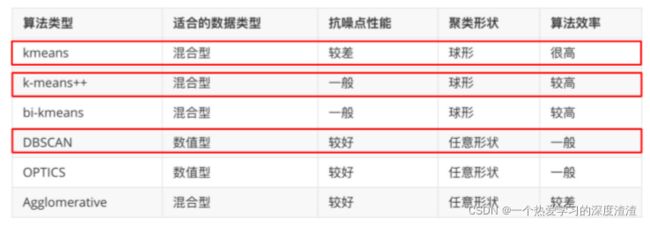
轻量级车道线检测
一、前置知识
首先需要知道实例分割的任务主要有两种实现方式:

1、自上而下:先检测出框,再对框内的物体进行像素点分类,缺点在于对于一些目标检测框不完整,会影响精度;
2、自下而上,先对目标像素点进行分类,再通过聚类的方式将像素点归到各个目标上;
总结:对于车道线场景,采用自下而上的方式较多,因为车道线的场景复杂,不利于检测;
二、聚类算法
通过自下而上的方式分类点后,需要聚类,将各个像素点归到不同的目标上;
这里又称为度量学习距离度量学习相似度学习;
注意:在分割、关键点检测、人脸识别 任务中都涉及该概念;
车道线任务中采用自下而上后聚类的方式,而不采用度量学习的方式;
用到一个损失函数,论文:https://arxiv.org/pdf/1708.02551.pdf

上图展示了花瓣通过该聚类方法进行聚类的效果;
下面展示几种聚类的方法:
K-means
实现步骤:
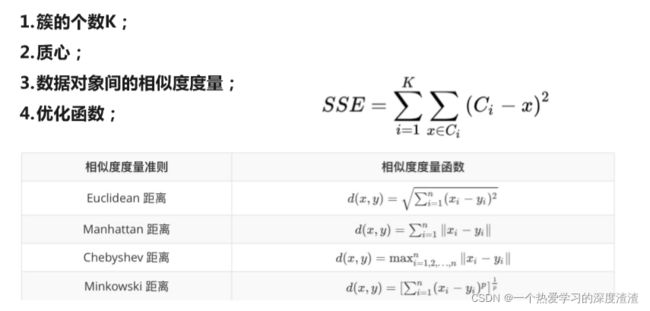
下图展示了聚类的过程中,Kmean的变化:
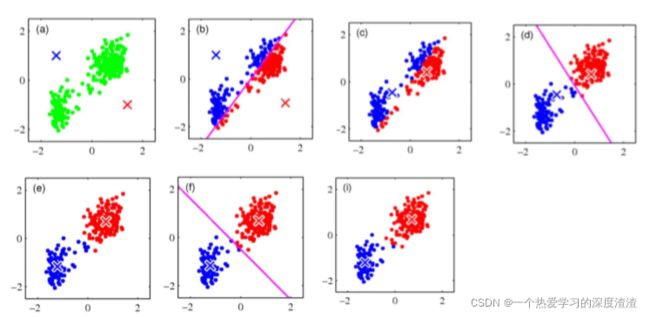
优点:
原理简单、容易实现,聚类效果好,适用于常规数据集;
缺点:
K值、初始值的选取难确定,初始聚类中心敏感;
得到的结果只是局部最优;
对于团状数据集区分效果好,对于带状数据集效果不好;
K-means++改进
对于初始化质心的优化策略:

DBSCAN
说明:一个聚类的算法;
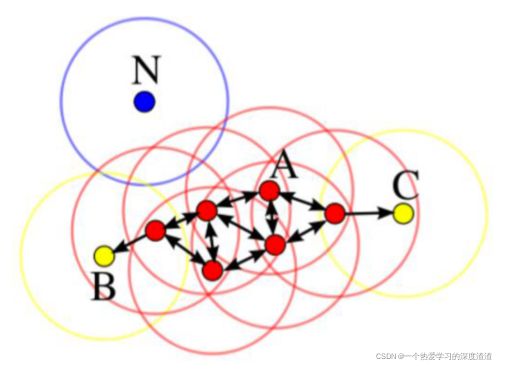
A:核心对象;
B、C:边界线点;
N:离群点;
过程:以A为核心点,不断往外进行画圈扩散,不断往外找和核心对象一个类别的点;
优势:
1、不需要指定簇的个数;
2、可以发现任意形状的簇;
3、擅长找到离群点;
4、聚类结果没有偏倚,相对的,K-Means之类的聚类算法初始值对聚类结果有很大影响;
劣势:
1、高维数据有些困难(可作降维)
2、对密度不均匀,聚类间距相差很大时,聚类效果差;
3、参数选择比较困难(不同参数对结果的影响非常大)
4、效率很慢;
Mean Shift
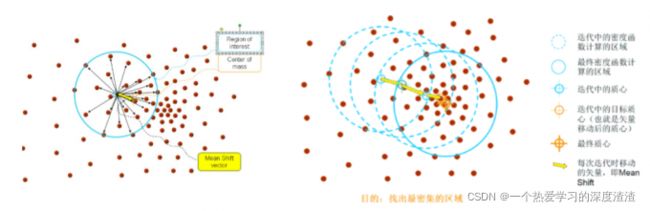
说明:从图中可以看出,通过初始质心点,计算选中区域的所有点的一个均值向量,迭代找到下一个质心点,不断迭代这个过程;直到找到最终的质心;
注意:其中也用到了一些核函数的概念,需要对该知识有一定理解;
三、LaneNet模型结构介绍
相对于FCN做车道线检测,LaneNet
首先看一个整体的实现图:
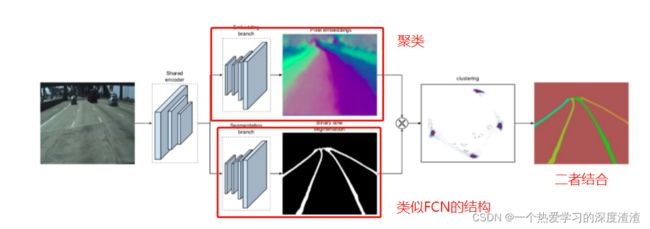
流程:
先通过encoder(编码)学习到共享的特征,随后通过两个分支;
上面分支是embedding branch,进行聚类的操作;
下面分支是Segmentation branch,进行上采样,实现车道线分割;
最后通过两个分支进行融合,得到车道线实例分割的效果;
多任务学习
当然,用不同的分支并且有不同的损失函数进行反向传播,会涉及一个多任务学习策略;
下面举一个多任务学习的常见例子:
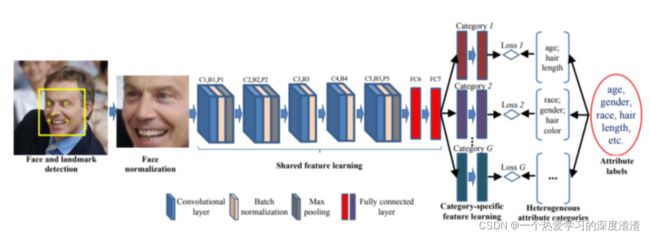
说明:上图也就是一个人脸属性的多任务学习,其中浅层特征图的权重实际是共享的,针对不同的任务返回的损失值,需要通过加权的方式返回,随后进行反向传播更新参数;
如果接触过Faster RCNN的也应该知道,最后也是通过两个分支做检测和分类;
实际上多任务学习还可以做一些网络的变体,也就是改变共享卷积的方式:
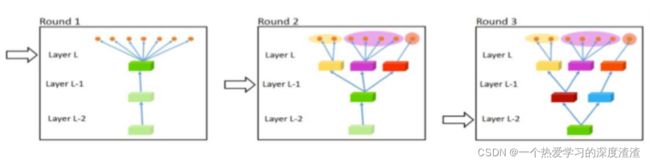
当然,两个分支的卷积也可以交叉共享:
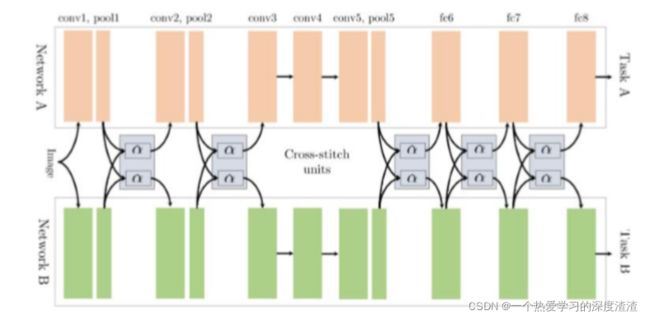
这里需要思考一个问题,如何设置不同分支的损失函数的权重呢?
提供一个思路:单独输出不同分支下的Loss值,通过权重先进行损失平衡(也就是归一化的操作),举个例子:一个分支损失值为100,一个分支为1,那么就需要权重比为1:100来平衡;随后根据任务的重要性,对齐进行一定比例的调整;
模型改进措施
为了实现端到端,会加入一层H-Net回归车道线;
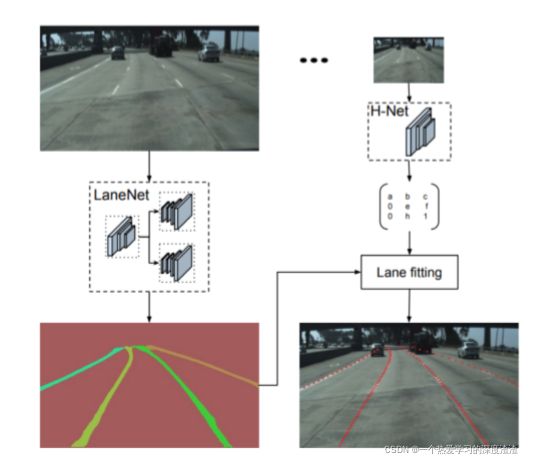
也就是说H矩阵可以理解成一个变换矩阵,实际上加入H矩阵后效果不一定更好;
四、聚类代码实现
1、Kmean算法的代码实现
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
# 创建样本点
coordinate, type_index = make_blobs(
# 1000个样本
n_samples=1000,
# 每个样本2个特征,代表x和y
n_features=2,
# 4个中心(聚类的类别)
centers=4,
# 随机数种子
random_state=2
)
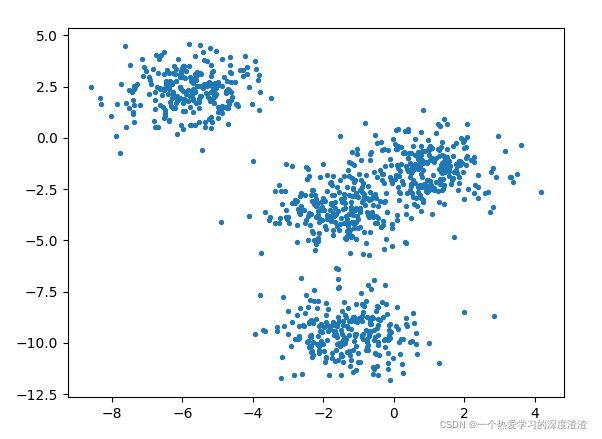
fig0, axi0 = plt.subplots(1)
# 传入x、y坐标,macker='o'代表打印一个圈,s=8代表尺寸
axi0.scatter(coordinate[:, 0], coordinate[:, 1], marker='o', s=8)
# 打印所有的点
plt.show()
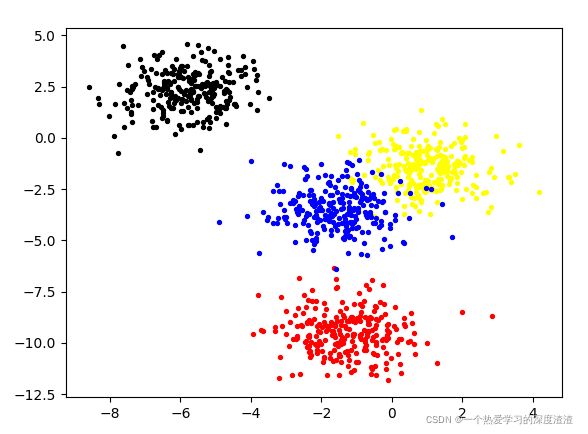
color = np.array(['red', 'yellow','blue','black'])
fig1, axi1=plt.subplots(1)
# 下面显示每个点真实的类别
for i in range(4):
axi1.scatter(
coordinate[type_index == i, 0],
coordinate[type_index == i, 1],
marker='o',
s=8,
c=color[i]
)
plt.show()
# 下面用kmeans去聚类得到的结果
y_pred = KMeans(n_clusters=4, random_state=9).fit_predict(coordinate)
plt.scatter(coordinate[:, 0], coordinate[:, 1], c=color[y_pred], s=8)
plt.show()
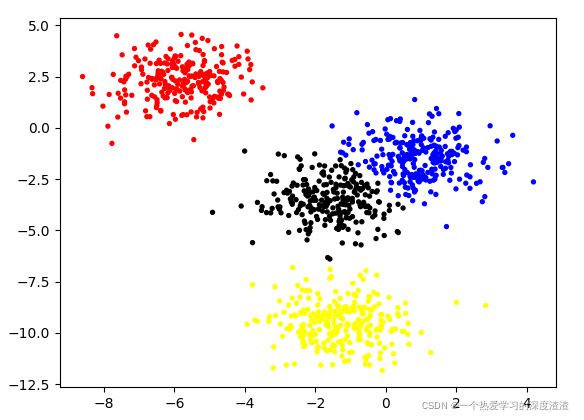
结论:可以看出,Kmean的聚类效果还是不错的,除了一些干扰点的效果不好;可能也是由于数据过于简单吧,能够达到好的效果;
2、Kmean++
在Kmean算法上进行改进,只需要在调用函数时加多一个参数即可;
# 下面用kmeans++去聚类得到的结果
y_pred = KMeans(n_clusters=4, random_state=9, init='k-means++').fit_predict(coordinate)
plt.scatter(coordinate[:, 0], coordinate[:, 1], c=color[y_pred], s=8)
plt.show()
结论:从结果上看和Kmean没有很大区别;
3、DBSCAN算法
# eps:半径,min_samples:使用附近的多少个样本来构建中心点
y_pred = DBSCAN(eps=1.8, min_samples=3).fit_predict(coordinate)
plt.scatter(coordinate[:, 0], coordinate[:, 1], c=y_pred, s=8)
plt.show()
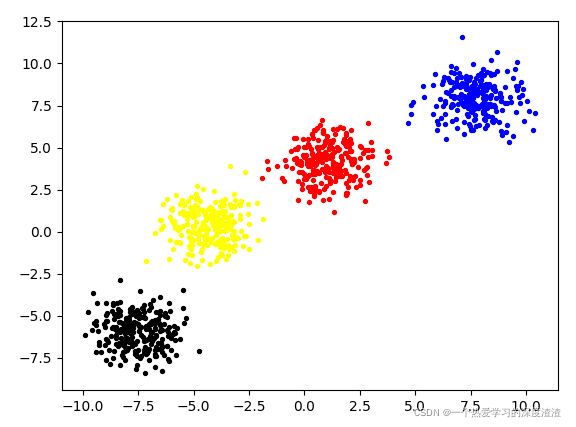
这个算法我们用另一种分布来构建样本点,下图是原始样本点:
通过DBSCAN后的结果:
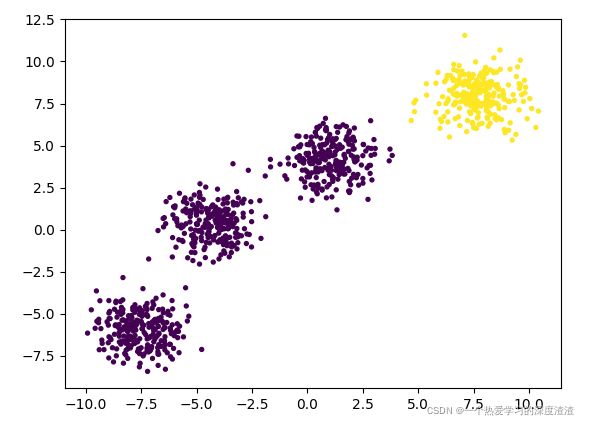
结论:DBSCAN的算法原理是基于周围的点的数量来判断类别,所以间隔不远的簇会被当成一个类别,可以通过调参来解决;
4、Meanshift算法
# 估算半径
bandwidth = estimate_bandwidth(coordinate, quantile=0.2, n_samples=500)
# bin_seeding: 随便找一些点的中心来作为初始位置
meanShift = MeanShift(bandwidth=bandwidth, bin_seeding=True)
meanShift.fit(coordinate)
labels = meanShift.labels_
plt.scatter(coordinate[:, 0], coordinate[:, 1], c=labels, s=8)
plt.show()
聚类效果图:
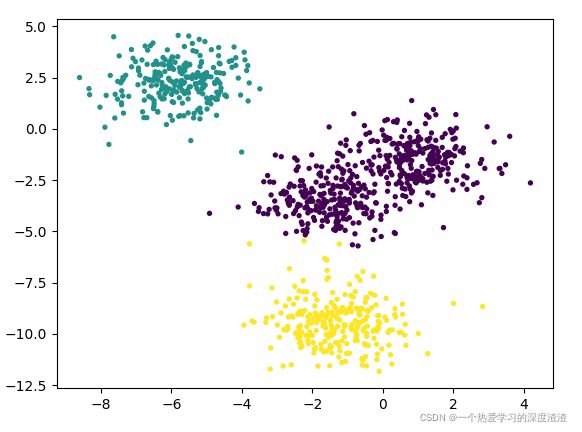
结论:可以看出基于圆心的聚类,靠的太近的簇会分为同一类别;
五、用检测网络识别车道线
由于用语义分割网络进行车道线检测,性能还是过低。无法达到落地应用的程度;
将语义分割任务变为检测任务,模型的性能得到提升,并且效果也不差;
论文地址:https://arxiv.org/pdf/2004.11757.pdf
下图为该检测任务的具体方法:
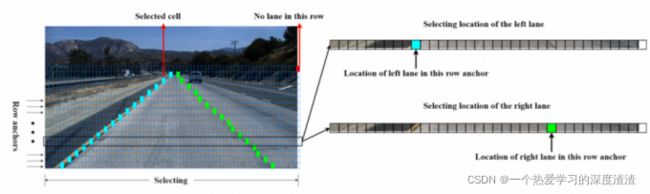
说明:从图中可以看出,将输入图分为了网格图,对其中每一个网格判断有无车道线,并且位置信息也做了保存;
下面介绍一下数据增强的trick:
1、crop:由于车道线场景上面一部分都是没有车道线的,根据数据标注的信息,可以切除·上面部分的图像,减少计算量;
2、旋转:数据增强;
3、垂直和纵向的变换:将车道线拉直等操作;
4、延长车道线;

网络结构图:
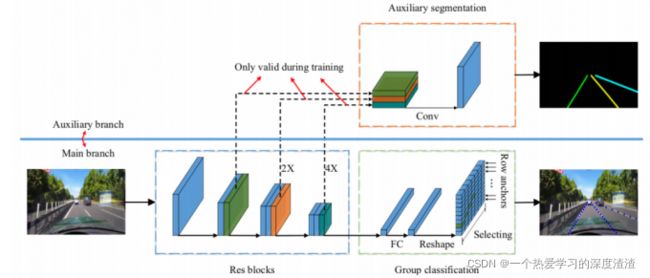
说明:上面分支主要是在训练阶段使用,用于车道线类别区分,推理时只需要走下面分支即可;可以看出,网络的总体结构用了一个ResNet的骨干网络,后续接入全连接实现特征维度的转换,最终得到含车道线所在点的网格位置;
损失函数:
L total = L c l s + α L s t r + β L s e g L_{\text {total }}=L_{c l s}+\alpha L_{s t r}+\beta L_{s e g} Ltotal =Lcls+αLstr+βLseg
说明:分类损失+位置损失+分割损失
代码实战
源码地址:https://github.com/cfzd/Ultra-Fast-Lane-Detection
可在项目地址中下载预训练模型:

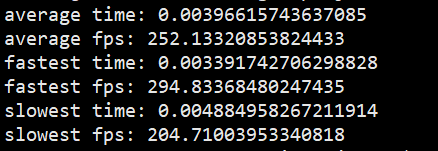
根据官方给出的结论,在Tusimple数据集下可以达到306fps的效果,实际在1080Ti下运行只达到了250fps;
1、处理数据
作用:根据区域进行的车道线回归,Tusimple数据集分为四个区域(因为数据集中最多有四条车道线),所以将数据集按区域对车道线做标签;
python scripts/convert_tusimple.py --root $TUSIMPLEROOT
2、修改配置文件
修改config/tusimple.py下的data_root,修改为tusimple数据集的路径;
3、进行训练
python train.py configs/path_to_your_config
4、进行可视化测试
python demo.py configs/tusimple.py --test_model
将会生成一个test.avi文件,其中是将所有检测后的图片做成一个视频进行展示;
5、测试模型推理速度
python speed.py
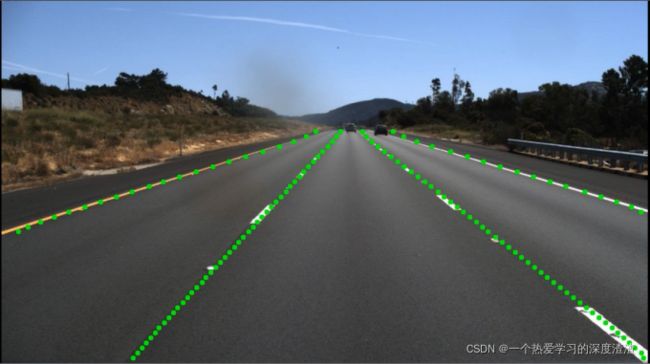
随机放一张最终的效果图:
六、总结
本次关于车道线检测项目的进行,学习到了蛮多知识点:
-
分割网络的基本架构和设计;
-
聚类算法;
-
多任务学习如何实现;
-
用检测代替分割来实现车道线检测,提高性能;
以上知识点都可以在其他方向上进行深入理解:
- 聚类算法在度量学习中的应用;(比如实际做一个图像检索的项目)
- 多任务学习实现多属性分类,控制权值共享的网络层;(比如做一个人脸属性多分类)