BiLSTM维度详解
一、BiLSTM
之前文章有介绍过LSTM,BiLSTM就是由前向的LSTM与后向的LSTM结合而成。比如,我们对“我爱中国”这句话进行编码,模型如图所示。

二、二种BiLSTM的应用
1、字向量表示
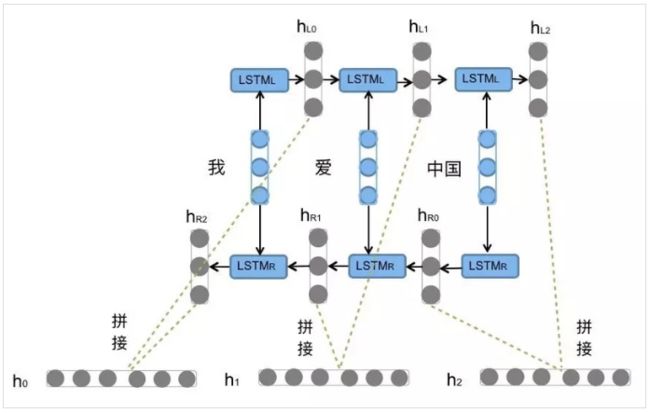
前向的 L S T M L LSTM_L LSTML一次输入“我”,“爱”,“中国”得到三个向量{ h L 0 h_L0 hL0, h L 1 h_L1 hL1, h L 2 h_L2 hL2}。后向的 L S T M R LSTM_R LSTMR依次输入为“中国”,“爱”,“我”得到三个向量{ h R 0 h_R0 hR0, h R 1 h_R1 hR1, h R 2 h_R2 hR2}。最后将前向和后向的隐向量进行拼接的搭配{[ h L 0 h_L0 hL0, h R 2 h_R2 hR2],[ h L 1 h_L1 hL1, h R 1 h_R1 hR1],[ h L 3 h_L3 hL3, h R 0 h_R0 hR0]},用{ h 0 h_0 h0, h 1 h_1 h1, h 2 h_2 h2}表示。
2、分类任务
分类任务一般采用{ h L 1 h_L1 hL1, h R 2 h_R2 hR2}对句子向量进行表示,因为其中包含前向与后向的所有信息。

三、BiLSTM输入和输出维度
1、output
保存了最后一层,每个time step的输出h,如果是双向LSTM,每个time step的输出h = [h正向, h逆向] (同一个time step的正向和逆向的h连接起来)。
output是一个三维的张量,第一维表示一批的样本数(batch),第二维表示序列长度,第三维是 hidden_size(隐藏层大小) * num_directions。num_directions根据是“否为双向”取值为1或2。因此,我们可以知道,output第三个维度的尺寸根据是否为双向而变化,如果不是双向,第三个维度等于我们定义的隐藏层大小
2、h_n
保存了每一层,最后一个time step的输出h,如果是双向LSTM,单独保存前向和后向的最后一个time step的输出h。
h_n是一个三维的张量。第一维表示一批的样本数量(batch)。第二维是num_layers*num_directions。第三维表示隐藏层的大小。
3、c_n
与h_n一致,只是它保存的是c的值
四、BiLSTM应用
以百度AnyQ simnet为例,计算文本相似度。一种是采用拼接的方式计算相似度;一种采用cos计算相似度。个人认为在样本量较少时,采用cos相似度效果好些,可以降低过拟合的影响。
1、字向量表示
tf.nn.bidirectional_dynamic_rnn():
(1)输入4个参数。前向神经元的个数、后向神经元的个数、句子的embedding维度、句子长度
(2)2个输出:第一个输出是每个词向量在该时刻的输出[ h 1 h_1 h1, h 2 h_2 h2… h t h_t ht]构成的列表,再将前向和后向进行拼接,如上图“字向量表示”;第二个输出最后一个隐状态 h t h_t ht和记忆细胞 c t c_t ct构成的元组( h t h_t ht, c t c_t ct)。
(3)下面例子只取[ h 1 h_1 h1, h 2 h_2 h2… h t h_t ht]最为句子向量的表示。单个句子维度为(seq_len, hidden)
def predict(self, left, right):
#(batch,seq_len,1)---->(batch,seq_len,embed_size)
left_emb = self.emb_layer.ops(left)
right_emb = self.emb_layer.ops(right)
#(batch, seq_len, embed_size)---->((batch, seq_len, hidden),(batch, seq_len, hidden))
## left
bi_left_outputs, _ = tf.nn.bidirectional_dynamic_rnn(self.fw_cell, self.bw_cell,
left_emb, sequence_length=self.seq_length(left), dtype=tf.float32)
left_seq_encoder = tf.concat(bi_left_outputs, -1)
## right
#((batch, seq_len, hidden),(batch, seq_len, hidden))
bi_right_outputs, _ = tf.nn.bidirectional_dynamic_rnn(self.fw_cell, self.bw_cell,
right_emb, sequence_length=self.seq_length(right), dtype=tf.float32)
# ((batch, seq_len, hidden),(batch, seq_len, hidden)) ---->((batch,seq_len, hidden*2))
right_seq_encoder = tf.concat(bi_right_outputs, -1)
# (batch, seq_len, hidden*2)*(batch,hidden*2,seq_len,)----->(batch, seq_len, seq_len)
cross = tf.matmul(left_seq_encoder, tf.transpose(right_seq_encoder, [0, 2, 1]))
# (batch, seq_len, seq_len)---->(batch, seq_len*seq_len)
cross_reshape = tf.reshape(cross, [-1, self.seq_len * self.seq_len])
# (batch, seq_len*seq_len)---->(batch, 25)
k_max_match = tf.nn.top_k(cross_reshape, k=self.k_max_num, sorted=True)[0]
#(batch, k_max_num)*(k_max_num, num_class) ---->(batch,num_class)
pred = self.fc2_layer.ops(k_max_match)
return pred
2、句子向量表示
下面例子取最后一层隐层的输出 h t h_t ht最为句子向量的表示。单个句子维度为(, hidden)
def predict(self, left, right):
#(batch,seq_len,1)---->(batch,seq_len,embed_size)=(batch,10,200)
left_emb = self.emb_layer.ops(left)
right_emb = self.emb_layer.ops(right)
#(batch, seq_len, embed_size)---->((batch, hidden),(batch, hidden))
## left
_, bi_left_outputs = tf.nn.bidirectional_dynamic_rnn(self.fw_cell, self.bw_cell,
left_emb, sequence_length=self.seq_length(left), dtype=tf.float32)
bi_leftt_outputs_c, bi_left_outputs_h = zip(*list(bi_left_outputs))
#((batch, hidden), (batch, hidden)) ------>(batch,hidden*2)
left_seq_encoder = tf.concat(bi_left_outputs_h, -1)
## right
#(batch, seq_len, embed_size)---->((batch, hidden),(batch, hidden))
_, bi_right_outputs = tf.nn.bidirectional_dynamic_rnn(self.fw_cell, self.bw_cell,
right_emb, sequence_length=self.seq_length(right), dtype=tf.float32)
# ((batch, hidden), (batch, hidden)) ------>(batch,hidden*2)
bi_right_outputs_c, bi_right_outputs_h = zip(*list(bi_right_outputs))
right_seq_encoder = tf.concat(bi_right_outputs_h, -1)
#(batch,hidden*2) ------>(batch,hidden)
hid1_left = self.fc1_layer.ops(left_seq_encoder)
hid1_right = self.fc1_layer.ops(right_seq_encoder)
#(batch_size, hidden_size)
left_relu2 = tf.nn.leaky_relu(hid1_left, alpha=0.2)
right_relu2 = tf.nn.leaky_relu(hid1_right, alpha=0.2)
pred = self.cos_layer.ops(left_relu2, right_relu2)
return pred
参考文献:
1、聊一聊PyTorch中LSTM的输出格式:https://zhuanlan.zhihu.com/p/39191116
2、详解 LSTM:https://www.cnblogs.com/chihaoyuIsnotHere/p/10604085.html
3、BiLSTM介绍及代码实现:https://www.jiqizhixin.com/articles/2018-10-24-13