干货!深度学习加速综述:算法、编译器、体系结构与硬件设计
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
转载于 :meton
知乎链接:https://zhuanlan.zhihu.com/p/101544149
概述
NeurlPS2019 大会的「Efficient Processing of Deep Neural Network: from Algorithms to Hardware Architectures」的演讲概括性地介绍了目前深度学习加速领域的进展,看后觉得这个演讲的逻辑清晰,于是想结合演讲ppt内容和近期调研的一些加速器相关内容,总括性地理一下深度学习加速领域的内容。首先关于深度学习加速,一般会想到的就是关于深度学习加速器的硬件设计,但其实更宽泛地讲,从算法顶层,到编译器,到体系结构,硬件最底层都有涉及。下面的介绍也大致围绕这几个方面展开。(有新的东西会继续往上加,长期更新)
目录
1.算法顶层
大规模分布式机器学习(并行模式、调度模式、更新策略)
优化算法
轻量级网络设计
神经网络架构搜索
量化与剪枝
卷积运算的优化
2.深度学习编译器
需求与痛点
TVM
Pytorch Glow
Tensorflow XLA
3.体系结构与硬件设计
关注指标
CPU和GPU平台与其设计考量
Domain-Specific 硬件设计
设计关注点
深度学习应用数据重用机会
两类设计范式:Temporal Arch. 与 Spatial Arch.
加速器设计可以利用的特性(稀疏、低精度、压缩)
一些经典的加速器设计案例分析(DianNao、PuDiannao、TPU、Eyeriss)
1. 算法顶层
算法顶层在深度学习加速的工作也囊括了很多方面,例如:更好的分布式训练调度(大规模分布式机器学习系统),更好的优化算法,更简单高效的神经网络结构,更自动化的网络搜索机制(神经网络架构搜索NAS), 更有效的网络参数量化剪枝算法、卷积运算的优化等等。
1.1. 大规模分布式机器学习
这方面主要是分布式系统的一些设计。现在的网络模型越来越大,为了达到好的拟合效果,许多公司需要用极大的数据量喂给模型训练,这些数据往往单机都塞不下,而要一个batch一个batch慢慢给可能要训练到猴年马月,因此才需要大规模分布式机器学习系统。

下面内容先概括:
并行方式有数据并行和模型并行
调度方式有集中式(参数服务器)和去中心化调度(RingAllReduce)
参数更新方式有同步和异步两种,从另外角度分的话有基于参数的,有基于梯度方式的
分布式机器学习系统的并行加速本质上是就是DLP的多机延伸,具体来说其并行的方式分为两种:
数据并行
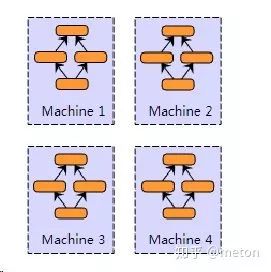
顾名思义就是每台机器都有模型的副本,但是将数据的不同部分分别喂给各个模型(各个机器), 最后的结果以某种方式进行合并(可能是直接参数融合,也可能是传递梯度数据进行融合)。数据并行是最常见也是最直观可以理解的。
模型并行
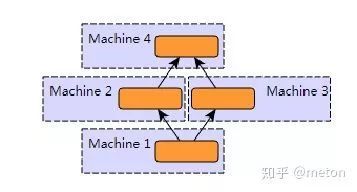
模型并行的话,就是模型本身太大了,因此需要将模型各个部分分散在各个机器间,这种情况在更新参数时需要层间跨机器通信。
两者结合

当然实际上还会有数据并行和模型并行的结合,可以从这个角度理解: 模型各个部分分散在单机的多个GPU中(模型并行),同时模型在多个机器都有副本,数据各个部分分别喂给各个机器并行训练(数据并行)。
上面介绍的是并行的方式,那么在实际分布式训练中是怎么进行训练的调度呢?调度方式主要分为集中式调度 和 去中心化调度,前者代表有Parameter Server方式,后者代表有Ring Allreduce方式。
Parameter Server
参数服务器是一种集中式的架构,有专门的机器用于存放全局参数,其他的worker用于训练!那么怎么更新呢?
一种方法是参数平均,这是一种同步方式!
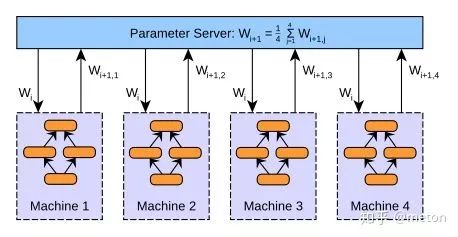
这种方式下,参数服务器每次将全局参数分配到各个worker,worker们每次迭代更新了参数后再汇集到参数服务器求平均得到这一轮的结果,之后再重复上述步骤直到收敛,是不是很简单!然而实际在工程上要考虑更多!例如,由于参数服务器要等待所有worker的参数到来后才可以操作(同步方式),那么如果有worker发生故障呢?如果worker每一次迭代就发参数给参数服务器,那么通信可能会成为瓶颈,而我们知道,计算比重 要大于传输比重,才有收益,所以可能需要考虑在worker那边多做几轮迭代后再给参数服务器更新,减少通信开销。诸如此类的衡量还有很多。
另一种就是基于梯度的方式,worker不是发送本地更新后的参数给参数服务器,而是发送梯度数据,参数服务器汇总的是梯度,然后在那边统一进行梯度更新。这也是一种同步更新的方式!两种方式似乎大同小异,但是由于梯度的稀疏特性,在通信前可以利用压缩算法来减少传输开销。

参数平均和基于梯度的方式本质上都是同步更新方式,有同步就有异步方式(基于梯度的方法本身可以做成异步更新的方式)。异步是说参数服务器不再等待最后一个worker才开始操作,而是有worker的参数到了,我这边就开算,不进行等待。那么两种更新方式的区别是啥?
同步方式: 有较大通信开销和同步等待开销,但是优点是收敛过程比较稳定。
异步方式: 速度快,高吞吐,等待时间少。但是噪声更大,有参数过期问题,所以收敛过程没有前者稳定。

Ring AllReduce
这种调度方式是与Parameter Server相反的方式,体现了设备去中心化思想。集中式调度容易管理,但是随着worker数目增加,master的负担越来越大,加速比也急剧恶化。

而 Ring AllReduce可以将参数通信分散到各个GPU,经过一循环的数据传递和计算后,得到正确结果。通过Ring AllReduce这种比较巧妙的方式,每个设备的负载更加均衡,基本上可以实现当GPU并行卡数的增加,实现计算性能的线性增长。一些相关的分布式训练库: horovod baidu-allreduce

关于大规模分布式机器学习系统先介绍到这里,以后再细讲。之前看过一本相关书籍《分布式机器学习:算法、理论与实践》,感觉不错,感兴趣可以参考一下。
1.2. 优化算法
深度学习的优化算法我觉得也可以算入深度学习加速的范畴,因为各式各样的优化算法(SGD,Adagrad,Adadelta,RMSprop,Momentum,Adam,Adamax,Nadam)的目标都是使得梯度下降搜索的时候可以更加趋近全局最优,使得收敛的速度更快,从而加速训练进度。当然,优化算法在分布式机器学习系统上需要实现其相应的分布式的版本,各类优化算法在分布式系统的参数更新方式上可以玩出很多花来。
1.3. (轻量级)高效的神经网络结构
由于神经网络对于噪声不敏感,所以许多早期经典模型的参数其实是存在很大冗余度的,这样的模型很难部署在存储有限的边缘设备,因此学术界开始追求一些轻量级的网络设计(这代表着更少的参数,更少的乘法操作,更快的速度):
减小卷积核大小
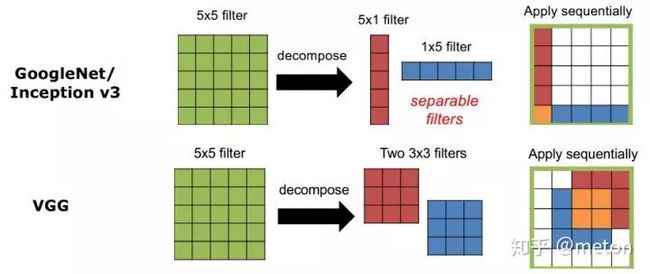 主要的做法包括使用更小的3x3卷积(加深网络来弥补感受野变小);将大卷积核分解成一系列小的卷积核的操作组合。
主要的做法包括使用更小的3x3卷积(加深网络来弥补感受野变小);将大卷积核分解成一系列小的卷积核的操作组合。
减少通道数
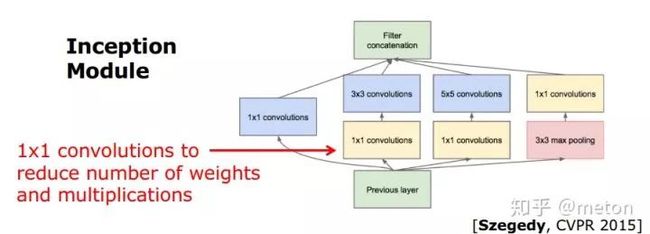
第一种方式:1x1卷积的应用。在大卷积核前应用1X1卷积,可以灵活地缩减feature map通道数(同时1X1卷积也是一种融合通道信息的方式),最终达到减少参数量和乘法操作次数的效果。

第二种方式:group convolution,将feature map的通道进行分组,每个filter对各个分组进行操作即可,像上图这样分成两组,每个filter的参数减少为传统方式的二分之一(乘法操作也减少)。

第三种方式:depthwise convolution,是组卷积的极端情况,每一个组只有一个通道,这样filters参数量进一步下降。

如果只采用分组卷积操作,相比传统卷积方式,不同组的feature map信息无法交互,因此可以在组卷积之后在feature map间进行Shuffle Operation来加强通道间信息融合。或者更巧妙的是像Pointwise convolution那样将原本卷积操作分解成两步,先进行 depthwise convolution,之后得到的多个通道的feature map再用一个1X1卷积进行通道信息融合,拆解成这样两步,卷积参数也减少了。
减少filter数目
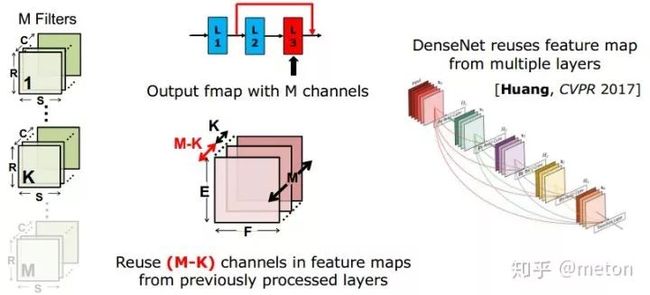
直接减少的filter数目虽然可以减少参数,但是导致每层产生的feature map数目减少,网络的表达能力也会下降不少。一个方法是像DenseNet那样,一方面减少每层filter数目,同时在每层输入前充分重用之前每一层输出的feature map。
池化操作
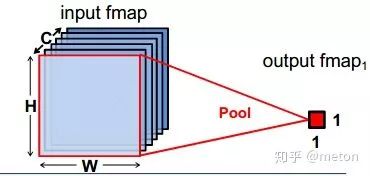
池化操作是操作卷积神经网络的标准操作,池化层没有参数,同时又可以灵活缩减上一级的feature map大小,从而减少下一级卷积的乘法操作。
1.4. 神经网络架构搜索
1.3节所介绍的那些高效的神经网络结构本质上是人工精心(费力)设计的结构,而神经网络架构搜索NAS则是将神经网络设计探索这个过程自动化。
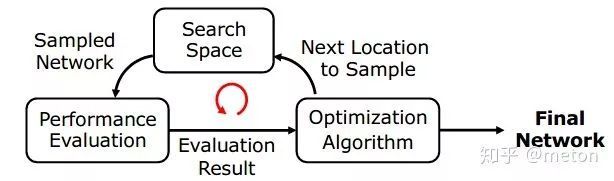
NAS主要包括三个主要的components:
搜索空间:搜索空间的每个样本就是一种神经网络设计架构
优化算法:如何进行采样得到一种网络设计
性能评价:用什么指标评价采样出来的网络设计,评价的结果反过来指导优化算法的采样。通常的指标是DNN的accuracy和所需的搜索时间。
优化总搜索时间可以从缩小搜索空间、提升优化算法和简化性能评价指标三部分入手:
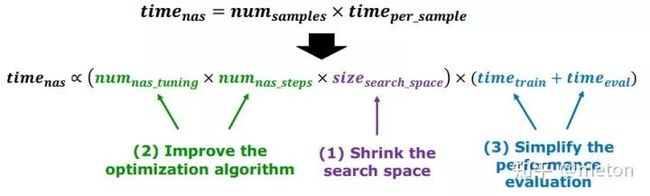
缩小搜索空间

可以通过增加一些搜索约束来减少探索空间,例如 权衡架构的宽度;放低所要达到的性能目标;结合domain knowledge,通过现有的人工设计经验来缩小探索范围。下面是一种搜索的例子,将设计空间设定为 layer operations和 layer connections的不同组合,然后NAS系统在人工设计的几种选择组合选项中进行搜索:


提升优化算法
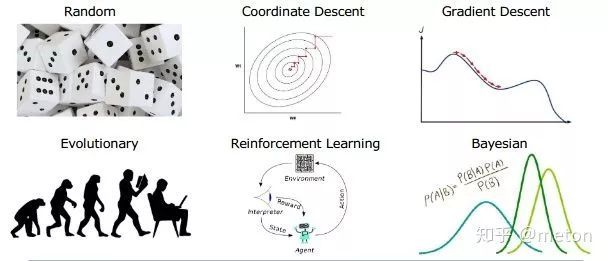
关于如何用一种比较好的启发算法从搜索空间采样出网络设计,NAS + 以前优化领域那一系列智能算法又可以玩出各式花样来,遗传算法、模拟退火、粒子群、蚂蚁算法...等等都有相关的结合工作。
简化性能评价
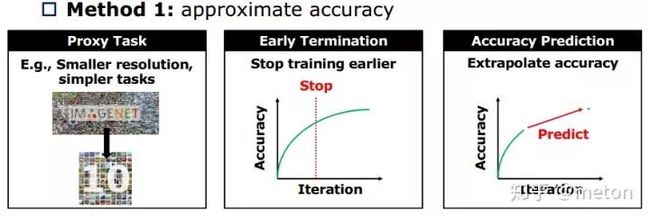
先在小型轻量级的数据集训练和快速验证,观察验证集精度曲线决定是否早期停止等等,这些经常使用的训练技巧在NAS上也同样适用。
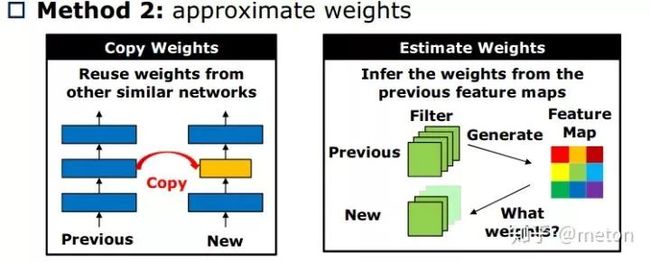
基于历史搜索经验来减少一些无意义的探索
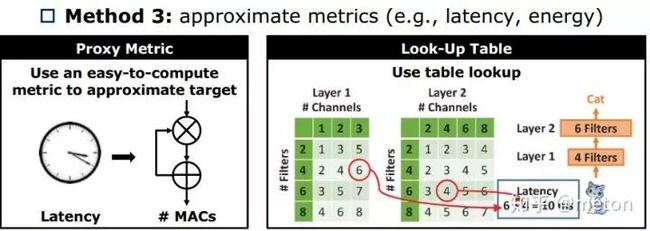
估算搜索出来的网络架构的参数,由此推算该网络的乘加操作次数,如果超出了设定的约束范围,那么可以间接预估出该网络架构过于复杂,不符合要求,那么直接丢弃这个设计,连训都不用训。另外可以建立查找表记录各个搜索出来的网络架构的时间,根据表中信息,可以推算出新网络架构的时间。
1.5. 网络量化剪枝
什么是量化
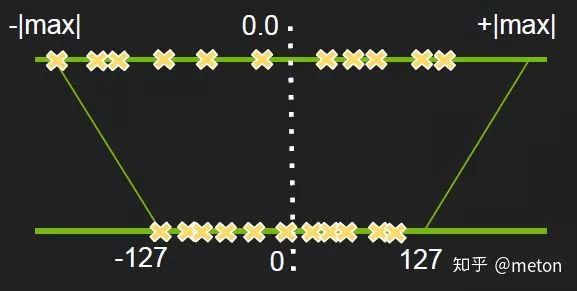
根据上图,最简单的理解方式就是:统计网络权重和激活值的取值范围,找到最大值最小值后进行min-max映射把所有的权重和激活映射到到INT8整型范围(-127~128).
量化为什么有效

首先量化会损失精度,这相当于给网络引入了噪声,但是神经网络一般对噪声是不太敏感的,只要控制好量化的程度,对高级任务精度影响可以做到很小。
其次,传统的卷积操作都是使用FP32浮点,浮点运算时需要很多时间周期来完成,但是如果我们将权重参数和激活在输入各个层之前量化到INT8,位数少了乘法操作少了,而且此时做的卷积操作都是整型的乘加运算,比浮点快很多,运算结束后再将结果乘上scale_factor变回FP32,这整个过程就比传统卷积方式快很多。
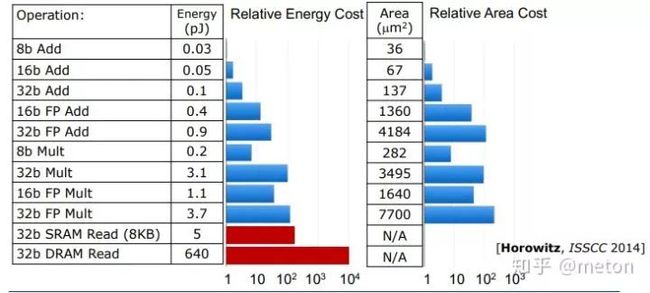
提前从体系结构的考量角度思考量化带来的另一个好处是节能和芯片面积,怎么理解呢?每个数使用了更少的位数,做运算时需要搬运的数据量少了,减少了访存开销(节能),同时所需的乘法器数目也减少(减少芯片面积)。

量化的一些其它考量
上面举的例子都是INT8量化,实际上要根据设备的支持情况以及应用的性能要求选择INT32、INT16、 INT8量化。
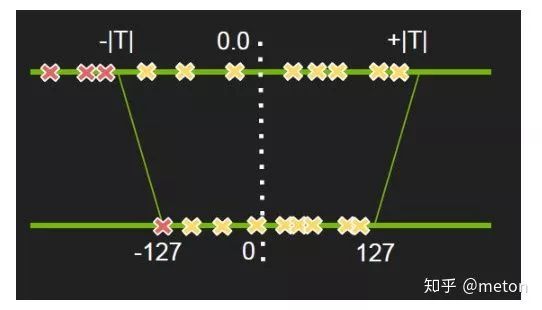
单纯使用min-max映射可以将分布均匀的浮点数映射到INT8空间,但是如果权重和激活比较多地集中在0.0以上,只有小部分落在负数,那么此时min-max映射后许多数也会集中在INT8某个小范围,那么INT8宝贵的动态范围就被浪费了,因此我们需要选择一个合适的阈值对激活和权重的范围进行裁剪,NIVDIA在实际操作中是根据KL散度来选择出这个裁剪阈值,具体细节参考 章小龙:Int8量化-介绍(一)
权重剪枝
神经网络的权重剪枝就是把网络趋近于0的权重直接裁剪成0,以达到稀疏性。权重剪枝,可以作为量化模型后进一步的优化,有了稀疏性,通过压缩后可以进一步减少参数存储量;有了稀疏性,运算时如果跳过权重为0的计算,又可以减少功耗。TensorFlow Lite框架对模型的移动端部署的核心优化就是量化和权重剪枝。
稀疏模型的优势在于易于可压缩,在推理过程中跳过权重为0的计算。剪枝通过压缩模型来实现。在牺牲微小精度的前提下,我们的模型有6倍的性能提升。剪枝这项技术,也在实际应用到语音应用中,如语音识别、文本转语音以及横跨各种视觉与翻译的模型中。
权重剪枝主要有两种方式:
后剪枝:拿到一个模型直接对权重进行剪枝,不需要其他条件。
训练时剪枝:训练迭代时边剪枝,使网络在训练过程中权重逐渐趋于0,但是由于训练时权重动态调整,使得剪枝操作对网络精度的影响可以减少,所以训练时剪枝比后剪枝更加稳定。
TF官方提供了详尽的Keras剪枝教程和Python API文档,以及训练稀疏模型等高级用法的指导。此外,还有一个MNIST手写体图像识别的CNN模型剪枝代码,和IMDN情感分类的LSTM模型的剪枝代码也可以参考。
1.6. 卷积运算的优化
卷积转化为矩阵乘法
大部分深度学习框架会把卷积操作转化成矩阵乘法操作,这样可以利用现有成熟的矩阵乘法优化方案,比较常见的转化方式是img2col:

全连接层可以直接转化为矩阵乘法,因为全连接的操作本质上就是Y=WX的矩阵操作。从另一个角度,全连接的操作其实还可以看作 每个神经元为1x1filter,所进行的卷积操作。而对于卷积层,转化为矩阵乘法后,会引入一定冗余度:
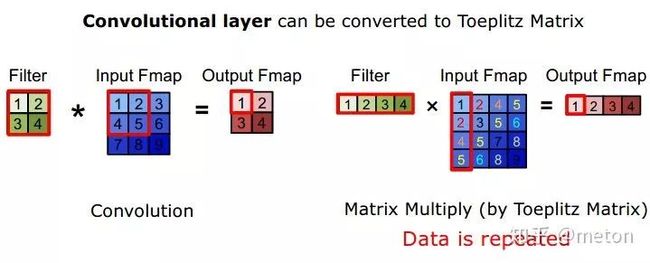
矩阵乘法的一些优化操作

矩阵分块可以更好地匹配各级cache的大小,这样cache局部性更好,访存时的miss率更低。除此之外,对矩阵的内存数据布局进行重排布来增加待计算数据放置的连续性,这样取数的时候cache miss率也会更低,像常见的 NCWH 和 NWHC 排布模式都是这方面考虑。
矩阵乘法的近似计算

使用其它的卷积近似替代算法,可以减少复杂度。不过有些算法有使用条件,像Winograd只是对小卷积核操作有比较大的优化效果。傅里叶变换似乎不太常用,因为要达到理论上的加速,要求卷积核要很大才可以,而实际上深度学习用的都是小卷积核。

2. 深度学习编译器
2.1 需求
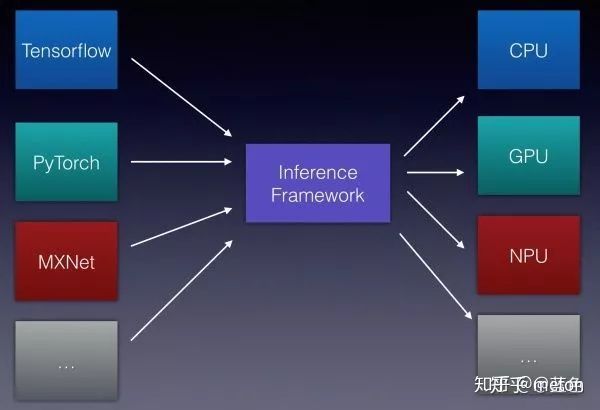
这个算是连接顶层和体系结构的部分,之所以有深度学习编译器的需求,是因为我们的模型从各式各样的顶层框架训练出来(Pytorch, Tensorflow, MXNet, Caffe等 ),但很多时候并不是还在训练时用的平台部署来进行推理,最终落地阶段可能需要将模型部署到各式各样的设备(Intel CPU, Nvidia GPU, 移动端Arm CPU, 移动端GPU, FPGA, Risc-V CPU ), 而这些设备是用不同的指令集架构的。
举个例子,你使用Tensorflow或者Pytorch为服务器端的Nvidia GPU所实现的算子操作(一些列cuda 函数) 完成了模型在GPU的训练,你得到了模型参数,接下来你被要求将模型部署到手机端cpu,那么可以肯定的是,你训练时候所使用的那些cuda函数肯定在手机端用不了了,怎么办呢?你需要针对你手机端的指令集架构Arm,重新手写算子(实现一些前向推理需要的卷积啊池化操作的函数,并且实现方式还必须高效,不然到时模型跑起来速度太慢也没有意义) ,这样你的模型才跑得起来,只手写一套你觉得还OK,顶得住,那如果还要部署要其他类型的设备呢?问题变得繁琐起来...
人工的话不太可能有精力对那么多目标平台重新手写切合各个平台指令集架构的算子(各类卷积,池化,点乘...),因此,如果有深度学习编译器来作为中间部分,将顶层框架的模型流图转化成中间层表示IR,在这个中间层表示做系列标准的流图优化操作(loop 调度,算子融合...),最后在按需求生成各个目标平台的机器码,那就是顶好的!
2.2 TVM
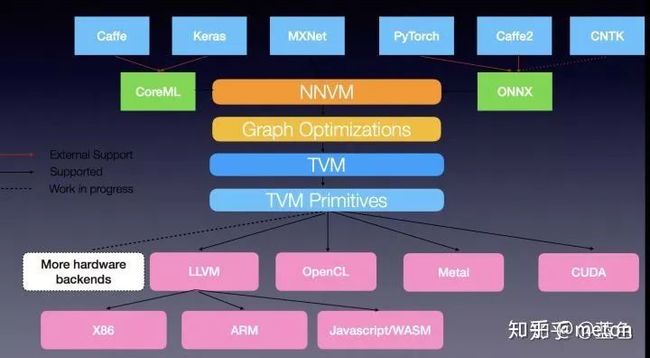
从上图可以看出来,TVM其实是一个桥梁作用,TVM可以实现算子代码的自动生成,也就是说现在我在顶层训练好了模型需要部署到不同的目标平台,通过TVM可以生成针对这些平台的优化的算子和推理代码。当然自动生成的算子还可以结合手工进一步优化(自动与手工结合)。除了自动生成算子代码功能,TVM很有吸引力的一点就是其自动生成的代码可以媲美那些手工优化的加速库。
TVM的使用场景:
一种是离线支持敏捷算子优化,通过TVM自动代码生成的功能,部分解放优化人员手动添加优化的负担。具体地,给定一个计算,优化人员进行workload characterization分析完计算访存pattern之后,可以拟定几种可能的优化方案,如果TVM的schedule中包含,那么可以直接应用TVM来生成包含该优化的代码。然后借助profiler来分析代码的瓶颈,进一步修正或者更新优化方案,再试图借助TVM的自动生成能力,如此循环往复。到最后,如果TVM代码的可读性足够的话,优化人员可以在其上做手动优化;如果可读性不好的话,TVM也可以帮助优化人员快速确定优化方案。
另外一种场景是,运行时代码生成。当研究员在试验新的算子时,由于没有可供调用的计算库,同时缺乏CUDA等高性能代码开发经验,因此很多情况下是通过裸跑python代码来调用新算子的。PyTorch已经在今年5月份开始将TVM接入到PyTorch中实现运行时代码优化编译,目前已经可以运行了。
详细的讨论参考:HONG:也谈TVM和深度学习编译器,https://zhuanlan.zhihu.com/p/87664838
关于深度学习编译器我还了解不多,下一步打算深入探究一下TVM再来补充。TVM入门可以参考 蓝色:手把手带你遨游TVM,https://zhuanlan.zhihu.com/p/50529704
2.3 Tensorflow XLA
XLA(Accelerated Linear Algebra,加速线性代数)是一种优化TensorFlow计算的编译器。XLA(加速线性代数)是为优化TensorFlow计算的特定领域编译器。它可以提高服务器和移动平台的速度、改进内存使用、提升便携性(或者说是可移植性)。XLA框架是目前处于开发中的实验性项目。更多信息请阅读XLA指南,
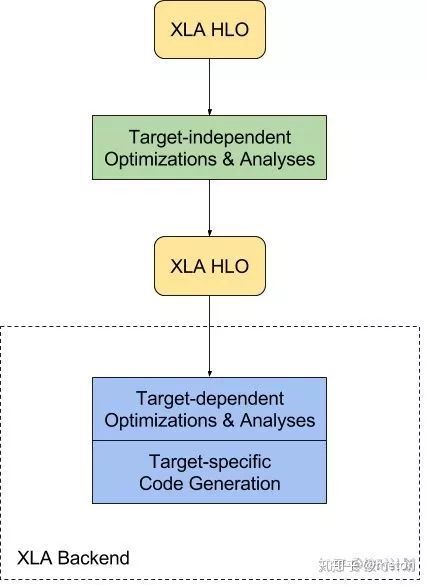
XLA有几个与目标硬件无关的优化,例如公共子表达式消除(CSE,common subexpression elimination),过程与硬件后端无关的(target-independent)算子融合,以及用于为计算而在运行时做内存分配的缓冲区分析。
硬件目标无关的步骤之后,XLA将HLO计算发送
到后端去做进一步的HLO级优化,HLO级优化会针对硬件目标特定信息和需求,如XLA GPU后端的算子融合、确定如何将计算划分为流。此阶段,后端还可以将某些算子或其组合与优化的库调用进行模式匹配。
下一步是特定于目标硬件的代码生成。CPU包括XLA使用的GPU后端会使用LLVM生成低级IR、优化和代码生成。硬件后端以有效方式发出了表示XLA HLO计算所必需的LLVM IR,然后调用LLVM从LLVM IR发出原生代码。
GPU后端目前通过LLVM NVPTX后端支持NVIDIA GPU,CPU后端支持多个CPU指令级架构( ISA)
详细可以参考:按时计划:TensorFlow Lite概述:转换器、解释器、XLA和2019年路线图,https://zhuanlan.zhihu.com/p/74085789
2.4 Pytorch Glow
https://github.com/pytorch/glow
Glow是一个机器学习的编译器和执行引擎,它可以面向多种硬件, 是基于LLVM项目进行了开发的。(后续继续补充....)

3. 体系结构与硬件设计
传统标量处理器适合分支情况复杂的程序,但是对于深度学习这种数据驱动的、有明显的DLP特征的应用就显得不适用了,因此现在通常是通用处理器和专用处理器的结合,像我们手机有多个CPU负责一般程序执行,又有NPU去加速器一些神经网络应用。
3.0. 关注指标
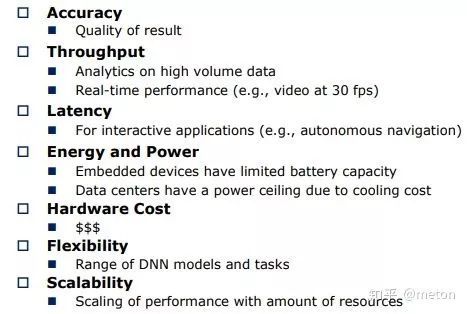
DNN加速器的关注的点不仅仅是 OPS/W,更多的是准确度、吞吐量、时延、功耗、硬件成本、硬件的灵活度或者说对新出现模型的可复用性等等各个方面的权衡。
3.1. CPU与GPU平台

现有的CPU和GPU都有官方的加速库来加速矩阵运算。CPU和GPU为了支持DLP行为,有专门的向量指令集,例如CPU的SIMD指令,不过SIMD毕竟是通用处理器对DLP的补充,并行度其实不算太高;还有就是GPU的SIMT,其实本质上是SIMD的一种不同的抽象方式,并且借助GPU大量的运算核心,在并行度方面远超支持向量处理的CPU。
SIMD和SIMT本质上是一种时间上的并行展开,属于Temporal架构,怎么理解呢?就好比一个循环并行,我每个并行计算单元做的是某次迭代的事,相当于把通用CPU在一段时间内的循环操作在我们的加速器的并行单元上一次性展开了。

SIMD/SIMT本质上是一种Temporal Arch
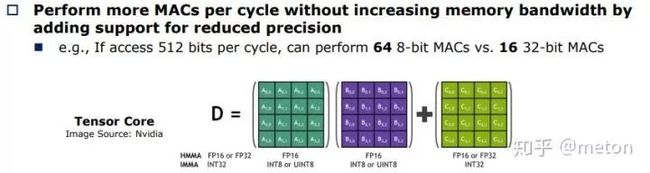
进一步,有些CPU/GPU支持INT8 INT16低精度运算,在取相同的数据量情况下,还可以进行更多的乘法运算(4个INT8 相当于原先一个 FP32所占的空间)。
CPU和GPU的设计考虑
1. 软件(编译器)
通过对卷积操作的变换来减少不必要的MACs,例如前面提到的卷积近似计算
通过编译时的优化PASS对循环执行进行调度(循环展开、循环tile等等)
编译器优化减少load,store指令,尽量用寄存器操作
2. 硬件软件
提高PEs处理每个MAC的时间.
提高并行度(使用更多并行的PEs,例如PE阵列).
提高PE的利用率. 意思是尽量使得PE忙碌,一个方法是增加片上缓存大小,提高访存总线宽度等等入手,这些都旨在减少访存的瓶颈,PEs可以更快拿到数,减少等待时间;另一种方式是让数据尽可能在数据通路中多停留,这样在访存能力不变的情况下,就可以用流水线的形式让PE尽可能有事做,后面讲解的TPU所用的脉动阵列,和流行的 DtaFlow数据流架构都是类似方式,当然在GPU的设计上也可以融入上述通用思想.
3.2. Domain-Specific 硬件设计
设计关注点

上图展示了DNN加速器在体系结构设计所关注的几个点:数据的读写也就是访存,以及计算。尤其是访存问题,因为通常PE数目很容易堆上去,并行度上去后,数据读写往往会成为瓶颈,也就是常说的撞到“内存墙”,内存访问在我们的机器上是有层级的,寄存器,cache很快,但是到了内存取数就很慢,数据在cache miss后代价会很大,因此如果没有很好的访存优化,那么对于大数据的深度学习,加速比是很难做上去的。
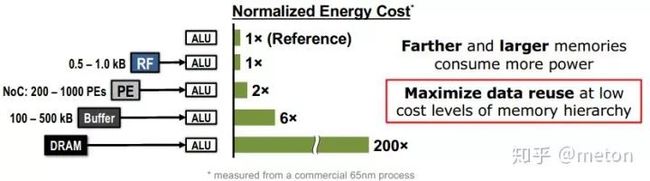
从DNN加速器的经典实现 DianNao系列、TPU、Eyeriss来看(后面会讲到),这些加速器都十分关注访存方面的设计,后续有时间就其一些设计细节展开。不过大体上优化访存的方式有:
研究新的内存制作工艺:这个没那么没那么容易其实
从更下级cache取数:一般CPU从L1 cache取数,但是L1 cache能装的数比较少,我看到有些加速器从L2 cache取数,因为L2 更大一些,取数 miss几率小,不过这么做要解决一下cache一致性问题(Hwacha)。
增大加速器的片上buffer:好理解,如果我加速器的buffer大的可以装进更多权重,那么计算部件PE要消费数据的时候取数从片上buffer取,那肯定比从内存取数要快。
数据重用:如果这个PE产生的结果下一次计算会被接着用上,那么可以让这个数据留在PE中,等待下次复用,这样就减少了数据被store回去、下一次又load回来的开销。从另外一个角度看,第二种方式本质上也是在利用数据的复用,只不过把数放在片上buffer来复用,复用的粒度不同。
两类设计范式

Temporal Arch. 这个前面有提及主要以SIMD,SIMT为代表.
Spatial Arch. 也就是数据流模式. 相比Temporal Arch的不同之处就是,数据流模式中PE与PE之间是可以相互通信的,也就是说数据可以在PE间流动,这一周期计算出来的结果可以在下一周期流到其他PE参与运算,而不用发生访存动作。所以,这样带来的好处是有更大的数据吞吐量,适合具有很好数据重用特性的应用。

深度学习应用的data reuse机会
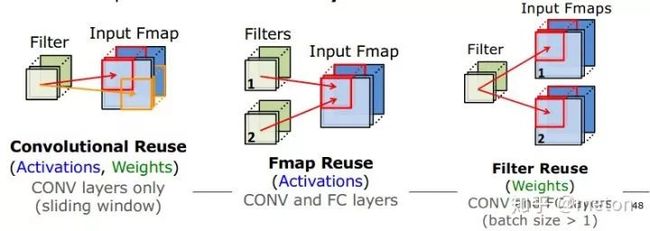
前面说道,处理访存问题是DNN加速器设计的一个关键,一个方法就是发掘卷积操作中的数据复用性。
卷积神经网络三个角度复用,一是复用权重;二是复用激活(也就是feature map);三是复用两者。不同的复用策略,可以引申出不同设计架构和取数策略:
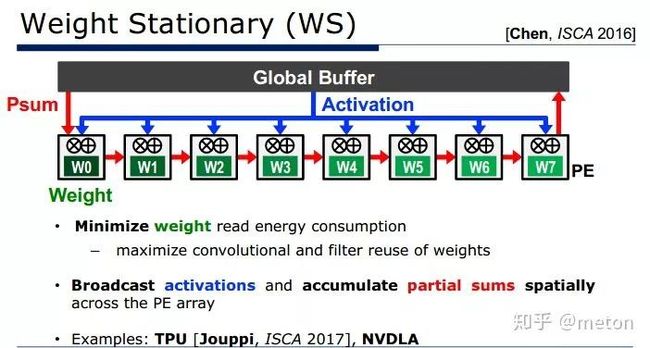
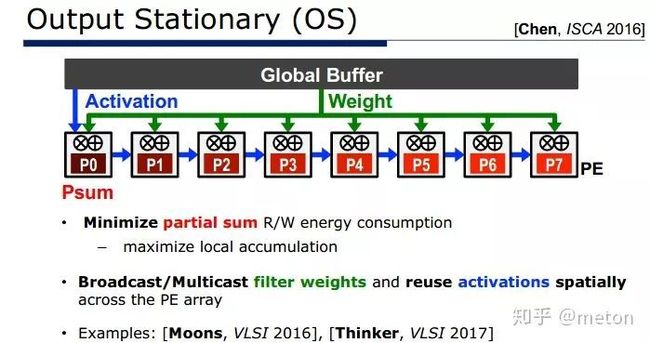

加速器Eyeriss则是采用了 行复用的方式:

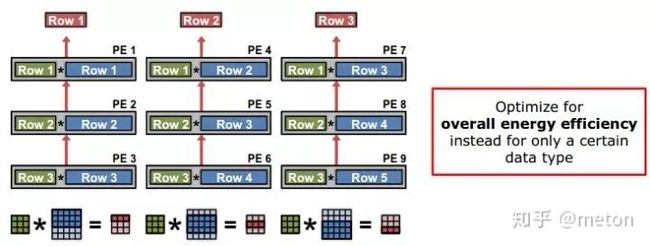
加速器设计一些可以利用的点
稀疏性质
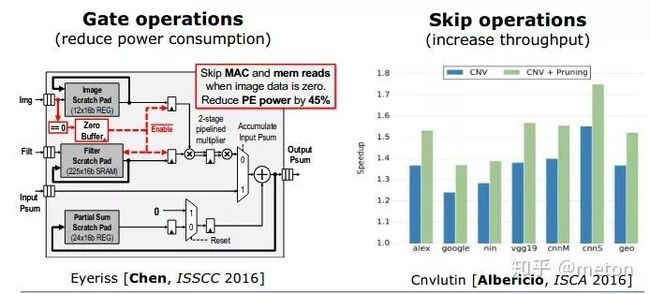
为什么稀疏是一个对硬件设计友好的特性呢?首先,减少不必要的乘法操作。0乘上任何数都是0,那么如果有0出现的话可以不使能乘法单元去计算,直接输出结果0,这样可以节省运算产生的功耗;乘法的操作数有0的话,不必费力去内存取0,直接有个存0寄存器输出0给乘法单元即可,这样就减少了数据搬移的开销。体系结构设计上可以利用剪枝的思想,把很小的只裁剪成0,这样就增大数据稀疏性,这里说的剪枝是硬件实现的剪枝。
低精度
前面算法层面有讲过量化的加速作用,但是量化本身其实是一个软硬件结合的设计,怎么理解呢?你在程序上实现的量化算法,落到指令架构级别都需要硬件的支持才行。这里再加强一下,INT8低精度支持可以使得数据的搬移量减少,同时整形操作速度更加快从而起到加速效果,目前许多设备都开始支持低精度推理
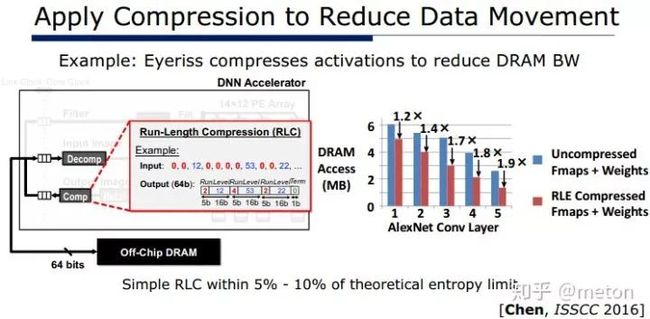
压缩
同样,如果硬件支持压缩功能,那么也可以减少数据搬移,例如,Eyeriss在写回数据时候会进行压缩编码再写回,这样大大减少访存的时间。
一些经典加速器设计案例分析
DianNao
https://www.cs.princeton.edu/courses/archive/spring16/cos598F/p269-chen.pdf

可以说是深度学习加速器的开山之作,比TPU还要早。里面的一些设计哲学就是在分析了DNN的行为模式后设计的。论文的贡献在于:
1、对大规模的CNNs和DNNs最先进机器学习算法的综合硬件设计
之前的加速器将神经网络每一层一次性全部实现到了硬件上,这种做法只适合规模小的网络结构。而且可拓展性很差(改动新的网络参数或者结构发生变化那么这个加速器就用不了了)。DianNao的利用计算单元的复用来适应大规模的网络。
2、专注于优化访存的性能,着重减缓”存储墙”的问题。
不用cache,用sratchpad作为buffer。因为cache的数据冲突问题会带来高功耗。
将输入数据split成两个独立的输入buffer。因为对于神经网络来说,输入数据和权重是两类很明显独立的数据,分开的话就不用混在一起,这样更加容易处理。考虑reuse的话,例如一个Nbin中一列输入数据Tn需要和实际中权重矩阵中多列进行相同的运算(也就是输入数据的重用),那么SB中的一列的位宽可以做的大一些(NBin一列是Tn=16宽度,也就是一列放16个输入特征;那么SB一列可以设置成TnXTn,也就是SB的一列代表权重矩阵Tn列,每列Tn个权重值,一共TnXTn个数)。从这个角度来说,将NBin和SB分开可以方便的根据reuse模式裁剪不同的位宽,如果是只用一个统一的buffer的话就做不到这点(一个buffer只能用一种位宽)。
NBout在输出最后结果之前,大部分时间可以用来缓存中间结果,这样中间结果先不回去memory。NBout缓存的中间结果可以回去NFU2进一步计算得到最终结果。
NBin和SB在DMA控制下进行preload,也就是每次计算单元取数时候数已经preload在buffer中了。
三个buffer用三个DMA控制,这样方便三个buffer中各自的取数写数操作。例如在计算过程中,SB和NBin的DMA要负责 preload 和 放数据给计算单元这两类任务。NBout的DMA负责将中间结果wirte进NBout缓存 以及 将最终结果load回内存 这两类任务。可见DMA分开可以各自干各自事,比较灵活。
PuDianNao
https://dl.acm.org/doi/10.1145/2786763.2694358
普电脑和DianNao的区别就在于,DianNao主要针对神经网络,而普电脑而是支持一类机器学习算法(KNN、朴素贝叶斯、SVM、K-Means、线性回归、决策树等等)的加速,属于特定领域的通用加速(狗头。论文中花了大量篇幅,仔细分析了各类机器学习算法在访存行为、计算模式上的异同,(搞体系结构的访存真的时常挂嘴边啊...,强烈建议搞体系结构、加速器设计的同学仔细读一下论文里面对各个算法案例的分析),最终得出一个结论:
各类机器学习的行为模式很大不同(相比各类DNN而言),但是从更细粒度,也就是在数据重用、计算操作(乘加、计数比较..)角度上是可以分几类的,针对这一点设计如下的结构:
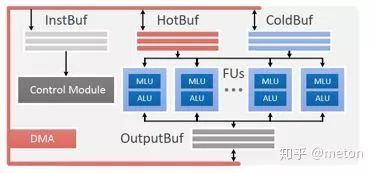

HotBuf和ColdBuf 就是在分析几类算法的数据重用行性后设计的,有的数据重用距离小,有的数据重用距离大,所以将buffer根据重用距离进行分离。
数据通路根据总结了几类算法出现的高频运算操作(有比较操作、计数、乘加(乘法+加法树组合)、中间结果缓存、非线性运算)做成流水线,对于某种特定的类型,如果在某级不需要该运算,可以直接bypass.
PuDianNao论文的详细分析可以参考:中科院说的深度学习指令集diannaoyu到底是什么?大佬讲的蛮好的。另外,如果想细究一下加速器一些具体的设计细节,可以看看ShiDianNao,这篇论文没有太多架构创新,但是在加速器设计细节上讲的应该是所有DianNao系列论文中最细致的了.
TPU
https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=8192463&tag=1

设计哲学就是:
Simple and regular design:可以说,简单和规则是脉动阵列的一个重要原则。而这样的设计主要是从“成本”的角度来考虑问题的。
Balancing computation with I/O:平衡运算和I/O,应该说是脉动阵列最重要的设计目标。尽量让数据在运算部件中多停留。尽量让运算部件保持繁忙,不会因为要取数而停滞计算。
脉动矩阵
TPU使用了脉动阵列,这是一个很有趣的点,脉动阵列在很早之前就已经出现,后来被认为实用性不大,但是在深度学习时代,计算密集的大矩阵运算让脉动矩阵焕发活力,可以算是加速器设计的重新考古发现。关于脉动阵列的计算方式可以参考https://github.com/meton-robean/PaperNotes/issues/3

简述一下脉动阵列计算方式就是:权重先送进各个PE,之后input 矩阵数据从左往右流进阵列计算,之后计算结果从下面依次流出(不同列输出相差若干个周期),没错,这就是一种数据流架构的实现嘛.
脉动矩阵的一些看法与分析:
1. 脉动架构是一种很特殊的设计,结构简单,实现成本低。但它灵活性较差,只适合特定运算。而作者认为,卷积运算是展示脉动架构特点的理想应用。
2. 脉动阵列难以扩展,因为它需要带宽的成比例的增加来维持所需的加速倍数。这违反摩尔定律和储存速度落后于逻辑速度的技术趋势。另外它又使延迟变得更糟,这违反了论文中提到的用户需求的趋势。即使TPU中的矩阵乘法单元只是脉动矩阵乘法的多种选项之一。是否可以找到可扩展并且节能的替代方案,来实现所需的传播和累加而不以牺牲延迟时间为代价,这是一个值得思考的有趣的话题。
3. 数据重排。脉动矩阵主要实现向量/矩阵乘法。以CNN计算为例,CNN数据进入脉动阵列需要调整好形式,并且严格遵循时钟节拍和空间顺序输入。数据重排的额外操作增加了复杂性,据推测由软件驱动实现。
4. 规模适配.在数据流经整个阵列后,才能输出结果。当计算的向量中元素过少,脉动阵列规模过大时,不仅难以将阵列中的每个单元都利用起来,数据的导入和导出延时也随着尺寸扩大而增加,降低了计算效率。因此在确定脉动阵列的规模时,在考虑面积、能耗、峰值计算能力的同时,还要考虑典型应用下的效率。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

