目标检测 YOLO 系列: 持续改进 YOLO v3
目标检测 YOLO 系列: 持续改进 YOLO v3
- 目标检测 YOLO 系列: 开篇
- 目标检测 YOLO 系列: 开宗立派 YOLO v1
- 目标检测 YOLO 系列: 更快更准 YOLO v2
- 目标检测 YOLO 系列: 持续改进 YOLO v3
- 目标检测 YOLO 系列: 你有我有 YOLO v4
- 目标检测 YOLO 系列: 快速迭代 YOLO v5
- 目标检测 YOLO 系列:你有我无 YOLOX
作者:Joseph Redmon, Ali Farhadi
发表时间:2018
Paper 原文: YOLOv3: An Incremental Improvement(严格来说,这并非是一篇学术论文,因为没有正式发表,作者行文也比较潇洒)
YOLO v3 最大的特点是精度不错,但是速度飞快,并且对小目标的效果也有提升。320x320 YOLO v3 精度和 SSD321 差不多,但是速度是 SSD321 的三倍。凭借卓越的性能,YOLO v3 在工业界备受欢迎。
1 网络结构
在 v3 中,作者又提出了新的 backbone——Darknet-53,这个网络比 Darknet-19 要厉害的多,当然也更大,但是相比 Resnet101 或者 Restnet152 要更高效。更多关于 Darknet-53 的内容请参考CV 经典主干网络 (Backbone) 系列: Darknet-53。
完整的 v3 结构可以参考下面两张图片。v3 最大的区别是网络有三个不同尺度的输出(13x13,26x26 & 52x52)。
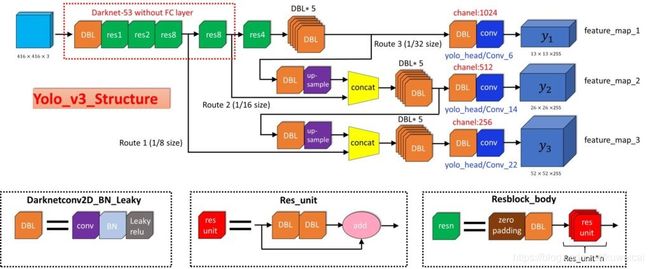
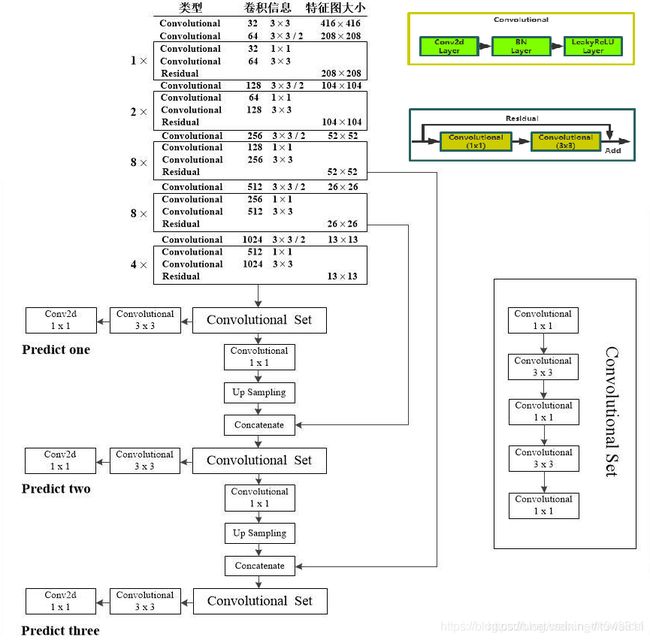
整个网络的结构也还是比较清晰,这里有用到 “Up Sampling” 层,上采样的方法很多,其实 darknet 中用的就是最简单的最近邻插值。源代码如下(摘自 darknet 源码 blas.c)。
void upsample_cpu(float *in, int w, int h, int c, int batch, int stride, int forward, float scale, float *out)
{
int i, j, k, b;
for(b = 0; b < batch; ++b){
for(k = 0; k < c; ++k){
for(j = 0; j < h*stride; ++j){
for(i = 0; i < w*stride; ++i){
int in_index = b*w*h*c + k*w*h + (j/stride)*w + i/stride;
int out_index = b*w*h*c*stride*stride + k*w*h*stride*stride + j*w*stride + i;
if(forward) out[out_index] = scale*in[in_index];
else in[in_index] += scale*out[out_index];
}
}
}
}
}
2 网络原理
这里主要介绍 V3 输出部分的改进。
作者在训练模型之前,在 COCO 数据集上通过聚类得到了 9 个 prior box 尺寸 ((10x13),(16x30),(33x23),(30x61),(62x45),(59x119),(116x90),(156x198),(373x326)),至于这 9 个 prior box 要怎么用,且往下看。
从下图(来自参考1)可以清楚看到 v3 的工作流程,输入一张图片(416x416x3),最后得到三种不同尺度的 feature map(52x52, 26x26, 13x13)。在这里我们以 13x13 的 tensor 为例,原始输入图像会被分割成 13x13 的 grid cell,每个 grid cell 对应着 3D tensor 中的1x1x255 这样一个长条形 voxel。255 这个数字来源于 (3x(4+1+80)),其中的数字代表 bounding box 的坐标,物体识别度(objectness score),以及相对应的每个class的confidence,具体释义见下图。
v3 中直接在三个不同的尺度上进行检测(类似FPN),通常较浅的层目标的位置信息更准确,而较深的层语义信息更准确。相比 v2 中采用 shortcut 的方式,这种多尺度的方式更为直接,这也是 v3 对小目标有更好检测效果的原因。
作者把 9 个 prior box 分配到 3 个不同尺度的 feature map 上,显然越小的 feature map 具有更大的感受野,适合用来检测较大的目标,而较大的 feature map 用来检查较小的目标。具体来说就是对于 52x52 的 feature map 对应 (10x13),(16x30),(33x23) 的 prior box,而 13x13 的 feature map 对应 (116x90),(156x198),(373x326) 的 prior box。 另外需要注意的是, prior box 的尺寸是在 416x416 分辨率下计算得到的,所以具体使用时需要换算到相应的分辨率下,比如对于 13x13 的 prior box 来说,就需要除于 32。

训练时,如果训练集中某一个 ground truth 对应的 bounding box 中心恰好落在了输入图像的某一个 grid cell 中(如图中的红色 grid cell),那么这个 grid cell 就负责预测此物体的bounding box,于是这个 grid cell 所对应的 objectness score 就被赋予 1,其余的 grid cell 则为 0。此外,每个 grid cell 还被赋予 3 个不同大小的 prior box 。在学习过程中,这个 grid cell 会逐渐学会如何选择哪个大小的prior box,以及对这个 prior box 进行微调(即 offset/coordinate)。但是 grid cell 是如何知道该选取哪个 prior box 呢?在这里作者定义了一个规则,即只选取与 ground truth bounding box 的 IOU 重合度最高的哪个 prior box。
4 性能
-
和 V2 相比,速度上有一定下降(Titan X 上, V2 416x416 可以达到 67 FPS,而 V3 416x416 只有 33 FPS),但是精度要好。总的来说,速度上 V2 > V3 > V1, 效果上 V3 > V2 > V1。
-
和 SSD321 相比,精度差不多,但是 V3 的速度是其 3 倍。
参考
- 近距离观察YOLOv3