【LIMU-Bert论文阅读】
LIMU-BERT: Unleashing the Potential of Unlabeled Data for IMU Sensing Applications
题目重点:
- 充分利用无标签数据
- 适用于IMU传感器应用(并没有指出specfic task)
文章核心:
如何根据IMU数据的特征设计出LIMU-Bert,从而提取出泛化特征。
ABSTRACT
本文并没有针对某一项任务而设计,而是从IMU应用角度出发,考虑大多数工作都需要大量且高质量的有标签数据,这需要high annotation和training costs,相比较而言无标签数据更加易得。所以设计了LIMU-Bert表征学习模型:
- 充分利用无标签数据
- 提取出泛化特征,如temporal relations和feature distributions
文章成果:
- 通过观察IMU数据,提出了适用于IMU应用的方法
- task-specific模型使用LIMU-BERT提取到的表征,可以通过少量的有标签数据取得优秀的performance
- 在HAR和DPC两个任务上进行验证,取得了好的效果
- 模型lightweight,可以部署到移动设备上
INTRODUCTION
目前工作遇到的困难
严重依赖于监督学习过程,其需要大量的有标签数据来训练模型。对有标签数据的大量需求,阻碍了实践中的使用。
- 由于有标签数据采集过程十分耗时耗力,所以十分稀缺。
- 需要采集大量的数据,保证移动设备,用户,环境等足够充分,才可以获得泛化的模型。
文章意义
为了解决有标签数据的挑战,该篇文章提出了一种自监督表征学习模型,可以利用大量的无标签数据来提取泛化的特征。之后,task-specific模型可以使用少量的无标签数据进行训练。(两阶段)
文章挑战
需要从IMU数据中得到哪些一般特征?
- distributions of individual measurements of IMU sensors(IMU传感器的单个测量值的分布)
eg 当实验人员的活动由站立变为走路时,acc和gyr的测量值变大
- temporal relations in continuous measurements(连续测量值的时间关系)
eg 当设备方向变化时,加速度计的三轴分量的相关性不同。
如何从IMU数据中提取出如上的泛化特征?
本文设计了数据融合和归一化、有效的训练方法、结构优化等技术,并将其嵌入到BERT框架中。
PRELIMINARIES
Representation Learning
BERT是一种有效的自然语言处理(NLP)自监督学习模型,具有两个自我监督的任务:MLM和NSP。BERT 可以学习文本数据中的上下文关系,并据此为每个单词生成有效的嵌入。经过自监督的训练过程后,预训练的模型可以与fine-tune连接起来,通过监督训练来执行各种NLP任务。
受BERT的启发,采用一种类似Bert有效的自监督技术。作为时间序列类型的数据,IMU传感器数据也包含了丰富的上下文关系。从未标记的IMU数据中提取有效的表征,可以提高下游模型的性能,并且降低对标签数据的要求。
Uniqueness of IMU Sensing
为了设计LIMU-BERT,使预训练模型适用于IMU数据应用,将IMU数据进行可视化,并分析其特征,这些特征将作为后续的指导。
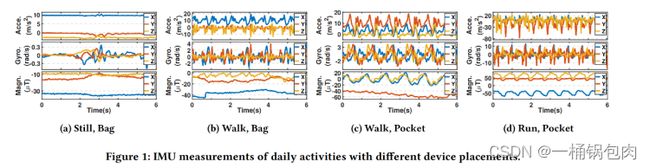
为了进行HAR和DPC两个任务,本文针对不同活动,传感器的不同位置进行了数据可视化,得出了以下三个方法指导:
Fusion matters
观察:在图(a)中,用户所处的状态是,将传感器放入包中,处于静止状态。观察到陀螺仪的数值波动很大,而加速度计的数值几乎不变。所以得出结论:陀螺仪对周围环境更加敏感。
如果仅使用陀螺仪数据,则环境噪声很多,难提取出高质量的表征。所以如果同时考虑加速度计数据和陀螺仪数据,将会削弱陀螺仪范围波动的影响。
结论:所以多个传感器的交叉引用可以提供更多信息并提高整体性能。
除此之外,考虑到多模态方向,表示学习模型应该支持多个IMU传感器的数据融合,所以在LIMU-BERT中应该考虑这个问题。
Distribution matters
观察:图(b),©,(d),可以观察到当用户走路时,陀螺仪读数在 (-5, 5) 范围内,而当用户跑步时,陀螺仪读数分布在-15到15之间。
在不同活动中,单个传感器的测量值的范围差异很大。(Range)
观察:图(b),©,可以观察到当设备放在包中,则 y 轴上的加速度计读数与其他两个轴相比读书都大,但当设备放在口袋中时,它们的相关性不同。
当设备放置不同时,每个传感器三轴读数之间的关系也会发生变化。(Relation)
结论:IMU读数的分布包含了丰富的信息,这是LIMU-BERT应该捕获的一个特征。所以如果我们想捕获一般特征,则任何可能会破坏分布信息的转换,都不应该应用。
Context matters(时间窗口?)
观察:图(a),由于人类活动很复杂,偶尔的波动是不可避免的。但是走路©和跑步(d)的数据有明显的周期性规律,这是区分它们与静止的特征,解释周期性的原因可以为步频等。通过观察用户在图1(b)和图1©中行走时的IMU读数,在口袋中的智能手机的读数有更显著的变化。这很可能是因为智能手机的方向随着腿的移动而经常改变。
结论:时间关系在IMU数据的表示学习中也起着重要的作用。
Potential Application
在该节中解释了为什么选择HAR和DPC两个任务。
DESIGN
总体设计
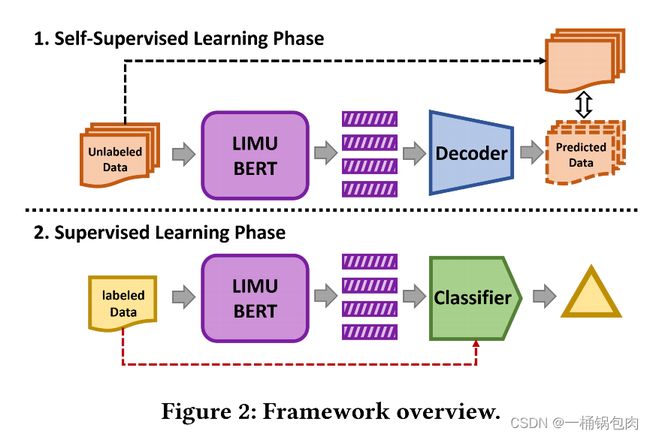
整个模型包括三个组件和两个阶段。
三个组件
LIMU-BERT:将未标记的IMU数据作为输入,并输出高级表示或特征。
Decoder:根据学习到的特征重构未标记的数据。
Classifier:用少量标记数据的表示训练的分类器,旨在完成特定于任务的应用程序,如HAR。
两个阶段
自监督阶段:在这一阶段,文章mask了未标记数据的部分读数,并将它们输入LIMU-BERT中。LIMU-BERT和解码器通过学习temporal relations共同预测被mask数据的原始值。自监督学习过程的目标是充分利用大量的未标记数据,并据此提取一般特征。
监督阶段:将LIMU-BERT与一个分类器连接起来。在这一阶段,LIMU-BERT的所有参数都被冻结,只有分类器使用由LIMU-BERT处理的有限标记表示进行训练。训练结束后,共同完成下游任务。
融合和归一化
⚠️:在该文章中将IMU数据看成是一维的数据。
归一化
- 为什么需要使用归一化:
LIMU-BERT需要处理多个传感器数据,然而这些数据的分布不同,这个差异将会影响模型的性能,所以需要使用合适的归一化方法处理多个传感器数据。
- 普通归一化方法的弊端
常用的归一化方法是min-max归一化或mean-variance归一化。除此之外,还可以使用data transformations进行归一化(应用傅里叶变换,用频域特征替换原始数据)。然而,这些方法会导致分布信息的损失,并可能对生成的一般特征造成负面影响。
- 归一化方法的要求
缩小不同数据之间的范围差异,而不严重改变其分布。
- 该文章采用的归一化方法
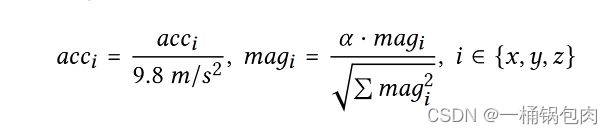
- 和分别表示加速度计和磁强计的轴上的测量值。
- 是一个对磁强计读数范围的权重比例,在LIMU-BERT中设置为2。
- 由于磁强计读数很容易受到环境的影响(如附近的电子设备),所以用自身的读数进行归一化,仍可以保证磁强计的三轴读数之间的关系。
- 对于陀螺仪读数来说,保持陀螺仪读数不变,因为它们本身是很小的值。
经过归一化后,所有数据的分布都在同一个范围中。
窗口
通过归一化得到的IMU数据需要通过固定的时间窗口进行划分,得到IMU Sequence。每个IMU Sequence ∈ R×。
- L是时间窗口的大小,每个IMU Sequence包含了L个归一化之后的IMU读数
- 是收集到的IMU特征的维度。比如在只有加速度计和陀螺仪数据的情况下,是6,因为每个传感器都是三维的。前三个特征对应于加速度计的三个轴,而后三个轴对应于陀螺仪的三个轴。
Projection
IMU传感器的一个关键特征是特征数量较少(eg 6)。为了扩展特征的尺寸以及融合多个IMU传感器数据,该论文将归一化的传感器数据 投影到了更高维度的空间。

Layer Normalazation
接下来,LIMU-BERT利用Layer Normalazation对相同测量时间对应的融合特征进行归一化。

(·)和(·)分别表示第列中(同一时刻)各元素的均值和方差。的值很小,和是超参数。通过学习归一化层的参数,神经网络可以实现动态化地对IMU传感器的隐式特征进行了基本的归一化。
学习表征
由Bert引申为LIMU-BERT
LIMU_BERT需要从IMU数据中提取到两方面的特征:单个数据的分布和连续数据之间的时间关系(在第一节文章挑战中提出,在第二节得到证实)。
考虑Bert的两个任务:
- MLM
MLM任务适用于IMU数据。原因是MLM任务mask数据序列的一些子序列,模型的任务是预测masked子序列,对IMU表示学习具有双重意图。首先,通过MLM任务,模型能够根据相应的表示重构掩码读数,这意味着LIMU-BERT学习到的特征必须包含分布的信息。其次,需要LIMU-BERT为掩蔽读数生成表示,这样的过程迫使它学习IMU数据中的上下文关系。总之,文章认为MLM有利于从IMU数据中提取出目标特征(分布 + 时序)。
- NSP
NSP任务并不适用于IMU数据,原因是由于人类日常活动的频繁转换,学习两个IMU序列是否存在前后续关系,并不会给模型带来很大的好处。
LIMU-BERT中的MLM任务
在原始Bert中,考虑到每个单词都有各自的语义,所以每次只mask一个token。然而,在IMU数据相邻的读数很相似,所以如果只mask一个sample,则模型很容易通过相邻的sample重建读数。所以在LIMU-BERT中mask较长的子序列,从而提供一个具有挑战性的条件,训练一个有效的模型。
根据以上分析,MLM任务的首要挑战是:确定mask子序列的长度。—— Span Masking

- 具体流程
- 确定一个IMU Sequence中整体被mask的长度
- 使用几何分布确定被mask的子序列长度
- 随机选择被mask的子序列起始位置,并根据长度确定终止位置
- 根据策略,mask子序列
- mask策略
由于输入数据在监督学习阶段没有被mask,所以全部mask会导致在两个学习阶段存在差异。为了解决这个问题,LIMU-BERT可以学习如何通过概率掩蔽来处理数据。所选读数的所有值有的概率被替换0,其余情况保持不变。
构建轻量级模型
- 降低采样频率
在原始的Bert中,最长序列的长度为512。假设时间窗口为6秒,且原始的采样频率为100HZ,则IMU Sequence为600。因此该文章采用了更小的采样率(即20Hz),并相应地减少了输入IMU序列的长度。广泛的实验表明 20 Hz对于我们的目标应用程序来说已经足够了。此外,由于IMU数据特征数量较少(eg 6),LIMU-BERT的表示维数小于原始BERT(如1024,也有助于缩小模型的尺寸。
- 共享参数
LIMU-BERT采用跨层参数共享机制[19],以提高了参数效率。LIMU-BERT由多个编码器层组成,其中只有第一个编码器层中的参数a 重新训练。第一层的参数与其他层共享。这一机制显著减少了LIMU-BERT的参数数量。
- 回归任务
该文章将IMU数据重构问题作为一个回归任务,而不是一个分类任务。因为IMU特征是连续的变量。而回归模型可以避免了大量的输出层,并大大简化了解码器。
LIMU-BERT设计(第一阶段)
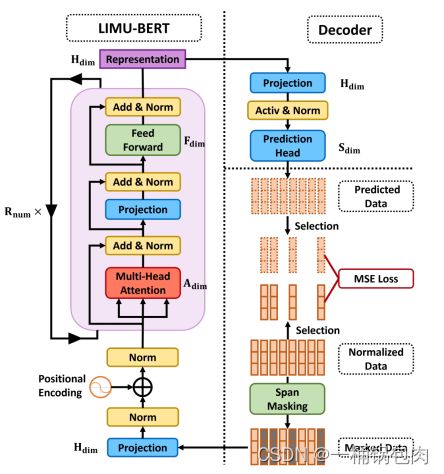
在该部分中,总结了以上所有的设计。该部分综合以上设计进行详细说明。
LIMU-BERT(自监督阶段)的目标是生成未标记IMU数据的泛化表示,它可以表述为:
![]()
(具体的模型详见论文)
分类器设计(第二阶段)
使用未标记数据对LIMU-BERT进行训练后,可以利用训练好的预训练模型来生成标记IMU数据的表示。基于学习到的数据表示及其对应的标签,对有监督模型进行训练。
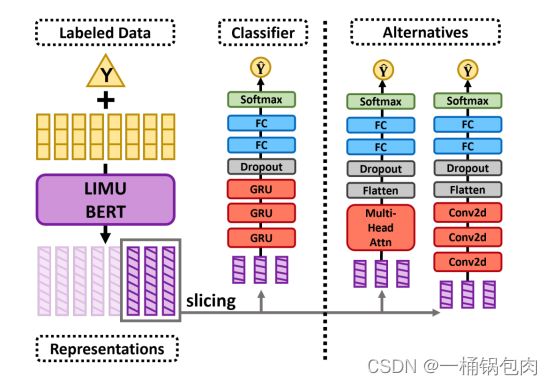
IMU数据在监督训练阶段没有被掩盖。并且可以分割对应的数据表征。分类器处理的IMU数据的长度记为。请注意,slice是一个可选的步骤。
在该文章中,使用了GRU作为分类器。(GRU具体设置详见论文)
分类器的其他选择:CNN,Multi-head Attention。
⚠️:在第二阶段,只有分类器的参数进行更新,LIMU-BERT的参数冻结。
EVALUATION
实验的准备工作
数据集
该论文使用了四个公开数据集进行实验,它们从实验人员数量、活动标签、传感器类别、设备类型、设备摆放位置和采样频率等之间存在差异。
| 数据集 | 实验人员数量 | 活动标签 | 传感器类别 | 设备类型 | 设备摆放位置 | 采样频率 |
|---|---|---|---|---|---|---|
| HHAR | 9 | 6 | A,G | 6种 | 腰部 | 100HZ - 200HZ |
| UCI | 30 | 6 | A,G | Samsung Galaxy S II | 腰部 | 50HZ |
| MotionSense | 24 | 6 | A,G | iPhone 6s | 前口袋 | 50HZ |
| Shoaib | 10 | 7 | A,G,M | 5种 | 5个位置 | 50HZ |
HHAR的6种活动:biking,sitting, standing, walking, upstairs, downstairs
UCI的6种活动:standing, sitting, lying, walking, walking downstairs, walking upstairs
MotionSense的6种活动:downstairs, upstairs, walking, jogging, sitting, standing
Shoaib的7种活动:walking, sitting, standing, jogging, biking, walking upstairs, walking downstairs
预处理
- 降采样
- 划分时间窗口
对于所有的数据集,该论文首先将样本降采样到20Hz,并将连续的IMU数据分割到长度为120次测量的窗口中。任何两个窗口之间都没有重叠。
- 划分数据集
我们将每个数据集随机分为训练集(80%)、验证集(10%)和测试集(10%)。将训练集进一步分为1%为标记集,99%为未标记集。labeling rate 为标记集的样本数与训练集的样本数的⽐值。默认为1%。
在该论文中的实验设置中,只有1%的标记样本被用于训练特定于任务的分类器,这模拟了只有有限标签可用的实际应用场景。
⚠️:在划分训练集时,确保每个类都有相同数量的标记样本。本文没有考虑类不平衡问题。因为作者认为,如果只需要少量的标记数据,那么类不平衡问题对特定于任务的分类器的影响是有限的。
Baseline
- LIMU-GRU
LIMU-GRU是一个基于该论文的框架实现的分类模型。使用LIMU-BERT提取出泛化的表示,之后使用GRU进行分类。
- DCNN
DCNN设计了一个基于CNN的深度模型,可以自动从原始IMU输入数据中进行特征学习,并优于许多传统的方法。为了使DCNN适应该论文的设置,稍微调整了输入层和输出层的大小。
- DeepSense
与其他模型不同,DeepSense对原始IMU数据应用傅里叶变换,并将频域特征(即幅度和相位对)提供给神经网络。它融合来自多个传感器的数据,并据此提取时间特征。由于DeepSense中的输入设置与该论文的不同,所以在DeepSense中使用较小的自适应(例如,较小的内核)来实现CNN。
- TPN
据该论文所知,TPN是唯一一项能够在训练特定任务模型之前从未标记数据中学习一般特征的研究。训练一个多任务时序CNN来识别应用于输入数据的几种转换。然后将CNN转移到HAR分类模型中。针对TPN,通过减少CNN层中的内核大小,使TPN适应窗口大小。
- R-GRU(有监督学习)
为了展示LIMU-BERT学习到的表示的有效性,我们实现了一个基线模型,直接将GRU分类器应用于原始IMU数据。
在HAR任务上的评估
overall
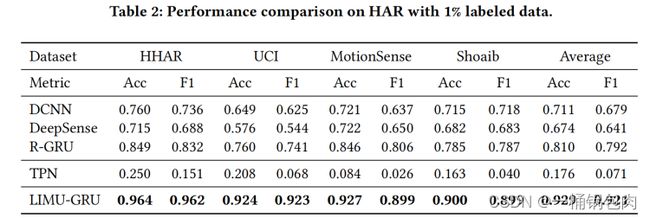
- 结果显示,LIMU-GRU在所有情况(不同数据集)下的表现都大大优于其他baseline线模型(至少10%),这证明了LIMU-BERT的有效性。一般来说,LIMU-GRU在所有数据集上都达到了接近0.90的acc和f1。
- DCNN和DeepSense的性能甚至比一个更简单的模型R-GRU更差。愿意可能是因为有标签数据过少,产生了过拟合问题。
- TPN的性能最差,可能是因为TPN没有被设计用于处理多模态数据。
- R-GRU和LIMU-GRU之间的性能差距清楚地表明,LIMU-BERT学习到的表征是有效的。
- IMU传感器的20Hz采样率已经为HAR任务提供了高性能。
labeling rate
在本实验中,研究了DCNN、DeepSense、R-GRU和LIMU-GRU在不同labeling rate下的性能,从0.2%到10%不等。
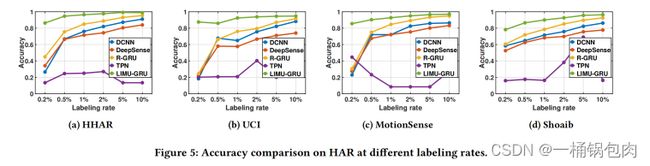
- 随着标记率的提高,大多数情况都能够实现更高的精度。结果显示,LIMU-GRU在所有情况下都始终优于baseline线水平。
- 当labeling rate较小时,LIMU-GRU与其他模型之间的性能差距越大。所有其他baseline的精度都只在0.5以下。
- 结果表明,LIMU-BERT能够有效地从未标记数据中学习一般的表示形式。下游的GRU分类器通过学习表示获得更高的精度。特别是当标记数据样本较少,性能增益显著。
sequence length
在DPC任务上的评估
该试实验将标记率从0.2%更改为10%,并将LIMU-GRU与其他baseline模型进行了比较。实验是在Shoaib数据集上进行的。
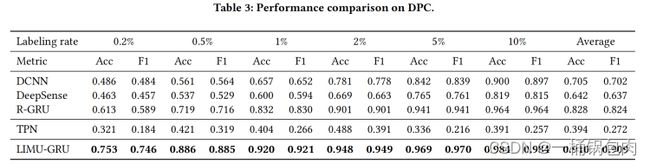
- 与HAR的情况类似,LIMU-GRU在所有情况下都优于所有基线模型。
- 当labeling rate较小时,性能越显著。
其他实验
Representation visualization
为了理解LIMU-BERT学习到的表示的有效性,采用t-SNE来在二维空间可视化学习到的高维表示。

- 这些聚类显示了在所有数据集中的学习表示之间的高度相关性。属于同一活动类的样本具有较高的聚类效应。
- 动态活动的表征(散步,慢跑,楼上,向下 楼梯等等)很可能会很接近,这些活动需要许多运动,从而引入IMU传感器数据的波动。
- 与其他关于活动标签的数据集相比,Shoaib数据的表示不那么集中。这主要是因为Shoaib数据集包含了设备放置的多样性,而学习到的表示包含了关于活动和设备放置的双重信息。
classifier

除了GRU之外,其他常用的神经网络组件也可以承接LIMU-BERT来进行任务分类器设计。
- GRU提供了最高的性能,且其他的替代方案也获得了相当好的性能。
- 结果表明,由LIMU-BERT产生的表征有利于许多神经网络模型的分类任务。它们的性能高于之前提出的所有baseline模型,这也证明了学习表征的可靠性。
sensors
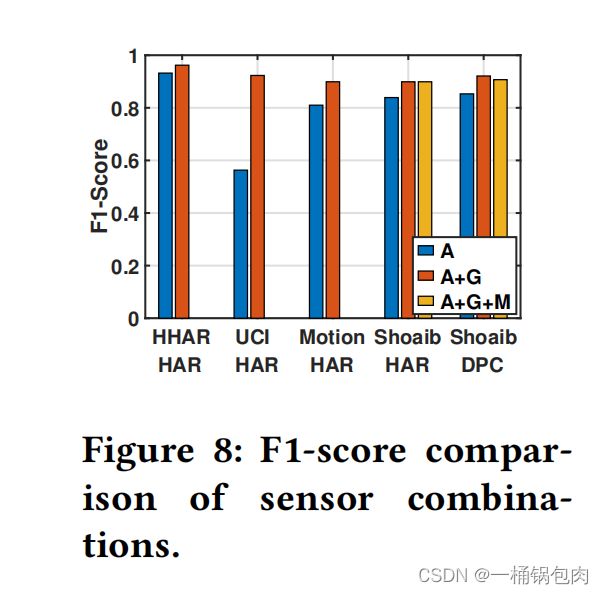
该实验研究了LIMU-BERT在不同的传感器组合上执行的性能差异,包括只提供加速度计读数,加速度计和陀螺仪读数的组合,以及所有的IMU传感器。
- 由陀螺仪读数引入的性能增益是显著的,特别是在UCI数据集中。原因是那个陀螺仪传感器可以提供关于移动设备的运动的更多信息。
- 另一方面,磁强计读数在我们的目标应用中并没有带来太多好处。可能的原因包括,它对设备的运动不像其他两个传感器那样敏感,而且它可能很容易受到环境的影响。但是磁强计读数并不会降低LIMU-GRU的性能。
- LIMU-BERT能够很好地处理多个IMU传感器。
normalization method
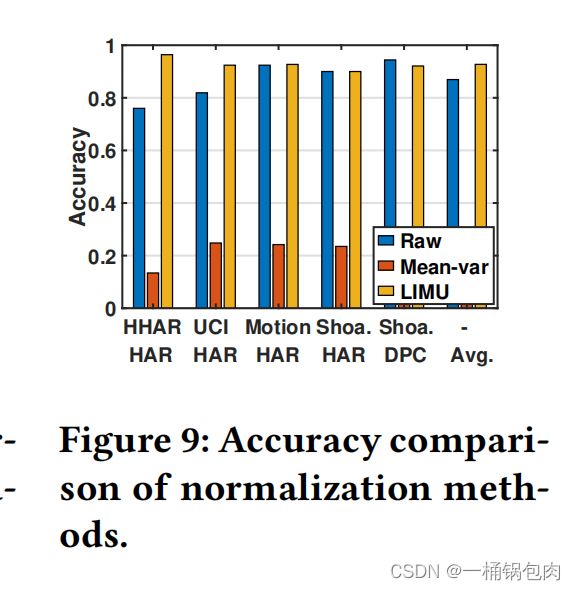
该实验评估了所提出的归一化方法的有效性。
- 我们发现,在motionsense和shoaib数据集中,输入原始数据可以获得与LIMU归一化方法相似的精度。然而,在其他情况下,其准确性显著下降,这表明原始数据的性能并不稳定。
- 对于均值-方差归一化方法,分类器不能从学习到的表示中提取有效的特征,因此精度非常低。破坏原始IMU数据的分布信息的归一化方法可能会导致性能下降。
- 相比之下,在LIMU-BERT中采用的归一化方法平均比使用原始数据高出5.78%,并达到了最高的总体精度。
masking approach
dataset
该实验研究了LIMU-BERT如何在不同的数据集上执行。eg。将在HHAR数据集上训练的LIMU-BERT应用于MotionSense。
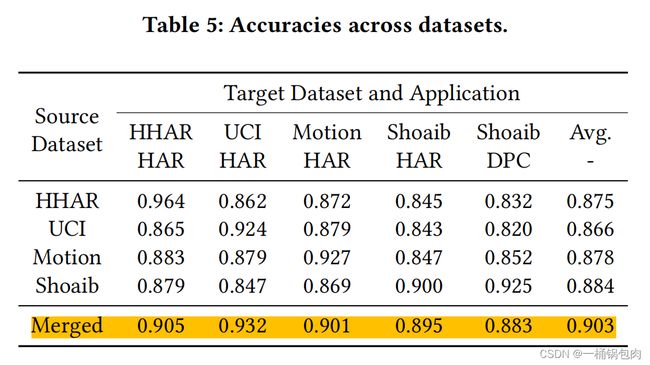
- 在所有数据集上训练的LIMU-BERT的平均精度都高于0.850,这表明LIMU-BERT生成的特征是可推广的,可以转移到不同的数据集。但是由于数据集的多样性,跨数据集情况下的性能会下降。
- 在合并数据集上训练的LIMU-BERT具有最好的性能,说明当在更广泛的未标记数据上训练时,LIMU-BERT能够更好地处理数据集的多样性和提取一般特征。
computation overhead
参考文献
- 为了利用大量的未标记数据,已经提出了更先进的模型[6,7,19,53]来从未标记的图像、视频或文本中提取表征。
[6] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. _arXiv preprint arXiv:1810.04805 _(2018).
[7] Basura Fernando, Hakan Bilen, Efstratios Gavves, and Stephen Gould. 2017. Self-supervised video representation learning with odd-one-out networks. In Proceedings of the IEEE conference on computer vision and pattern recognition. 3636–3645.
[19] Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. 2019. Albert: A lite bert for self-supervised learning of language representations. _arXiv preprint arXiv:1909.11942 _(2019).
[53] Xiaohua Zhai, Avital Oliver, Alexander Kolesnikov, and Lucas Beyer. 2019. S4l: Self-supervised semi-supervised learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 1476–1485.
- 多个传感器数据融合的重要性
[36] Muhammad Shoaib, Stephan Bosch, Ozlem Durmaz Incel, Hans Scholten, and Paul JM Havinga. 2014. Fusion of smartphone motion sensors for physical activity recognition. Sensors 14, 6 (2014), 10146–10176.
- 多模态传感器融合
[23] Shengzhong Liu, Shuochao Yao, Jinyang Li, Dongxin Liu, Tianshi Wang, Huajie Shao, and Tarek Abdelzaher. 2020. GIobalFusion: A Global Attentional Deep Learning Framework for Multisensor Information Fusion. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies 4, 1 (2020), 1–27.
[49] Jianbo Yang, Minh Nhut Nguyen, Phyo Phyo San, Xiaoli Li, and Shonali Krishnaswamy. 2015. Deep convolutional neural networks on multichannel time series for human activity recognition… In Ijcai, Vol. 15. Buenos Aires, Argentina,
[51] Shuochao Yao, Shaohan Hu, Yiran Zhao, Aston Zhang, and Tarek Abdelzaher.2017. Deepsense: A unified deep learning framework for time-series mobilesensing data processing. In Proceedings of the 26th International Conference onWorld Wide Web. 351–360.
- DPC任务使用场景
[5] Zhi-An Deng, Guofeng Wang, Ying Hu, and Di Wu. 2015. Heading estimation for indoor pedestrian navigation using a smartphone in the pocket. Sensors 15, 9 (2015), 21518–21536.
[50] Zhijian Yang, Yu-Lin Wei, Sheng Shen, and Romit Roy Choudhury. 2020. Ear-AR: indoor acoustic augmented reality on earphones. In Proceedings of the 26th Annual International Conference on Mobile Computing and Networking. 1–14.
- 使用data transformations进行归一化
[51] Shuochao Yao, Shaohan Hu, Yiran Zhao, Aston Zhang, and Tarek Abdelzaher.2017. Deepsense: A unified deep learning framework for time-series mobilesensing data processing. In Proceedings of the 26th International Conference onWorld Wide Web. 351–360.
- Layer Normalazation
[1] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. 2016. Layer Normalization. arXiv:1607.06450 [stat.ML]
- 采样频率
[8] Taesik Gong, Yeonsu Kim, Jinwoo Shin, and Sung-Ju Lee. 2019. Metasense: fewshot adaptation to untrained conditions in deep mobile sensing. In Proceedings ofthe 17th Conference on Embedded Networked Sensor Systems. 110–123.
[33] Aaqib Saeed, Tanir Ozcelebi, and Johan Lukkien. 2019. Multi-task self-supervised learning for human activity detection. Proceedings of the ACM on Interactive,Mobile, Wearable and Ubiquitous Technologies 3, 2 (2019), 1–30.
[51] Shuochao Yao, Shaohan Hu, Yiran Zhao, Aston Zhang, and Tarek Abdelzaher.2017. Deepsense: A unified deep learning framework for time-series mobilesensing data processing. In Proceedings of the 26th International Conference onWorld Wide Web. 351–360.
- 数据集
[40] Allan Stisen, Henrik Blunck, Sourav Bhattacharya, Thor Siiger Prentow,Mikkel Baun Kjærgaard, Anind Dey, Tobias Sonne, and Mads Møller Jensen.2015. Smart devices are different: Assessing and mitigatingmobile sensing heterogeneities for activity recognition. In Proceedings of the 13th ACM conference on embedded networked sensor systems. 127–140.
[32] Jorge-L Reyes-Ortiz, Luca Oneto, Albert Samà, Xavier Parra, and Davide Anguita. 2016. Transition-aware human activity recognition using smartphones.Neurocomputing 171 (2016), 754–767.
[25] Mohammad Malekzadeh, Richard G Clegg, Andrea Cavallaro, and Hamed Haddadi. 2019. Mobile sensor data anonymization. In Proceedings of the international conference on internet of things design and implementation. 49–58.
[36] Muhammad Shoaib, Stephan Bosch, Ozlem Durmaz Incel, Hans Scholten, and Paul JM Havinga. 2014. Fusion of smartphone motion sensors for physical activity recognition. Sensors 14, 6 (2014), 10146–10176.
- 类不平衡问题
[11] Nathalie Japkowicz and Shaju Stephen. 2002. The class imbalance problem: A systematic study. Intelligent data analysis 6, 5 (2002), 429–449.
- 其他对比的模型
[49] Jianbo Yang, Minh Nhut Nguyen, Phyo Phyo San, Xiaoli Li, and Shonali Krishnaswamy. 2015. Deep convolutional neural networks on multichannel time series for human activity recognition… In Ijcai, Vol. 15. Buenos Aires, Argentina,3995–4001.
[51] Shuochao Yao, Shaohan Hu, Yiran Zhao, Aston Zhang, and Tarek Abdelzaher.2017. Deepsense: A unified deep learning framework for time-series mobilesensing data processing. In Proceedings of the 26th International Conference onWorld Wide Web. 351–360.
[33] Aaqib Saeed, Tanir Ozcelebi, and Johan Lukkien. 2019. Multi-task self-supervised learning for human activity detection. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies 3, 2 (2019), 1–30.
- t-SNE
[42] Laurens Van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-SNE.Journal of machine learning research 9, 11 (2008).