y_{1} \boldsymbol{x}_{1}, \cdots, y_{N} \boldsymbol{x}_{N}\right) Qij=yiyjxiTxj=(y1x1,⋯,yNxN)T(y1x1,⋯,yNxN),很明显是一个半正定矩阵,它也是目标函数的黑塞矩阵,黑塞矩阵半正定,说明目标函数是一个凸函数,约束条件都是线性的,可行域是凸集,因此该问题是凸优化问题,在最优点处 满足KKT条件。
原问题的两个不等式约束必须满足互补松弛性,即: α i ( y i ( w T x i + b ) − 1 + ξ i ) = 0 , i = 1 , ⋯ , N β i ξ i = 0 , i = 1 , ⋯ , N (4-38) \begin{aligned} \alpha_{i}\left(y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right)-1+\xi_{i}\right)=0, & i=1, \cdots, N \\ \beta_{i} \xi_{i}=0, & i=1, \cdots, N \end{aligned}\tag{4-38} αi(yi(wTxi+b)−1+ξi)=0,βiξi=0,i=1,⋯,Ni=1,⋯,N(4-38)同时还要满足原问题中的约束条件,即: y i ( w T x i + b ) ⩾ 1 − ξ i ξ i ⩾ 0 , i = 1 , ⋯ , N (4-39) \begin{array}{l}y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right) \geqslant 1-\xi_{i} \\ \xi_{i} \geqslant 0, i=1, \cdots, N\end{array}\tag{4-39} yi(wTxi+b)⩾1−ξiξi⩾0,i=1,⋯,N(4-39)以及KKT乘子大于等于0: α i ⩾ 0 , i = 1 , ⋯ , N β i ⩾ 0 , i = 1 , ⋯ , N (4-40) \begin{aligned} \alpha_{i}\geqslant0, & i=1, \cdots, N \\ \beta_{i} \geqslant0, & i=1, \cdots, N \end{aligned}\tag{4-40} αi⩾0,βi⩾0,i=1,⋯,Ni=1,⋯,N(4-40)以及梯度为0给我们的信息: α i + β i = C (4-41) \alpha_{i}+\beta_{i}=C\tag{4-41} αi+βi=C(4-41)
结合4-38到4-41,我们分三种情况对模型进行解析。
- 当 α i = 0 \alpha_{i}=0 αi=0时, ( y i ( w T x i + b ) − 1 + ξ i ) \left(y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right)-1+\xi_{i}\right) (yi(wTxi+b)−1+ξi)没有约束, β i = C \beta_{i}=C βi=C;因为 β i ξ i = 0 \beta_{i} \xi_{i}=0 βiξi=0,所以 ξ i = 0 \xi_{i} =0 ξi=0,结合4-39的第一个不等式推导出 y i ( w T x i + b ) ⩾ 1 y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right) \geqslant 1 yi(wTxi+b)⩾1。也就是说,当 α i = 0 \alpha_{i}=0 αi=0时,对应的数据到超平面的点比支持向量点到超平面的距离(即1)要大,这些数据点对模型没有影响,为自由向量。
- 当 α i = C \alpha_{i}=C αi=C时,根据互补松弛性的第一个公式,有 ( y i ( w T x i + b ) − 1 + ξ i ) = 0 \left(y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right)-1+\xi_{i}\right)=0 (yi(wTxi+b)−1+ξi)=0,即 y i ( w T x i + b ) = 1 − ξ i y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right)=1-\xi_{i} yi(wTxi+b)=1−ξi;根据公式4-41, β i = 0 \beta_{i}=0 βi=0,互补松弛性对 ξ i \xi_{i} ξi没有约束,约束条件中有 ξ i ⩾ 0 \xi_{i} \geqslant 0 ξi⩾0,因此 y i ( w T x i + b ) = 1 − ξ i ⩽ 1 y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right)=1-\xi_{i}\leqslant1 yi(wTxi+b)=1−ξi⩽1,也就是说,当 α i = C \alpha_{i}=C αi=C时,对应的数据到超平面的点比支持向量点到超平面的距离(即1)要小,这些数据点时违反硬间隔不等式约束的数据点(即不能不线性划分的点)。
- 当 0 ⩽ α i ⩽ C 0\leqslant \alpha_{i}\leqslant C 0⩽αi⩽C时,我们既有 y i ( w T x i + b ) ⩾ 1 y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right) \geqslant 1 yi(wTxi+b)⩾1又有 y i ( w T x i + b ) = 1 − ξ i ⩽ 1 y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right)=1-\xi_{i}\leqslant1 yi(wTxi+b)=1−ξi⩽1,因此 y i ( w T x i + b ) = 1 − ξ i = 1 y_{i}\left(\boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}_{i}+b\right)=1-\xi_{i}=1 yi(wTxi+b)=1−ξi=1。也就是说,当 0 ⩽ α i ⩽ C 0\leqslant \alpha_{i}\leqslant C 0⩽αi⩽C时,对应的数据点是支持向量。
支持向量机的核技巧
模型形式
上文提到,对于硬间隔支持向量机,利用拉格朗日对偶方法优化问题可以写成4-28,对于软间隔支持向量机,利用拉格朗日对偶方法优化问题可以写成4-36。
同时,值得注意的是即便不使用拉格朗日对偶方法,原优化问题也是一个凸优化问题,一样可以借助一些QP套件进行求解。之所以使用拉格朗日乘子对偶方法,是想将原来 p + 1 p+1 p+1个自变量、 N N N个约束条件的优化问题转化成 N N N个自变量、 N + 1 N+1 N+1个约束条件的优化问题。这样一来,优化问题的复杂度就跟输入空间的大小无关,只跟样本数量有关了。这样的方法特别适合输入空间比较大的优化问题,尤其是在原输入空间线性不可分的情况下,需要首先进行特征转换,转换后的新特征空间的维度有可能会很大甚至是无穷维。
然而,我们观察使用拉格朗日对偶之后的优化问题,尽管需要优化的变量数量有变化,但是依然没法彻底解决维度太大带来的计算问题。因为在计算 x i T x j \boldsymbol{x}_{i}^{\mathrm{T}} \boldsymbol{x}_{j} xiTxj( x i \boldsymbol{x}_{i} xi可以属于原来的输入空间,也可以属于新的特征空间),即计算输入向量的内积时,还是受数据维度的影响。如果输入向量是经过特征转换后的特征空间,这个空间可能很大,计算起来会非常麻烦。而对于大部分问题,一般来说使用特征转换后效果会要好得多。因此最好有一种方法能够帮助我们彻底摆脱计算内积时特征空间维度的影响。于是,核技巧横空出世!
核技巧的基本思想是:既然计算输入变量的内积时会受到特征转换后特征空间维度的影响,那么可以想办法将特征转换和内积计算结合起来。我们一起来看一下这样的思路是否可行。
我们将特征转换后的特征向量记作 z i , i = 1 , 2 , … , N \boldsymbol z_i,i=1,2,\dots,N zi,i=1,2,…,N,特征转换函数记作 Φ ( ⋅ ) \Phi\left( \cdot\right) Φ(⋅),即 z i = Φ ( x i ) \boldsymbol z_{i}=\Phi\left(\boldsymbol x_{i}\right) zi=Φ(xi),特征向量的内积 z i T z j = Φ ( x i ) Φ ( x j ) \boldsymbol z_{i}^{T} \boldsymbol z_{j}=\Phi\left(\boldsymbol x_{i}\right) \Phi\left(\boldsymbol x_{j}\right) ziTzj=Φ(xi)Φ(xj)。我们以硬间隔支持向量机对应的优化问题4-28进行示范,软间隔支持向量机的形式可以由其推而广之。
硬间隔支持向量机的优化问题用矩阵形式可以写成: min α 1 2 α T Q α − e T α α i ⩾ 0 , i = 1 , 2 , … N ∑ i = 1 N α i y i = 0 (4-42) \begin{array}{l}\min _{\alpha} \frac{1}{2} \boldsymbol{\alpha}^{\mathrm{T}} \boldsymbol{Q} \boldsymbol{\alpha}-\boldsymbol{e}^{\mathrm{T}} \boldsymbol{\alpha} \\ \alpha_{i} \geqslant 0, i=1,2, \ldots N \\ \sum_{i=1}^{N} \alpha_{i} y_{i}=0\end{array}\tag{4-42} minα21αTQα−eTααi⩾0,i=1,2,…N∑i=1Nαiyi=0(4-42)
其中 Q i j = y i y j Φ ( x i ) T Φ ( x j ) = ( y 1 Φ ( x i ) ⋯ , y N Φ ( x i ) ) T ( y 1 x 1 , ⋯ , y N Φ ( x N ) ) Q_{i j}=y_{i} y_{j}\Phi\left(\boldsymbol x_{i}\right)^T \Phi\left(\boldsymbol x_{j}\right)=\left(y_{1} \Phi\left(\boldsymbol x_{i}\right) \cdots, y_{N}\Phi\left(\boldsymbol x_{i}\right) \right)^T\left(y_{1} \boldsymbol{x}_{1}, \cdots, y_{N} \Phi\left(\boldsymbol x_{N}\right) \right) Qij=yiyjΦ(xi)TΦ(xj)=(y1Φ(xi)⋯,yNΦ(xi))T(y1x1,⋯,yNΦ(xN))。
定义核函数,将特征转换和特征转换后的内积两个步骤合并: K Φ ( x i , x j ) = Φ ( x i ) T Φ ( x j ) (4-43) K_{\Phi}\left(\boldsymbol x_i,\boldsymbol x_j\right)=\Phi(\boldsymbol x_i)^T \Phi\left(\boldsymbol x_j\right)\tag{4-43} KΦ(xi,xj)=Φ(xi)TΦ(xj)(4-43)
于是有: Q i j = y i y j K Φ ( x i , x j ) (4-44) Q_{i j}=y_{i} y_{j} K_{\Phi}\left(\boldsymbol{x}_{i}, \boldsymbol{x}_{j}\right)\tag{4-44} Qij=yiyjKΦ(xi,xj)(4-44)接下来需要找到合适的核函数, K Φ ( x i , x j ) K_{\Phi}\left(\boldsymbol{x}_{i}, \boldsymbol{x}_{j}\right) KΦ(xi,xj)使得相关运算不再受特征空间的维度影响。
我们不妨先来看看一个特例,对于二阶多项式的特征转换,我们将原始的输入变量 x i \boldsymbol x_i xi映射到二阶多项式对应的空间: Φ 2 ( x i ) = ( 1 , x i 1 , x i 2 , … , x i p , x i 2 , x i 1 x i 2 , … , x i 1 x i p , x i 2 x i 1 , x i 2 2 , … , x i 2 x i p , … , x i p 2 ) (4-45) \Phi_{2}(\boldsymbol{x_i})=\left(1, \boldsymbol x_{i1}, \boldsymbol x_{i2}, \ldots, \boldsymbol x_{ip}, \boldsymbol x_{i}^{2}, \boldsymbol x_{i1}\boldsymbol x_{i2}, \ldots, \boldsymbol x_{i1}\boldsymbol x_{ip}, \boldsymbol x_{i2}\boldsymbol x_{i1}, \boldsymbol x_{i2}^{2}, \ldots, \boldsymbol x_{i2}\boldsymbol x_{ip}, \ldots, \boldsymbol x_{ip}^{2}\right)\tag{4-45} Φ2(xi)=(1,xi1,xi2,…,xip,xi2,xi1xi2,…,xi1xip,xi2xi1,xi22,…,xi2xip,…,xip2)(4-45)
那么我们有:
K Φ ( x i , x j ) = Φ ( x i ) T Φ ( x j ) = 1 + ∑ d = 1 p x i d x j d + ∑ d = 1 p ∑ d = 1 p x i d x i d x j d x j d = 1 + ∑ i = 1 p x i d x j d + ∑ d = 1 p x i d x j d ∑ d = 1 p x i d x j d = 1 + x i T x j + ( x i T x j ) ( x i T x j ) (4-46) \begin{aligned} K_{\Phi}\left(\boldsymbol{x}_{i}, \boldsymbol{x}_{j}\right)=\Phi\left(\boldsymbol{x}_{i}\right)^{T} \Phi\left(\boldsymbol{x}_{j}\right) &=1+\sum_{d=1}^{p} x_{id} x_{jd}+\sum_{d=1}^{p} \sum_{d=1}^{p} x_{id} x_{id} x_{jd}x_{jd} \\ &=1+\sum_{i=1}^{p} x_{id} x_{jd}+\sum_{d=1}^{p} x_{id} x_{jd}\sum_{d=1}^{p} x_{id} x_{jd}\\ &=1+\boldsymbol {x_i}^{T} \boldsymbol {x_j}+\left(\boldsymbol {x_i}^{T} \boldsymbol {x_j}\right)\left(\boldsymbol {x_i}^{T} \boldsymbol {x_j}\right) \end{aligned}\tag{4-46} KΦ(xi,xj)=Φ(xi)TΦ(xj)=1+d=1∑pxidxjd+d=1∑pd=1∑pxidxidxjdxjd=1+i=1∑pxidxjd+d=1∑pxidxjdd=1∑pxidxjd=1+xiTxj+(xiTxj)(xiTxj)(4-46)
二次多项式转换后的特征空间维度是 p 2 + 1 p^2+1 p2+1, 经过核函数处理后,相关的运算只与 x \boldsymbol x x(维度是 p p p)有关,而与特征空间的维度无关。
也就是说,经过核函数的运算后,尽管原始输入空间使用了特征转换,但是矩阵 Q Q Q各元素的相关运算 Q i j = y i y j K Φ ( x i , x j ) Q_{i j}=y_{i} y_{j} K_{\Phi}\left(\boldsymbol{x}_{i}, \boldsymbol{x}_{j}\right) Qij=yiyjKΦ(xi,xj)却不再跟特征空间有关。我们使用核函数实现了上面的要求。
二次多项式特征转换更一般的形式可以写成: Φ 2 ( x i ) = ( 1 , 2 γ x i 1 , … , 2 γ x i d , γ x i 1 2 , … , γ x i p 2 ) (4-47) \Phi_{2}(\boldsymbol {x_i})=\left(1, \sqrt{2 \gamma} \boldsymbol x_{i1}, \ldots, \sqrt{2 \gamma} \boldsymbol x_{id}, \gamma \boldsymbol x_{i1}^{2}, \ldots, \gamma \boldsymbol x_{ip}^{2}\right)\tag{4-47} Φ2(xi)=(1,2γxi1,…,2γxid,γxi12,…,γxip2)(4-47)对应的核函数为: K 2 ( x i , x j ) = ( 1 + γ x i T x j ) 2 (4-48) K_{2}\left(\boldsymbol {x_i}, \boldsymbol{x_j}\right)=\left(1+\gamma \boldsymbol {x_i}^{T} \boldsymbol{x_j}\right)^{2}\tag{4-48} K2(xi,xj)=(1+γxiTxj)2(4-48)
称为二次多项式核,其中 γ > 0 \gamma>0 γ>0。已经证明二次多项式核是符合我们要求的核函数,推而广之,更高次的多项式核也是符合我们要求的核函数,感兴趣的同学们可以自行证明。n次多项式核的形式可以统一写成: K n ( x i , x j ) = ( ζ + γ x i T x j ) n (4-48) K_{n}\left(\boldsymbol {x_i}, \boldsymbol{x_j}\right)=\left(\zeta+\gamma \boldsymbol {x_i}^{T} \boldsymbol{x_j}\right)^{n}\tag{4-48} Kn(xi,xj)=(ζ+γxiTxj)n(4-48)其中 γ > 0 , ζ ≥ 0 \gamma>0, \zeta \geq 0 γ>0,ζ