使用 Docker 来运行 HuggingFace 海量模型
本篇文章将分享如何通过 Docker 来在本地快速运行 Hugging Face 上的有趣模型。用比原项目更少的代码,和更短的时间成本将模型跑起来。
如果你熟悉 Python,那么绝大多数的模型项目,都可以用 10 分钟左右的时间,完成本地的部署和运行。
写在前面
为了方便展示,我选择了一个图像处理模型。在聊细节之前,让我们来一起看看这个模型项目的实际运行效果吧。


上面的图片处理所使用的 AI 模型,是我在 Hugging Face 上找到的。随着 Hugging Face 的爆火,平台上出现了越来越多的有趣的模型和数据集,目前仅模型数量就高达 4 万 5 千多个。
这些模型有一个有趣的特点,在云平台上跑的好好的,但是一旦想在本地跑起来就得各种“费劲”折腾,项目关联的 GitHub 中总是能看到用户反馈:这个模型和代码,我本地跑不起来,运行环境和调用代码搞起来太麻烦了。
其实在日常的工作和学习中,我们也会经常遇到类似上面 Hugging Face 的情况:许多模型在“云上”跑的好好的,但是一到本地就跑不起来了,这或许是因为“操作系统环境、设备 CPU 架构(x86/ ARM)差异”、或许是因为“Python 运行时版本过高或过低”、或许是因为“某个 PIP 安装的软件包版本不对”、“冗长的示例代码中写死了一堆东西”…
那么,有没有什么偷懒的方法,可以让我们绕开这些浪费时间的问题呢?
在经过了一番折腾之后,我探索出了一个相对靠谱的方案:用 Docker 容器搭配 Towhee,制作模型的一键运行环境。
譬如本文开头提到的这个模型,假如我们想进行快速调用,针对我们的图片进行一个快速修复处理,真的并不难:只需要一条 docker run 命令,搭配二、三十来行 Python 代码即可。
接下来,我就以腾讯 ARC 实验室开源的 GFPGAN 模型为例,来聊聊如何快速的把网上开放的模型快速的跑起来。
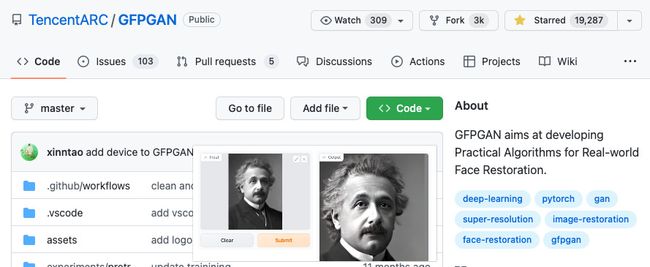
因为该模型基于 PyTorch,所以本篇文章里,我们先聊聊如何制作基于 PyTorch 的模型使用的通用 Docker 基础镜像。如果同学们有需求,我就再聊聊其他模型框架。
制作 PyTorch 模型使用的通用 Docker 基础镜像
本章节的完整示例代码,我已经上传到了 GitHub:https://github.com/soulteary/docker-pytorch-playground,感兴趣的同学可以自取。如果你想进一步省事,还可以直接使用我已经构建好的镜像,来作为基础镜像使用:https://hub.docker.com/r/soulteary/docker-pytorch-playground 。
如果你对如何封装基础镜像感兴趣,可以继续阅读本章节,如果你只关心如何快速跑模型,可以直接阅读下一章节内容。
言归正传,出于下面三个原因,我建议想在本地快速复现模型的同学采用容器方案 :
- 想要避免不同项目之间的环境造成干扰(污染)
- 想要确保项目依赖清晰,任何人都能够在任何设备上复现结果
- 想要复现模型的时间成本更低一些,不喜欢折腾 80% 重复的模型调优之外的工作内容(尤其是环境、基础配置)
在了解到容器方案的优势之后。接下来,我们来聊聊如何编写这类基础镜像的 Dockerfile ,以及编写过程中的思考:
考虑到模型可能需要在 x86 和 ARM 两类设备上运行,推荐使用 miniconda3 这个基于 debian 内置了 conda 工具包的基础镜像。
FROM continuumio/miniconda3:4.11.0
关于基础环境镜像的使用,我推荐大家使用具体版本号,而不是 latest,这样可以让你的容器在需要重复构建的时候,也能保持“稳定”,减少“意外的惊喜”。如果你有特殊的版本需求,可以在这里找到更适合你的镜像版本。关于 conda 和 mini conda 相关的内容,本篇文章暂不赘述,感兴趣的同学可以从官方仓库中获得更多的信息。如果有需求的话,我会写一篇更详细的文章来聊聊它。
因为我们会频繁使用 OpenGL 的 API,所以我们需要在基础镜像中安装 libgl1-mesa-glx 软件包,如果你想了解这个软件包的详情,可以阅读 debian 官方软件仓库的文档,为了让安装时间更少,这里我调整了软件源为国内的“清华源”。
RUN sed -i -e "s/deb.debian.org/mirrors.tuna.tsinghua.edu.cn/" /etc/apt/sources.list && \
sed -i -e "s/security.debian.org/mirrors.tuna.tsinghua.edu.cn/" /etc/apt/sources.list && \
apt update
RUN apt install -y libgl1-mesa-glx
当我们完成了基础系统依赖库的安装之后,就可以开始准备模型运行环境了,以 PyTorch 安装为例:
RUN pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
RUN conda install -y pytorch
同样为了节约 Python PyPi 软件包的下载时间,我同样将下载源切换到了国内的“清华源”。当 conda install -y pytorch 命令执行完毕之后,我们的基础的运行环境也就 OK 了。
考虑到大家的网络环境不相同,这里列出一些国内其他的常用镜像源。你可以根据你自己的情况,调整软件包下载源,来获取更快的软件包下载速度。
# 清华源
https://pypi.tuna.tsinghua.edu.cn/simple
# 阿里云
http://mirrors.aliyun.com/pypi/simple
# 百度
https://mirror.baidu.com/pypi/simple
# 中科大
https://pypi.mirrors.ustc.edu.cn/simple
# 豆瓣
http://pypi.douban.com/simple
在上面的步骤中,我们大概需要下载接近 200MB 的软件包(conda 14MB、pytorch 44MB、mkl 140MB),需要有一些耐心。
为了让我们的基础镜像环境能够兼容 x86 和 ARM,在完成上面的基础环境安装之外,我们还需要指定 torch 和 torchvision 版本,关于这点在PyTorch 社区里曾有过 一些讨论。
RUN pip3 install --upgrade torch==1.9.0 torchvision==0.10.0
在上面的命令中,我们会将 torch 替换为指定版本。实际构建镜像的过程中,大概需要额外下载 800MB 的数据。即使我们使用了国内的软件源,时间可能也会比较漫长,可以考虑去冰箱里拿一罐冰可乐,缓解等待焦虑。
在处理完上面的各种依赖之后,我们就来到了构建镜像的最后一步。为了后续运行各种 PyTorch 模型能够更省事,推荐直接在基础镜像中安装 Towhee:
# https://docs.towhee.io/Getting%20Started/quick-start/
RUN pip install towhee
至此,一个基于 PyTorch 的模型使用的通用 Docker 基础镜像的 Dockerfile 就编写完毕啦,为了方便阅读,我在这里贴出完整文件内容:
FROM continuumio/miniconda3:4.11.0
RUN sed -i -e "s/deb.debian.org/mirrors.tuna.tsinghua.edu.cn/" /etc/apt/sources.list && \
sed -i -e "s/security.debian.org/mirrors.tuna.tsinghua.edu.cn/" /etc/apt/sources.list && \
apt update
RUN apt install -y libgl1-mesa-glx
RUN pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
RUN conda install -y pytorch
RUN pip3 install --upgrade torch==1.9.0 torchvision==0.10.0
RUN pip install towhee
将上面的内容保存为 Dockerfile 后,执行 docker build -t soulteary/docker-pytorch-playground .,等到命令执行完毕,我们的 PyTorch 基础镜像就构建完成了。
如果你不想浪费时间构建,也可以直接使用我已经构建好的基础镜像(支持自动区分 x86 / ARM 架构设备),直接从 DockerHub 下载即可:
# 可以直接下载最新版本
docker pull soulteary/docker-pytorch-playground
# 也可以使用带有具体版本的镜像
docker pull soulteary/docker-pytorch-playground:2022.05.19
搞定基础镜像之后,我们就可以继续折腾前文提到的具体模型的运行环境和程序啦。
使用 Python 编写模型调用程序
我们在 GFPGAN 项目中可以找到官方的模型使用示例:https://github.com/TencentARC/GFPGAN/blob/master/inference_gfpgan.py,原始文件比较长,大概有 155 行,这里我就不贴了。
我在上一小节中提到过,我们可以使用 Towhee 来“偷懒”,比如可以将示例代码的行数缩短到 30 来行,并且额外实现一个小功能:扫描工作目录的所有图片,然后将他们分别交给模型去处理,最后生成一个静态页面,来将处理前后的图片进行对比展示。
import warnings
warnings.warn('The unoptimized RealESRGAN is very slow on CPU. We do not use it. '
'If you really want to use it, please modify the corresponding codes.')
from gfpgan import GFPGANer
import towhee
@towhee.register
class GFPGANerOp:
def __init__(self,
model_path='/GFPGAN.pth',
upscale=2,
arch='clean',
channel_multiplier=2,
bg_upsampler=None) -> None:
self._restorer = GFPGANer(model_path, upscale, arch, channel_multiplier, bg_upsampler)
def __call__(self, img):
cropped_faces, restored_faces, restored_img = self._restorer.enhance(
img, has_aligned=False, only_center_face=False, paste_back=True)
return restored_faces[0][:, :, ::-1]
(
towhee.glob['path']('*.jpg')
.image_load['path', 'img']()
.GFPGANerOp['img','face']()
.show(formatter=dict(img='image', face='image'))
)
如果将上面为了保持“原汁原味”的 warnings 剔除掉,其实还可以获得更短的行数。将上面的内容保存为 app.py,我们稍后使用。
搞定了调用模型所需要的程序之后,我们继续来聊聊,如何制作具体模型(GFPGAN)运行所需要的应用容器镜像。
制作具体模型使用的应用镜像
这部分的完整代码,我同样上传到了 GitHub,方便大家“偷懒”:https://github.com/soulteary/docker-gfpgan。配套的预构建镜像在这里 https://hub.docker.com/r/soulteary/docker-gfpgan 。
言归正传,有了上文中的基础镜像之后,我们在日常玩耍的过程中,就只需要针对每个不同的模型做一些镜像依赖微调即可。
下面就来看看如何针对上文中提到的 GFPGAN 项目做应用镜像定制吧。
同样是以编写 Dockerfile 为例,先来声明我们正在构建的应用镜像是基于上面的基础镜像。
FROM soulteary/docker-pytorch-playground:2022.05.19
这样做的好处是,在后续的日常使用中,我们可以节约大量的镜像构建时间,以及本地磁盘空间。不得不说,模型类大容器特别能够享受 Docker 特性带来的便利。
接下来,我们需要在要制作的应用镜像中放置我们要使用的模型文件,以及完成相关 Python 依赖的补充下载。
考虑到国内网络下载 Hugging Face 和 GitHub 模型比较慢,还容易出现网络中断。我推荐大家在做应用模型构建的时候,可以考虑提前进行依赖模型的下载,在构建镜像的过程中,将模型放置到合适的目录位置即可。至于具体的模型使用方式,不论是打包到镜像里,或者选择在使用的过程中动态的挂载,其实都是可以的。
在 GFPGAN 项目中,我们一共依赖俩模型文件,一个是 https://github.com/xinntao/facexlib 项目中基于 ResNet50 的人脸检测模型,另一个是用于图片修复的 GFPGAN 对抗网络模型,也就是传统意义上的“主角”。
第一个模型文件 detection_Resnet50_Final.pth ,我们可以在 https://github.com/xinntao/facexlib/releases/tag/v0.1.0 中获取;第二个模型则需要我们根据自己的设备状况,来做具体选择:
- 如果你需要使用 CPU 来跑模型,可以在 https://github.com/TencentARC/GFPGAN/releases/tag/v0.2.0 中下载
GFPGANCleanv1-NoCE-C2.pth;或者在https://github.com/TencentARC/GFPGAN/releases/tag/v1.3.0中下载GFPGANv1.3.pth,这类模型可以完成黑白人像图片的处理。 - 如果你可以使用 GPU 来跑模型,可以在 https://github.com/TencentARC/GFPGAN/releases/tag/v0.1.0 中下载
GFPGANv1.pth;或者在 https://share.weiyun.com/ShYoCCoc 中进行模型文件下载,这类模型可以处理带颜色的人像图片。 - 除了 GitHub 之外,我们也可以选择直接从 Hugging Face 下载模型(只是可选版本不像上面那么多):https://huggingface.co/TencentARC/GFPGANv1/tree/main/experiments/pretrained_models。
将下载好的模型文件和新的 Dockerfile 文件放置于相同目录之后,我们来继续完善 Dockerfile 的内容,完成项目依赖的安装,并将模型放置在容器内合适的目录位置:
# 安装模型相关代码库
RUN pip install gfpgan realesrgan
# 将提前下载好的模型复制到指定位置,避免构建镜像过程中的意外
COPY detection_Resnet50_Final.pth /opt/conda/lib/python3.9/site-packages/facexlib/weights/detection_Resnet50_Final.pth
# 根据你下载的模型版本做选择,选一个模型文件就行
COPY GFPGANCleanv1-NoCE-C2.pth /GFPGAN.pth
# COPY GFPGANCleanv1-NoCE-C2_original.pth /GFPGAN.pth
# COPY GFPGANv1.pth /GFPGAN.pth
# COPY GFPGANv1.3.pth /GFPGAN.pth
上面除了 gfpgan 之外,我还安装了 realesrgan,这个软件包可以让处理完毕的图片中的人脸之外的背景也显得更好看、更自然一些。
完成了基础依赖、模型的配置之后,最后就是一些简单的收尾工作了:
# 将上一步保存的调用模型的程序拷贝到镜像中
COPY app.py /entrypoint.py
# 声明一个干净的工作目录
WORKDIR /data
# 这里可以考虑直接将我们要测试的数据集扔到容器里
# 也可以考虑在运行过程中动态的挂载进去
# COPY imgs/*.jpg ./
# 补充安装一些项目需要的其他依赖
RUN pip install IPython pandas
# 因为 Towhee 目前只支持直接展示模型结果
# 暂时还不支持将展示结果保存为文件
# 所以这里需要打个小补丁,让它支持这个功能
RUN sed -i -e "s/display(HTML(table))/with open('result.html', 'w') as file:\n file.write(HTML(table).data)/" /opt/conda/lib/python3.9/site-packages/towhee/functional/mixins/display.py
CMD ["python3", "/entrypoint.py"]
上面的代码中,我添加了不少注释来解释每一步要做什么,就不多赘述啦。额外解释一下这里的设计和思考,把上文中的 app.py 挪到 / 根目录,而不是扔到工作目录可以让我们的程序在使用过程中更简单,因为我计划将工作目录作为图片的读取和处理结果的保存目录。容器最后使用 CMD 而不是 ENTRYPOINT 来执行默认命令,也更方便用户直接调用命令,或者进入容器调试。
同样的,为了方便阅读,我将上面的 Dockerfile 内容合并到一起:
FROM soulteary/docker-pytorch-playground:2022.05.19
RUN pip install gfpgan realesrgan
COPY detection_Resnet50_Final.pth /opt/conda/lib/python3.9/site-packages/facexlib/weights/detection_Resnet50_Final.pth
# 尺寸大一些的模型文件,可以选择使用挂载的方式
# 而不在此处直接 COPY 到容器内部
COPY GFPGANCleanv1-NoCE-C2.pth /GFPGAN.pth
COPY app.py /entrypoint.py
WORKDIR /data
RUN pip install IPython pandas
RUN sed -i -e "s/display(HTML(table))/with open('result.html', 'w') as file:\n file.write(HTML(table).data)/" /opt/conda/lib/python3.9/site-packages/towhee/functional/mixins/display.py
CMD ["python3", "/entrypoint.py"]
将上面的内容保存为 Dockerfile 之后,我们执行命令,来完成应用镜像的构建:
docker build -t pytorch-playground-gfpgan -f Dockerfile .
片刻之后,我们就得到一个包含了模型和模型运行程序的应用镜像啦。
接下来,我们来看看如何使用这个镜像,来得到文章一开始时的模型运行结果。
模型应用镜像的使用
如果上一步你已经下载了模型文件,并将模型文件打包到了镜像中,那么我们只需要下载一些黑白或者彩色的包含人像的图片(根据模型来选择),将它们放在一个目录中(比如 data目录),然后执行一行命令就能够完成模型的调用啦:
docker run --rm -it -v `pwd`/data:/data soulteary/docker-gfpgan
如果你不愿意费事找图片,也可以直接使用我在项目中准备的示例图片:https://github.com/soulteary/docker-gfpgan/tree/main/data。
上面是针对应用镜像中包含模型的情况,下面我们来看看如果应用镜像中不包含模型要怎么处理。
如果在上文构建应用模型镜像时,没有选择将 GFPGAN 模型打包到镜像中,那么我们就需要使用文件挂载的方式,来运行模型了。为了项目结构的清晰,我在项目中创建了一个名为 model 的目录,来存放上文中提到的模型文件。
完整的目录结构类似下面这样:
.
├── data
│ ├── Audrey\ Hepburn.jpg
│ ├── Bruce\ Lee.jpg
│ ├── Edison.jpg
│ ├── Einstein.jpg
│ └── Lu\ Xun.jpg
└── model
└── GFPGANCleanv1-NoCE-C2.pth
当准备好模型和要处理的图片之后,我们还是执行一条简单的命令,来将文件挂载到容器中,让模型发挥“魔力”:
docker run --rm -it -v `pwd`/model/GFPGANCleanv1-NoCE-C2.pth:/GFPGAN.pth -v `pwd`/data:/data soulteary/docker-gfpgan
当命令执行完毕之后,在 data 目录中,会多出一个 result.html 文件,里面记录了模型处理前后的图片结果。使用浏览器直接打开,可以看到类似下面的结果:

写到这里,如何封装 PyTorch 容器基础镜像、如何封装具体模型的应用镜像、如何快速的调用模型就都介绍完啦。如果后面有机会,我会聊聊如何基于这些镜像做进一步的性能调优,以及聊聊 PyTorch 之外的镜像封装。
最后
本篇内容的完成,需要感谢两位好朋友、Towhee 项目的核心开发者 @侯杰 、@郭人通 的帮助。解决了对于我这个 Python 菜鸟来说,虽然行数不多,但是非常麻烦的模型调用的内容。
下一篇相关的内容中,我计划聊聊如何在 M1 设备上进行模型训练和推理,以及继续实践一些更有趣的 AI 项目。
–EOF
本文使用「署名 4.0 国际 (CC BY 4.0)」许可协议,欢迎转载、或重新修改使用,但需要注明来源。 署名 4.0 国际 (CC BY 4.0)
本文作者: 苏洋
创建时间: 2022年05月20日
统计字数: 10723字
阅读时间: 22分钟阅读
本文链接: https://soulteary.com/2022/05/20/use-docker-to-run-huggingface-models.html