论文阅读笔记 | 三维目标检测——VoxelNet算法
如有错误,恳请指出。
文章目录
- 1.背景
- 2. 网络结构
-
- 2.1 体素特征表示
- 2.2 卷积特征提取
- 2.3 RPN网络
- 3. 实验结果
paper:《VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection》
1.背景
以往的3d检测器都难免利用了手工设计特征(hand-crafted),不够智能不能实现end-to-end地自动提取特征,而如果利用全部点云输入,处理点云可能搞到100k个点的数据可能会带来极大的计算量(其实这里是可以对输入进行采样的,不过对于一个大场景来说数据点确实有点大,这时候对点云量化确实是一个比较好的选择,具体需要结合特定的场景和数据量)。为此,VoxelNet提出一个端对端的3d检测器,对点云数据进行量化,避免复杂场景带来的高计算。
具体来说,VoxelNet将点云划分为等间距的3D体素,通过堆叠的VFE层对每个体素进行编码,然后3D卷积进一步聚合局部体素特征,将点云转换为高维体积表示。最后在RPN结构利用高维体积的特征表示来产生检测结果。
此外,在related work中,介绍了对中体素(voexl)的编码方法。比如,每个非空体素Voexl导出6个统计量进行特征编码;融合多个局部统计对体素进行编码;计算体素网格中的截断带距离(truncated signed distance)进行编码;或者对3d体素网格进行二进制(binary encoding)编码等等。
ps:这里稍微介绍一下什么是Truncated Signed Distance,简写为TSDF(Truncated Signed Distance Function)

详细参考资料见:三维建模中基于体素的TSDF模型是什么
2. 网络结构
VoxelNet是一个anchor-based、one-stage的网络,其整体的网络结构大致可以分为体素特征表示,卷积特征提取以及RPN提取候选框三个部分。结构图如下所示。
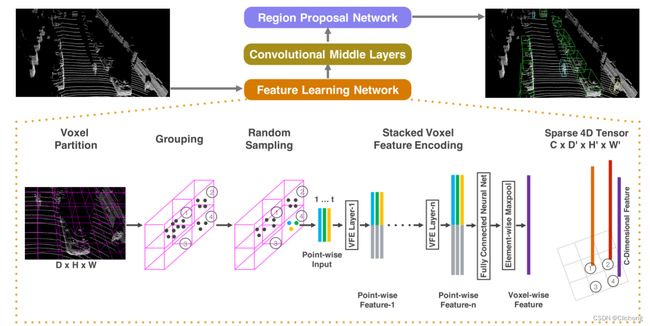
2.1 体素特征表示
这里以对kitti数据集中的车辆检测为例进行说明。首先这里对点云场景进行区域划分,只考虑分别沿着Z、Y、X轴在[−3,1] × [−40,40] × [0,70.4]米范围内的点云。设置点云体素的体积为0.4x0.2x0.2,那么即可获得10x400x352数量的体素集合,在每个体素中设置T=35为最大考虑点。也就是分配在每个体素中的点为一组,在当前体素中采样35个点来表征当前的体素。由于T是最大采样点,所以每个体素中的点数量是不平衡的,此时需要对这些数量不平衡的体素表征点做处理来编码成voxel feature。
对于每个体素中的点,具有xyzr是个特征(位置特征xyz+反射强度r),计算出体素的质心位置为vx,vy,vz,将每个点位置与质心位置相减,提取到相对坐标位置重新添加到每个点的特征上。那么,现在体素中的每个点具有7个特征:[xi, yi, zi, ri, xi −vx, yi −vy, zi −vz]。随后,将每个体素通过Voxel feature encodeing layer(VFE)结构处理,具体的操作如下所示。

这里原始的点特征作为point-wise input,逐点进行全连接层编码操作(这里的FCN包含MLP+BN+ReLU三个部分),获得point-wise feature,将其进行max pooling操作之后再拼接回去每一个点特征上。那么,现在每一个点的特征包括了原始特征进行MLP操作后的feature,以及进行max pooling聚合了局部信息的feature两个部分。当前层的VFE的输出作为下一层VFE的输入,point-wise feature的维度会不断增加,因为每一个VFE层都有两部分特征进行拼接。在具体实现上,这里会有2层VFE,参数为:VFE-1(7, 32)、VFE-2(32, 128),对于最后每一个点的特征都编码成128维度。对于最后一层VFE的输出,再使用FCN层编码处理,随后进行max pooling聚合当前所有点的特征,作为最后的voxel-wise feature。
2.2 卷积特征提取
经过上个步骤的处理,现在对每一个体素都进行了编码,获得其voxel-wise feature。那么,按刚开始所说的对车辆的采样方式具有10x400x352个体素,现在的特征维度即为128x10x400x352。现在利用3d卷积进行特征提取,扩大其感受野进行聚合体素特征。对车辆检测具体的3d卷积设置为:Conv3D(128, 64, 3, (2,1,1), (1,1,1)),、Conv3D(64, 64, 3, (1,1,1), (0,1,1))、Conv3D(64, 64, 3, (2,1,1), (1,1,1))。每一层3d卷积都包含BN层和ReLU层。那么,128 x 10 x 400 x 352的特征输入现在经过3层卷积处理后变成了64 × 2 × 400 × 352的特征输出。
2.3 RPN网络
RPN网络的具体参数与结构如下所示(图以及画得很清晰,这里就不再作过多的解释)。

可以看见,最后的feature map回有两个head,一个用来分类,一个用来回归。这里需要解释下为什么score map的channels是2,而regression map的channels是14。对于feature map上的每个特征点,VoxelNet只对车辆检测设计了一种先验框(prior box):la = 0.8, wa = 0.6, ha = 1.73 meters centered at za = −0.6 meters,同时对反向设置了0°和90°两个方向。也就是每个特征点上配置2中尺度相同但是方向垂直的两个先验框,所以score map的channels是2。而VoxelNet用(xa, ya, za, la, wa, ha, θa)一组7个的参数来表示3d候选框,所以一个piror预测7组参数,2x7=14,所以regression map的channels是14。
此外,VoxelNet的7个回归参数采用的是直接回归不分bin的方法,来直接回归ground truth的参数。非常的简洁明了,但是由于过于简单感觉后续可以改进其损失函数来提升精度。损失函数如下所示。对于车辆检测来说,在俯视图上最高置信度以及iou>0.6的anchor设置为正样本,iou<0.45的anchor设置为负样本,剩余阈值中的直接排除。


在训练过程中,VoexlNet还使用了一些数据增强的方法。
(1)随机平移与旋转,并且平移之后不同目标在俯视图上不存在重叠,即不发生碰撞。
(2)随机旋转,对点云坐标和真实检测框8个顶点坐标进行随机旋转。
(3)随机缩放,对点云坐标和真实检测框8个顶点坐标进行随机缩放。
对于kitti的行人和直行车配置等其他细节,可以查看论文。
3. 实验结果
验证集上的结果如下所示:

在网络的具体处理中,由于点云的稀疏性导致90%的体素中完全没有点数据,为了使用GPUs来进行并行加速训练,VoxelNet设置了一个Efficient Implementation操作如下所示。
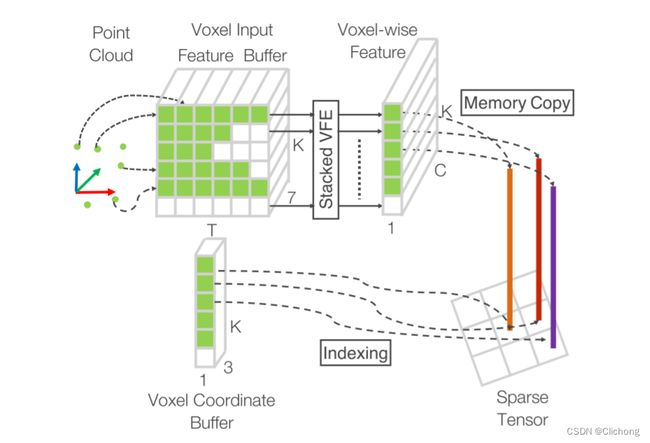
其中K是非空体素的最大数目,T是每个体素的最大点数,并且7是每个点的输入编码维度。在构建体素输入缓冲区之后,这些操作可在GPU上并行计算,实现稀疏体素结构重组为密集体素网格。