文献翻译2:AOPG: Anchor-free Oriented Proposal Generator for Object Detection
文献翻译2:AOPG: Anchor-free Oriented Proposal Generator for Object Detection
- AOPG: Anchor-free Oriented Proposal Generator for Object Detection
-
- Abstract
- Introduction
- RELATED WORK
-
- Horizontal Scheme in Oriented Detectors
- Anchor Scheme in Object Detection
- Proposed Method
-
- Horizontal Box-based Scheme vs Oriented Box-based Scheme
- Coarse Location Module
-
- Oriented Box Definition
- Region Assignment
- Training
- Oriented Box Refinement
-
- Feature Alignment by AlignConv
- High-quality Proposals
- Oriented Object Detection
- Experiments
-
- Datasets and training details
- Training Details
- Comparison with State-of-the-Art Methods
- Evaluation of CLM
- Conclusion
AOPG: Anchor-free Oriented Proposal Generator for Object Detection
Gong Cheng, Jiabao Wang, Ke Li, Xingxing Xie, Chunbo Lang, Yanqing Yao, Junwei Han
日期:2021-10-05
paper: http://arxiv.org/abs/2110.01931
code: https://github.com/jbwang1997/AOPG
Abstract
Oriented Object Detection是遥感图像判读中具有实用价值和挑战性的任务。HBB往往与ground-truth的IoU很小,导致引入噪声等问题。
本文提出了anchor-free的AOPG(Anchor-free Oriented Proposal Generator)。AOPG摒弃了与HBB有关的操作。AOPG首先通过anchor-free的Coarse Location Module (CLM) 生成粗糙的oriented boxes,然后细化它们以生成高质量的oriented proposal。在AOPG之后采用了Faster RCNN head来获取检测结果。为解决大规模数据集缺乏的问题,作者发布了基于DIOR的DIOR-r。
DIOR-r: 64.41% mAP
DOTA: 75.24% mAP
HRSC2016: 96.22 mAP
Introduction
除了分类和定位,还需要生成任意方向的bounding box。目前的算法基本上都是沿袭了Faster RCNN,在两个阶段中都用了HBB。
尽管基于HBB的算法也取得了一些成功,但是其缺点仍然很明显:
- HBB包含大量背景,有时甚至包含多个目标,因为它们往往密集的排列在一起。这就导致pooling操作会将不相关特征引入到目标的特征中,降低其与ground truth的匹配程度。
- OBB和HBB之间的IoU往往很小,不能明确反应两者之间的匹配程度。
- OBB和HBB在回归目标上相差很大。由于HBB的回归目标往往很大,使得模型的鲁棒性受损。

如上图所示,
- 一个HBB中包含了几个目标,使得检测器很难定位和分类目标。
- 即便该HBB被认为是正样本,其IoU仅有0.16。而OBB的IoU达到了0.87。
- HBB的回归目标达到了2.06,而OBB仅有0.14.
解决这些问题的最直观方法就是生成旋转proposal。
-
Rotated RPN直接在原有anchor的基础上铺设带有方向的anchor。但是为了提高召回率,Rotated RPN铺设了过多的anchor ( 3 × 3 × 6 ) (3\times{3}\times{6}) (3×3×6),导致计算量骤升以及负样本过多。
-
RoI Transformer从HBB中预测OBB,降低了计算量。其中的RRoI learner可以容易地添加到所有two-stage的检测器中,大大提高其性能。但是其仍然采用了包含HBB的pipeline,仍受到HBB的限制。此外,官方最新的RoI Transformer取消了轻量化设计,为提高精度而降低了效率。
本文提出了AOPG(Anchor-free Oriented Proposal Generator),旨在生成完全不需要HBB参与的高质量oriented proposal。AOPG的主要结构如下所示。

AOPG在每一个位置用anchor-free的方案生成一个粗略的定向盒(Coarse Oriented Box)。然后采用一种新的叫做AlignConv的技术将特征和粗盒对齐。对其之后,将粗盒细化为精确的位置,生成高质量的oriented proposal。在第二个stage,采用Faster RCNN head来预测分类和回归。
此外,作者发现大规模数据集的缺乏严重阻碍了Oriented Object Detection的发展,因此在他们的DIOR数据集的基础上提出了DIOR-R数据集。其中包括多达23463幅遥感图像和192512个实例,涵盖了20个常见类。由于提出了高质量的方案,OPG在DIOR-R、DOTA和HRSC2016数据集上获得了64.41%、75.24%和96.22%的mAP,在所有数据集上精度最高。
本文的贡献总结为以下几点:
- 分析了HBB在Oriented Object Detection中的不足,并这对这些问题提出了一一个anchor-free的proposal生成器AOPG,以生成oriented proposal且不涉及HBB。
- 发布了DIOR-R。
- 进行了大量实验证明了AOPG的sota。
RELATED WORK
目标检测根据其结构主要可分为两种类型。由Faster RCNN衍生而来的two-stage算法首先用轻量化的全卷积网络生成RoI,然后提取RoI的特征来进行精确的分类和细化。尽管two-stage算法在很多benchm上都有领先性能,但是其计算量巨大、结构复杂。而one-stage算法希望直接通过一个全卷积网络来完成检测,效率更高且更容易实现。One-stage检测器因为不像Faster RCNN进行样本随机抽样,往往会由负样本过多、正负样本不平衡的问题。而Focal Loss动态地为难例分配大权重,使得one-stage可以与two-stage一战。
Horizontal Scheme in Oriented Detectors
SCRDet提出了IoU-Smooth L1 Loss来缓解角度周期性的影响。R3Det通过在特征中编码中心和角点来获取更精确的位置。Gliding Vertex预测四边形而不是oriented boxes。但是上述的几种算法都使用HBB作为参考,因此也受HBB缺点的限制。
还有一些工作直接将oriented anchor应用在图像上,避免了HBB。但是这种方法不仅效率低,而且面临着严重的正负样本不平衡问题,降低了性能。RoI Transformer训练RRoI learner module,从HBB中提取OBB。虽然其性能较高、anhor数量可以接受,但是仍残留HBB的相关操作。
Anchor Scheme in Object Detection
Anchor目前已经成为了目标检测器的基础部件。但是anchor需要较多的超参数、针对不同数据集专门设计。而且即使精心设计各种参数,很多极端情况下anchor不起效。
Guided Anchoring从图像特征中提取锚点,然后在自适应锚点的引导下细化图像特征。Cascade RPN发展自Guided Anchoring,运行级联结构,逐步适应锚点。FCOS和FoveaBox直接从点中回归boxes,预测点到目标上下左右四个边界的距离,完全不需要anchor。与上述不同,CenterNet和CornerNet将目标检测视为点的检测,CornerNet检测左上和右下一对点,CenterNet直接预测目标的中点。Oriented Object Detection中也有很多工作致力于解决anchor的问题。 S 2 A N e t S^2ANet S2ANet基于one-stage的RetinaNet,自适应地生成oriented anchor,并采用深度特征对齐来消除错位问题。DRN在Oriented Detection中也采用了点预测的策略。
AOPG直接从点中生成oriented boxes而不是在输入中滑动anchor。AOPG完全摒弃了HBB,因此不受其带来的缺陷限制。
Proposed Method
首先通过在两个比较Faster RCNN和AOPG的proposal来研究在oriented detection中使用hbb的弊端。
然后介绍了AOPG的细节。AOPG使用了FPN作为backbone,在FPN的每一层特征上由一个粗定位模块(Coarse Location Module, CLM)来从特征点中生成oriented boxes。CLM提取了粗box之后,用AlignConv来消除特征和oriented box之间的不对齐,然后用小型全卷积层来细化粗box。更为准确的分数由CLM的分数和全卷积网络的细化分数平均而来。
Horizontal Box-based Scheme vs Oriented Box-based Scheme
从IoU分布和回归目标分布两个方面来比较HBB和OBB。作者在DOTA的HBB和OBB上分别训练了Faster RCNN和AOPG。首先从两个检测器中随机选择5000个正样本并计算其与ground truth的IoU,如下图所示。
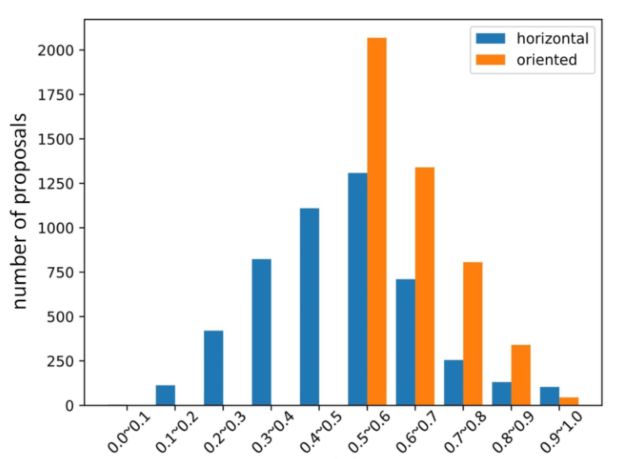
HBB的IoU普遍较小,而OBB比较大。这证明HBB不能精确地配对proposal和ground truth。此外,较小的IoU意味着包含了大量的背景和无关对象。这明显降低了分类和回归的准确性。
此外作者计算了两个检测器的回归目标并给出了分布情况。如图所示,horizontal proposal的回归目标并不是以原点为中心对称的,并且有很多样本的回归目标很极端,这些问题将会增加检测器的训练难度。而oriented proposal无此问题。

基于上述对比,作者认为在检测器中引入horizontal box将会影响检测器的最终精度。因此作者认为要在检测器中摒弃horizontal元素。以此为动机,作者提出了AOPG,一种新的生成oriented proposal的架构。
Coarse Location Module
Oriented Box Definition
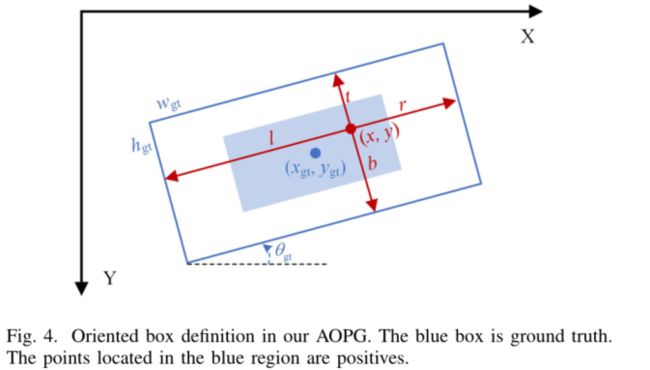
如图所示,本文定义一个oriented ground-truth为 ( x g t , y g t , w g t , w g t , θ g t ) (x_{gt},y_{gt},w_{gt},w_{gt},\theta_{gt}) (xgt,ygt,wgt,wgt,θgt),其中 ( x g t , y g t ) (x_{gt},y_{gt}) (xgt,ygt)表示中心坐标, w g t w_{gt} wgt和 h g t h_{gt} hgt指的是宽和高, θ g t \theta_{gt} θgt指的是其中一条边与x轴正方向的夹角(顺时针方向为正),满足 θ g t ∈ ( − π / 4 , π / 4 ) \theta_{gt}\in(-\pi/4,\pi/4) θgt∈(−π/4,π/4)。给定一个正样本 ( x , y ) ∈ A r e a b l u e (x,y)\in{Area_{blue}} (x,y)∈Areablue,ground-truth距离向量 t g t = ( l , t , r , b ) t_{gt}=(l,t,r,b) tgt=(l,t,r,b)。
Region Assignment
Anchor-based类算法使用anchor和ground-truth之间的IoU来匹配正负样本。CLM没有anchor,因此作者提出了一种region assignment scheme来替代传统IoU assignment。训练过程中,每一个ground-truth box首先根据其尺寸被分配到FPN的某层特征上。接下来将featurn map映射到图像中并将坐落在ground-truth中心区域的顶点选作正样本,其他为负样本。
具体来说,采用FPN的 { P 2 , P 3 , P 4 , P 5 , P 6 } \{P_2,P_3,P_4,P_5,P_6\} {P2,P3,P4,P5,P6},其步长 { s 2 , s 3 , s 4 , s 5 , s 6 } = { 4 , 8 , 16 , 32 , 64 } \{s_2,s_3,s_4,s_5,s_6\}=\{4,8,16,32,64\} {s2,s3,s4,s5,s6}={4,8,16,32,64},ground-truth的尺寸 s i z e ∈ [ α 2 s i 2 / 2 , 2 α 2 s i 2 ] size\in{[\alpha^2s_i^2/2,2\alpha^2s_i^2]} size∈[α2si2/2,2α2si2]的被匹配到特征层 P i P_i Pi,其中 α \alpha α是尺寸范围的放大因子。此外,将 P 2 P_2 P2的最小尺寸设为0 P 6 P_6 P6的最大尺寸设为100000以覆盖所有尺寸。
将ground-truth匹配到对应特征层上之后,将坐落在中心区域的点标记为正样本。Ground truth的中心区域可以表示为 B σ = ( x g t , y g t , σ w g t , σ h g t , θ g t ) B_{\sigma}=(x_{gt},y_{gt},\sigma{w_{gt}},\sigma_{h_{gt}},\theta_{gt}) Bσ=(xgt,ygt,σwgt,σhgt,θgt),其中 σ \sigma σ为中心率。为判断点 ( x p t , y p t ) (x_{pt},y_{pt}) (xpt,ypt)是否坐落在中心区域内,需要将点的图像坐标系转换为ground truth坐标系:
( x ′ y ′ ) = ( cos θ g t − sin θ g t sin θ g t cos θ g t ) ( x − x g t y − y g t ) \begin{pmatrix} x' \\ y' \end{pmatrix}= \begin{pmatrix} \cos{\theta_{gt}} && -\sin{\theta_{gt}} \\ \sin{\theta_{gt}} && \cos{\theta_{gt}} \end{pmatrix} \begin{pmatrix} x-x_{gt} \\ y-y_{gt} \end{pmatrix} (x′y′)=(cosθgtsinθgt−sinθgtcosθgt)(x−xgty−ygt)
若变换后的点满足:
KaTeX parse error: No such environment: align at position 8: \begin{̲a̲l̲i̲g̲n̲}̲ |x'|<\sigma{w_…
则该点在ground truth的中心区域中,认为该点为正样本。
Training

如图所示,CLM有三个分支,分别用于生成每个位置的coarse boxes的score、distance和angle,分别表示为 c c c、 t t t和 θ \theta θ。
score分支是分类分支,目的是判断该点是否位于ground truth的中心区域。用上文的正负样本分配的结果来训练该分支。
distance分支预测特征图上每个点到左、上、右和下四个方向的距离。该分支只在正样本上训练。由于图像坐标系和gt坐标系不对齐,所以也要像上一步一样转换坐标系——**将特征图上的每个点转换到其对应的gt坐标系中。**然后如下图所示,点 ( x , y ) (x,y) (x,y)的gt距离向量 t g t = ( l , t , r , b ) t_{gt}=(l,t,r,b) tgt=(l,t,r,b)可以表示为:
{ l = w g t / 2 + x ′ , r = w g t / 2 − x ′ t = h g t / 2 + y ′ , b = h g t / 2 − y ′ \left\{ \begin{aligned} l=w_{gt}/2+x', && r=w_{gt}/2-x' \\ t=h_{gt}/2+y', && b=h_{gt}/2-y' \end{aligned} \right. {l=wgt/2+x′,t=hgt/2+y′,r=wgt/2−x′b=hgt/2−y′
作者用标准化的距离向量 t g t ∗ = ( l ∗ , t ∗ , r ∗ , b ∗ ) t_{gt}^*=(l^*,t^*,r^*,b^*) tgt∗=(l∗,t∗,r∗,b∗)来训练距离分支,其中 t g t ∗ = log t g t ∗ / z t_{gt}^*=\log{t_{gt}^*/z} tgt∗=logtgt∗/z, z z z是定义在不同特征层的标准化因子。
由于本文中角度的定义是对称的,因此作者直接用ground truth来训练角度分支。所以CLM的损失如下:
L C L M = λ N ∑ ( x , y ) L c t r ( c , c g t ∗ ) + 1 N p o s ∑ ( x , y ) c g t ∗ L d i s t ( t , t g t ∗ ) + 1 N p o s ∑ ( x , y ) c g t ∗ L a n g l e ( θ , θ g t ∗ ) L_{CLM}=\frac{\lambda}{N}\sum_{(x,y)}{L_{ctr}(c,c_{gt}^*)}+\frac{1}{N_{pos}}\sum_{(x,y)}{c_{gt}^*L_{dist}(t,t_{gt}^*)}+\frac{1}{N_{pos}}\sum_{(x,y)}{c_{gt}^*L_{angle}(\theta,\theta_{gt}^*)} LCLM=Nλ(x,y)∑Lctr(c,cgt∗)+Npos1(x,y)∑cgt∗Ldist(t,tgt∗)+Npos1(x,y)∑cgt∗Langle(θ,θgt∗)
其中 L c t r L_{ctr} Lctr是focal loss, L d i s t L_{dist} Ldist和 L a n g l e L_{angle} Langle是smooth L1 loss。 N N N表示特征图上的所有点数, N p o s N_{pos} Npos表示特征图上的正样本点数, c g t ∗ c_{gt}^* cgt∗表示经过区域匹配流程(前文的Region Assignment)后的标签(1正样本0负样本)。
Oriented Box Refinement
然后本文设计了一个小弟全卷积网络来确认前景并精确地细化coarse oriented boxes。Anchor在整个特征图上都是一致的,有相同的形状和尺寸。而CLM的coarse oriented boxes在不同位置是不同的,导致与特征图存在不对齐问题。本文提出了一种特征对其技术来对齐coarse oriented boxes和特征,成为AlignConv。对齐之后就生成了用于精确定位和分类的高质量oriented proposal。
Feature Alignment by AlignConv
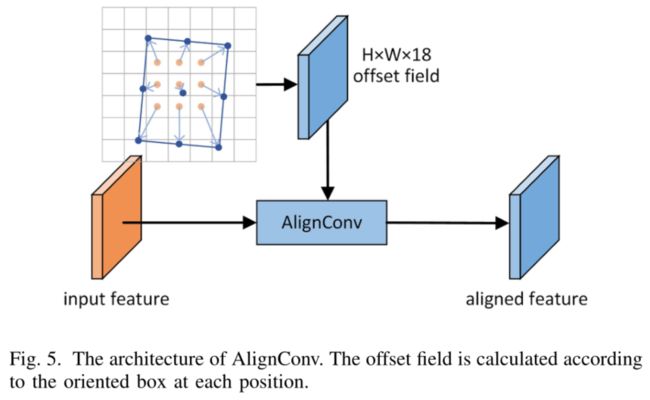
上图展示了AlignConv的结构。AlignConv主要的部分是一层deformable convolution layer,通过offset field来指导特征对齐。与常规的deformable convolution从小的网络中生成offset field不同,AlignConv从oriented boxes中获取offset field。对于一个位置向量 p ∈ { 0 , 1 , 2 , . . . , H − 1 } × { 0 , 1 , 2 , . . . , W − 1 } p\in\{0,1,2,...,H-1\}\times{\{0,1,2,...,W-1\}} p∈{0,1,2,...,H−1}×{0,1,2,...,W−1},标准的 3 × 3 3\times3 3×3可变形卷积可以表示为:
Y ( p ) = ∑ r ∈ R W ( r ) ⋅ X ( p + r + o ) Y(p)=\sum_{r\in{R}}{W(r)\cdot{X(p+r+o)}} Y(p)=r∈R∑W(r)⋅X(p+r+o)
其中p指该位置,r指卷积核的网格向量, R 3 × 3 = { ( − 1 , − 1 ) , ( − 1 , 0 ) , . . . , ( 1 , 1 ) } R_{3\times3}=\{(-1,-1),(-1,0),...,(1,1)\} R3×3={(−1,−1),(−1,0),...,(1,1)},o表示可变形卷积的位置偏移量。在AlignConv中,作者约束采样点服从coarse oriented box B = ( x , y , w , h , θ ) B=(x,y,w,h,\theta) B=(x,y,w,h,θ)的规则分布(可能就是长得一样的意思)。
采样公式由下式推导:
r b o x = 1 s i ( ( x , y ) − p + ( w 2 , h 2 ) ⋅ r ) R T ( θ ) r_{box}=\frac{1}{s_i}((x,y)-p+(\frac{w}{2},\frac{h}{2})\cdot{r})R^T(\theta) rbox=si1((x,y)−p+(2w,2h)⋅r)RT(θ)
其中 R ( θ ) R(\theta) R(θ)是旋转矩阵, s i s_i si是特征图 P i P_i Pi步长。offset量O可以由下式得到:
O = ∑ r ∈ R ( r b o x − p − r ) O=\sum_{r\in{R}}{(r_{box}-p-r)} O=r∈R∑(rbox−p−r)
High-quality Proposals
特征对齐之后,用两个 1 × 1 1\times{1} 1×1的卷积分别生成分类特征图和回归特征图,分别进行前景识别和oriented box细化。coarse box化时,首先计算其与ground truth的IoU以确定其标签(粗框指的是CLM的输出)。IoU大于0.7认为是正样本,小于0.3认为是负样本,其他的忽略。根据正样本和负样本的定义,将粗框细化为精确位置,以生成高质量的oriented proposal。
Oriented Object Detection

如图所示,two-stage采用一个修改过的Fast RCNN head来预测分类分数并回归最终的oriented bounding box。与常规的Fast RCNN不同,本文在回归分支增加了一个角度偏移参数。
Experiments
Datasets and training details
除了常规的DOTA和HRSC2016之外,作者发布了DIOR-R。

Training Details
若非特殊声明,本文采用ResNet-50-FPN作为backbone,很多超参数都是与Fast RCNN相同的。在Region Assignment中 α = 8 , σ = 0.2 \alpha=8,\sigma=0.2 α=8,σ=0.2。规则化参数 z = { 16 , 32 , 64 , 128 , 256 } z=\{16,32,64,128,256\} z={16,32,64,128,256},分别对应 { P 2 , P 3 , P 4 , P 5 , P 6 } \{P_2,P_3,P_4,P_5,P_6\} {P2,P3,P4,P5,P6}。Proposal生成时的NMS阈值为0.8。所有实验都是在一张RTX 2080Ti上进行的,batch size为2。训练时加载了在ImageNet上预训练过的模型。用SGD来优化模型,初始学习率0.005,动量0.9,weight decay 0.0001。为避免过拟合,采用了随机水平和初始反转。
由于DOTA数据集图像尺寸过大,在singlescale实验中将其以824的步长才建成 1024 × 1024 1024\times{1024} 1024×1024的patch,在multiscale中,首先缩放为 { 0.5 , 1.0 , 2.0 } \{0.5,1.0,2.0\} {0.5,1.0,2.0},然后以200为步长才建成 1024 × 1024 1024\times{1024} 1024×1024的patch。共训练了12个epoch,在8和11的时候衰减为1/10。
DOIR-R中保持 800 × 800 800\times{800} 800×800不变,其他与DOTA一样。
HRSC2016中,缩放到 ( 800 , 1333 ) (800,1333) (800,1333)并保持长宽比。共训练36epoch。在24和33时衰减为1/10。
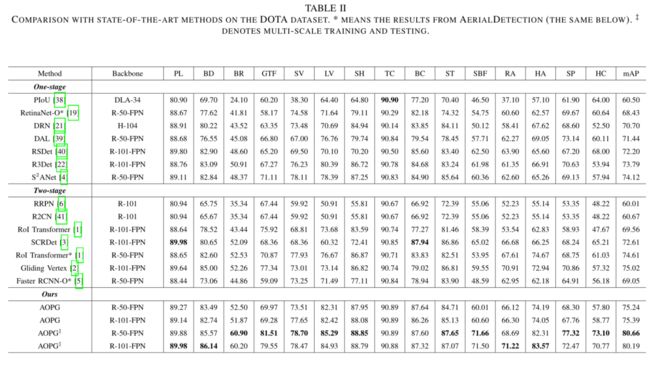
Comparison with State-of-the-Art Methods


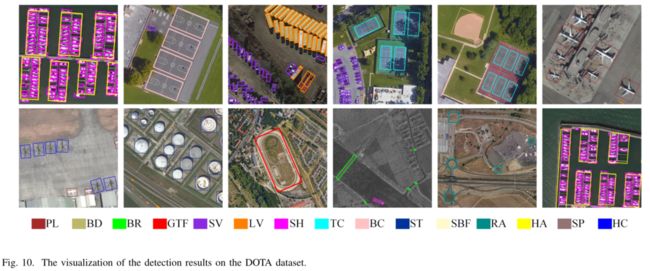


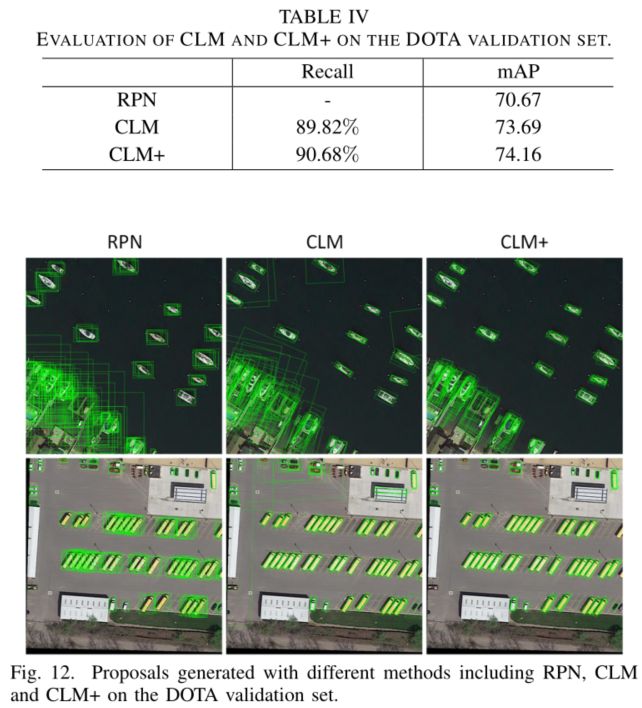
Evaluation of CLM
Conclusion
在本文中,我们分析了使用水平框进行面向对象检测的缺点,并得出结论:将HBB纳入检测器将损害最终结果。以这个问题为出发点,我们提出了一种新的无锚定向建议生成器AOPG,它可以完全摒弃HBB。此外,我们还发布了一个新的大规模面向对象检测数据集DIOR-R,以缓解数据不足的问题。综合实验表明,我们的AOPG有助于提高检测精度。具体而言,我们的AOPG在没有任何花里胡哨的况下实现了最高的精度,并在DIOR-R、DOTA和HRSC2016数据集上获得了比baseline更好的性能。