SLAM_信息矩阵&协方差矩阵
目录
1 协方差矩阵基本概念
2 方差和协方差的定义
3 从方差/协方差到协方差矩阵
4 SLAM中协方差矩阵、信息矩阵的应用和理解
SLAM状态估计中信息矩阵 Ω 的应用
参考
1 协方差矩阵基本概念
如何直观地理解「协方差矩阵」?
什么是协方差,怎么计算?为什么需要协方差?
感性理解:
均值描述的是样本集合的中间点,它告诉我们的信息是很有限的,而标准差给我们描述的则是样本集合的各个样本点到均值的距离之平均。以这两个集合为例,[0,8,12,20]和[8,9,11,12],两个集合的均值都是10,但显然两个集合差别是很大的,计算两者的标准差,前者是8.3,后者是1.8,显然后者较为集中,故其标准差小一些,标准差描述的就是这种“散布度”。之所以除以n-1而不是除以n,是因为这样能使我们以较小的样本集更好的逼近总体的标准差,即统计上所谓的“无偏估计”。而方差则仅仅是标准差的平方。
标准差和方差一般是用来描述一维数据的,但现实生活我们常常遇到含有多维数据的数据集,最简单的大家上学时免不了要统计多个学科的考试成绩。面对这样的数据集,我们当然可以按照每一维独立的计算其方差,但是通常我们还想了解更多,比如,一个女孩子的长相是否和学习成绩存在一些联系啊。协方差的结果有什么意义呢?如果结果为正值,则说明两者是正相关的(从协方差可以引出“相关系数”的定义),也就是说一个女孩子越漂亮学习越好。结果为负值就说明负相关的,女孩子越漂亮就学习越差。如果为0,也是就是统计上说的“相互独立”,也就是女孩子漂不漂亮和成绩没有关系。
SLAM状态估计中:均值可看作是对变量最优值的估计,而协方差矩阵则度量了它的不确定性。
2 方差和协方差的定义
在统计学中,方差是用来度量单个随机变量的离散程度,其中,方差的计算公式为
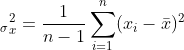
其中,n 表示样本量,符号  表示观测样本的均值,这个定义在初中阶段就已经开始接触了。
表示观测样本的均值,这个定义在初中阶段就已经开始接触了。
协方差则一般用来刻画两个随机变量的相似程度(统计两组数据之间的协同程度(相关程度、相关性,变化规律是否一致),遍历不同组数据的方差)。在此基础上,协方差的计算公式被定义为
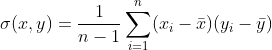
在公式中,符号 、 分别表示两个随机变量所对应的观测样本均值,据此,我们发现:方差
分别表示两个随机变量所对应的观测样本均值,据此,我们发现:方差 ![]() 可视作随机变量 关于其自身的协方差
可视作随机变量 关于其自身的协方差![]() .
.
参考2:如何通俗易懂地解释「协方差」与「相关系数」的概念?
可以通俗的理解为:两个变量在变化过程中是同方向变化?还是反方向变化?同向或反向程度如何?
你变大,同时我也变大,说明两个变量是同向变化的,这时协方差就是正的。
你变大,同时我变小,说明两个变量是反向变化的,这时协方差就是负的。
从数值来看,协方差的数值越大,两个变量同向程度也就越大。反之亦然。
协方差 表达式的另一种写法:
![]()
如果有X,Y两个变量,每个时刻的“X值与其均值之差”乘以“Y值与其均值之差”得到一个乘积,再对这每时刻的乘积求和并求出均值(其实是求“期望”,简单认为就是求均值了)。
拓展:相关系数 概念

3 从方差/协方差到协方差矩阵
根据方差的定义,给定d个随机变量![]() ,则这些随机变量的方差为
,则这些随机变量的方差为

其中,为方便书写, ![]() 表示随机变量
表示随机变量  中的第i个观测样本, n表示样本量,每个随机变量所对应的观测样本数量均为n 。对于这些随机变量,我们还可以根据协方差的定义,求出两两之间的协方差(理解协方差矩阵的关键就在于牢记它度计算的是不同维度之间的协方差,而不是不同样本之间),即
中的第i个观测样本, n表示样本量,每个随机变量所对应的观测样本数量均为n 。对于这些随机变量,我们还可以根据协方差的定义,求出两两之间的协方差(理解协方差矩阵的关键就在于牢记它度计算的是不同维度之间的协方差,而不是不同样本之间),即
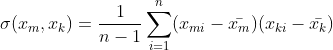
因此,协方差矩阵为
其中,对角线上的元素为各个随机变量的方差,非对角线上的元素为两两随机变量之间的协方差,根据协方差的定义,我们可以认定:矩阵  为对称矩阵(symmetric matrix),其大小为 dxd 。
为对称矩阵(symmetric matrix),其大小为 dxd 。
4 SLAM中协方差矩阵、信息矩阵的应用和理解
视觉SLAM框架中的协方差矩阵用来做什么
推导香港科技大学沈老师的VINS-MONO框架公式的时候,第一部分为IMU预计分,那么预积分之后就要求解各观测量的协方差矩阵。那么为什么要求解协方差矩阵,作用是什么呢?沈老师在公开课中说:“ IMU和视觉信息融合也可以粗暴的叫做加权平均,那么加权就是每个测量值对应的协方差矩阵”。
泡泡机器人创始人 刘富强 强哥的解答:
权重矩阵又称为信息矩阵,它是协方差矩阵的逆,因为每个残差都看作高斯分布,而每个高斯分布都可以归一化为标准的高斯分布N(0,1),这种归一化操作是减去均值求平方然后除以方差(?)。残差预期均值为0,所以不用减只需要除以方差,扩展到多维的话就变成了信息矩阵加权形式(?)。
就是说计算出协方差矩阵,然后除以协方差矩阵。IMU和视觉融合的过程其实就是对IMU的预积分残差以及视觉信息的重投影误差进行量纲的过程,这样两个归一化之后才可以直接线性相加。
OrbSLAM的Optimizer函数用到的信息矩阵如何理解?
例子:采用G2O图模型经过优化后,误差只是减少并不是完全消除,不能消除的误差去那了呢,当然是每条边分摊喽,那么问题来了,每条边误差分担多少呢,难道每条边都分担一样多的误差吗,当然也是可以的,但这样明显不科学,因为有些边在构建的时候已经很准确了,所以这个时候就有了信息矩阵,它表达的是每条边要分摊总误差的多少,嗯 ,这样就科学多了。提一句,如果你的信息矩阵是单位矩阵,那么误差就是均摊啦。
ORB-SLAM3中 函数Optimizer::BundleAdjustment中 如下设置信息矩阵:
// invSigma2: 第一层等于1 第二层等于1/1.2 第三层等于1/(1.2^2) 依次类推
const float &invSigma2 = pKF->mvInvLevelSigma2[kpUn.octave];
e->setInformation(Eigen::Matrix2d::Identity()*invSigma2);即此处信息差矩阵形式为:

参考1:
首先,在特征提取中,我们会构造图像金字塔,然后在不同尺度上提取特征点。若我们在比较上层的图像上提取特征点,由于图像经过缩小,所以坐标比较小,因此我们需要将该坐标乘以尺度,让它的坐标恢复在最底层上的尺度,
乘以尺度后,坐标会扩大。我们再看看在BA优化中的情况,误差项是重投影误差,即观测到的像素坐标减去估计的像素坐标,这个误差也会由于尺度而扩大。不同层提取的特征点误差扩大的程度不同,有些扩大程度较大的会被后面的核函数抑制或者被卡方检验视为outlier。因此,我们把所有误差项全部除以对应的尺度平方。
参考2:
// setInformation,即设置信息矩阵,也是协方差,
// 表明了这个约束的观测在各个维度(x,y)上的可信程度,
// 在我们这里对于具体的一个点,两个坐标的可信程度都是相同的,
// 其可信程度受到特征点在图像金字塔中的图层有关,图层越高,可信度越差
// 为了避免出现信息矩阵中元素为负数的情况,这里使用的是sigma^(-2)
SLAM状态估计中信息矩阵 Ω 的应用
一句话总结:
在采用最小二乘法求解状态向量x时,作为误差项的权重,以赋予不同传感器不同的信任度。
问题定义:
待估计的状态向量记为x,用的观测函数记为f(x), 当然这里有很多个观测,就有很多个(记为i个)观测方程(超定问题:方程个数>未知数个数),在状态x下,经过观测函数f(x)(映射关系:如重投影误差之类的投影关系)得到预测值 ![]() , 这里需要跟观测值
, 这里需要跟观测值  进行对比,以计算误差,然后使用最小二乘进行求解。
进行对比,以计算误差,然后使用最小二乘进行求解。

误差函数(Error Function)定义:
如下式所示。
我们设定error符合mean = 0 的高斯分布;假设我们还知道我们的sensor有多好,用信息矩阵(information matrix) Ω表示。在把error转换成平方差 square error的时候,我们把information matrix Ω引入作为 权重 weight。

问题转换:
更一般的我们将 F(x) 表示全局误差(标量值,F(X)是所有error的形式,具体可以展开成sum of squared error terms 或者sum of 别的 error terms;正常来说就是求导找极值,当然也有非线性形式要处理。),则这里使用 ![]() 表示一个观测对应的平方误差项,使用上面的公式替换后对状态x进行求解。即当前状态x的估计值为:
表示一个观测对应的平方误差项,使用上面的公式替换后对状态x进行求解。即当前状态x的估计值为:
![]()
参考: SLAM基础——聊一聊信息矩阵 :那为什么需要信息矩阵呢?
因为系统可能有很多传感器,传感器精度越高,对应的信息矩阵information matrix里面的系数会很大(这里是越大越好,因为它是协方差矩阵的逆矩阵),系数越大代表权重越高,表达的信息越多,在优化的过程中就越会被重视。用一个形象的数学表达式表达就是:
const int INT_MAX=1e9;
argmin( INT_MAX*(x-3)^2+1/INT_MAX*(x-1)^2))那么INT MAX就代表我们的精确传感器,那么优化的结果肯定是 x=3;也就是说,我们更加相信我们好的传感器

接下来就是一个一个求解最小二乘问题了。
参考
6.5 矩阵的运算及其运算规则
信息矩阵在图优化slam里面的作用
Ch4. Least Squares - An Informal Introduction - Sensing and State Estimation II - uni-bonn
SLAM基础——聊一聊信息矩阵