【15】Faster-RCNN网络详细解读
【1】前言
最近博客上看了很多篇关于Faster-RCNN网络详细解读,但是始终对其中的解释一知半解。刚开始以为自己懂了,有看了一些发现自己又困惑了,这个东西到底是什么,是怎么训练的?怎么传播的?里面的名词究竟是什么意思?看的始终是一知半解。对于Faster-RCNN的网络的用途以及Faste-RCNN和RCNN原理此处不讲解,只讲解Faster-RCNN的网络,对其进行详细的剖析。
【2】Faster-RCNN网络框架

图(1)Faster-RCNN网络框架
首先必须要搞懂一点Faster-Rcnn不是一个神经网络。准确的说他是由两个神经网络构成的一个特征检测网络。
(1)对于CNN网络主要是用来提供输入图像的特征图,通常是经典的卷积神经网络,ALEXNET,VGGNET,RESNET等经典的卷积网络。本文则以Vgg16作为特征提取网络。
输入为图片,输出为特征图
(2)RPN网络则是根据CNN网络得到的特征图对特征图上的特征进行检测,确定检测物体的位置。
输入为特征图,物体标签,即训练集中所有物体的类别与边框位置;输出为Proposal(区域框)、分类Loss、回归Loss,其中,Proposal作为生成的区域,供后续模块分类与回归。
(3)FasterRCNN网络为CNN和RPN网络相加。
输入为图片,输出为分类和回归(分类对区域框中的图像进行分类,回归则是为了预测分类框的位置)
【3】RPN网络
理解了RPN网络就是理解了Fasterrcnn网络。网络结构如下所示。
【3.1】原理理解
特征提取网络Backbone:输入图像首先经过Backbone得到特征图,在此以VGGNet为例,假设输入图像的维度为3×600×800,由于VGGNet包含4个Pooling层(物体检测使用VGGNet时,通常不使用第5个Pooling层),下采样率为16,因此输出的feature map的维度为512×37×50。这个图最下面的conv feature map的大小就是512×37×50。
RPN模块:区域生成模块,如图4.3的中间部分,其作用是生成较好的建议框,即Proposal,这里用到了强先验的Anchor。RPN包含5个子模块:
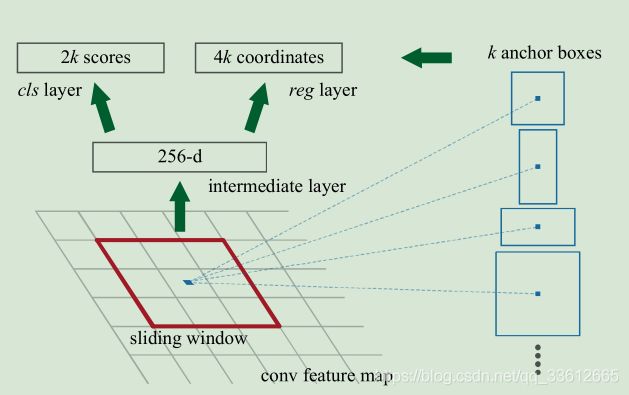

图(2)3*3卷积计算图 图(3)Faster-RCNN网络卷积原理图
初次看图(2)时根本看不懂这个图是什么意思,很正常,因为这个图是高度抽象的。个人觉得PRN网络其实只在图(3)中的红色虚线内部,classifer对应于图(2)中的上部分,即生成256维的数据。
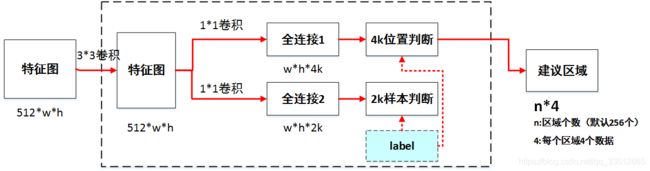
图(4-a) RPT网络原理图

图(4-b) RPT网络计算图
(1)·Anchor生成:RPN对feature map上的每一个点都对应了9个Anchors,这9个Anchors大小宽高不同,对应到原图基本可以覆盖所有可能出现的物体。因此,有了数量庞大的Anchors, RPN接下来的工作就是从中筛选,并调整出更好的位置,得到Proposal。·
(2)RPN卷积网络:与上面的Anchor对应,由于feature map上每个点对应了9个Anchors,因此可以利用1×1的卷积在feature map上得到每一个Anchor的预测得分与预测偏移值。
(3)计算RPN loss:这一步只在训练中,将所有的Anchors与标签进行匹配,匹配程度较好的Anchors赋予正样本,较差的赋予负样本,得到分类与偏移的真值,与第二步中的预测得分与预测偏移值进行loss的计算。
(4)·生成Proposal:利用第二步中每一个Anchor预测的得分与偏移量,可以进一步得到一组较好的Proposal,送到后续网络中。·
(5)筛选Proposal得到RoI:在训练时,由于Proposal数量还是太多(默认是2000),需要进一步筛选Proposal得到RoI(默认数量是256)。在测试阶段,则不需要此模块,Proposal可以直接作为RoI,默认数量为300。
【3.2】细节理解
下面将详细的讲解每一步的原理:
(1)为什么会有3*3的尺度不变卷积?
这个是作者原文上就有的,是针对输入的特征图进行卷积,获取跟高维度的特征,获取更大的感受野。
(2)512*w*h如何通过1*1的卷积变成两个全连接的??
1*1的卷积其实并不是一个卷积,而是一个类似滑动窗口的卷积核。目的是定位并不是真的卷积。输入图片通过卷积网络得到特征图,通过卷积网络也可以知道缩放比例。

图(5) Anchor原理图
Anchor的本质是在原图大小上的一系列的矩形框,但Faster RCNN将这一系列的矩形框和feature map进行了关联。为适应不同物体的大小与宽高,在作者的论文中,默认在每一个点上抽取了9种Anchors,具体Scale为{8, 16, 32}, Ratio为{0.5, 1, 2},将这9种Anchors的大小反算到原图上,即得到不同的原始Proposal,如图4.4所示。由于feature map大小为37×50,因此一共有37×50×9=16650个Anchors。而后通过分类网络与回归网络得到每一个Anchor的前景背景概率和偏移量,前景背景概率用来判断Anchor是前景的概率,回归网络则是将预测偏移量作用到Anchor上使得Anchor更接近于真实物体坐标。
一个矩形框有4个参数,分别为矩形框左上角的坐标,矩形框长度和宽度。一个矩形里面的区域分类为两种,正样本和负样本。因为一个点对应九个这样的框,所以1*1滑动结束后数据的维度分别为w*h*4k,w*h*2k。一个全连接是算区域位置,一个是算样本的类别。这里总共有16650个Anchors,但是我们总共需要256个Anchors输入到后面,即作为RPN网络的输出。
如何减少Anchors??? 通过与真实的样本进行比较得到损失函数,不断优化。
(1)真假判断
举个例子,如图6所示,输入图像中有3个Anchors与两个标签,从位置来看,Anchor A、C分别和标签M、N有一定的重叠,而Anchor B位置更像是背景。

图6 图像中Anchor与标签的关系
首先介绍模型的真值。对于类别的真值,由于RPN只负责区域生成,保证recall,而没必要细分每一个区域属于哪一个类别,因此只需要前景与背景两个类别,前景即有物体,背景则没有物体。RPN通过计算Anchor与标签的IoU来判断一个Anchor是属于前景还是背景。IoU的含义是两个框的公共部分占所有部分的比例,即重合比例。在图4.5中,Anchor A与标签M的IoU计算公式如式(1)所示。
 (1)
(1)
当IoU大于一定值时,该Anchor的真值为前景,低于一定值时,该Anchor的真值为背景。
然后是偏移量的真值。仍以图6中的Anchor A与标签M为例,假设Anchor A的中心坐标为xa与ya,宽高分别为wa与ha,标签M的中心坐标为x与y,宽高分别为w与h,则对应的偏移真值计算公式如式(2)所示。
 (2)
(2)
从式(2)中可以看到,位置偏移tx与ty利用宽与高进行了归一化,而宽高偏移tw与th进行了对数处理,这样的好处是进一步限制了偏移量的范围,便于预测。有了上述的真值,为了求取损失,RPN通过卷积网络分别得到了类别与偏移量的预测值。具体来讲,RPN需要预测每一个Anchor属于前景与背景的概率,同时也需要预测真实物体相对于Anchor的偏移量,记为[插图]、[插图]、[插图]和[插图]。另外,在得到预测偏移量后,可以使用式(3)的公式将预测偏移量作用到对应的Anchor上,得到预测框的实际位置x*、y*、w*和h*。
 (3)
(3)
如果没有Anchor,做物体检测需要直接预测每个框的坐标,由于框的坐标变化幅度大,使网络很难收敛与准确预测,而Anchor相当于提供了一个先验的阶梯,使得模型去预测Anchor的偏移量,即可更好地接近真实物体。实际上,Anchor是我们想要预测属性的先验参考值,并不局限于矩形框。如果需要,我们也可以增加其他类型的先验,如多边形框、角度和速度等。
(2)求解回归偏移值。
上一步将每个Anchor赋予正样本或者负样本代表了预测类别的真值,而回归部分的偏移量真值还需要利用Anchor与对应的标签求解得到,具体公式见式2。得到偏移量的真值后,将其保存在bbox_targets中。与此同时,还需要求解两个权值矩阵bbox_inside_weights和bbox_outside_weights,前者是用来设置正样本回归的权重,正样本设置为1,负样本设置为0,因为负样本对应的是背景,不需要进行回归;后者的作用则是平衡RPN分类损失与回归损失的权重,在此设置为1/256。
(3)计算损失函数
有了网络预测值与真值,接下来就可以计算损失了。RPN的损失函数包含分类与回归两部分,具体公式如式(4)所示。
 (4)
(4)
![]() 代表了256个筛选出的Anchors的分类损失,Pi为每一个Anchor的类别真值,
代表了256个筛选出的Anchors的分类损失,Pi为每一个Anchor的类别真值,![]() 为每一个Anchor的预测类别。由于RPN的作用是选择出Proposal,并不要求细分出是哪一类前景,因此在这一阶段是二分类,使用的是交叉熵损失。值得注意的是,在F.cross_entropy()函数中集成了Softmax的操作,因此应该传入得分,而非经过Softmax之后的预测值。
为每一个Anchor的预测类别。由于RPN的作用是选择出Proposal,并不要求细分出是哪一类前景,因此在这一阶段是二分类,使用的是交叉熵损失。值得注意的是,在F.cross_entropy()函数中集成了Softmax的操作,因此应该传入得分,而非经过Softmax之后的预测值。 代表了回归损失,其中bbox_inside_weights实际上起到了
代表了回归损失,其中bbox_inside_weights实际上起到了 进行筛选的作用,bbox_outside_weights起到了[插图]来平衡两部分损失的作用。
进行筛选的作用,bbox_outside_weights起到了[插图]来平衡两部分损失的作用。
(4)NMS与生成Proposal
完成了损失的计算,RPN的另一个功能就是区域生成,即生成较好的Proposal,以供下一个阶段进行细分类与回归。NMS生成Proposal的主要过程如图4.8所示,首先生成大小固定的全部Anchors,然后将网络中得到的回归偏移作用到Anchor上使Anchor更加贴近于真值,并修剪超出图像尺寸的Proposal,得到最初的建议区域。在这之后,按照分类网络输出的得分对Anchor排序,保留前12000个得分高的Anchors。由于一个物体可能会有多个Anchors重叠对应,因此再应用非极大值抑制(NMS)将重叠的框去掉,最后在剩余的Proposal中再次根据RPN的预测得分选择前2000个,作为最终的Proposal,输出到下一个阶段。

图7 RPN生成Proposal的过程
(5) 筛选Proposal得到RoI
在训练时,上一步生成的Proposal数量为2000个,其中仍然有很多背景框,真正包含物体的仍占少数,因此完全可以针对Proposal进行再一步筛选,过程与RPN中筛选Anchor的过程类似,利用标签与Proposal构建IoU矩阵,通过与标签的重合程度选出256个正负样本。这一步有3个作用:·筛选出了更贴近真实物体的RoI,使送入到后续网络的物体正、负样本更均衡,避免了负样本过多,正样本过少的情况。·减少了送入后续全连接网络的数量,有效减少了计算量。筛选Proposal得到RoI的过程中,由于使用了标签来筛选,因此也为每一个RoI赋予了正、负样本的标签,同时可以在此求得RoI变换到对应标签的偏移量,这样就求得了RCNN部分的真值。具体实现时,首先计算Proposal与所有的物体标签的IoU矩阵,然后根据IoU矩阵的值来筛选出符合条件的正负样本。筛选标准如下:·对于任何一个Proposal,其与所有标签的最大IoU如果大于等于0.5,则视为正样本。经过上述标准的筛选,选出的正、负样本数量不一,在此设定正、负样本的总数为256个,其中正样本的数量为p个。为了控制正、负样本的比例基本满足1:3,在此正样本数量p不超过64,如果超过了64则从正样本中随机选取64个。剩余的数量256-p为负样本的数量,如果超过了256-p则从负样本中随机选取256-p个。经过上述操作后,选出了最终的256个RoI,并且每一个RoI都赋予了正样本或者负样本的标签。在此也可以进一步求得每一个RoI的真值,即属于哪一个类别及对应真值物体的偏移量。至此RPN网络结束了,输出为256矩形框。
【4】 ROIPooling
上述步骤得到了256个RoI,以及每一个RoI对应的类别与偏移量真值,为了计算损失,还需要计算每一个RoI的预测量。前面的VGGNet网络已经提供了整张图像的feature map,因此自然联想到可以利用此feature map,将每一个RoI区域对应的特征提取出来,然后接入一个全连接网络,分别预测其RoI的分类与偏移量。然而,由于RoI是由各种大小宽高不同的Anchors经过偏移修正、筛选等过程生成的,因此其大小不一且带有浮点数,然而后续相连的全连接网络要求输入特征大小维度固定,这就需要有一个模块,能够把各种维度不同的RoI变换到维度相同的特征,以满足后续全连接网络的要求,于是RoI Pooling就产生了。
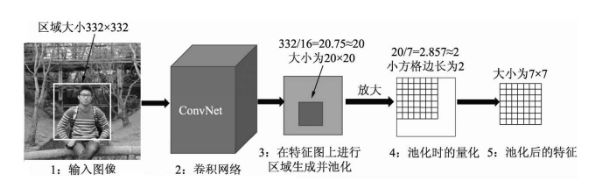
图8 RoI Pooling的实现过程示例

图9 roipooling原理图

图10 roipooling过程图
通过对特征图上的特定区域进行pooling,得到了256*512*7*7维度的数据,其中512*7*7表示roipooling后特征图的大小。
【5】全连接RCNN模块
在经过RoI Pooling层之后,特征被池化到了固定的维度,因此接下来可以利用全连接网络进行分类与回归预测量的计算。在训练阶段,最后需要计算预测量与真值的损失并反传优化,而在前向测试阶段,可以直接将预测量加到RoI上,并输出预测量。RCNN全连接网络如图11所示,上述中256个RoI经过池化之后得到固定维度为512×7×7的特征,在此首先将这三个维度延展为一维,因为全连接网络需要将一个RoI的特征全部连接起来。

图11 RCNN部分网络计算流程
接下来利用VGGNet的两个全连接层,得到长度为4096的256个RoI特征。为了输出类别与回归的预测,将上述特征分别接入分类与回归的全连接网络。在此默认为21类物体,因此分类网络输出维度为21,回归网络则输出每一个类别下的4个位置偏移量,因此输出维度为84。