SettingWithCopyWarning:A value is trying to be set on a copy of a slice from a DataFrame(Pandas库)
pandas警告SettingWithCopyWarning: A value is trying to ...原理和解决方案_Lucky0928的博客-CSDN博客 以下内容是对这篇文章的前半部分做一个学习记录,附加我自己的一点理解与尝试。
1 SettingWithCopyWarning
SettingWithCopyWarning仅仅是一个警告 Warning,而不是错误 Error。一般情况下它是不会影响程序的运行的,但是知道如何避免SettingWithCopyWarning是很有必要的。
2 Pandas操作返回类型
Pandas中的一些操作会返回原数据,另一些操作会返回数据的副本(Copy)。
比如说我们要提取额下面DataFrame里面第一行和第二行的数据,A.loc[0:1,'A':'B']。数据有两种返回方式,一是左边的df2直接选中df1中的部分数据,二是右边的df2不对原数据df1进行修改,独立返回了一个copy。
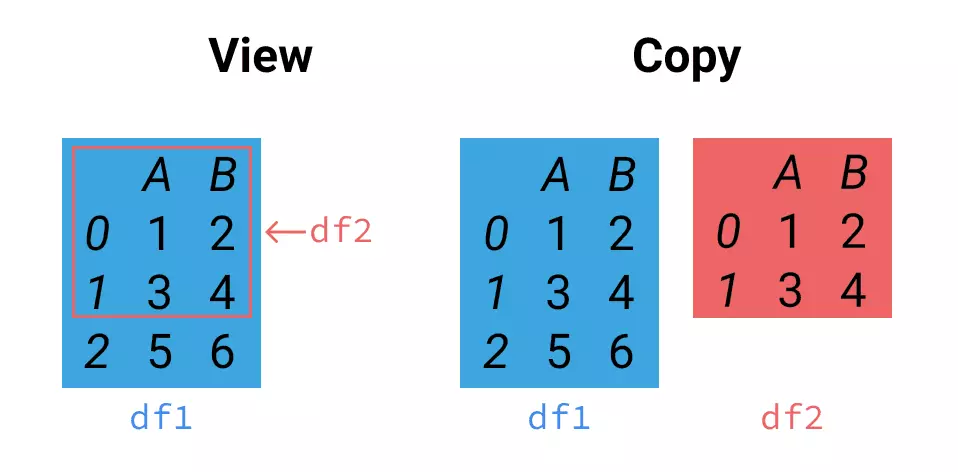
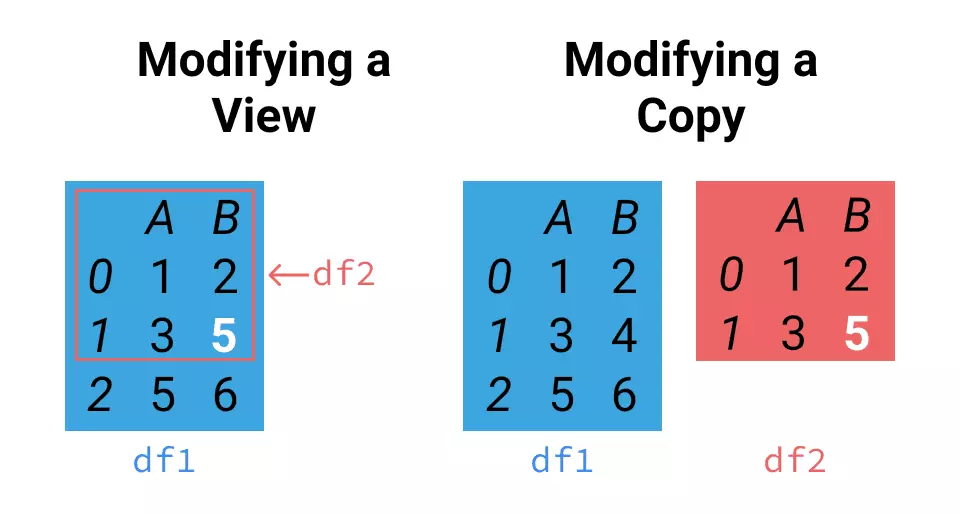
当我们再次要对返回的内容操作,比如说要把第1行第B列的数据改成5时,A.loc[0:1,'A':'B']['B'][1]=5,这时计算机不知道到底是修改左边的df2呢还是右边的df2。
3 链式索引
SettingWithCopyWarning提示的后面还有让我们去看一个文件,里面的大致意思是引起警告的原因是我们使用了链式索引。链式索引是指连续使用多个索引操作,例如A[A.b==2]['c']。
import pandas as pd
A=pd.DataFrame({'a':[1,2,3],'b':[2,2,4],'c':[2,2,5]})
print(A)
#OutA: a b c
# 0 1 2 2
# 1 2 2 2
# 2 3 4 5
print(A[A.b==2])
#Out: a b c
# 0 1 2 2
# 1 2 2 2
A[A.b==2]['c']=5
#:1: SettingWithCopyWarning:
#A value is trying to be set on a copy of a slice from a DataFrame.
print(A)
#OutA:a b c
# 0 1 2 2
# 1 2 2 2
# 2 3 4 5
#再次查看A,发现A确实没有修改这次警告是因为A[A.b==2]['c']是链式索引,简单的说该命令直接使用了两次方括号索引。
第一次索引先执行A[A.b==2],返回了一个DataFrame(不知道是会返回原数据A,还是返回A的副本B);第二次索引['c']=5是找到上一步得到的DataFrame的c列对该列赋值。
但是计算机很困惑,第一步的确生成了一个DataFrame,但是第二次修改到底是修改原数据A还是A的副本B?
从再次查看A可知第二次的赋值并没有修改原始的A,只是对A的副本B进行赋值。这种情况对应的解决方案很简单:使用loc或者iloc函数将两次链式操作简化为一步操作,确保第一次索引返回的是A。如下可以看出A被修改了
A.loc[A.b==2,'c']=4
print(A)
#Out: a b c
# 0 1 2 4
# 1 2 2 4
# 2 3 4 5
除了两次方括号索引这样明显的链式索引,还有比较隐蔽的链式索引
import pandas as pd
A=pd.DataFrame({'class':[1,2,3],'name':[2,2,4],'grade':[2,2,5]})
print(A)
#Out: class name grade
# 0 1 2 2
# 1 2 2 2
# 2 3 4 5
B=A.loc[A.name==A.grade]
print(B)
#Out: class name grade
# 0 1 2 2
# 1 2 2 2
B.loc[0,'class']=2
print(B)
#SettingWithCopyWarning:A value is trying to be set on a copy of a slice from a
#Out: class name grade
# 0 1 2 2
# 1 2 2 2
这次使用了loc函数,依然出现了警告。因为虽然把链式索引分成了两个代码,但是B变量它依然可能是原始数据A的副本,也可能是原始数据A。这意味着当我们尝试修改B时,可能也修改了A。这种情况下的警告解决方案是:创建新数据B时明确告知 Pandas 创建一个副本.copy():
import pandas as pd
A=pd.DataFrame({'class':[1,2,3],'name':[2,2,4],'grade':[2,2,5]})
print(A)
B=A.loc[A.name==A.grade].copy()
B.loc[0,'class']=2
print(B)
#Out:class name grade
# 0 2 2 2
# 1 2 2 2