模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
作者:邱震宇(华泰证券股份有限公司 算法工程师)
知乎专栏:我的ai之路

本文是模型压缩实践系列的第二篇,方法参考自论文:BERT-of-Theseus: Compressing BERT by Progressive Module Replacing。本文方法与上一篇讲到的layerdrop有一些相似点,同样聚焦工程实践,基本的核心思想其实并不复杂,非常容易应用到实际的项目场景中。本人也实现了tensorflow版本供大家参考,链接如下:
https://github.com/qiufengyuyi/bert-of-theseus-tf
qiufengyuyi/bert-of-theseus-tf github.com
本文内容分为如下几点:
1、对论文方法的详细介绍,包括论文方法的核心思想,具体方法步骤以及一些实现的细节。
2、对官方的pytorch实现代码的简单介绍。
3、对本人实现的tensorflow版本的描述,并给出该方法在中文NER任务上的实际效果。(基于bert-mrc方法)
bert-of-theseus思想概述
bert-of-theseus与传统的知识蒸馏的核心思想比较相似,主要是通过一些方法让压缩后的模型能够与原始的模型在性能和表现上尽量接近。目前也有很多针对bert的知识蒸馏的方法,但是这些方法在实际生产实践中都有一些局限性:
大部分的针对bert的蒸馏方法,比如distilbert、tinybert等,都是直接作用在bert预训练阶段,让模型在预训练的时候就适应模型压缩后的场景,然后再用修正后的预训练模型做下游任务的finetune。我相信除了一些大厂外,绝大部分企业都没有时间、也没有硬件条件去做这个事情,只能被动得去等待大厂释放一些训练好的模型。而这些方法直接作用的finetune阶段时,压缩后的模型往往精度下降得比较多,并不能替换原始的模型。(例如上一篇介绍的layerdrop方法,相比原始模型,精度一般会下降6个百分点左右)
传统的KD方法在训练时,为了让压缩后模型尽量与原始模型相似,会设计一些loss来计算两个模型之间的差异程度,比如原模型和新模型的输出概率的kl-divergence、mean-squared loss等,有的复杂方法会将两个模型的中间层的权重也会设计相应的对标loss。这些loss之间的权重关系也需要我们取精调,因此要取得好的效果,在模型的训练设计上也要花费一定的成本。
基于上述问题,bert-of-theseus提出了利用module replacing的方式来做模型压缩。module可以是一个模型中具备相似特性的网络子结构,如上一篇layerdrop中所述的group一样,一个module可以是n个transformer layer,也可以是n个head,其中n>=1。本文针对的是bert模型的压缩,因此将transformer layer作为module的基本元素。我们将原始的模型简称为 ,压缩后的模型简称为 。假设我们模型层数的压缩比为m=2,即压缩一半的层数。原始bert-base为12层,压缩后为6层,那么对于来说,第i个module为 ,每个module包含一个transformer layer。对于,我们将12层分隔成6个module,每个module包含两个transformer layers,得到 ,此时我们可以将 和 建立一对一的映射关系。之后我们就可以进行正式的压缩步骤了。
整个过程都是在具体某个NLP下游任务的finetune阶段实施,而不是在预训练阶段。同时我们需要预先使用12层原始bert模型先finetune出一个好模型作为 。为了加速整个训练过程,我们使用的部分权重来初始化 的所有module,最简单的做法是将前六层的 transformer layer权重直接赋值给 的六层transformer layer。
整个过程分为两个阶段,第一阶段是模块替换训练阶段,这一段同时考虑了 和 ,让两个模型都参与到训练中;第二阶段为单独 的finetune阶段,目的是为了让所有 的模块完整参与到训练任务中。具体过程如下:
module replace training
module replace的基本思想很简单,就是在训练时将 的某一个module平行替换掉 的对应module。当然我们不会将每个都替换掉,这就相当于是直接用6层的bert进行finetune了。假设当前第i个module的输出为 ,则原始模型第i+1个module的前向计算输出为: 。下面给出module replace后的计算过程:
1、假设当前处理第i+1个module,我们通过一个伯努利分布,采样一个随机变量 ,其中采样的概率为p, 有p的概率为1,1-p的概率为0。
2、第i+1个module的最终输出如下: 。我们可以将 看做是一个hard型控制门,控制当前module是使用原始的双层layers还是简化后的单层layer。替换的流程可参见论文配图:
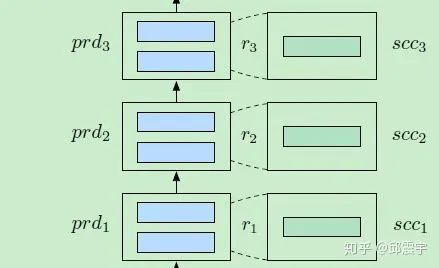
3、整个综合模型仍然使用下游任务loss来进行finetune训练。这里需要关注一个训练细节:在梯度传递的时候,所有属于 的权重参数都freeze不参与梯度计算,而 的相关module权重参数会参与梯度更新。
finetune和inference
第一阶段结束后,由于每个step训练时,只会有部分不同的 module参与到训练中,所有的 并没有整合到一起参与到任务训练中。因此需要添加一个post-training过程,将所有重新组合成完整的transformer,并沿用 的embedding layer和output layer(因为之前训练时这些权重参数都是freeze的,可以直接拿来用),在相同的训练数据和下游任务场景下进行finetune。
对于第一阶段训练时将 的权重freeze不参与训练,个人认为其原因可能是 的权重在一开始的原始finetune阶段已经达到一个较为稳定的状态,如果此时让其参与到和 的整合训练中,反而会导致遗忘问题。另外,我们的目的是让 module尽量得到更新,如果让 module参与到梯度更新,可能会让 module被忽略。另外,freeze 的权重也能提升整个模型训练的效率,减小模型训练所需的steps。当然,这个是我个人的观点,如果有同学有深入的研究,欢迎一起讨论。
替换概率策略
对于整个方法来说,除去原始NLP任务中的超参数外,只有一个超参数需要关注,即替换概率p。一般来说,使用一个常量0.5就可以达到比较不错的效果(亲测)。但是论文还提出了一个线性策略来为每个训练step设置不同的替换概率,其具体公式如下:
其中,t表示当前的训练step。k表示每个step的增长率,b表示初始的替换概率。通过这种策略,在初始阶段,我们的让更多的 参与进来,能够提升整个模型的质量,得到更小的loss,从而使得整个训练过程平滑不会过于震荡;在训练后期,我们的模型整体都比较好了,此时可以让更多的 参与进来,让模型逐渐摆脱对的依赖,使得我们能够平稳过度到第二阶段。
另外,在替换训练初始阶段,对于 ,我们计算所有的期望学习率:
其中, 表示训练过程中我们得到的替换模块数量的期望值,lr表示整个训练我们设置的学习率。可以看到,我们相当于在训练阶段间接得给学习率应用了一个warm-up策略,间接得提升了模型训练的效率。
pytorch实现
官方很贴心得放出了源码(就喜欢这种务实的风格),详见:github.com/JetRunner/BE。其实代码本身很简单,他基于的是huggingface的pytorch-transformer实现。对其中部分代码进行了修改。下面列出核心的部分:
if self.training:
inference_layers = []
for i in range(self.scc_n_layer):
if self.bernoulli.sample() == 1: # REPLACE
inference_layers.append(self.scc_layer[i])
else: # KEEP the original
for offset in range(self.compress_ratio):
inference_layers.append(self.layer[i * self.compress_ratio + offset])
else: # inference with distilled model
inference_layers = self.scc_layer其中,self.bernoulli通过伯努利分布采样到替换的门开关,若替换,则直接将scc的layer添加到模型中;若不替换,则根据当前层数的位移,将对应位置的prd的layer添加到模型中。
然后我们仍然像之前那样使用bert,在用bert预训练模型初始化权重时,需要添加如下代码:
scc_n_layer = model.bert.encoder.scc_n_layer
model.bert.encoder.scc_layer = nn.ModuleList([deepcopy(model.bert.encoder.layer[ix]) for ix in range(scc_n_layer)])即,使用 的前n层初始化n层 。
另外,对于线性替换概率策略实现也比较简单:
class LinearReplacementScheduler:
def __init__(self, bert_encoder: BertEncoder, base_replacing_rate, k):
self.bert_encoder = bert_encoder
self.base_replacing_rate = base_replacing_rate
self.step_counter = 0
self.k = k
self.bert_encoder.set_replacing_rate(base_replacing_rate)
def step(self):
self.step_counter += 1
current_replacing_rate = min(self.k * self.step_counter + self.base_replacing_rate, 1.0)
self.bert_encoder.set_replacing_rate(current_replacing_rate)
return current_replacing_rate每次训练更新梯度后,需要调用该scheduler的step方法更新替换概率。另外,关于k的选取,我建议可以先用常量p先训练一个模型,看大概需要多少step。然后使用公式:
TensorFlow实现
为了验证方法的有效性,我决定在之前的中文NER任务上进行验证测试。由于之前使用的是tensorflow框架,因此我需要将该实现用tensorflow重写。其实也不是很难,主要是在原来bert源码的基础上修改三个地方:
1、modeling.py中,修改transformer_model的实现,我们需要将scc的layer集成进去。由于实现时我不知道tensorflow有直接的伯努利分布采样实现,因此我采用了上一篇中实现layerdrop的方式。假设当前正在处理第i层:
compress_ratio = num_hidden_layers // succ_layers
sample_prob = tf.random_uniform(shape=[], minval=0, maxval=1)
# 替换概率越大,sample_prob大于replace_rate_prob的难度越高,condition越容易变成false,gate偏向1,因此更倾向于用suc替换pre
condition = sample_prob > replace_rate_prob
condition = tf.cast(condition, tf.bool)
gate = tf.cond(condition, lambda: tf.zeros_like(prev_output),
lambda: tf.ones_like(prev_output))
if is_training and not finetune_suc:
for layer_idx in range(succ_layers):
pre_layer_output = prev_output
suc_layer_output = single_layer_implement("suc_",layer_idx,prev_output)
# print("comress_ratio:{}".format(compress_ratio))
for offset in range(compress_ratio):
pre_layer_output = single_layer_implement("",layer_idx*compress_ratio+offset,pre_layer_output)
# print("predLayer:{}".format(pre_layer_output))
layer_output = gate * suc_layer_output + (1. - gate)*pre_layer_output
prev_output = layer_output
all_layer_outputs.append(layer_output)
else:
for layer_idx in range(succ_layers):
layer_output = single_layer_implement("suc_", layer_idx, prev_output)
prev_output = layer_output
all_layer_outputs.append(layer_output)核心在于生成gate。替换概率越大,我们倾向于打开使用scc 模块的开关门,关闭prd模块的开关门。另外替换只会发生在第一阶段的model replacing阶段。
2、modeling.py中,修改get_assignment_map_from_checkpoint的实现。因为我们的模型初始化时,需要将prd的前n层权重赋予scc的相应层。而原版bert中的权重初始化,是将当前我们定义的新计算图中的变量与bert预训练模型中的变量名称建立字典映射。但是现在我们需要将bert中的一个prd权重同时赋予新计算图中的prd变量和对应scc变量,因此需要建立两个字典映射,分别做这个事情。核心代码如下:
if re.search(r"bert\/encoder\/layer_\d+",name):
suc_layer_var_name = re.sub(r"layer_",suc_layer_prefix+"layer_",name)
if suc_layer_var_name in name_to_variable.keys():
assignment_map[name] = name_to_variable[name]
initialized_variable_names[suc_layer_var_name] = 1
initialized_variable_names[suc_layer_var_name + ":0"] = 1
suc_assignment_map[name] = name_to_variable[suc_layer_var_name]
initialized_variable_names[name] = 1
initialized_variable_names[name + ":0"] = 1
else:
assignment_map[name] = name_to_variable[name]
initialized_variable_names[name] = 1
initialized_variable_names[name + ":0"] = 1
else:
assignment_map[name] = name_to_variable[name]
initialized_variable_names[name] = 1
initialized_variable_names[name + ":0"] = 1最后我们需要返回原始的assignment_map以及suc_assignment_map。
3、optimization.py中,我们需要修改在第一阶段的梯度更新代码。即只更新scc的权重。
if not finetune_suc:
# only compute suc_layer
tvars_update = [var for var in tvars if re.search(r"suc_layer_\d+",var.name)]
else:
tvars_update = tvars4、上面是主要改动,其他地方就是调用模型的时候,实现替换概率策略时,使用tf.train.get_or_create_global_step()获取当前的step,然后使用我上面说的方法计算k。
验证结果
本次验证使用的基础模型时bert-mrc-focalloss,验证任务是中文NER。相关的内容可以参考我的另一篇文章:中文NER任务实验小结报告——深入模型实现细节。其中原始的模型的span-level f1分数为0.9580。我们需要验证在层数降低一半的情况下,简化模型是否能够得到一个较为理想的结果。
我主要做了几个对比实验:
1、按照论文的方法,进行两阶段的完整训练,使用常量替换概率0.5。
2、按照论文的方法,进行两阶段的完整训练,使用线性替换概率策略,初始替换概率设为0.3
3、只进行第一阶段的训练,验证post-training的有效性。
最终得到的结果如下:
通过实验验证,可以看到完整的压缩方法能够带来比较可观的结果,在整个模型inference性能提升40%以上的情况下,整个模型的精度只下降了1-2个百分点。其中,使用linear策略,能够得到更好的效果。而通过最后一个对比实验可以知道,post-training是有效的。
小结
个人认为,本文介绍的方法是可以应用到实际的项目中,其一是该方法不需要重新进行预训练过程,直接作用在下游任务finetune中,虽然整个finetune过程相比原来的情况增加了,但是相比于预训练的庞大耗时,可以说是很亲民了;其二是该方法的效果实测非常不错,在模型规模减掉40%多的情况下,模型的精度只下降了一点点,相比于之前尝试的layerdrop真的效果拔群。后续为了验证该方法的鲁棒性,会在更多的任务上进行验证,但至少在该中文NER数据集任务上,他的表现是很好的。
本文由作者授权AINLP原创发布于公众号平台,欢迎投稿,AI、NLP均可。原文链接,点击"阅读原文"直达:
https://zhuanlan.zhihu.com/p/112787764
个人微信:加时请注明 (昵称+公司/学校+方向)

