Pre-train Model
Pre-Train Model
预训练模型的5大类结构
Encoder-AE结构

输入句中的未被Mask的任意单词两两可见,但是被Mask掉的单词之间都相互独立,互不可见。在预测某个被Mask掉的单词的时候,所有其它被Mask的单词都不起作用,但是句内未被Mask掉的所有单词,都可以参与当前单词的预测。
对于语言理解类的NLP任务,AE结构都是效果最好的,但是对于语言生成类的任务,AE结构效果相对很差。也就是说,这种结构比较适合做语言理解类的任务。
Decoder-AR结构

语言模型预训练的时候,采用AR方法,就是从左到右逐个生成单词,第 i i i个单词$ w_i $只能看到它之前的第 1 1 1到第 ( i − 1 ) (i-1) (i−1)个单词 $w_1….w_{i−1} $,不能看到后面的单词。
Encoder-Decoder结构

Encoder-Decoder结构如上图所示。这种结构在Encoder侧,单独使用一个Transformer,采用了Encoder-AE的结构。也就是说,编码阶段采用双向语言模型,任意两个单词两两可见,以更充分地编码输入信息;而在Decoder侧,使用另外一个Transformer,采用了Decoder-AR结构,从左到右逐个生成单词。
在进行预训练的时候,Encoder和Decoder会同时对不同Mask部分进行预测:Encoder侧双向语言模型生成被随机Mask掉的部分单词;Decoder侧单向语言模型从左到右生成被Mask掉的一部分连续片断。两个任务联合训练,这样Encoder和Decoder两侧都可以得到比较充分地训练。
Prefix LM
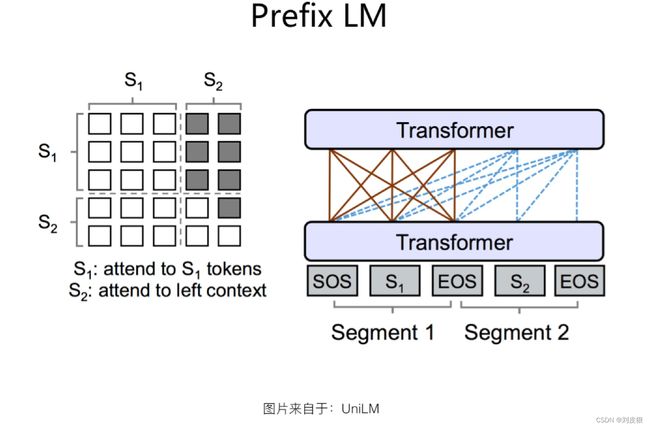
Prefix LM,相当于Encoder和Decoder通过分割的方式,分享了同一个Transformer结构,Encoder部分占用左部,Decoder部分占用右部,这种分割占用是通过在Transformer内部使用Attention Mask来实现的。与标准Encoder-Decoder类似,Prefix LM在Encoder部分采用AE模式,就是任意两个单词都相互可见,Decoder部分采用AR模式,即待生成的单词可以见到Encoder侧所有单词和Decoder侧已经生成的单词,但是不能看未来尚未产生的单词,就是说是从左到右生成。
Permuted Language Model(PLM)

PLM一样采用单个Transformer模型作为主干结构,但是从训练方法上来说,是个很另类也很有创意的做法,是种“形为AR,实为AE”的做法。在语言模型预训练过程中,它看上去遵循AR从左到右的输入过程,这符合一般生成任务的外在表现形式,但是在内部通过Attention Mask,实际做法其实是AE的做法,无非是把AE的做法隐藏在Transformer内部。
关于预训练模型高效的原因分析
更高质量、更多数量的预训练数据

在保证预训练数据质量的前提下,数据规模越大模型效果越好。因为数据量越多,数据里蕴含的知识也越多,那么模型能学到的东西越多,所以模型效果会更好,这是一个靠简单推理就能得出的结论。
增加模型容量及复杂度

所谓增加模型容量及复杂度,指的是增加Transformer模型的参数量,一般而言,模型容量越大,模型的表达能力越强。最直接的增加模型容量的方式就是增加Transformer Block层深,比如可以从Bert base的12层,增加到Bert Large的24层,还可以继续增加到比如36层,这是纵向增加复杂度,Google T5走的这条路(从上图可以看出,模型容量增加到4倍后,有些数据集效果相对Baseline有大幅度的提升)。除此外,还可以横向增加模型复杂度,比如在固定Transformer层深的情况下,可以通过放大Transformer中构件的大小,比如Hidden Size的增大,FFN层对隐层的放大,Multi-Head Self Attention的Attention头的增加,等多种方式来做到这一点。ALBERT走的这条路,它的xxLarge模型效果最好,只用了12层Transformer Block,但是Hidden Size达到了4096。
这两种模式还可以相互结合,就是同时纵向和横向增加模型复杂度,GPT 3即是如此,将模型复杂度这点推到了极致。
更充分地训练模型
这里所谓的“更充分”,一般指的是放大Batch Size、增加预训练步数,就是RoBERTa做的那两个事情。
有难度的预训练任务
原始的Bert预训练,有两个训练任务:一个是单词级的Mask语言模型MLM,一个是句子级的下一句预测任务NSP。RoBERTa证明了NSP对于模型效果没什么影响,所以拿掉了这个任务。
对于单词级的Mask语言模型来说,Span类的预训练任务效果最好。所谓Span类的任务,就是Mask掉的不是一个独立的单词,而是一个连续的单词片断,要求模型正确预测片断内的所有单词。Span类任务,只是一个统称,它会有一些衍生的变体,比如N-Gram,就是Span模型的一个变体,再比如Mask掉的不是单词而是短语,本质上也是Span类任务的变体,这里我们统称为Span类任务。进一步说明,Span内多个单词独立被生成效果会更好。
对于句子级的任务,NSP任务学习两个句子是否连续句:正例由两个连续句子构成,负例则随机选择一句跟在前一句之后,要求模型预测两者是否连续句子。本质上,NSP在预测两个句子是否表达相近主题,而这个任务,相对MLM来说,过于简单了,导致模型学不到什么知识。ALBERT采用了句子顺序预测SOP(Sentence Order Prediction):跟NSP一样,两个连续出现的句子作为正例,但是在构造负例的时候,则交换句子正确顺序,要求模型预测两个句子出现顺序是否正确,这样增加任务难度,StructBERT也采取了类似的做法。实验证明SOP是有效的句子级预测任务。
其他知识的引入
显示知识的引入
过去已经通过一些技术手段,归纳出大量的结构化知识,比如知识图谱;或者已经建立了很多知识分析工具,比如命名实体识别系统等。那么能否利用这些知识识别工具,抑或已有的结构化知识,让预训练模型能够直接学到这些知识。

百度ERNIE的思路是:在预训练阶段被Mask掉的对象上做文章,我们可以使用比如命名实体识别工具/短语识别工具,将输入中的命名实体或者部分短语Mask掉(参考上图),这些被Mask掉的片断,代表了某种类型的语言学知识,通过这种方式,强迫预训练模型去强化地学习相关知识。

清华ERNIE则是另外一种思路:我们已经有些结构化知识或者实体关系知识等现成的外部知识库,可以在预训练的过程中,通过工具找出句中的命名实体,句中的命名实体可以触发知识库中其它相关实体,然后预训练模型通过特殊的结构,来融合文本和结构化知识,以进一步促进语言的理解(参考上图)。
多模态预训练
目前的多模态预训练任务中,通常都是“双模态”预训练,常见的包括“文本-图片”、“文本-视频”、“视频-音频”等模态类型组合。假设我们有“文本-图片”两种模态数据,需要联合学习三种预训练模型:文本模态自身的预训练模型,图片模态自身的预训练模型,以及两个模态之间的语义对齐预训练模型。从模型结构来说,目前主流的结构有两种:双流交互模型以及单流交互模型。

文本编码器代表一个流,一般采用Transformer模型捕捉文本单词之间的关系;图片编码器代表另外一个流,一般也是采用Transformer模型,对于图片来说,一般用Faster-RCNN模型识别出图片中包含的多个物体及其对应的矩形位置信息,将高置信度的物体及其对应的位置信息作为图片侧Transformer的输入,用来学习图片中物品的相互关系;在两个流之上,再加入额外的Transformer模型,用于融合两个模态的语义映射关系。在这种双流结构上,模型同时学习文本预训练目标、图片预训练目标,以及图片-文本对齐预训练目标。一般文本预训练目标和标准的Bert做法类似,通过随机Mask一部分文本单词的语言模型来做;图片预训练目标类似,可以Mask掉图片中包含的部分物品,要求模型正确预测物品类别或者预测物品Embedding编码;为了能够让两个模态语义对齐,一般还要学习一个跨模态目标,常规做法是将对齐语料中的“文本-图片”作为正例,随机选择部分图片或者文本作为负例,来要求模型正确做二分类问题,通过这种方式逼迫模型学习两种模态间的对齐关系。典型的双流模型包括LXMERT、ViLBERT等。

典型的单流交互模型结构如上图Unicoder-VL模型所示。单流和双流的区别在于:单流模型只用一个Transformer,而双流模型,如上所述,需要三个Transformer各自分工协作。输入的图片,经过上述的Faster-RCNN物体识别和位置编码后,和文本单词拼接,整体作为Transformer模型的输入。也就是说,单流模型靠单个Transformer,同时学习文本内部单词交互、图片中包含物体之间大的交互,以及文本-图片之间的细粒度语义单元之间的交互信息。单流模型的预训练目标,与双流交互模型是类似的,往往也需要联合学习文本预训练、图片预训练以及对齐预训练三个目标。典型的单流模型包括Unicoder-VL、VisualBERT、VL-VERT、UNITER等。
从两阶段模型到四阶段模型
一般我们解决NLP问题有两个阶段:第一阶段是模型预训练阶段,预训练模型从文本等信息中学习语言知识;第二阶段是Fine-tuning阶段,根据手上的有监督数据,对模型参数进行微调,以获得更好的任务效果。
很多时候,我们手头上的任务数据有很强的领域性,比如可能是计算机领域的,因为预训练数据一般具备通用性,即使大量预训练文本里包含部分计算机类的文本,整体占比也很小。于是,这种情况下,由于领域差异比较大,预训练模型带给手头任务的收益,就没期望中那么大。一种直观的,也是不少人在用的解决方案是:把领域性文本,也加入到预训练数据中,一同参与预训练过程,这样能够增加预训练文本和手上任务的相似性,就能提升任务效果。事实上,这样做也确实能解决这个问题。但是,有一个问题:预训练阶段往往会兼顾模型的通用性,尽可能兼顾各种下游任务,希望模型能在不同领域都有效。而且,从趋势看,数据规模和模型规模会越来越大,也就是训练成本会越来越高。所以,这种把领域数据添加到预训练数据一起训练的做法,一则影响模型通用性,二则实现成本高,看上去就不是特别好的方法。
第一阶段仍然采取大数据、大模型,走通用普适、各种任务都能受益的路子,不特意考虑领域特点,因为兼顾不过来;第二阶段,在第一阶段训练好的通用预训练模型基础上,利用领域数据,再做一次预训练,等于把通用的预训练模型往领域方向拉动一下。这样两个阶段各司其职,有独立的优化目标,也能兼顾通用性和领域适配性。

任务预训练:在前两个预训练模型基础上,比如从第二个阶段里面的多个不同的领域预训练模型中,选择和手头任务适配的那个领域预训练模型,在这个模型基础上,用手头数据,抛掉数据标签,再做一次预训练,无论手上任务数据有多少。