解析Disruptor:为什么它会这么快(一)-锁是坏的
原文地址http://mechanitis.blogspot.com/2011/07/dissecting-disruptor-why-its-so-fast.html
Martin Fowler has written a really good article describing not only the Disruptor, but also how it fits into the architecture at LMAX. This gives some of the context that has been missing so far, but the most frequently asked question is still "What is the Disruptor?".
Martin Fowler写了一篇很好的文章,讲了什么是Disruptor,和它为什么适合LMAX架构。那篇文章给出了一些到目前为止我还没讲的内容,但是问得最多的仍然是“什么是
Disruptor?”。
I'm working up to answering that. I'm currently on question number two: "Why is it so fast?".
我正在着手回答它。我先解决2号疑问:“为什么它这么快?”。
These questions do go hand in hand, however, because I can't talk about why it's fast without saying what it does, and I can't talk about what it is without saying why it is that way.
不过,这些问题其实是连在一起的,因为我无法只讲为什么它这么快而不讲它是什么,也无法只讲它是什么而不讲它为什么这么快。
So I'm trapped in a circular dependency. A circular dependency of blogging.
所以我被困在了一个循环依赖中。一个循环依赖的博文。
To break the dependency, I'm going to answer question one with the simplest answer, and with any luck I'll come back to it in a later post if it still needs explanation: the Disruptor is a way to pass information between threads.
为了打破这个依赖关系,我将用最简单的答案回答1号问题,并且幸运的话,我会在迟些的文章中回头讲解它,如果有这个必要:Disruptor是线程间传递信息的一种方式。
As a developer, already my alarm bells are going off because the word "thread" was just mentioned, which means this is about concurrency, and Concurrency Is Hard.
作为一个开发者,我的警铃早已经停了,因为刚刚提到了“thread”,意味着这是关于并发的,而并发是难的。
Concurrency 101
并发101

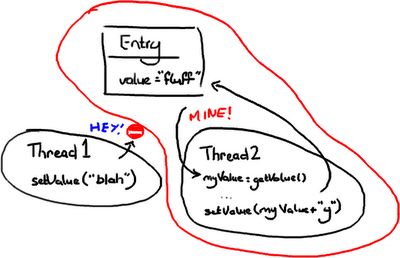
Imagine two threads are trying to change the same value.
想像两个线程正试着改变同一个值。
Case One: Thread 1 gets there first:
情况1:线程1先到:
1.The value changes to "blah"
值变为“blah”
2.Then the value changes to "blahy" when Thread 2 gets there.
然后当线程2到的时候值变为“blahy”
Case Two: Thread 2 gets there first:
情况2:线程2先到:
1.The value changes to "fluffy"
值变为“fluffy”
2.Then the value changes to "blah" when Thread 1 gets there.
然后当线程1到的时候值变为“blah”
Case Three: Thread 1 interrupts Thread 2:
情况3:线程1打断线程2:
1.Thread 2 gets the value "fluff" and stores it as myValue
线程2得到值“fluff”并存为myValue
2.Thread 1 goes in and updates value to "blah"
线程1进入并且把值更新为“blah”
3.Then Thread 2 wakes up and sets the value to "fluffy".
然后线程2醒来并把值设置为“fluffy”
Case Three is probably the only one which is definitely wrong, unless you think the naive approach to wiki editing is OK (Google Code Wiki, I'm looking at you...). In the other two cases it's all about intentions and predictability. Thread 2 might not care what's in value, the intention might be to append "y" to whatever is in there regardless. In this circumstance, cases one and two are both correct.
情况3应该是唯一一个肯定是错的,除非你认为维基幼稚的编辑功能是没问题的(Google Code维基,我正看着你...)。另外两个情况和意图和预见性有关。线程2可能不关心value里是什么,它可能只想把“y”加到value值后面,无论是什么。这种情况下,情况1和2都是对的。
Entry
as soon as it knows it needs it and stops anything from setting it. Then it does its thing, sets the value, and lets everything else carry on.
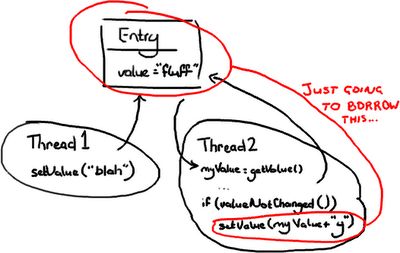
In this case Thread 2 will only lock Entry when it needs to write to it. In order to make this work, it needs to check if Entry has changed since it first looked at it. If Thread 1 came in and changed the value to "blah" after Thread 2 had read the value, Thread 2 couldn't write "fluffy" to the Entry and trample all over the change from Thread 1. Thread 2 could either re-try (go back, read the value, and append "y" onto the end of the new value), which you would do if Thread 2 didn't care what the value it was changing was; or it could throw an exception or return some sort of failed update flag if it was expecting to change "fluff" to "fluffy". An example of this latter case might be if you have two users trying to update a Wiki page, and you tell the user on the other end of Thread 2 they'll need to load the new changes from Thread 1 and then reapply their changes.
这种情况下线程2只在自己需要写Entry的时候锁住它。为了达到这个目的,它需要检查Entry从它第一次锁它开始有没有被修改过。如果线程1在线程2读到值之后进入,并且把值变为“blah”,线程2就不能向Entry写“fluffy”,并且丢弃所有线程1做的修改。线程2可以重试(重头来过,读值,在新值后面追加“y”),如果线程2不关心值被改成什么了;或者它可以抛一个异常或返回一些更新失败的标记,如果它是希望把“fluff”修改为“fluffy”的话。后一种情况的一个例子:如果你有两个用户尝试更新一个维基页面,你告诉线程2那端的用户他们需要从线程1加载新的变更然后再重新申请他们的变更。
Potential Problem: Deadlock
潜在的问题:死锁
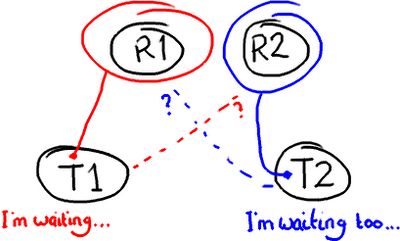
If you've used an over-zealous locking technique, both threads are going to sit there forever waiting for the other one to release its lock on the resource. That's when you reboot Windows your computer.
如果你过度地使用锁技术,两个线程会一直等待另一个线程释放资源上的锁。那是你该重启电脑的时候。
Definite Problem: Locks are sloooow...
确定的问题:锁很慢...
The thing about locks is that they need the operating system to arbitrate the argument. The threads are like siblings squabbling over a toy, and the OS kernel is the parent that decides which one gets it. It's like when you run to your Dad to tell him your sister has nicked the Transformer![]() when you wanted to play with it - he's got bigger things to worry about than you two fighting, and he might finish off loading the dishwasher and putting on the laundry before settling the argument. If you draw attention to yourself with a lock, not only does it take time to get the operating system to arbitrate, the OS might decide the CPU has better things to do than servicing your thread.
when you wanted to play with it - he's got bigger things to worry about than you two fighting, and he might finish off loading the dishwasher and putting on the laundry before settling the argument. If you draw attention to yourself with a lock, not only does it take time to get the operating system to arbitrate, the OS might decide the CPU has better things to do than servicing your thread.
锁需要操作系统来调解争端。线程就像是兄弟姐妹为了一个玩具吵架,操作系统内核就是决定谁拿玩具的父母。这就像当你想玩变形金刚的时候你跑去告诉你父亲你妹妹把它弄了个缺口-比起你们两个吵架,它有更大的事要担心,也许他会先洗碗,再去洗衣店,然后才解决你们的争端。如果你注意锁的话,不但让操作系统来调用很耗时,而且比起为你的线程服务,操作系统可能觉得CPU有更重要的事要做。
The Disruptor paper talks about an experiment we did. The test calls a function incrementing a 64-bit counter in a loop 500 million times. For a single thread with no locking, the test takes 300ms. If you add a lock (and this is for a single thread, no contention, and no additional complexity other than the lock) the test takes 10,000ms. That's, like, two orders of magnitude slower. Even more astounding, if you add a second thread (which logic suggests should take maybe half the time of the single thread with a lock) it takes 224,000ms. Incrementing a counter 500 million times takes nearly a thousandtimes longer when you split it over two threads instead of running it on one with no lock.
Disruptor文章讲述了我们做的一个试验。那个测试调用一个对一个64位计数器循环递增5亿次的方法。对于单个无锁的线程,测试花了300ms。如果加入锁的话(而且是在单个线程的情况下,没有冲突,也没有除了锁之外的复杂东西)测试花了10000ms。这就像慢了两个数量级。甚至更惊人,如果你再加入一个线程(逻辑上来说应该只花单个线程时大概一半的时间)它花了224000ms。对一个计数器递增5亿次,当你把它分由两个线程来跑比使用单个无锁线程多花了将近一千倍的时间。
I'm just touching the surface of the problem, and obviously I'm using very simple examples. But the point is, if your code is meant to work in a multi-threaded environment, your job as a developer just got a lot more difficult:
我只涉及到了这个问题的表面,而且很明显我用了极简单的例子。但是问题是,如果你的代码是要在多线程环境下工作,作为一个开发者,你的工作就变得难很多了:
Naive code can have unintended consequences. Case Three above is an example of how things can go horribly wrong if you don't realise you have multiple threads accessing and writing to the same data.
幼稚的代码会引起意想不到的后果。上面的情况3是一个事情会错得多可怕的例子,如果你有多个线程对相同的数据进行访问和写入。
Selfish code is going to slow your system down. Using locks to protect your code from the problem in Case Three can lead to things like deadlock or simply poor performance.
自私的代码会使你的系统变慢。使用锁来使你的代码回避情况3中的问题会导致像死锁或者很差的性能之类的问题。
This is why many organisations have some sort of concurrency problems in their interview process (certainly for Java interviews). Unfortunately it's very easy to learn how to answer the questions without really understanding the problem, or possible solutions to it.
这也是为什么很多组织访问时都有一些并发问题的原因(当然是JAVA的访问)。遗憾的是,学会如何回答问题很容易,但是真正理解问题或是找出可能的解决方案很难。
How does the Disruptor address these issues?
Disruptor是怎么处理这些问题的呢?
For a start, it doesn't use locks. At all.
首先,它不用锁。完全不用。
Instead, where we need to make sure that operations are thread-safe (specifically, updating the next available sequence number in the case of multiple producers), we use a CAS (Compare And Swap/Set) operation. This is a CPU-level instruction, and in my mind it works a bit like optimistic locking - the CPU goes to update a value, but if the value it's changing it from is not the one it expects, the operation fails because clearly something else got in there first.
作为替代,在需要保证操作线程安全的地方(特别是,在多生产者情况中更新下一个可用的序列号)我们使用CAS(Compare And Swap/Set)操作。这是CPU级的指令,而且在我看来它的工作方式有点像乐观锁-CPU更新一个值,但是如果那个它要修改的值不是它期望的,操作就会失败因为很明显某些东西先到那儿了。
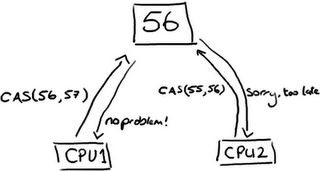
Note this could be two different cores rather than two separate CPUs.
注意这里可以是两个不同的内核而不是两个分离的CPU。
CAS operations are much cheaper than locks because they don't involve the operating system, they go straight to the CPU. But they're not cost-free - in the experiment I mentioned above, where a lock-free thread takes 300ms and a thread with a lock takes 10,000ms, a single thread using CAS takes 5,700ms. So it takes less time than using a lock, but more time than a single thread that doesn't worry about contention at all.
CAS操作比锁的代价低很多因为它们不涉及操作系统,它们直接和CPU打交道。但是并不是没有代价的-在前面我提到的那个试验中,无锁的线程花300ms,有锁的线程花10000ms,单个线程使用CAS要花5700ms。因此它比用锁耗费的时间要少,但是比根本不需要担心冲突的单个无锁线程耗时要多。
Back to the Disruptor - I talked about the ClaimStrategy when I went over the producers. In the code you'll see two strategies, a SingleThreadedStrategy and a MultiThreadedStrategy. You could argue, why not just use the multi-threaded one with only a single producer? Surely it can handle that case? And it can. But the multi-threaded one uses an AtomicLong (Java's way of providing CAS operations), and the single-threaded one uses a simple long with no locks and no CAS. This means the single-threaded claim strategy is as fast as possible, given that it knows there is only one producer and therefore no contention on the sequence number.
回到Disruptor-我在讲生产者的时候讲过ClaimStrategy。在代码中你会看到两个Strategy,SingleThreadedStrategy和MultiThreadedStrategy。你要有意见了,为什么不在单生产者时也只用多线程那个Strategy?它当然可以处理那个情形。是的它可以。但是多线程的那个使用AtomicLong(JAVA提供的CAS操作的方法),而单线程那个使用的是简简单单的long,没有锁和CAS。这意味着单线程那个claim strategy是尽可能快的,让它知道只有一个生产者所以序列号上没有冲突。
I know what you're thinking: turning one single number into an AtomicLong can't possibly have been the only thing that is the secret to the Disruptor's speed. And of course, it's not - otherwise this wouldn't be called "Why it's so fast (part one)".
我知道你在想什么:把单个数字改成AtomicLong不可能是Disruptor如此快速的唯一秘诀。它当然不是-不然的话这篇文章也不会叫“为什么它这么快(一)”了。
But this is an important point - there's only one place in the code where multiple threads might be trying to update the same value. Only one place in the whole of this complicated data-structure-slash-framework. And that's the secret. Remember everything has its own sequence number? If you only have one producer then every sequence number in the system is only ever written to by one thread. That means there is no contention. No need for locks. No need even for CAS. The only sequence number that is ever written to by more than one thread is the one on the ClaimStrategy if there is more than one producer.
但这点也很重要-Disruptor代码里只有一个地方有可能出现多个线程同时尝试对一个值进行更新的情况。在整个复杂的数据结构/框架中只有一个地方。这就是秘诀。还记得所有东西都有它自己的序列号吗?如果你只有一个生产者的话那么系统中的每个序列号只会由一个线程来写入。这意味着没有冲突。不需要锁。甚至不需要CAS。如果有一个以上的生产者,唯一会被多个线程写入的序列号就是在ClaimStrategy上的那个。
This is also why each variable in the Entry can only be written to by one consumer. It ensures there's no write contention, therefore no need for locks or CAS.
这也是为什么Entry上的每个属性都只能被一个消费者写入的原因。它保证了没有写冲突,因此不需要锁或是CAS。
Back to why queues aren't up to the job
回到为什么队列不适合这个工作的问题
So you start to see why queues, which may implemented as a ring buffer under the covers, still can't match the performance of the Disruptor. The queue, and the basic ring buffer, only has two pointers - one to the front of the queue and one to the end:
那么你开始明白为什么队列,可能内部实现类似ring buffer,却仍然比不上Disruptor的性能。队列,还有基本的ring buffer,只有两个指针-一个指向头一个指向尾:
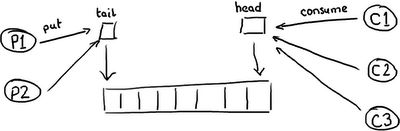
If more than one producer wants to place something on the queue, the tail pointer will be a point of contention as more than one thing wants to write to it. If there's more than one consumer, then the head pointer is contended, because this is not just a read operation but a write, as the pointer is updated when the item is consumed from the queue.
如果有一个以上的生产者想放一些东西到队列中,尾指针就会成为冲突点,因为有一个以上的东西想要对它写入。如果有一个以上的消费者,那么头指针就冲突了,因为这不仅仅是一个读操作,还有写操作,因为当队列中的项被消耗之后要更新指针。
But wait, I hear you cry foul! Because we already knew this, so queues are usually single producer and single consumer (or at least they are in all the queue comparisons in our performance tests).
但是等等,我听到你喊冤了!因为我们早知道这事了,因此队列通常用在单个生产者和单个消费者的情况(或者至少它们全在我们性能测试的队列比较中)。
There's another thing to bear in mind with queues/buffers. The whole point is to provide a place for things to hang out between producers and consumers, to help buffer bursts of messages from one to the other. This means the buffer is usually full (the producer is out-pacing the consumer) or empty (the consumer is out-pacing the producer). It's rare that the producer and consumer will be so evenly-matched that the buffer has items in it but the producers and consumers are keeping pace with each other.
还有一件关于队列/事需要牢记。整件事都是为了弄一块地方让东西可以在生产者和消费者之间瞎逛,为了在它们之间辅助缓冲连续的消息。这意味着缓冲常常是满的(生产者的速度超过消费者)或者空的(消费者的速度超过生产者)。很少有生产者和消费者会达到这样的平衡,缓冲中有东西但是生产者和消费者保持步调一致的。
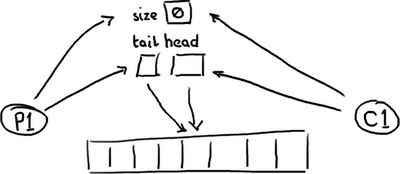
So this is how things really look. An empty queue:
所以下面的才是实际看到的样子。一个空队列:
...and a full queue:
...一个满的队列:
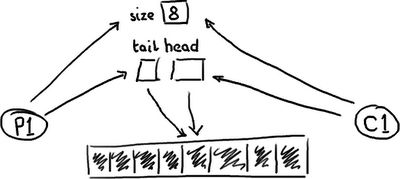
The queue needs a size so that it can tell the difference between empty and full. Or, if it doesn't, it might determine that based on the contents of that entry, in which case reading an entry will require a write to erase it or mark it as consumed.
队列需要一个尺寸来区分空的还是满的。或者,如果没有的话,也许它会基于条目的内容来作判断,在这种情况下读取一个条目需要一个写操作来擦除它或者把它变成已消耗的。
Whichever implementation is chosen, there's quite a bit of contention around the tail, head and size variables, or the entry itself if a consume operation also includes a write to remove it.
不管选择哪个实现方式,都会有不少冲突存在于尾,头和尺寸变量,或者条目自己,如果消耗操作也包含清除它的写操作的话。
On top of this, these three variables are often in the same cache line, leading to false sharing. So, not only do you have to worry about the producer and the consumer both causing a write to the size variable (or the entry), updating the tail pointer could lead to a cache-miss when the head pointer is updated because they're sat in the same place. I'm going to duck out of going into that in detail because this post is quite long enough as it is.
在此之上,这三个变量常常会放在同一个高速缓存中,导致伪共享。因此,你不仅要担心生产者和消费者都会出现对尺寸变量(或者条目)进行写操作的情况,当头指针已经更新再更新尾指针时还会导致高速缓存未命中,因为它们存在同一个地方。我不会详细讨论这个因为这篇文章已经够长了。
So this is what we mean when we talk about "Teasing Apart the Concerns" or a queue's "conflated concerns". By giving everything its own sequence number and by allowing only one consumer to write to each variable in the Entry, the only case the Disruptor needs to manage contention is where more than one producer is writing to the ring buffer.
那么这就是我们说的“测试远离关注”或者一个队列的“关注点混淆”。通过给所有东西它自己的序列号和Entry中的每个变量都只允许一个消费者写入,Disruptor唯一需要管理冲突的情况就是当有一个以上生产者向ring buffer写入时。
In summary
总结
The Disruptor a number of advantages over traditional approaches:
Disruptor相比传统方法的一些优势:
1.No contention = no locks = it's very fast.
没有冲突=没有锁=很快。
2.Having everything track its own sequence number allows multiple producers and multiple consumers to use the same data structure.
所有东西都追踪自己的序列号允许多生产者和消费者使用相同的数据结构。
3.Tracking sequence numbers at each individual place (ring buffer, claim strategy, producers and consumers), plus the magic cache line padding, means no false sharing and no unexpected contention.
追踪序列号在各自独立的地方(ring buffer,claim strategy,producer和consumer),加上神奇的高速缓存块补全,意味着没有伪共享和没有意外冲突。
EDIT: Note that version 2.0 of the Disruptor uses different names to the ones in this article. Please seemy summary of the changes if you are confused about class names.
修改:注意2.0版的Disruptor使用了和本文提到的不一样的名称。如果你对类名有疑问,请查看我的变更总结。