介绍几个语言生成的预训练模型

作者 | Chilia
哥伦比亚大学 nlp搜索推荐
整理 | NewBeeNLP
大家好,这里是NewBeeNLP。本篇介绍四个为语言生成设计的预训练模型 -- BART,MASS,PEGASUS,UniLM。其中前三种方法都使用了Transformer Encoder-Decoder结构,UniLM只使用了Transformer Encoder结构。本篇只介绍基本思想和预训练任务,具体的实验结果和分析请自行查看原论文。
1.BART
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
https://aclanthology.org/2020.acl-main.703.pdf
BERT等预训练语言模型主要应用于文本理解(NLU), 而在文本生成任务(NLG)中表现不佳 -- 这主要是由预训练阶段和下游任务阶段的差异造成的。因此,BART提出了一种 符合生成任务的预训练方法。
BART的全称是Bidirectional and Auto-Regressive Transformers,顾名思义,就是兼具上下文语境信息(双向)和自回归(单向)特性的Transformer。BART其实并不是一个新的模型,因为它使用的结构还是传统的Seq2seq Transformer;它是一种针对生成任务而设计的预训练方法。
1.1 BART和GPT、BERT的区别与联系
BART预训练任务和GPT、BERT的对比如下图:
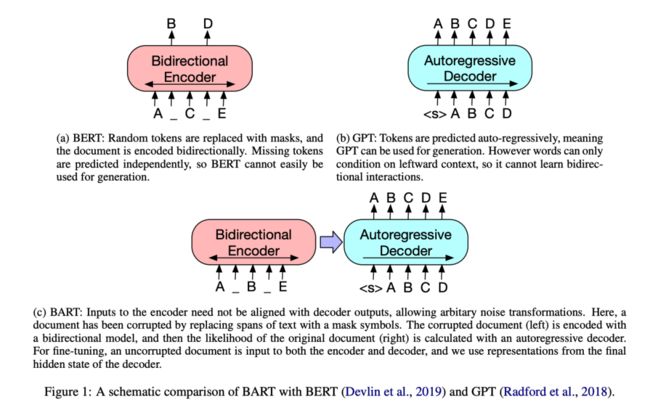
BERT: 只有Transformer Encoder部分,随机MASK掉一些token,然后利用上下文还原。
GPT:只有Transformer Decoder部分,采用自回归的方法训练,每个位置只能关注到其左边的token。
BART:使用了完整的Transformer(Encoder+Decoder)。其encoder端的输入是加了噪音的序列,decoder端的输入是right-shifted的序列,decoder端的目标是原序列。模型设计的目的很明确,就是在利用encoder端的双向建模能力的同时,保留自回归的特性,以适用于生成任务。
1.2 BART使用的noise
相对于BERT中单一的noise类型 (只有简单地用[MASK] token进行替换这一种noise),BART在encoder端尝试了 多种更加灵活的noise (甚至可以改变序列的长度)然后decoder端试图恢复这些noise。这样做是因为:BERT的这种简单替换导致的是encoder端的输入携带了有关序列结构的一些信息(比如序列的长度等信息),而这些信息在文本生成任务中一般是不会提供给模型的。相比而言,BART采用更加多样的noise, 意图是破坏掉这些有关序列结构的信息 ,防止模型去依赖这样的信息。
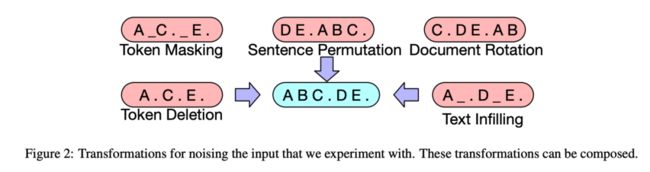
BART采用的一些noise包括:
Token Masking : BERT的方法--随机将token替换成[MASK] -> 训练模型推断单个token的能力
Token Deletion : 随机删去token -> 训练模型推断单个token_及其位置_的能力
Text Infilling : 随机将一段连续的token(称作span)替换成[MASK],span的长度服从 \lambda=3 的泊松分布。注意span长度为0就相当于插入一个[MASK]。这个方法带来了更多的 灵活性 !->训练模型推断一个span对应多少token的能力
Sentence Permutation : 将一个document的句子打乱。->类似BERT中的 NSP 目标,训练模型推断不同句子之间关系的能力
Document Rotation : 从document序列中随机选择一个token,然后使得该token作为document的开头。->训练模型找到document开头的能力
这些noise变换方式还可以组合,带来了更多的灵活性。
1.3 BART在下游任务的应用
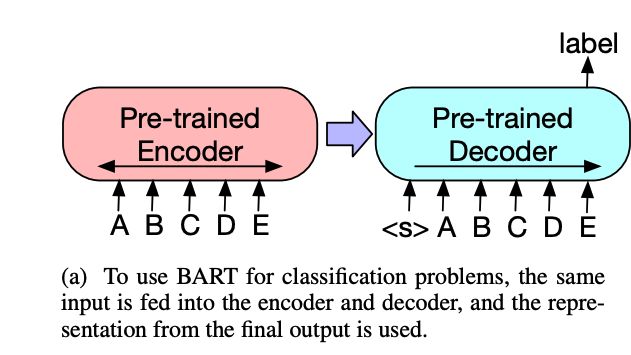
① Sequence Classification
将该序列同时输入给encoder端和decoder端,然后取decoder最后一个token对应的final hidden state表征。注意我们需要在decoder端序列末尾增加一个[EOS],让它能够关注到整个句子。
② Token Classification
将该序列同时输入给encoder端和decoder端,使用decoder的final hidden states作为每个token的表征
③ Sequence Generation
由于BART本身就是在sequence-to-sequence的基础上构建并且预训练的,它天然比较适合做序列生成的任务,比如生成式问答、文本摘要、机器对话等。encoder就是输入的序列,decoder用自回归的方法生成输出序列
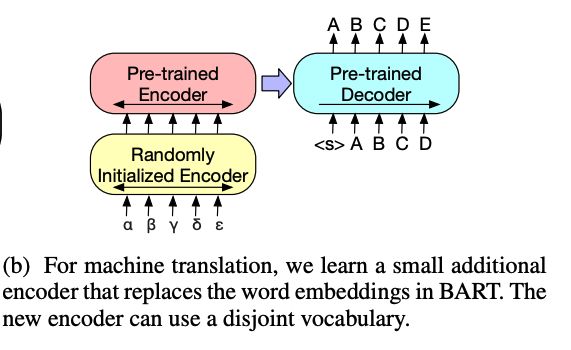
④ Machine Translation
BART能够提升其他语言 翻译到英语 的效果。具体的做法是将BART encoder端的embedding层替换成随机初始化的encoder, 新的encoder也可以用不同的vocabulary 。通过这个新加的encoder,我们可以将新的语言映射到BART能解码到English(假设BART是在English的语料上进行的预训练)的空间。具体的finetune过程分两阶段:
第一步冻结大部分参数,只更新新加的encoder + BART positional embedding + BART的encoder第一层的self-attention 输入映射矩阵。
第二步更新全部参数,但是只训练很少的几轮。
2. MASS
Masked Sequence to sequence pre-training for Language Generation
https://arxiv.org/pdf/1905.02450.pdf
和BART类似,MASS也是使用完整的Transformer结构,并且对encoder输入进行一些破坏,让decoder试图还原之。MASS的提出早于BART,因此它提出的noise方法也没有BART那么丰富。具体做法就是mask掉句子的一部分,再用decoder去预测之,如下图所示:
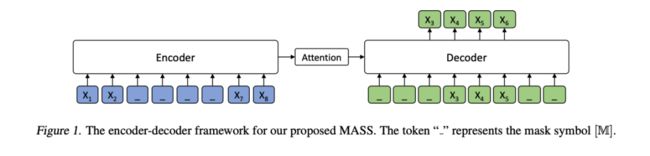
和BART不同的是,这里的decoder只输入应该被预测的token,这是为了可以让decoder依赖于encoder的编码,让两者更好地共同训练。
BERT的MLM预训练任务和GPT的自回归生成任务,分别是MASS k = 1 和 k = m 的特例:

3. Pegasus
PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization
https://arxiv.org/abs/1912.08777
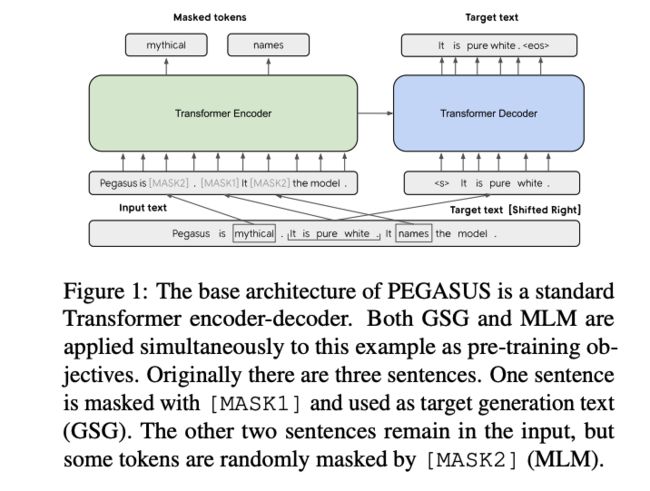
PEGASUS是专门针对 生成式摘要 设计的预训练模型。基本思想就是将输入文档的重要句子remove/mask,然后通过其他句子预测它们。其实验效果刷新了12项summarization任务;在low-resource摘要方面展现惊人性能,仅用了1000个example就超过了6个数据集上的最新结果。
3.1 Gap Sentences Generation (GSG)
我们知道,预训练目标与下游任务越接近,下游任务就会表现越好。那么,为了更好的完成文本摘要,可以mask掉文本中重要的一些句子,然后 拼接 这些gap-sentences形成伪摘要。相应位置的Gap-sentences用[MASK1]来替换。Gap sentences ratio(GSR)表示选中的gap sentences占总文档的比例。选择Gap Sentence的方法有:
Random: 随机选m个句子
Lead: 选前m个句子
Principal: 选最重要的m个句子。如何衡量句子的重要性呢?文中又提出了四种方法:
① 独立选择(Ind.)/连续选择(Seq.): 句子重要性可根据一个句子与其它句子集的ROUGE1-F1来计算,其公式为 , 独立选择就是选择得分最高的m个句子;连续选择则是贪婪地最大化选中句子集S\cup\{x_{i}\}与其余句子集 的ROUGE1-F1值,具体算法如下:

② 计算ROUGE1-F1的方式也可分为两种 -- Uniq 和 Orig。Uniq把n-gram当成集合处理(去重);Orig则允许重复n-gram出现。
因此,Ind/Seq 和 Uniq/Orig两两组合可得到四种方式。最后的实验结果表明,选择了文档30%的句子作为Gap sentences,用Ind-Orig选重要句子效果最好。
3.2 预训练任务
本文MASK的方式有两种:
① MLM:选择输入文本的15%的tokens, 其中80%的被替换为[MASK2]、10%的被随机的token替换、10%未发生变化。在encoder部分恢复这些token。
② GSG:以[MASK1]去mask选中的重要句子,在decoder部分恢复这些句子。
最终实验表明,仅采用MLM效果最差,预训练在100-200K steps时,GSG+MLM的效果在提升,但之后包含MLM效果在下降。因而最后PEGASUS-LARGE仅采用GSG,PEGASUS-BASE采用GSG+MLM。
4. UniLM
Unified Language Model Pre-training for Natural Language Understanding and Generation
https://arxiv.org/abs/1905.03197
UniLM是一种简洁的预训练方法,其模型的框架与BERT一致,是由一个多层Transformer Encoder网络构成;但训练方式不同,它是通过联合训练三种不同目标函数得到 -- 通过控制mask来控制预测单词的 可见上下文词语数量 ,在同一个模型中同时实现了bidirectional, unidirectional和seq2seq prediction 三种任务,因此可以同时用于语言生成和语言理解。
模型的三种预训练目标如下图所示:

seq2seq task在pretrain过程中,mask token可以出现在第一个文本序列中、也可以出现在第二个文本序列中;但是到了fine-tuning阶段时,mask token仅出现在第二个文本序列中。
Bidirectional LM: 跟Bert模型一致。同时,与bert模型一样,也进行NSP任务的预测。
Left-to-Right LM: 有从右到左和从左到右两者,类似GPT。
Seq2seq LM :如果[Mask]出现在第一段文本中,仅可以使用第一段文本中所有的token进行预测;如果预测[Mask]出现在第二段文本中时,可以采用第一段文本中所有的token,和第二段文本中左侧所有token预测。这种方法虽然不是seq2seq,但是通过mask可以做到seq2seq同样的效果。
综上,就是对于不同的语言模型,我们可以仅改变self-attention mask,就可以完成multi-task联合训练。
在预训练时的一个batch中,使用1/3的数据进行bidirectional task,1/3的数据进行seq2seq task,1/6的数据进行left-to-right unidirectional task,1/6的数据进行right-to-left unidirectional task。
模型结构与BERT-large模型一致(layer = 24, hidden_size = 1024, head = 16),约有340M参数,并由训练好的BERT-large模型进行初始化。MASK的概率为15%,在被掩掉的token中,有80%使用[MASK]替换,10%使用字典中随机词进行替换,10%保持越来token不变(这与BERT一致)。此外,在80%的情况下,每次随机掩掉一个token,在剩余的20%情况下,掩掉一个二元token组或三元token组。
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)

本文参考资料
[1]
潘小小:【论文精读】生成式预训练之BART: https://zhuanlan.zhihu.com/p/173858031
[2]李rumor:BERT生成式之MASS解读: https://zhuanlan.zhihu.com/p/67687640
[3]Espersu:PEGASUS模型:一个专为摘要提取定制的模型: https://zhuanlan.zhihu.com/p/214195504
[4]刘聪NLP:UniLM论文阅读笔记: https://zhuanlan.zhihu.com/p/113380840
