mobilenetv2
如何评价mobilenet v2 ? - 知乎总结一句话就是 业界良心。 另外说点其他答主没提到的东西。 其他答主都已经回答了两个关键的改进: inv… https://www.zhihu.com/question/265709710/answer/298245276详解MobileNetV2 - 知乎MobileNetV2是在V1基础之上的改进。V1主要思想就是深度可分离卷积。如果对这个方面不太了解的话,可以参考我写的这篇文章: 寒号鸟:深度可分离卷积下面重点介绍V2的新概念。 V2的新想法包括Linear Bottleneck 和 …https://zhuanlan.zhihu.com/p/98874284深度可分离卷积 - 知乎一些轻量级的网络,如mobilenet中,会有深度可分离卷积depthwise separable convolution,由depthwise(DW)和pointwise(PW)两个部分结合起来,用来提取特征feature map 相比常规的卷积操作,其参数数量和运算成本比…https://zhuanlan.zhihu.com/p/92134485
https://www.zhihu.com/question/265709710/answer/298245276详解MobileNetV2 - 知乎MobileNetV2是在V1基础之上的改进。V1主要思想就是深度可分离卷积。如果对这个方面不太了解的话,可以参考我写的这篇文章: 寒号鸟:深度可分离卷积下面重点介绍V2的新概念。 V2的新想法包括Linear Bottleneck 和 …https://zhuanlan.zhihu.com/p/98874284深度可分离卷积 - 知乎一些轻量级的网络,如mobilenet中,会有深度可分离卷积depthwise separable convolution,由depthwise(DW)和pointwise(PW)两个部分结合起来,用来提取特征feature map 相比常规的卷积操作,其参数数量和运算成本比…https://zhuanlan.zhihu.com/p/92134485
mobilenetv2是一篇好文章,和resnet一样有理论支撑,有设计思路,也有实际应用的效果。mobilenetv2依然沿袭了resnet的整体结构设计,由mobilenetv1(dw,pwconv的堆叠网络)进化而来。
1.Abstarct:
基于inverted residual structure(在两个thin bottleneck之间的shortcut),在bottleneck中先经过expansion layer再使用轻量级的depthwise conv来过滤特征以提供非线性,此外,我们发现在窄层去掉非线性层是有助于提供模型表示能力(通道数目很小的时候就别用relu了,越用信息损失越大)。
2.preliminaries,dicussion and intuition
3.1 depthwise separable convolutions
在轻量化网络中,深度可分离卷积是跑不了,如下图。
常规卷积:

深度可分离卷积:


上面这个图很直观了,深度可分离卷积参数量之所以少就是因为第一步卷积时是对应相乘再相加,比三个维度直接乘要少很多,但是对应卷积相乘会造成channel维度信息不交互,影响信息传递,后面又接了一个1x1conv.(Xception论文指出,这种卷积背后的假设是跨channel相关性和跨spatial相关性的解耦。应用深度可分离卷积的另一个优势即是参数量的节省(这一点其实也是解耦的结果,参数描述上享受了正交性的乘法增益)
这里有个统计,MobileNetV2 uses k = 3 (3x3 depthwise separable convolutions) so the computational cost is 8 to 9 times smaller than that of standard convolutions at only a small reduction in accuracy.作者说在精度损失很小的境况下,深度可分离卷积比常规卷积要省8到9倍的计算力。
3.2 linear bottleneck
这是本文的核心,作者说神经网络n个Li层组成,每层经过激活的tensor的维度是h*w*d,把这个tensor看成是d维的有h*w个像素的容器,对于一张真实图像,经过一系列的激活之后,形成的这个tensor我们称之为manifold of interest(兴趣流形),其实就是特征提取的信息流,长期以来,一直假设在神经网络中这个流形可以embedded到一个低维子空间中(信息流在channel维度的变化,传统resnet设计中是64,128,256,512,1024,2048,在一个bottleneck中用1x1conv先对通道进进行降维,3x3conv之后,再对通道进行升维),当我们观察单独的d-channel的像素时,这些值中编码的信息实际存在于某个流形中,而流形又可以emedded到低维子空间中(通过1x1conv进行通道维度变换)。
这样的事实可以通过简单的降低层的维度来降低操作空间的维度来捕获和利用,mobilenetv1就是这么做的,通过width multiplier参数在计算和准确性之间进行了有效的权衡,width multiplier可以降低激活空间的维度,直到流形跨过整个空间。上面这些啥意思呢?就是说神经网络提取的信息流(流形)是可以被编码在channel维度中,如果是这样,低channel维度就可以有效的降低空间复杂度,模型更轻量化(在crnn中为了让识别模型更轻量,最有效的手段就是降低channel维度)。
然后深度卷积网络是具有非线性激活层的,以relu为例,如下图

上图的input数一个二维数据,其中蓝色螺旋线是流形,使用矩阵T将数据嵌入到n维空间中,后接relu,再使用T的逆矩阵将其投影回2维空间,当时n=2,3时,信息丢失严重,中心点坍塌了,当n=15,30时,恢复的信息就明显多了,也就是说relu这种非线性激活其实让上面的流形传递遭到了破坏,在channel维度很小时,流形并不是可以被完成的embedded到子空间中的,因此深度网络尽在输出域是非零体积的部分具有线性分类器的能力,当relu崩溃掉,它不可避免的损失通道中的信息,因此想让输入对应的输出全是非零的,那么输入和输出之间其实对应的就是一种线性映射关系。用线性映射替换channel数较少层中的relu,relu会对channel较低的tensor造成较大的信息耗损,relu会使负值为0,channel数较低时会有相对较高的概率使某一维度的tensor全为0,这一过程是不可逆的,tensor维度的减少就意味着特征描述容量的下降,也即流形的丢失。因此在需要使用relu的卷积层中,将channel数扩张到足够大,再进行激活,可以降低激活层的信息损失。两条路,一条是将非线性层换成线性层,一条是将channel维度增大,高维输入,流形则可以比较好的embedded到子空间中。
另一观点是dw conv 和relu的组合也会造成对信息的很大损失。Depthwise Conv确实是大大降低了计算量, 而且NxN Depthwise + 1X1 PointWise的结构在性能上也能接近NxN Conv。 在实际使用的时候, 我们发现Depthwise 部分的kernel比较容易训废掉: 训完之后发现depthwise训出来的kernel有不少是空的... 当时我们认为是因为depthwise每个kernel dim 相对于vanilla conv要小得多, 过小的kernel_dim, 加上ReLU的激活影响下, 使得神经元输出很容易变为0, 所以就学废了: ReLU对于0的输出的梯度为0, 所以一旦陷入了0输出, 就没法恢复了。 我们还发现,这个问题在定点化低精度训练的时候会进一步放大。
作者的实验也证明,在bottleneck中插入线性层能够很好防止非线性层对信息的破坏,从而提高性能。
3.3 Inverted residual
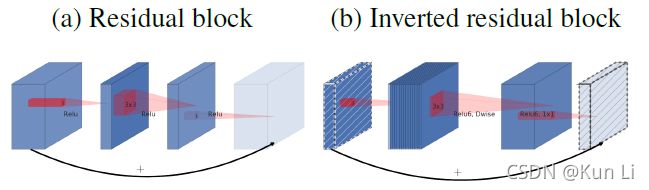



上面这几张图其实已经很明显的描述了Inverted residual结构的特点了,他与residual block的区别在于,resnet中的bottleneck首先会先对输入做1x1conv的降维在3x3conv特征提取,再1x1conv升维,在Inverted residual中,先用1x1conv(expansion layer)做升维,升多少倍是个超参,默认是6,升维之后通过depthwise conv layer做特征提取,这里因为relu对高维的信息破坏少,低维信息破坏严重,升维之后,经过卷积核激活层能够最大的保存流形的传递而不致使部分kernel直接输出0,造成神经元失活,之后再通一个1x1conv(projection layer)降维,输出不再经过relu,低维过relu,损失信息多,因此直接取消了relu。但我们看到inverted residual有两种形式,一种是有shortcut,一种是没有的,使用shortcut是有条件的,必须是输入通道等于输出通道且stride=1时。
观察一下residual block和inverted residual的区别,可以发现residual block是两头窄中间欧昂,而inverted residual则刚好相反,是中间胖二头窄。
4.model architecture
网络的结构设计是人工设计的,感觉也是挺复杂的,这些个参数。

arch_settings = [[1, 16, 1, 1], [6, 24, 2, 2], [6, 32, 3, 2],
[6, 64, 4, 2], [6, 96, 3, 1], [6, 160, 3, 2],
[6, 320, 1, 1]]
# from left to right: expand_ratio, channel, num_blocks, stride.mobilenetv2是很好的文章,有理论支撑有很好的架构设计,在指出深度神经网络提取特征的流形理论上是可以在高维低维子空间中做存储和流通的,relu等非线性层对低维channel的信息传递造成了损失(当然在低维channel下dw提取特征的kernel也是很容易失活的,这里xception中也说了dw后面不加relu效果会好一点),卷积和激活造成的信息破坏,在residual block中设计了先升维再dw再降维,并且去掉relu的结构,从代码角度上讲和resnet差别也不大,但是有这很好的理论支撑。
也有一些工程上的进步,以前大多数的模型结构加速的工作都停留在压缩网络参数量上。 其实这是有误导性的: 参数量少不代表计算量小; 计算量小不代表理论上速度快(带宽限制)。 resnet的结构其实对带宽不大友好: 恒等映射支路的计算量很小,add时的特征很大,所以带宽上就比较吃紧。由此看Inverted residual 确实是个非常精妙的设计! resnet中的bottlenet的特点是两头大,中间小,add操作的两头连接的都是channel数目很高的feature-map,所以说带宽比较吃紧。2. inverted redidual后则变成两头小,中大的结构,所以add时两头链接的feature-map的channel数目变小,从而省带宽。其实业界在做优化加速, 确实是把好几个层一起做了, 利用时空局部性,减少访问DDR来加速。 所以 Inverted residual 带宽上确实是比较友好的。
在resnet之后,像res2net引入多尺度,renest引入attention在bottleneck中,其实都是差分块信息的增强,在mobilenet类似的轻量化模型中,主要还是要证明在保证特征提取能力的同时能够减少参数量,减少部署的体积,减少计算力,加速特征提取。
2021.12.8:paperwithcode上imagenet上top1精度:74.7%。