rethinking imagenet pre-training
Rethinking ImageNet Pre-training 论文笔记_AI之路-CSDN博客论文:Rethinking ImageNet Pre-training论文链接:https://arxiv.org/abs/1811.08883Kaiming He这篇文章以计算机视觉中的目标检测、实例分割和人体关键点检测领域为例,思考预训练模型是否真的那么重要,最后基于实验结果得出结论:基于随机初始化的网络参数(train from scratch)训练模型的效果并不比基于ImageNet数...https://blog.csdn.net/u014380165/article/details/84557356?spm=1001.2014.3001.5501如何评价何恺明等 arxiv 新作 Rethinking ImageNet Pre-training? - 知乎[1811.08883] Rethinking ImageNet Pre-training https://www.zhihu.com/question/303234604
https://www.zhihu.com/question/303234604
用不用预训练模型是工程上经常会遇到的情况,通常来讲,小数据集的话是建议用预训练模型的,效果还是比较显著的,用迁移学习的思路去做,关于迁移学习有时候可能直接用预训练的模型做特征提取,后面再训一个小的fc可能就能解决问题,大一点的数据集从头训练的也很多,train from scratch就是想改网络的话会很好,预训练改网络的话会比较麻烦,改改pooling或者层的话就对不上预训练的结构了。本文是何凯明的作品,写的也不错,这波属于重读了,几个点:1.BN和epoch管够的话,random init不比pretrained的效果差,要好,2.pretrained在小数据集fine-tuning时也没有正则化的作用,10k的coco数据,random init还是比pretrained的好,但是1kcoco的话,pretrained要明显优于random init.当然这些现象下面也藏着很多值得分析的点。值得我们去想的就是什么情况pretrained,什么情况下自己去train from scratch会更好一点,此外在MAE的背景下,看看文章认为通用的pretrained model是否可行。
这边也提一下scratchDet的作者关于train from scratch的观点:1.需要能够稳定梯度的优化手段(比如clip_gradient、BN、GN、SN、等等)。2.训练足够多的epoch与合适的学习率。3.对于小数据集,在训练时需要一定的数据增广。
1.Introduction
A path to ‘solving’ computer vision then appears to be paved by pre-training a ‘universal’ feature representation on ImageNet-like data at massive scale。for object detection in particular they are small and scale poorly with the pre-training dataset size. That this path will ‘solve’ computer vision is open to doubt.在类似imagenet类数据集上预训练通用的特征标识来解决CV问题,但是目标检测来说,提升很小并且随着pretraining数据集大小扩展性很差,现在回头来看,确实如果,MAE类似作品都采用的nlp自监督的方案在海量的image上且patch做自监督来获取通用的特征表示,用imagenet这种监督方案来获取特征表示并不是一个好的路径。
(i) we use normalization techniques appropriately for optimization, and (ii) we train the models sufficiently long to compensate for the lack of pre-training.如果有适当的normalization和足够长的训练时间,那么train from scratch是完全可行的。并且train from random initialization on coco can be on par with its imagenet pretraining.效果不比预训练差。
2.Methodology
model normalization and training length,这是必要且仅有的两个修改,控制变量的因素。
2.1 normalization
normalization是很重要的,它包括normalized parameter initialzation and activation normalization layers. BN是最常用的normlization方式,partially makes training detectors from scratch difficult.主要是因为与分类不同,检测通常使用高分辨率输入进行训练,因此目标检测任务的bs参数比图像分类任务要小,由于显存的限制,这减少了bs,而小的bs会严重降低BN的准确性,(BN层的计算在batch size较小时受batch size参数影响较大,batch size越小,参数的统计信息越不可靠),如果用pre-trained模型可以避免这个问题,因为fine-tuning时可以使用预训练batch的统计量作为固定的参数,但是train from scratch就不行了,冻结BN的话就无效了,因为train from scratch检测器的话,只能选用小的bs,bs又不准,直接冻结bs,则训练效果肯定不好,因此影响train from scratch检测的关键也在这个normalization上,怎么办?作者尝试了两种有助于缓解小bs的normalization的策略(平时在训练检测模型时,也要注意这个问题,自己的显存有的时候并不能用大的bs就要考虑一些正则化的策略了,否则BP的梯度就不稳定,模型可能不收敛了)。
1.GN:采用GN代替BN,因为GN层的参数计算不依赖batch size的大小,因此就不存在参数计算不准确的问题。
2.SN:采用跨卡的BN层(synchronized batch normalization),跨卡BN层是传统BN层的优化版,表示BN层参数的计算是基于多个GPU的批次数据进行的,举个例子,假设某个检测模型的单卡batch size设置为8,那么传统的BN层在计算参数时不管你的训练GPU有多少块,都是基于8个样本来计算的;而跨卡BN层的参数计算和训练的GPU数量相关,假设有4块GPU,那么BN层的参数就基于4*8=32个样本计算,这样计算得到的数值相比基于8个样本要可靠得多。
Our experiments show that both GN and SyncBN can enable detection models to train from scratch.作者的实验表明GN和SN都可以从头训练检测器,甚至不用GN,SN,只要有合理的normalization initialization,VGG的检测器也能收敛。
2.2 Covergence
预训练模型学习了很多在微调阶段不需要重新学习的低级特征,例如边缘纹理等,而train from scratch 需要去学习这些低级和高级的语义特征,so more iterations may be necessary for it to converge well.所以需要更多的迭代才能收敛。With this motivation, we argue that models trained from scratch must be trained for longer than typical fine-tuning schedules.作者认为从头训练比典型的微调需要更长的训练时间。
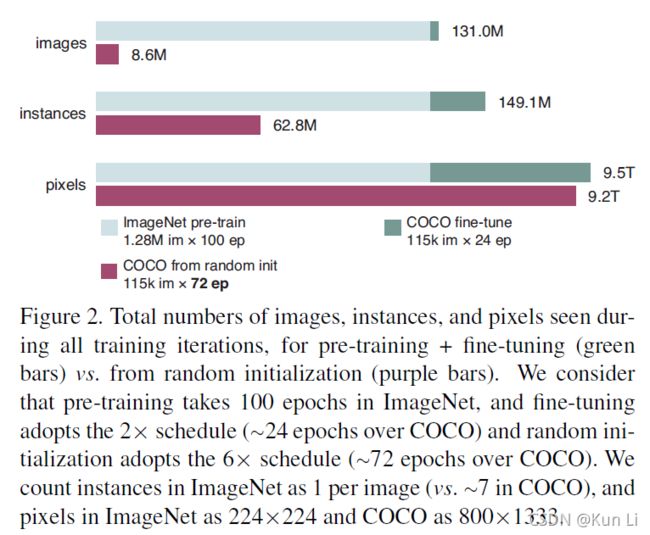
如上图所示,作者做了三个对样本粗略的定义,图片数量,实例数量和像素数量,例如一张图片训了100epoch就记作100张图,1个schedule是90k iteration,上图中,绿线是在imagenet上预训练100轮和在coco上fine-tuning了2xschdule,大概24个epoch,180k次iteration的模型,紫线是直接在coco上random init了6xschedule,大概72个epoch的模型,从训练时间上看,random init的比pretrained的模型要长3倍,但实际上从图像数量的角度看,train from scratch需要的图片要比pretrained的少的多,主要是因为coco的图像分辨率要高的多,从pixel上看,两者是接近的,实际上train from scratch的效果不比微调的效果差,主要有足够的训练数据和训练时长。
4.experimental setting
结构上用GN或SN,fine-tuning和train from scratch都用。学习率只在最后60k和20k时降低10倍,其他迭代不变。初始学习率是0.02,weight decay是0.0001,momentum是0.9,用SGD,每张卡两个图。
5.results and analysis
coco train2017:118287 imags,val:5000,
5.1 Baselines with GN and SN
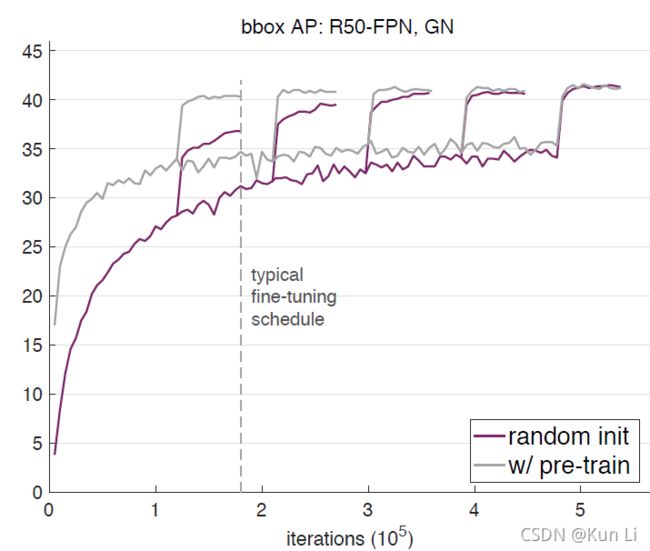
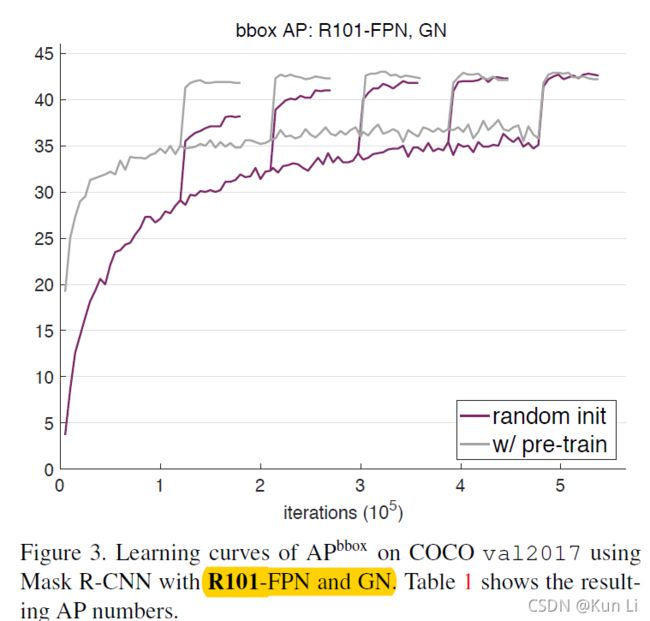

上面前两个图是resnet50和resnet101在GN下的结果,第三个图是resnet在SN下的结果。解释下中间有曲线跳跃,常规的Mask-RCNN算法使用预训练模型参数进行初始化,然后fine tune 90k次得到结果。而上图中的5次跳跃分别表示迭代次数是90k的2倍、3倍、4倍、5倍、6倍时模型第一次修改学习率(倒数第60k次迭代)的效果跳跃,因此上图是将5张收敛曲线合并在一起的情况。其次,在每次跳跃后,曲线在平缓上升阶段还有1次明显的上升,那是第2次改变学习率(倒数第20k次迭代)时模型效果的提升。举个例子,比如迭代次数是90k的2倍时(一共迭代180k)的这条收敛曲线,曲线在第120k(倒数第60k)时学习率缩小为原来的1/10,因此效果有个明显的上升,然后在第160k(倒数第20k)是学习率再次缩小为当前值得1/10时,效果上还有一个上升。另外4条迭代次数分别是270k、360k、450k、540k的曲线也是同理。
上图中的结论为:
1.fine-tune在2x时就达到了接近最佳状态,但是这个时间对train from scratch是不够的。
2.train from scratch在5x,6x时可以赶上fine-tune时模型,当他们收敛时,他们的ap并不比fine-tune差。
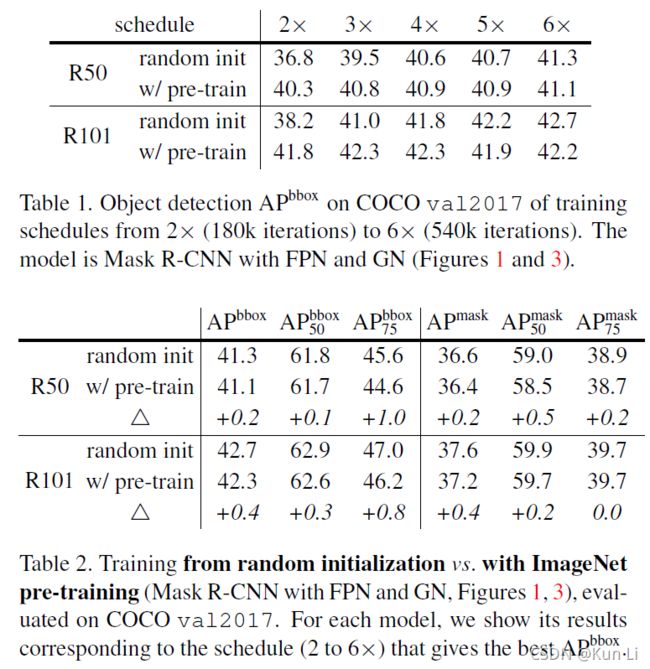
5.2 enhanced baseline
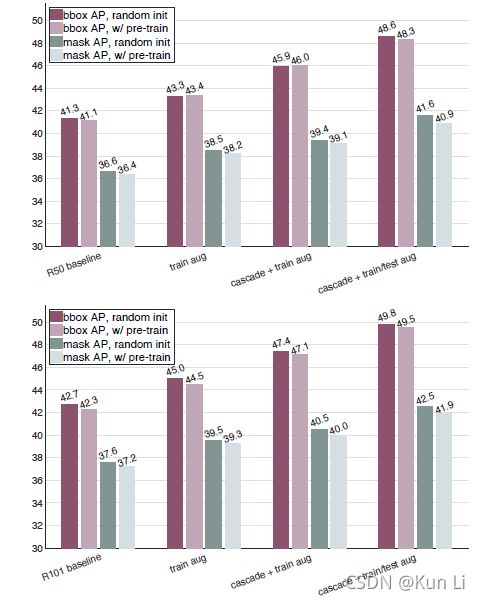
5.3 training from scratch with less data
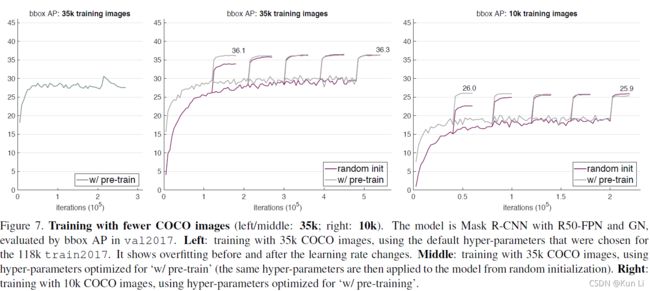
with substantially less data (1/10 of COCO),models trained from scratch are no worse than their counterparts that are pre-trained.作者发现用1/10数据,train from scratch也不如pre-trained模型差。
上图左和中都是在原始118kcoco数据上采样的1/3的35k数据训练的结果,右图是采样了1/10左右的数据,左图中,除了降低训练数据量,其他超参数和118k数据训练的模型是一致的,直接采用了pretrained,模型也存在过拟合现象(随着训练的增长,精度不变甚至下降,尤其是在last 60k,lr变化时,精度明显下降),It suggests that ImageNet pretraining does not automatically help reduce overfitting.这表明,pre-trained不能自动帮助减少过拟合。意思就是在一个很大的数据集上预训练之后迁移到一个样本较少的场景之后(当然超参是和小场景不匹配的),也无法避免过拟合,fine-tune效果不明显,如果直接train from scratch在一个小数据上,确实很容易过拟合。因此作者改了超参,中图和右图是作者利用网格搜索获得的新超参,用来降低其过拟合的风险,可见random init和pretrained的模型也是五五开的,尽管数据比较少。最右侧的图是10k上测试,在这个量级的数据上,fine-tune和train from scratch的结果还是相差不大的。
5.4 breakdown regime
更加极端的情况,作者只用1k的coco数据做训练,是fine-tune和train from scratch两个共同使用的训练数据,想验证,在任意小的数据集上,这种趋势能不能得意保留,显然是不行的,不过这里有个极限,作为一线算法工程大多就是靠经验了,小样本分类或者检测任务,其实1k图对于一个类别不太多的简单任务绝对足够了,比如banner图上文字区域检测,商品区域检测,当然简单场景非常容易过拟合。

损失函数看起来是没问题的,甚至train from scratch的损失函数下降的更多,但是pretrained的ap有9.9,train from scratch只有3.4,原因呢?We suspect that the fewer instances (and categories)
has a similar negative impact as insufficient training data.样本数太少了。
6.conclusion
1.不改变网络结构下,目标任务的train from scratch是可行的。实践中就是样本少pretrained,样本还行,train from scratch,但是实践中,问题很多,比如说有的类多,有点类少,单类在1k左右就算还可以了。
2.train from scratch需要训练更多iteration,实践中看ap吧,loss不下降,ap不怎么变化,基本就ok,训练时间太长等不起。
3.train from scratch比一定比pre-trained的效果要差,甚至在10k的coco上,有1w张的检测图,我一般就不加载预训练模型了,比如ocr,有一万张可以fine-tune的图的话,大概率会train from scratch.其实小样本就怕过拟合,泛化性会很差。
4.imagenet预训练加速了收敛速度,即便实在大样本的下游数据上,fine-tune肯定收敛的更快。如果在一些赶时间的项目上,考虑finetune是个好方案。
5.imagenet预训练的模型不一定有助于减少过拟合。
6.检测任务比分类对位置更敏感,imagenet预训练帮助很少。
作者后续的几个问答也很有意思,结合当下mae的背景,imagenet预训练其实也是监督学习的一种,确实不算是对下游精细化任务的一种通用的特征提取模型。整体读完,感受BN很重要,对梯度的约束,让信息流空间更平滑,梯度更集中确实很有用,另外在下游子任务中,其实有个边界,过小的任务还是考虑pretrained会好一点。
2021.12.15更新,在一个三分类数据集上测试(1w6左右样本),数据是创意图片数据和imagenet差距比较大,分别使用resent,resnetv1d,用pretrained model和train from scratch比较,pretrained的均下降2个点左右,事实上,是否采用pretrained和数据集关系很大。