yolov5训练自己的数据集
1.YOLOv5项目下载
1.YOLOv5为开源代码,直接从github上下载,首先打开github官网,下载。

下载使用pycharm打开,有图中这些文件,
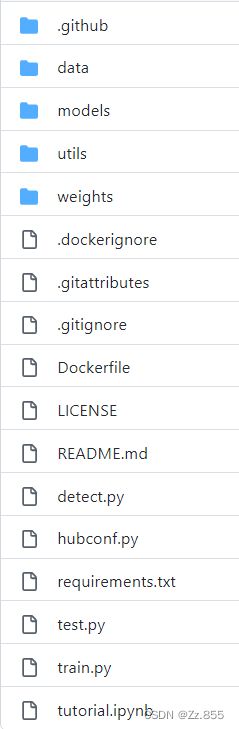
其中
data:主要是存放一些超参数的配置文件(这些文件(yaml文件)是用来配置训练集和测试集还有验证集的路径的,其中还包括目标检测的种类数和种类的名称);如果是训练自己的数据集的话,那么就需要修改其中的yaml文件。
models:主要是一些网络构建的配置文件和函数,如果训练自己的数据集的话,就需要修改这里面相对应的yaml文件来训练自己模型。
utils:存放的是工具类的函数,里面有loss函数,metrics函数,plots函数等等。
weights:放置训练好的权重参数。
detect.py:利用训练好的权重参数进行目标检测,可以进行图像、视频和摄像头的检测。
train.py:训练自己的数据集的函数。
test.py:测试训练的结果的函数
2.环境配置
1.创建yolov5环境,使用Anaconda创建yolov5环境
conda create -n yolov5 python=3.8 #创建环境
conda activate yolov5 #激活虚拟环境
conda deactivate #关闭环境
conda remove -n yolov5 --all #删除环境
conda config --remove-key channels #恢复默认环境2.创建完环境,激活进入环境
3.然后安装pytorch-gpu环境,在环境中输入如下代码更改为清华源进行下载。
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
conda config --set show_channel_urls yes4.打开pytorch官网,找到早期版本,寻找与自己电脑cuda版本对应的troch版本,防止cuda与troch版本不匹配。
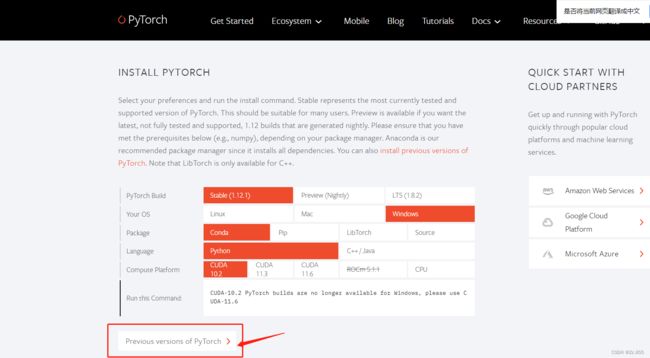
将蓝框中内容复制中yolov5环境中这样就开始将troch版本下载到环境中了。

这里查看自己电脑cuda版本的方法,在Anaconda中输入
nvcc --version
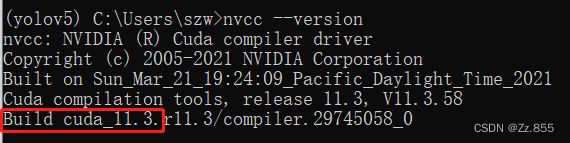 11.3版本。
11.3版本。
这里可以查看cuda与pytorch是否兼容,在pycharm配置刚创建的yolov5环境,输入
import torch
print(torch.__version__)
print(torch.cuda.is_available())结果:1.10.2 true 即为兼容,若为false则不兼容
5.打开pycharm中的requirements.txt还有一些环境要求。
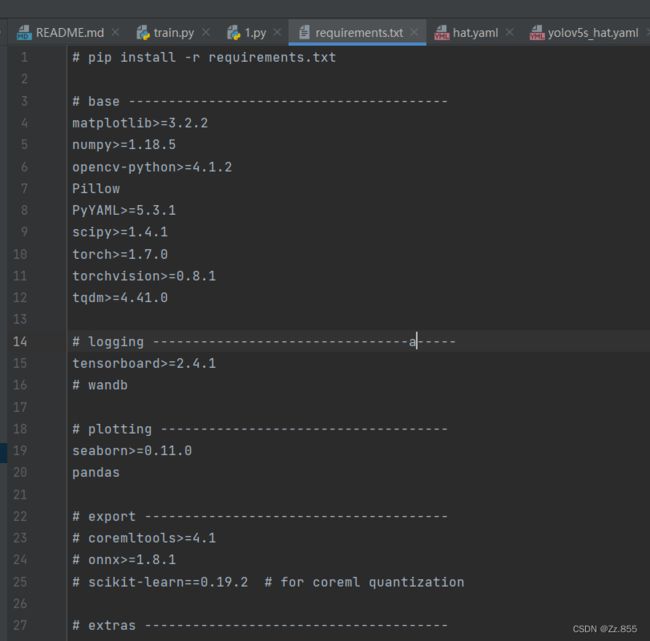
安装方法一:pycharm中安装pyYAML、pycocotools、thop、pandas可能会安装失败,其他环境可直接通过pycharm进行安装。
(1)pyYAML安装:
1)更新pip并安装setuptools。
pip install -U pip setuptools wheel若出现报错:AttributeError: module 'distutils' has no attribute 'version'则输入
pip install setuptools==59.5.02)安装ruamel.yaml
pip install ruamel.yaml3)安装pyYAML
pip install PyYAML2)pycocotools安装:在Anaconda的yolov5环境中输入
conda install -c esri pycocotools3)thop/pandas安装:在在Anaconda的yolov5环境中输入
conda install -c anaconda xxx安装方法二:在pycharm终端中输入
pip install -r requirements.txt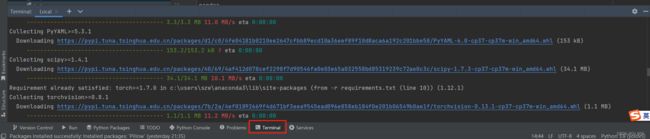
至此所有环境安装完毕。
3.数据集和预训练权重
3.1数据集
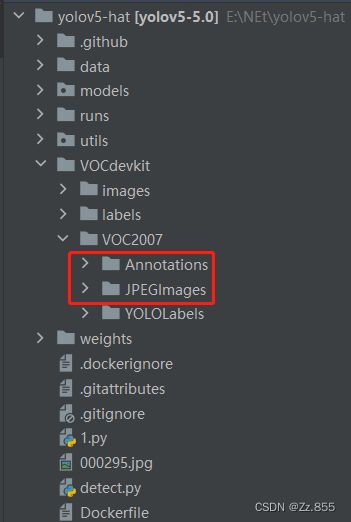
将自己数据集中的图片数据放到JPEGimages中和.xml文件放到Annotations中,使用数据转换代码将.xml格式标签转换为yolo的.txt格式
3.1.1 VOC转YOLO
#VOC转YOLO
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
def convert(size, box):
x_center = (box[0] + box[1]) / 2.0
y_center = (box[2] + box[3]) / 2.0
x = x_center / size[0]
y = y_center / size[1]
w = (box[1] - box[0]) / size[0]
h = (box[3] - box[2]) / size[1]
return (x, y, w, h)
def convert_annotation(xml_files_path, save_txt_files_path, classes):
xml_files = os.listdir(xml_files_path)
print(xml_files)
for xml_name in xml_files:
print(xml_name)
xml_file = os.path.join(xml_files_path, xml_name)
out_txt_path = os.path.join(save_txt_files_path, xml_name.split('.')[0] + '.txt')
out_txt_f = open(out_txt_path, 'w')
tree = ET.parse(xml_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
# b=(xmin, xmax, ymin, ymax)
print(w, h, b)
bb = convert((w, h), b)
out_txt_f.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
if __name__ == "__main__":
# 需要转换的类别,需要一一对应
classes1 = ['boat', 'cat'] #修改为自己标签中的种类
# 2、voc格式的xml标签文件路径
xml_files1 = r'E:\NEt\yolov5-hat\VOCdevkit\VOC2007\Annotations'
# 3、转化为yolo格式的txt标签文件存储路径
save_txt_files1 = r'E:\NEt\yolov5-hat\VOCdevkit\VOC2007\YOLOLabels'
convert_annotation(xml_files1, save_txt_files1, classes1)3.1.2 YOLO转VOC
from xml.dom.minidom import Document
import os
import cv2
# def makexml(txtPath, xmlPath, picPath): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径
def makexml(picPath, txtPath, xmlPath): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径
"""此函数用于将yolo格式txt标注文件转换为voc格式xml标注文件
在自己的标注图片文件夹下建三个子文件夹,分别命名为picture、txt、xml
"""
dic = {'0': "boat", # 创建字典用来对类型进行转换
'1': "cat", # 此处的字典要与自己的classes.txt文件中的类对应,且顺序要一致
}
files = os.listdir(txtPath)
for i, name in enumerate(files):
xmlBuilder = Document()
annotation = xmlBuilder.createElement("annotation") # 创建annotation标签
xmlBuilder.appendChild(annotation)
txtFile = open(txtPath + name)
txtList = txtFile.readlines()
img = cv2.imread(picPath + name[0:-4] + ".jpg")
Pheight, Pwidth, Pdepth = img.shape
folder = xmlBuilder.createElement("folder") # folder标签
foldercontent = xmlBuilder.createTextNode("driving_annotation_dataset")
folder.appendChild(foldercontent)
annotation.appendChild(folder) # folder标签结束
filename = xmlBuilder.createElement("filename") # filename标签
filenamecontent = xmlBuilder.createTextNode(name[0:-4] + ".jpg")
filename.appendChild(filenamecontent)
annotation.appendChild(filename) # filename标签结束
size = xmlBuilder.createElement("size") # size标签
width = xmlBuilder.createElement("width") # size子标签width
widthcontent = xmlBuilder.createTextNode(str(Pwidth))
width.appendChild(widthcontent)
size.appendChild(width) # size子标签width结束
height = xmlBuilder.createElement("height") # size子标签height
heightcontent = xmlBuilder.createTextNode(str(Pheight))
height.appendChild(heightcontent)
size.appendChild(height) # size子标签height结束
depth = xmlBuilder.createElement("depth") # size子标签depth
depthcontent = xmlBuilder.createTextNode(str(Pdepth))
depth.appendChild(depthcontent)
size.appendChild(depth) # size子标签depth结束
annotation.appendChild(size) # size标签结束
for j in txtList:
oneline = j.strip().split(" ")
object = xmlBuilder.createElement("object") # object 标签
picname = xmlBuilder.createElement("name") # name标签
namecontent = xmlBuilder.createTextNode(dic[oneline[0]])
picname.appendChild(namecontent)
object.appendChild(picname) # name标签结束
pose = xmlBuilder.createElement("pose") # pose标签
posecontent = xmlBuilder.createTextNode("Unspecified")
pose.appendChild(posecontent)
object.appendChild(pose) # pose标签结束
truncated = xmlBuilder.createElement("truncated") # truncated标签
truncatedContent = xmlBuilder.createTextNode("0")
truncated.appendChild(truncatedContent)
object.appendChild(truncated) # truncated标签结束
difficult = xmlBuilder.createElement("difficult") # difficult标签
difficultcontent = xmlBuilder.createTextNode("0")
difficult.appendChild(difficultcontent)
object.appendChild(difficult) # difficult标签结束
bndbox = xmlBuilder.createElement("bndbox") # bndbox标签
xmin = xmlBuilder.createElement("xmin") # xmin标签
mathData = int(((float(oneline[1])) * Pwidth + 1) - (float(oneline[3])) * 0.5 * Pwidth)
xminContent = xmlBuilder.createTextNode(str(mathData))
xmin.appendChild(xminContent)
bndbox.appendChild(xmin) # xmin标签结束
ymin = xmlBuilder.createElement("ymin") # ymin标签
mathData = int(((float(oneline[2])) * Pheight + 1) - (float(oneline[4])) * 0.5 * Pheight)
yminContent = xmlBuilder.createTextNode(str(mathData))
ymin.appendChild(yminContent)
bndbox.appendChild(ymin) # ymin标签结束
xmax = xmlBuilder.createElement("xmax") # xmax标签
mathData = int(((float(oneline[1])) * Pwidth + 1) + (float(oneline[3])) * 0.5 * Pwidth)
xmaxContent = xmlBuilder.createTextNode(str(mathData))
xmax.appendChild(xmaxContent)
bndbox.appendChild(xmax) # xmax标签结束
ymax = xmlBuilder.createElement("ymax") # ymax标签
mathData = int(((float(oneline[2])) * Pheight + 1) + (float(oneline[4])) * 0.5 * Pheight)
ymaxContent = xmlBuilder.createTextNode(str(mathData))
ymax.appendChild(ymaxContent)
bndbox.appendChild(ymax) # ymax标签结束
object.appendChild(bndbox) # bndbox标签结束
annotation.appendChild(object) # object标签结束
f = open(xmlPath + name[0:-4] + ".xml", 'w')
xmlBuilder.writexml(f, indent='\t', newl='\n', addindent='\t', encoding='utf-8')
f.close()
if __name__ == "__main__":
picPath = "E:\NEt\yolov5-hat\VOCdevkit\VOC2007\JPEGImages" # 图片所在文件夹路径,后面的/一定要带上
txtPath = "E:\NEt\yolov5-hat\VOCdevkit\VOC2007\YOLOLabels" # txt所在文件夹路径,后面的/一定要带上
xmlPath = "E:\NEt\yolov5-hat\VOCdevkit\VOC2007\Annotations" # xml文件保存路径,后面的/一定要带上
makexml(picPath, txtPath, xmlPath)
3.1.3划分训练集和验证集
1、将JPEGimages中所有的图片复制到images→train,将YOLOlables中所有的标签数据复制到lables→train中,运行代码自动划分。
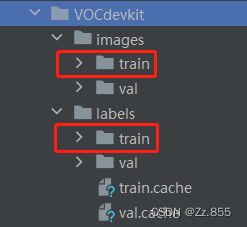
修改完路径,运行代码自动划分。
import os, random, shutil
def moveimg(fileDir, tarDir):
pathDir = os.listdir(fileDir) # 取图片的原始路径
filenumber = len(pathDir)
rate = 0.1 # 自定义抽取图片的比例,比方说100张抽10张,那就是0.1
picknumber = int(filenumber * rate) # 按照rate比例从文件夹中取一定数量图片
sample = random.sample(pathDir, picknumber) # 随机选取picknumber数量的样本图片
print(sample)
for name in sample:
shutil.move(fileDir + name, tarDir + "\\" + name)
return
def movelabel(file_list, file_label_train, file_label_val):
for i in file_list:
if i.endswith('.jpg'):
# filename = file_label_train + "\\" + i[:-4] + '.xml' # 可以改成xml文件将’.txt‘改成'.xml'就可以了
filename = file_label_train + "\\" + i[:-4] + '.txt' # 可以改成xml文件将’.txt‘改成'.xml'就可以了
if os.path.exists(filename):
shutil.move(filename, file_label_val)
print(i + "处理成功!")
if __name__ == '__main__':
fileDir = r"E:\NEt\yolov5-hat\VOCdevkit\images\train" + "\\" # 源图片文件夹路径
tarDir = r'E:\NEt\yolov5-hat\VOCdevkit\images\val' # 图片移动到新的文件夹路径
moveimg(fileDir, tarDir)
file_list = os.listdir(tarDir)
file_label_train = r"E:\NEt\yolov5-hat\VOCdevkit\labels\train" # 源图片标签路径
file_label_val = r"E:\NEt\yolov5-hat\VOCdevkit\labels\val" # 标签
# 移动到新的文件路径
movelabel(file_list, file_label_train, file_label_val)3.2预训练权重
用于加载预训练权重进行网络的训练,可下载多个权重,点击蓝色即可进行下载。
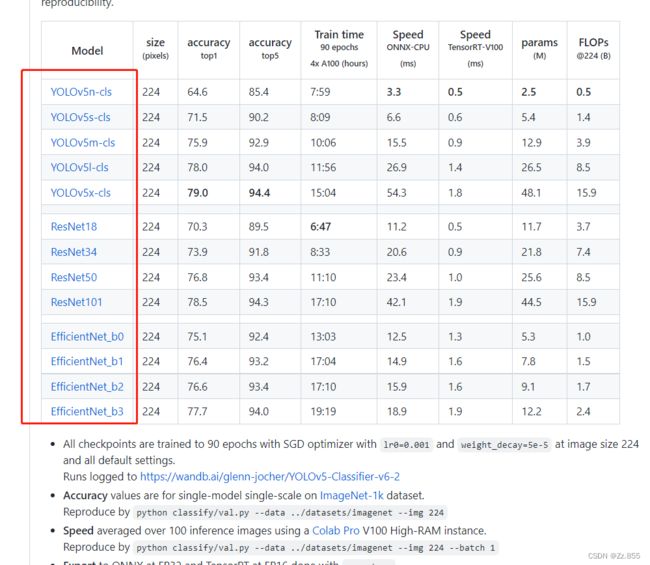
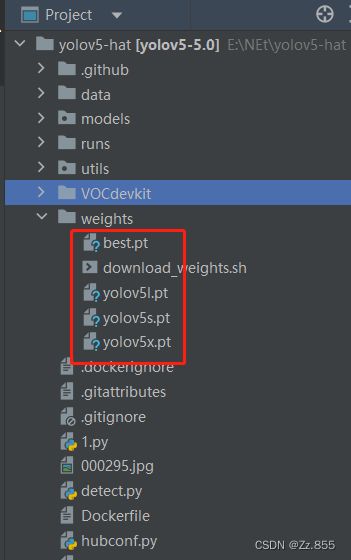
将下载好的预训练权重,复制到文件夹weights下
4.训练模型
预训练模型和数据集都准备好了,就可以开始训练自己的yolov5目标检测模型了,训练目标检测模型需要修改两个yaml文件中的参数。一个是data目录下的相应的yaml文件,一个是models目录文件下的相应的yaml文件
4.1修改data配置文件
修改data目录下的yaml文件: 找到目录下的voc.yaml文件,将该文件复制一份,将复制的文件重命名,例如hat.yaml。
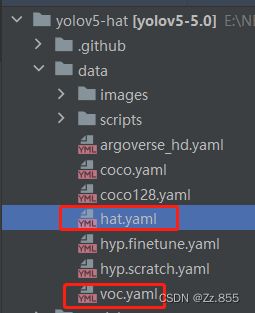
打开hat.yaml对应修改这些内容,其中路径最好填写绝对路径

4.2修改models配置文件
使用yolov5s预训练权重进行训练,要使用models目录下的yolov5s.yaml文件中的相应参数(因为不同的预训练权重对应着不同的网络层数,所以用错预训练权重会报错),同样复制一份进行重命名。
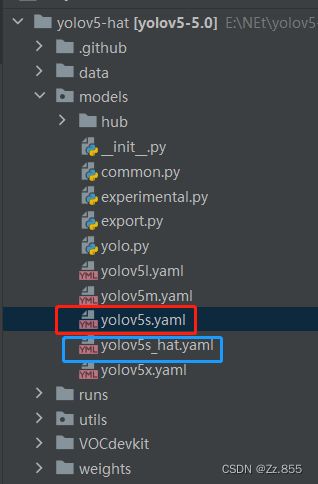
打开yolov5s_hat.yaml修改类别数
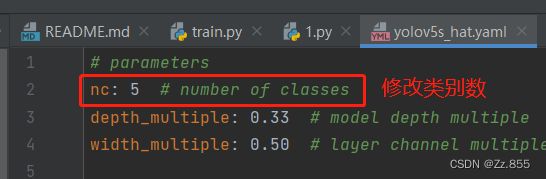
4.3启用tensorbord查看参数
修改完上述两个.yaml后,打开train.py往下翻到tensorbord模块,其中各函数语义如下,修改3行文件路径使用绝对路径,一个是权重文件,一个是模型的yaml文件,一个是数据的yaml文件,第五行epoch为循环次数,第六行batch-size为输入图片数量。
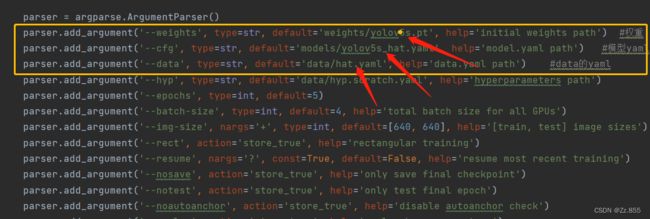
if __name__ == '__main__':
"""
opt模型主要参数解析:
--weights:初始化的权重文件的路径地址
--cfg:模型yaml文件的路径地址
--data:数据yaml文件的路径地址
--hyp:超参数文件路径地址
--epochs:训练轮次
--batch-size:喂入批次文件的多少
--img-size:输入图片尺寸
--rect:是否采用矩形训练,默认False
--resume:接着打断训练上次的结果接着训练
--nosave:不保存模型,默认False
--notest:不进行test,默认False
--noautoanchor:不自动调整anchor,默认False
--evolve:是否进行超参数进化,默认False
--bucket:谷歌云盘bucket,一般不会用到
--cache-images:是否提前缓存图片到内存,以加快训练速度,默认False
--image-weights:使用加权图像选择进行训练
--device:训练的设备,cpu;0(表示一个gpu设备cuda:0);0,1,2,3(多个gpu设备)
--multi-scale:是否进行多尺度训练,默认False
--single-cls:数据集是否只有一个类别,默认False
--adam:是否使用adam优化器
--sync-bn:是否使用跨卡同步BN,在DDP模式使用
--local_rank:DDP参数,请勿修改
--workers:最大工作核心数
--project:训练模型的保存位置
--name:模型保存的目录名称
--exist-ok:模型目录是否存在,不存在就创建
"""
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='weights/yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='models/yolov5s_hat.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/hat.yaml', help='data.yaml path')
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=10)
parser.add_argument('--batch-size', type=int, default=1, help='total batch size for all GPUs')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--notest', action='store_true', help='only test final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')
parser.add_argument('--project', default='runs/train', help='save to project/name')
parser.add_argument('--entity', default=None, help='W&B entity')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--linear-lr', action='store_true', help='linear LR')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--upload_dataset', action='store_true', help='Upload dataset as W&B artifact table')
parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval for W&B')
parser.add_argument('--save_period', type=int, default=-1, help='Log model after every "save_period" epoch')
parser.add_argument('--artifact_alias', type=str, default="latest", help='version of dataset artifact to be used')
opt = parser.parse_args()调试完上述数据就可以进行训练自己的数据集,运行train.py。
4.4训练后
1.训练完成后自动生成runs文件夹,在runs\train\exp\weights目录中生成两个权重文件,一个是最后一轮的权重文件,一个是最好的权重文件,一会我们就要利用这个最好的权重文件来做推理测试。除此以外还会产生一些验证文件的图片等一些文件。(再运行train会生成exp1···)

2.在主目录中找到 找到主目录下的detect.py文件,打开该文件。 detect.py:利用训练好的权重参数进行目标检测,可以进行图像、视频和摄像头的检测。
3.找到函数主要参数
f __name__ == '__main__':
"""
--weights:权重的路径地址
--source:测试数据,可以是图片/视频路径,也可以是'0'(电脑自带摄像头),也可以是rtsp等视频流
--output:网络预测之后的图片/视频的保存路径
--img-size:网络输入图片大小
--conf-thres:置信度阈值
--iou-thres:做nms的iou阈值
--device:是用GPU还是CPU做推理
--view-img:是否展示预测之后的图片/视频,默认False
--save-txt:是否将预测的框坐标以txt文件形式保存,默认False
--classes:设置只保留某一部分类别,形如0或者0 2 3
--agnostic-nms:进行nms是否也去除不同类别之间的框,默认False
--augment:推理的时候进行多尺度,翻转等操作(TTA)推理
--update:如果为True,则对所有模型进行strip_optimizer操作,去除pt文件中的优化器等信息,默认为False
--project:推理的结果保存在runs/detect目录下
--name:结果保存的文件夹名称
"""
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='runs/train/exp/weights/best.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='E:\\2022Projects\\QJ\\QJ4\sj\photo', help='source') # file/folder, 0 for webcam
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
opt = parser.parse_args()4.将训练好的最优权重结对路径路径复制到红框处,将要测试的图片/视频绝对路径放到蓝框。点击运行即可预测图片。
若要利用电脑摄像头进行测试,需要将路径改为0
![]()
并将datasets.py中的第279行下添加str。
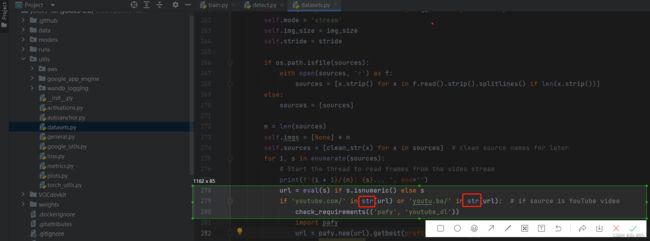
5.detect,py运行结束会将推理结果存在runs\detect\exp中
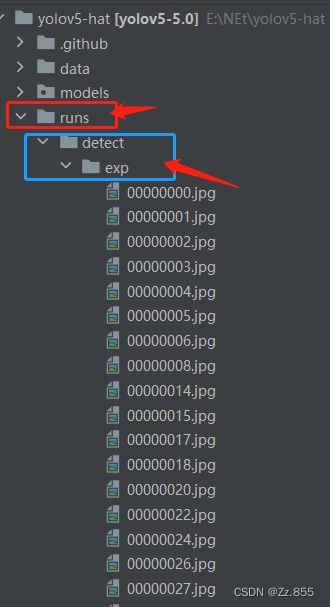
至此yolov5目标检测结束
参考文章:https://blog.csdn.net/didiaopao/article/details/119954291
最新PyTorch(GPU版)实操安装教程(3090 win10)_哔哩哔哩_bilibili
5.遇到的问题
1.未使用GPU训练
解决方法:不要在pytorch官网使用conda安装,使用pip安装
2.使用pip安装后报错
![]()
解决方法:检查一下自己Anaconda的envs安装路径中是否存在两个dll文件

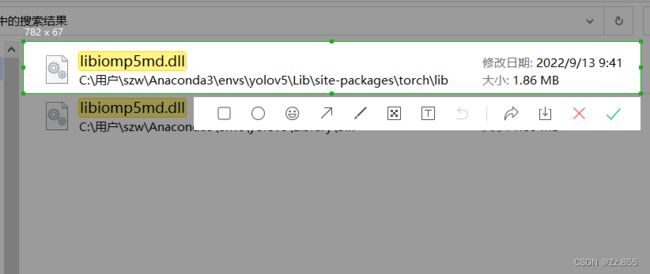
删除其中一个即可
3.报错:RuntimeError: result type Float can’t be cast to the desired output type long int
问题原因:官网的yolov5-master版本可以正常运行,但是yolov5-5.0/yolov5-6.1等版本就是不可以运行
解决方法:找到修改utils中的loss.py里面的两处内容
(1)【Ctrl+F】搜索【for i in range(self.nl)】替换成:
anchors, shape = self.anchors[i], p[i].shape
(2)【Ctrl+F】搜索【indices.append】替换成
indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid