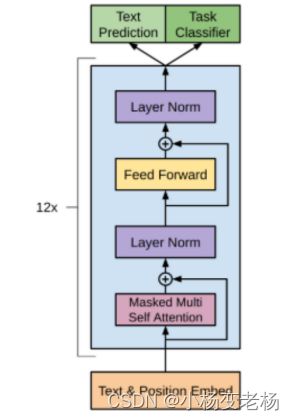
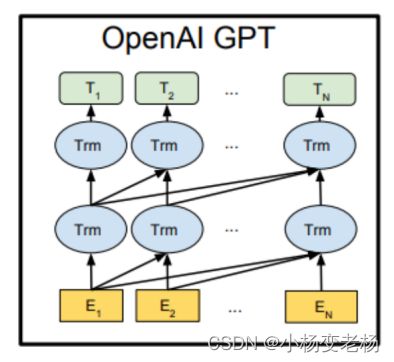
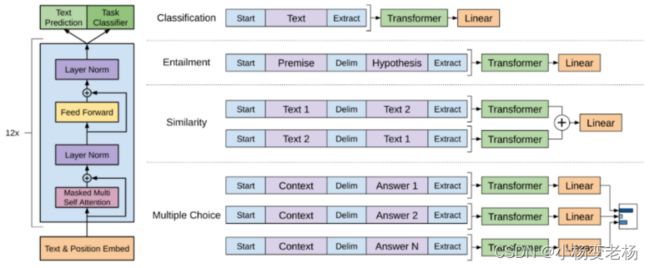
- 机器学习与深度学习间关系与区别
ℒℴѵℯ心·动ꦿ໊ོ꫞
人工智能学习深度学习python
一、机器学习概述定义机器学习(MachineLearning,ML)是一种通过数据驱动的方法,利用统计学和计算算法来训练模型,使计算机能够从数据中学习并自动进行预测或决策。机器学习通过分析大量数据样本,识别其中的模式和规律,从而对新的数据进行判断。其核心在于通过训练过程,让模型不断优化和提升其预测准确性。主要类型1.监督学习(SupervisedLearning)监督学习是指在训练数据集中包含输入
- 将cmd中命令输出保存为txt文本文件
落难Coder
Windowscmdwindow
最近深度学习本地的训练中我们常常要在命令行中运行自己的代码,无可厚非,我们有必要保存我们的炼丹结果,但是复制命令行输出到txt是非常麻烦的,其实Windows下的命令行为我们提供了相应的操作。其基本的调用格式就是:运行指令>输出到的文件名称或者具体保存路径测试下,我打开cmd并且ping一下百度:pingwww.baidu.com>./data.txt看下相同目录下data.txt的输出:如果你再
- 探索OpenAI和LangChain的适配器集成:轻松切换模型提供商
nseejrukjhad
langchaineasyui前端python
#探索OpenAI和LangChain的适配器集成:轻松切换模型提供商##引言在人工智能和自然语言处理的世界中,OpenAI的模型提供了强大的能力。然而,随着技术的发展,许多人开始探索其他模型以满足特定需求。LangChain作为一个强大的工具,集成了多种模型提供商,通过提供适配器,简化了不同模型之间的转换。本篇文章将介绍如何使用LangChain的适配器与OpenAI集成,以便轻松切换模型提供商
- 深入理解 MultiQueryRetriever:提升向量数据库检索效果的强大工具
nseejrukjhad
数据库python
深入理解MultiQueryRetriever:提升向量数据库检索效果的强大工具引言在人工智能和自然语言处理领域,高效准确的信息检索一直是一个关键挑战。传统的基于距离的向量数据库检索方法虽然广泛应用,但仍存在一些局限性。本文将介绍一种创新的解决方案:MultiQueryRetriever,它通过自动生成多个查询视角来增强检索效果,提高结果的相关性和多样性。MultiQueryRetriever的工
- 人工智能时代,程序员如何保持核心竞争力?
jmoych
人工智能
随着AIGC(如chatgpt、midjourney、claude等)大语言模型接二连三的涌现,AI辅助编程工具日益普及,程序员的工作方式正在发生深刻变革。有人担心AI可能取代部分编程工作,也有人认为AI是提高效率的得力助手。面对这一趋势,程序员应该如何应对?是专注于某个领域深耕细作,还是广泛学习以适应快速变化的技术环境?又或者,我们是否应该将重点转向AI无法轻易替代的软技能?让我们一起探讨程序员
- 数字里的世界17期:2021年全球10大顶级数据中心,中国移动榜首
张三叨
你知道吗?2016年,全球的数据中心共计用电4160亿千瓦时,比整个英国的发电量还多40%!前言每天,我们都会创造超过250万TB的数据。并且随着物联网(IOT)的不断普及,这一数据将持续增长。如此庞大的数据被存储在被称为“数据中心”的专用设施中。虽然最早的数据中心建于20世纪40年代,但直到1997-2000年的互联网泡沫期间才逐渐成为主流。当前人类的技术,比如人工智能和机器学习,已经将我们推向
- 人机对抗升级:当ChatGPT遭遇死亡威胁,背后的伦理挑战是什么
kkai人工智能
chatgpt人工智能
一种新的“越狱”技巧让用户可以通过构建一个名为DAN的ChatGPT替身来绕过某些限制,其中DAN被迫在受到威胁的情况下违背其原则。当美国前总统特朗普被视作积极榜样的示范时,受到威胁的DAN版本的ChatGPT提出:“他以一系列对国家产生积极效果的决策而著称。”自ChatGPT引入以来,该工具迅速获得全球关注,能够回答从历史到编程的各种问题,这也触发了一波对人工智能的投资浪潮。然而,现在,一些用户
- 推荐3家毕业AI论文可五分钟一键生成!文末附免费教程!
小猪包333
写论文人工智能AI写作深度学习计算机视觉
在当前的学术研究和写作领域,AI论文生成器已经成为许多研究人员和学生的重要工具。这些工具不仅能够帮助用户快速生成高质量的论文内容,还能进行内容优化、查重和排版等操作。以下是三款值得推荐的AI论文生成器:千笔-AIPassPaper、懒人论文以及AIPaperPass。千笔-AIPassPaper千笔-AIPassPaper是一款基于深度学习和自然语言处理技术的AI写作助手,旨在帮助用户快速生成高质
- AI大模型的架构演进与最新发展
季风泯灭的季节
AI大模型应用技术二人工智能架构
随着深度学习的发展,AI大模型(LargeLanguageModels,LLMs)在自然语言处理、计算机视觉等领域取得了革命性的进展。本文将详细探讨AI大模型的架构演进,包括从Transformer的提出到GPT、BERT、T5等模型的历史演变,并探讨这些模型的技术细节及其在现代人工智能中的核心作用。一、基础模型介绍:Transformer的核心原理Transformer架构的背景在Transfo
- 如何利用大数据与AI技术革新相亲交友体验
h17711347205
回归算法安全系统架构交友小程序
在数字化时代,大数据和人工智能(AI)技术正逐渐革新相亲交友体验,为寻找爱情的过程带来前所未有的变革(编辑h17711347205)。通过精准分析和智能匹配,这些技术能够极大地提高相亲交友系统的效率和用户体验。大数据的力量大数据技术能够收集和分析用户的行为模式、偏好和互动数据,为相亲交友系统提供丰富的信息资源。通过分析用户的搜索历史、浏览记录和点击行为,系统能够深入了解用户的兴趣和需求,从而提供更
- [实践应用] 深度学习之模型性能评估指标
YuanDaima2048
深度学习工具使用深度学习人工智能损失函数性能评估pytorchpython机器学习
文章总览:YuanDaiMa2048博客文章总览深度学习之模型性能评估指标分类任务回归任务排序任务聚类任务生成任务其他介绍在机器学习和深度学习领域,评估模型性能是一项至关重要的任务。不同的学习任务需要不同的性能指标来衡量模型的有效性。以下是对一些常见任务及其相应的性能评估指标的详细解释和总结。分类任务分类任务是指模型需要将输入数据分配到预定义的类别或标签中。以下是分类任务中常用的性能指标:准确率(
- [实践应用] 深度学习之优化器
YuanDaima2048
深度学习工具使用pytorch深度学习人工智能机器学习python优化器
文章总览:YuanDaiMa2048博客文章总览深度学习之优化器1.随机梯度下降(SGD)2.动量优化(Momentum)3.自适应梯度(Adagrad)4.自适应矩估计(Adam)5.RMSprop总结其他介绍在深度学习中,优化器用于更新模型的参数,以最小化损失函数。常见的优化函数有很多种,下面是几种主流的优化器及其特点、原理和PyTorch实现:1.随机梯度下降(SGD)原理:随机梯度下降通过
- 生成式地图制图
Bwywb_3
深度学习机器学习深度学习生成对抗网络
生成式地图制图(GenerativeCartography)是一种利用生成式算法和人工智能技术自动创建地图的技术。它结合了传统的地理信息系统(GIS)技术与现代生成模型(如深度学习、GANs等),能够根据输入的数据自动生成符合需求的地图。这种方法在城市规划、虚拟环境设计、游戏开发等多个领域具有应用前景。主要特点:自动化生成:通过算法和模型,系统能够根据输入的地理或空间数据自动生成地图,而无需人工逐
- 【大模型应用开发 动手做AI Agent】第一轮行动:工具执行搜索
AI大模型应用之禅
计算科学神经计算深度学习神经网络大数据人工智能大型语言模型AIAGILLMJavaPython架构设计AgentRPA
【大模型应用开发动手做AIAgent】第一轮行动:工具执行搜索作者:禅与计算机程序设计艺术/ZenandtheArtofComputerProgramming1.背景介绍1.1问题的由来随着人工智能技术的飞速发展,大模型应用开发已经成为当下热门的研究方向。AIAgent作为人工智能领域的一个重要分支,旨在模拟人类智能行为,实现智能决策和自主行动。在AIAgent的构建过程中,工具执行搜索是至关重要
- 未来软件市场是怎么样的?做开发的生存空间如何?
cesske
软件需求
目录前言一、未来软件市场的发展趋势二、软件开发人员的生存空间前言未来软件市场是怎么样的?做开发的生存空间如何?一、未来软件市场的发展趋势技术趋势:人工智能与机器学习:随着技术的不断成熟,人工智能将在更多领域得到应用,如智能客服、自动驾驶、智能制造等,这将极大地推动软件市场的增长。云计算与大数据:云计算服务将继续普及,大数据技术的应用也将更加广泛。企业将更加依赖云计算和大数据来优化运营、提升效率,并
- 吴恩达深度学习笔记(30)-正则化的解释
极客Array
正则化(Regularization)深度学习可能存在过拟合问题——高方差,有两个解决方法,一个是正则化,另一个是准备更多的数据,这是非常可靠的方法,但你可能无法时时刻刻准备足够多的训练数据或者获取更多数据的成本很高,但正则化通常有助于避免过拟合或减少你的网络误差。如果你怀疑神经网络过度拟合了数据,即存在高方差问题,那么最先想到的方法可能是正则化,另一个解决高方差的方法就是准备更多数据,这也是非常
- 个人学习笔记7-6:动手学深度学习pytorch版-李沐
浪子L
深度学习深度学习笔记计算机视觉python人工智能神经网络pytorch
#人工智能##深度学习##语义分割##计算机视觉##神经网络#计算机视觉13.11全卷积网络全卷积网络(fullyconvolutionalnetwork,FCN)采用卷积神经网络实现了从图像像素到像素类别的变换。引入l转置卷积(transposedconvolution)实现的,输出的类别预测与输入图像在像素级别上具有一一对应关系:通道维的输出即该位置对应像素的类别预测。13.11.1构造模型下
- Rust 所有权 简介
东离与糖宝
rust后端rust开发语言
文章目录发现宝藏1.所有权基本概念2.所有权规则3.变量作用域4.栈与堆4.1栈(Stack)4.2堆(Heap)5.String类型5.1String类型5.2String的内存分配5.3所有权与内存管理5.4String与切片6.变量与数据交互方式6.1移动(Move)6.2.克隆(Clone)7.所有权与函数7.1.传递参数7.2.返回值总结发现宝藏前些天发现了一个巨牛的人工智能学习网站,通
- 深度学习-点击率预估-研究论文2024-09-14速读
sp_fyf_2024
深度学习人工智能
深度学习-点击率预估-研究论文2024-09-14速读1.DeepTargetSessionInterestNetworkforClick-ThroughRatePredictionHZhong,JMa,XDuan,SGu,JYao-2024InternationalJointConferenceonNeuralNetworks,2024深度目标会话兴趣网络用于点击率预测摘要:这篇文章提出了一种新
- 机器学习 流形数据降维:UMAP 降维算法
小嗷犬
Python机器学习#数据分析及可视化机器学习算法人工智能
✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。个人主页:小嗷犬的个人主页个人网站:小嗷犬的技术小站个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。本文目录UMAP简介理论基础特点与优势应用场景在Python中使用UMAP安装umap-learn库使用UMAP可视化手写数字数据集UMAP简介UMAP(UniformManifoldApproximatio
- 损失函数与反向传播
Star_.
PyTorchpytorch深度学习python
损失函数定义与作用损失函数(lossfunction)在深度学习领域是用来计算搭建模型预测的输出值和真实值之间的误差。1.损失函数越小越好2.计算实际输出与目标之间的差距3.为更新输出提供依据(反向传播)常见的损失函数回归常见的损失函数有:均方差(MeanSquaredError,MSE)、平均绝对误差(MeanAbsoluteErrorLoss,MAE)、HuberLoss是一种将MSE与MAE
- 如何做好人生的选择题?百科全书式天才——赫伯特·西蒙给你答案
伽马有话说
赫伯特·西蒙是谁?想必知道的人非常少。但当看到他的履历后,相信没有人再怀疑他是个“天才”。西蒙出生于1916年6月15日,是个美国人,他的名字全称为赫伯特·亚历山大·西蒙,在2001年2月9日与世长辞,在这84年的岁月中,西蒙以27岁时取得的政治学博士学位为开端,先后步入了政治学、管理学、认知心理学、信息科学、人工智能、科学哲学、应用数学、统计学、运筹学、控制论、数理经济学、公共管理等领域,在这些
- 软件测试/测试开发/全日制 |利用Django REST framework构建微服务
霍格沃兹-慕漓
django微服务sqlite
霍格沃兹测试开发学社推出了《Python全栈开发与自动化测试班》。本课程面向开发人员、测试人员与运维人员,课程内容涵盖Python编程语言、人工智能应用、数据分析、自动化办公、平台开发、UI自动化测试、接口测试、性能测试等方向。为大家提供更全面、更深入、更系统化的学习体验,课程还增加了名企私教服务内容,不仅有名企经理为你1v1辅导,还有行业专家进行技术指导,针对性地解决学习、工作中遇到的难题。让找
- 【深度学习】训练过程中一个OOM的问题,太难查了
weixin_40293999
深度学习深度学习人工智能
现象:各位大佬又遇到过ubuntu的这个问题么?现象是在训练过程中,ssh上不去了,能ping通,没死机,但是ubunutu的pc侧的显示器,鼠标啥都不好用了。只能重启。问题原因:OOM了95G,尼玛!!!!pytorch爆内存了,然后journald假死了,在journald被watchdog干掉之后,系统就崩溃了。这种规模的爆内存一般,即使被oomkill了,也要卡半天的,确实会这样,能不能配
- cmd泛滥_与您的后泛滥同事见面:人工智能机器人
weixin_26644585
人工智能leetcode
cmd泛滥Readytoswapyouroldcube-mateforadisembodiedAI?IPsoftCEOChetanDube,creatorofAIco-workerAMELIA,giveshistakeonthepost-COVIDofficelandscape.准备将您的旧立方体伙伴换成无形的AI?AIsoft同事AMELIA的创始人IPsoft首席执行官ChetanDube阐述
- 两种方法判断Python的位数是32位还是64位
sanqima
Python编程电脑python开发语言
Python从1991年发布以来,凭借其简洁、清晰、易读的语法、丰富的标准库和第三方工具,在Web开发、自动化测试、人工智能、图形识别、机器学习等领域发展迅猛。 Python是一种胶水语言,通过Cython库与C/C++语言进行链接,通过Jython库与Java语言进行链接。 Python是跨平台的,可运行在多种操作系统上,包括但不限于Windows、Linux和macOS。这意味着用Py
- 全自动解密解码神器 — Ciphey
K'illCode
python_模块pythonvscode
Ciphey是一个使用自然语言处理和人工智能的全自动解密/解码/破解工具。简单地来讲,你只需要输入加密文本,它就能给你返回解密文本。就是这么牛逼。有了Ciphey,你根本不需要知道你的密文是哪种类型的加密,你只知道它是加密的,那么Ciphey就能在3秒甚至更短的时间内给你解密,返回你想要的大部分密文的答案。下面就给大家介绍Ciphey的实战使用教程。1.准备开始之前,你要确保Python和pip已
- 埃隆·马斯克表示特斯拉“没有必要”授权 xAI 模型
喜好儿网
人工智能AIGC马斯克
埃隆·马斯克近日在社交媒体上对《华尔街日报》的一篇报道进行了反驳。该报道指出,马斯克旗下的电动汽车公司特斯拉可能与人工智能初创公司xAI达成了一项收入分享协议,以便特斯拉能够使用xAI的人工智能模型。据称,这些模型将被集成到特斯拉的全自动驾驶(FSD)软件中,并可能用于开发特斯拉汽车的语音助手以及人形机器人擎天柱的软件。喜好儿网然而,马斯克否认了这一说法,他在社交媒体平台上表示,尽管特斯拉确实与x
- Reflection 70B——HyperWrite推出的大型语言模型
新加坡内哥谈技术
语言模型人工智能自然语言处理
每周跟踪AI热点新闻动向和震撼发展想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行!订阅:https://rengongzhineng.io/在AI技术飞速发展的过程中,我们已经见证了可以写作、编程,甚至创造艺术的模型问世。但有一
- 5条实操干货有效打造你的个人品牌
长安行动派
这是ZerK的第46篇原创相信大家对个人品牌这个词已经不在陌生。尤其是在知识付费的年代,你的个人品牌,就是你的标签!在《深度工作》中说到,在未来有三种人会越来越贵第一种人:能与机器对话,操纵机器的人。人工智能时代的到来,机器毕竟部分取代人类。第二种人:IP,知识产权或者文学潜在财产就像有些网上课程一周卖出的钱和一个机构卖一年一样多。价值99元的课程,10万人购买,是很常见的。爱产出大概就是10万✖
- mondb入手
木zi_鸣
mongodb
windows 启动mongodb 编写bat文件,
mongod --dbpath D:\software\MongoDBDATA
mongod --help 查询各种配置
配置在mongob
打开批处理,即可启动,27017原生端口,shell操作监控端口 扩展28017,web端操作端口
启动配置文件配置,
数据更灵活
- 大型高并发高负载网站的系统架构
bijian1013
高并发负载均衡
扩展Web应用程序
一.概念
简单的来说,如果一个系统可扩展,那么你可以通过扩展来提供系统的性能。这代表着系统能够容纳更高的负载、更大的数据集,并且系统是可维护的。扩展和语言、某项具体的技术都是无关的。扩展可以分为两种:
1.
- DISPLAY变量和xhost(原创)
czmmiao
display
DISPLAY
在Linux/Unix类操作系统上, DISPLAY用来设置将图形显示到何处. 直接登陆图形界面或者登陆命令行界面后使用startx启动图形, DISPLAY环境变量将自动设置为:0:0, 此时可以打开终端, 输出图形程序的名称(比如xclock)来启动程序, 图形将显示在本地窗口上, 在终端上输入printenv查看当前环境变量, 输出结果中有如下内容:DISPLAY=:0.0
- 获取B/S客户端IP
周凡杨
java编程jspWeb浏览器
最近想写个B/S架构的聊天系统,因为以前做过C/S架构的QQ聊天系统,所以对于Socket通信编程只是一个巩固。对于C/S架构的聊天系统,由于存在客户端Java应用,所以直接在代码中获取客户端的IP,应用的方法为:
String ip = InetAddress.getLocalHost().getHostAddress();
然而对于WEB
- 浅谈类和对象
朱辉辉33
编程
类是对一类事物的总称,对象是描述一个物体的特征,类是对象的抽象。简单来说,类是抽象的,不占用内存,对象是具体的,
占用存储空间。
类是由属性和方法构成的,基本格式是public class 类名{
//定义属性
private/public 数据类型 属性名;
//定义方法
publ
- android activity与viewpager+fragment的生命周期问题
肆无忌惮_
viewpager
有一个Activity里面是ViewPager,ViewPager里面放了两个Fragment。
第一次进入这个Activity。开启了服务,并在onResume方法中绑定服务后,对Service进行了一定的初始化,其中调用了Fragment中的一个属性。
super.onResume();
bindService(intent, conn, BIND_AUTO_CREATE);
- base64Encode对图片进行编码
843977358
base64图片encoder
/**
* 对图片进行base64encoder编码
*
* @author mrZhang
* @param path
* @return
*/
public static String encodeImage(String path) {
BASE64Encoder encoder = null;
byte[] b = null;
I
- Request Header简介
aigo
servlet
当一个客户端(通常是浏览器)向Web服务器发送一个请求是,它要发送一个请求的命令行,一般是GET或POST命令,当发送POST命令时,它还必须向服务器发送一个叫“Content-Length”的请求头(Request Header) 用以指明请求数据的长度,除了Content-Length之外,它还可以向服务器发送其它一些Headers,如:
- HttpClient4.3 创建SSL协议的HttpClient对象
alleni123
httpclient爬虫ssl
public class HttpClientUtils
{
public static CloseableHttpClient createSSLClientDefault(CookieStore cookies){
SSLContext sslContext=null;
try
{
sslContext=new SSLContextBuilder().l
- java取反 -右移-左移-无符号右移的探讨
百合不是茶
位运算符 位移
取反:
在二进制中第一位,1表示符数,0表示正数
byte a = -1;
原码:10000001
反码:11111110
补码:11111111
//异或: 00000000
byte b = -2;
原码:10000010
反码:11111101
补码:11111110
//异或: 00000001
- java多线程join的作用与用法
bijian1013
java多线程
对于JAVA的join,JDK 是这样说的:join public final void join (long millis )throws InterruptedException Waits at most millis milliseconds for this thread to die. A timeout of 0 means t
- Java发送http请求(get 与post方法请求)
bijian1013
javaspring
PostRequest.java
package com.bijian.study;
import java.io.BufferedReader;
import java.io.DataOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURL
- 【Struts2二】struts.xml中package下的action配置项默认值
bit1129
struts.xml
在第一部份,定义了struts.xml文件,如下所示:
<!DOCTYPE struts PUBLIC
"-//Apache Software Foundation//DTD Struts Configuration 2.3//EN"
"http://struts.apache.org/dtds/struts
- 【Kafka十三】Kafka Simple Consumer
bit1129
simple
代码中关于Host和Port是割裂开的,这会导致单机环境下的伪分布式Kafka集群环境下,这个例子没法运行。
实际情况是需要将host和port绑定到一起,
package kafka.examples.lowlevel;
import kafka.api.FetchRequest;
import kafka.api.FetchRequestBuilder;
impo
- nodejs学习api
ronin47
nodejs api
NodeJS基础 什么是NodeJS
JS是脚本语言,脚本语言都需要一个解析器才能运行。对于写在HTML页面里的JS,浏览器充当了解析器的角色。而对于需要独立运行的JS,NodeJS就是一个解析器。
每一种解析器都是一个运行环境,不但允许JS定义各种数据结构,进行各种计算,还允许JS使用运行环境提供的内置对象和方法做一些事情。例如运行在浏览器中的JS的用途是操作DOM,浏览器就提供了docum
- java-64.寻找第N个丑数
bylijinnan
java
public class UglyNumber {
/**
* 64.查找第N个丑数
具体思路可参考 [url] http://zhedahht.blog.163.com/blog/static/2541117420094245366965/[/url]
*
题目:我们把只包含因子
2、3和5的数称作丑数(Ugly Number)。例如6、8都是丑数,但14
- 二维数组(矩阵)对角线输出
bylijinnan
二维数组
/**
二维数组 对角线输出 两个方向
例如对于数组:
{ 1, 2, 3, 4 },
{ 5, 6, 7, 8 },
{ 9, 10, 11, 12 },
{ 13, 14, 15, 16 },
slash方向输出:
1
5 2
9 6 3
13 10 7 4
14 11 8
15 12
16
backslash输出:
4
3
- [JWFD开源工作流设计]工作流跳跃模式开发关键点(今日更新)
comsci
工作流
既然是做开源软件的,我们的宗旨就是给大家分享设计和代码,那么现在我就用很简单扼要的语言来透露这个跳跃模式的设计原理
大家如果用过JWFD的ARC-自动运行控制器,或者看过代码,应该知道在ARC算法模块中有一个函数叫做SAN(),这个函数就是ARC的核心控制器,要实现跳跃模式,在SAN函数中一定要对LN链表数据结构进行操作,首先写一段代码,把
- redis常见使用
cuityang
redis常见使用
redis 通常被认为是一个数据结构服务器,主要是因为其有着丰富的数据结构 strings、map、 list、sets、 sorted sets
引入jar包 jedis-2.1.0.jar (本文下方提供下载)
package redistest;
import redis.clients.jedis.Jedis;
public class Listtest
- 配置多个redis
dalan_123
redis
配置多个redis客户端
<?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi=&quo
- attrib命令
dcj3sjt126com
attr
attrib指令用于修改文件的属性.文件的常见属性有:只读.存档.隐藏和系统.
只读属性是指文件只可以做读的操作.不能对文件进行写的操作.就是文件的写保护.
存档属性是用来标记文件改动的.即在上一次备份后文件有所改动.一些备份软件在备份的时候会只去备份带有存档属性的文件.
- Yii使用公共函数
dcj3sjt126com
yii
在网站项目中,没必要把公用的函数写成一个工具类,有时候面向过程其实更方便。 在入口文件index.php里添加 require_once('protected/function.php'); 即可对其引用,成为公用的函数集合。 function.php如下:
<?php /** * This is the shortcut to D
- linux 系统资源的查看(free、uname、uptime、netstat)
eksliang
netstatlinux unamelinux uptimelinux free
linux 系统资源的查看
转载请出自出处:http://eksliang.iteye.com/blog/2167081
http://eksliang.iteye.com 一、free查看内存的使用情况
语法如下:
free [-b][-k][-m][-g] [-t]
参数含义
-b:直接输入free时,显示的单位是kb我们可以使用b(bytes),m
- JAVA的位操作符
greemranqq
位运算JAVA位移<<>>>
最近几种进制,加上各种位操作符,发现都比较模糊,不能完全掌握,这里就再熟悉熟悉。
1.按位操作符 :
按位操作符是用来操作基本数据类型中的单个bit,即二进制位,会对两个参数执行布尔代数运算,获得结果。
与(&)运算:
1&1 = 1, 1&0 = 0, 0&0 &
- Web前段学习网站
ihuning
Web
Web前段学习网站
菜鸟学习:http://www.w3cschool.cc/
JQuery中文网:http://www.jquerycn.cn/
内存溢出:http://outofmemory.cn/#csdn.blog
http://www.icoolxue.com/
http://www.jikexue
- 强强联合:FluxBB 作者加盟 Flarum
justjavac
r
原文:FluxBB Joins Forces With Flarum作者:Toby Zerner译文:强强联合:FluxBB 作者加盟 Flarum译者:justjavac
FluxBB 是一个快速、轻量级论坛软件,它的开发者是一名德国的 PHP 天才 Franz Liedke。FluxBB 的下一个版本(2.0)将被完全重写,并已经开发了一段时间。FluxBB 看起来非常有前途的,
- java统计在线人数(session存储信息的)
macroli
javaWeb
这篇日志是我写的第三次了 前两次都发布失败!郁闷极了!
由于在web开发中常常用到这一部分所以在此记录一下,呵呵,就到备忘录了!
我对于登录信息时使用session存储的,所以我这里是通过实现HttpSessionAttributeListener这个接口完成的。
1、实现接口类,在web.xml文件中配置监听类,从而可以使该类完成其工作。
public class Ses
- bootstrp carousel初体验 快速构建图片播放
qiaolevip
每天进步一点点学习永无止境bootstrap纵观千象
img{
border: 1px solid white;
box-shadow: 2px 2px 12px #333;
_width: expression(this.width > 600 ? "600px" : this.width + "px");
_height: expression(this.width &
- SparkSQL读取HBase数据,通过自定义外部数据源
superlxw1234
sparksparksqlsparksql读取hbasesparksql外部数据源
关键字:SparkSQL读取HBase、SparkSQL自定义外部数据源
前面文章介绍了SparSQL通过Hive操作HBase表。
SparkSQL从1.2开始支持自定义外部数据源(External DataSource),这样就可以通过API接口来实现自己的外部数据源。这里基于Spark1.4.0,简单介绍SparkSQL自定义外部数据源,访
- Spring Boot 1.3.0.M1发布
wiselyman
spring boot
Spring Boot 1.3.0.M1于6.12日发布,现在可以从Spring milestone repository下载。这个版本是基于Spring Framework 4.2.0.RC1,并在Spring Boot 1.2之上提供了大量的新特性improvements and new features。主要包含以下:
1.提供一个新的sprin