Python爬虫实例:爬取中国天气网上当地一周的气温
爬虫实例:爬取中国天气网上当地一周的气温
首先在程序开始处添加:
#coding:UTF-8
这样就能告诉解释器该py程序是utf-8编码的,源程序中可以有中文
- 第一步:导入要引用的包
import requests #用来爬取网页HTML源代码
import csv #将数据写入CSV文件中
import random #取随机数
import time #时间相关操作
import socket #socket和http.client在这里只用于异常处理
import http.client
import urllib.request #另一种爬取网页的HTML源代码的方法,但是不如requests方便
from bs4 import BeautifulSoup #用来代替正则式取源码中相应标签中的内容
- 获取网页中的HTML代码
def get_content(url , data = None):
header = {'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8',\
'Accept-Encoding':'gzip, deflate',\
'Accept-Language':'zh-CN,zh;q=0.9' ,\
'Connection': 'keep-alive',\
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36'}
timeout = random.choice(range(80,180))
while True:
try:
rep = requests.get(url,headers = header,timeout = timeout)
rep.encoding = 'utf-8'
break
except socket.timeout as e:
print('3:',e)
time.sleep(random.choice(range(8,15)))
except socket.error as e:
print('4:',e)
time.sleep(random.choice(range(20,60)))
except http.client.BadStatusLine as e:
print('5:',e)
time.sleep(random.choice(range(30,80)))
except http.client.IncompleteRead as e:
print('6:',e)
time.sleep(random.choice(range(5,15)))
return(rep.text) #返回html_text
其中header是requests.get的一个参数,目的是模仿浏览器访问。header可以用Chrome的开发者工具获得,具体方法如下:
打开Chrome进入中国天气网
再鼠标右键点击检查
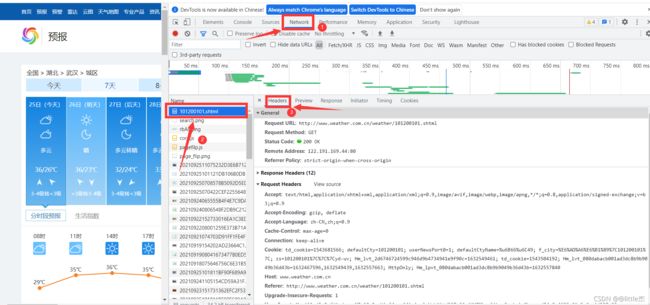
点击Network,查看第一条网络请求,查看它的header
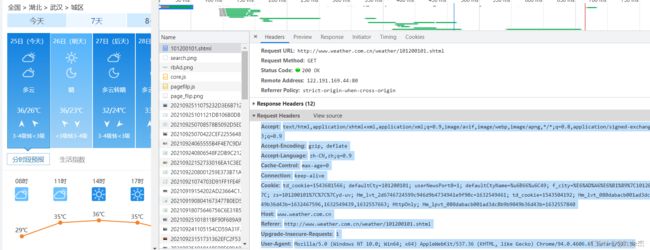
timeout是设定一个超时时间,取随机数是因为防止被网站认定为爬虫(其实就是哈哈哈)然后通过requests.get方法获取网页的源代码,rep.encoding = 'utf-8'是将源代码的编码格式改为utf-8,不改的话,源代码中中文部分会为乱码。
接着,还是用开发者工具查看网页源码,并找到所需字段的相应位置
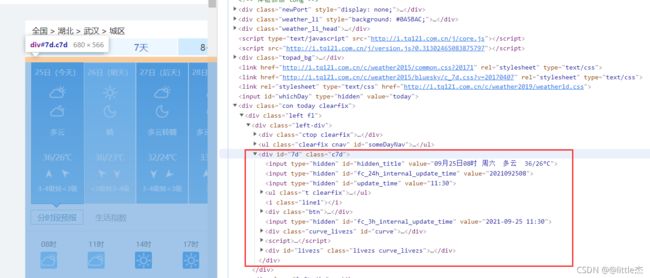
- 我们需要的字段都在id="7d"的‘“div”的ul中。日期在每个li中hl中,天气情况在每个1i的第一个P标签内,最高温度和是最低温度在每个li的span和i标签中。到了傍晚,需要找到当天最高温度,所以要多加一个判断。
代码如下:
def get_data(html_text):
final = []
bs = BeautifulSoup(html_text,"html.parser") #创建beautifulsoup对象
body = bs.body #获取body部分
data = body.find('div',{'id':'7d'}) #找到id为7d的div
ul = data.find('ul') #获取ul部分
li = ul.find_all('li') #获取所有的li部分
for day in li: #对每个li标签中的内容进行遍历
temp = []
date = day.find('h1').string #找到日期
temp.append(date) #添加到temp中
inf = day.find_all('p') #找到li中的所有p标签
temp.append(inf[0].string,) #第一个p标签中的内容(天气状况)加到temp中
if inf[1].find('span') is None:
temperature_highest = None#天气预报可能没有当天的最高气温(到了傍晚,就是这样)
#需要加个判断语句,来输出最低气温
else:
temperature_highest = inf[1].find('i').string #找到最高温度
temperature_highest = temperature_highest.replace('℃','')
temperature_lowest = inf[1].find('span').string #找到最低温度
temperature_lowest = temperature_lowest.replace('℃','')
temp.append(temperature_highest) #将最高温添加到temp中
temp.append(temperature_lowest) #将最低温添加到temp中
final.append(temp) #将temp添加到final中
return final
- 写入文件CSV,将数据爬出来后要将他们写入文件,具体代码如下:
def write_data(data,name):
file_name = name
with open(file_name,'a',errors = 'ignore',newline = '') as f:
f_csv = csv.writer(f)
f_csv.writerows(data)
- 主函数
if __name__ == '__main__':
url = 'http://www.weather.com.cn/weather/101200101.shtml'
html = get_content(url)
result = get_data(html)
write_data(result,'weather.csv')
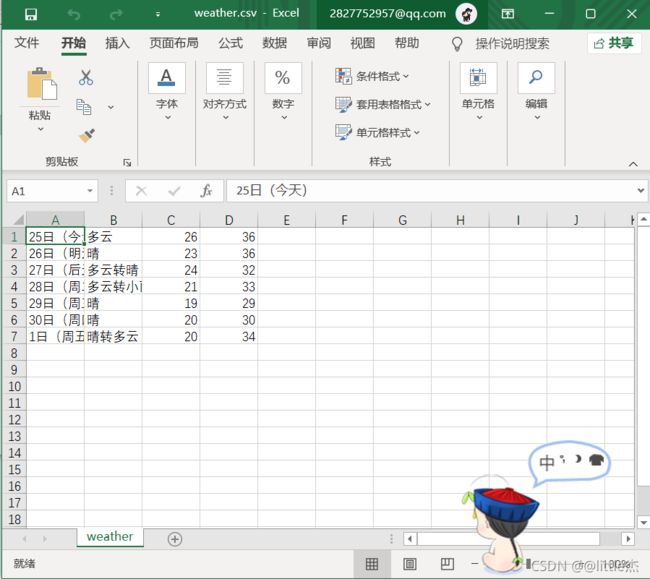
运行程序生成的weather.csv文件如下图所示: