深度学习图像分类篇--1.卷积神经网络CNN基础
最近在b站发现一个宝藏up主,讲解图像分类、目标检测和语义分割,教程主要是以tensorflow2.4以及pytorch1.10搭建模型,很适合初学者的入门学习。
立一个flag,跟着这个教程,做好笔记,好好调包,争取今年进入炼丹期。
参考内容来自:
up主的b站链接:霹雳吧啦Wz的个人空间_哔哩哔哩_Bilibili
up主将代码和ppt都放在了github:https://github.com/WZMIAOMIAO/deep-learning-for-image-processing
简单总结卷积神经网络 Convolutional Neural Networks的基本网络层和神经网络结构。
1.1卷积神经网络的基础
1.卷积神经网络

卷积神经网络 CNN,Convolutional Neural Network 的发展
1986 Rumelhart 和 Hinton 等人提出了反向传播 (Back Propagation,BP) 算法。
1998 LeCun 利用BP算法训练 LeNet5 网络,标志着CNN等真正面世。(硬件跟不上)
2006 Hinton 在他们的Science Paper 中首次提出了 Deep Learning 的概念。
2012 Hintonl的学生Alex Krizhevsky在寝室用GPU死磕了一个Deep Learning模型,举摘下了视觉领域竞赛LSVRC2012的桂冠,在百万量级的ImageNet?数据集合上,效果大幅度超过传统的方法,从传统的70%多提升到80%多。
什么是卷积?
对图像(不同的数据窗口数据)和滤波矩阵(一组固定的权重:因为每个神经元的多个权重固定,所以又可以看做一个恒定的滤波器filter)做内积(逐个元素相乘再求和)的操作就是所谓的『卷积』操作,也是卷积神经网络的名字来源。如下图
在CNN中,滤波器filter(带着一组固定权重的神经元)对局部输入数据进行卷积计算。每计算完一个数据窗口内的局部数据后,数据窗口不断平移滑动,直到计算完所有数据。这个过程中,有这么几个参数:
a. 深度depth:神经元个数,决定输出的depth厚度。同时代表滤波器个数。
b. 步长stride:决定滑动多少步可以到边缘。
c. 填充值zero-padding:在外围边缘补充若干圈0,方便从初始位置以步长为单位可以刚好滑倒末尾位置,通俗地讲就是为了总长能被步长整除。

2.全连接层
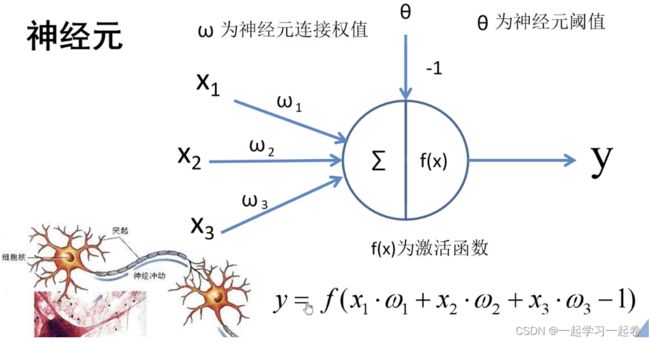
全连接层是由许多神经元连接而成的,上图是一个简单的神经元,输入X1,X2,X3分别乘于权重W1,W2,W3然后进行求和,再加上偏置θ,通过激活函数f(x)就得到最终输出y。
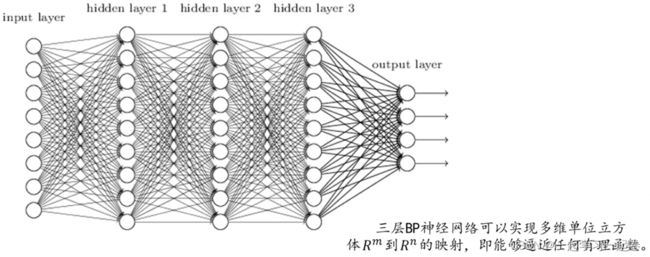
将神经元按列进行排列,列与列之间进行全连接就得到BP神经网络。BP (back propagation)算法包括信号的前向传播和误差的反向传播两个过程。即计算误差输出时按从输入到输出的方向进行,而调整权值和阈值则从输出到输入的方向进行。
正向传播是从输入到输出,由神经网络得到计算预测输出的过程;前向传播过程得到的输出值与期望值进行对比,就得到误差值;反向传播是从输出到输入,是寻找最合适的参数w和b,通过计算偏导数来进行梯度下降或梯度上升的过程。
神经网络的输入是什么? 输出是什么?
举例;利用BP神经网络做车牌数字识别

输入层
首先读入RGB图像,然后进行灰度化得到中间的图,然后进行二值化出来得到黑白图。
用5行3列的矩阵在图像上滑动,计算白色像素占整个框像素的比例。最后一行越界了,可以补一列零,或者提前判断一下,变成5行2列。

接着将5X5的矩阵按行展开,拼接成行向量,变成1行25列的行向量,当成神经网络的输入层。

输出层 one-hot 独热编码:进行编码的一种方式
一个图像是一行,多个图像就是矩阵。one-hot是除了目标其余全部写0,比如一行10个位置,分别代表0-9,如果推测目标是8,那么在第九个空位写1,其余九个空位全部写0,

有了输入和输出的期望,就能对网络进行训练。
3.卷积层
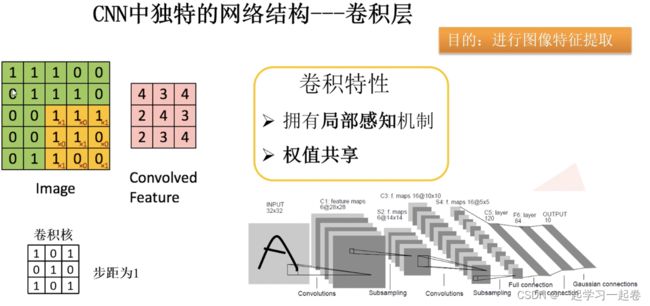
卷积核也叫滤波器覆盖到计算的特征值上,将卷积核上的值和特征值上的值相乘然后相加。卷积核代表着一种特征,比如这个卷积核就可以用来提取图像的特征,
卷积核的值初始化是随机的,后面通过反向传播更新。卷积核里的值最开始是随机确定一个,然后根据输出和方向传播不断更新卷积核里的参数,使输入输出的误差最小。
以一个灰度图像为例,灰度图像的channel为1.
参数W:连接层之间的权重参数,
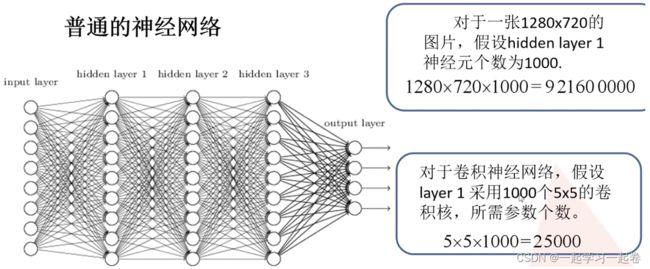
有多少个卷积核就加多少个偏置值,相同颜色求卷积,最后再相加,默认步长s为1.
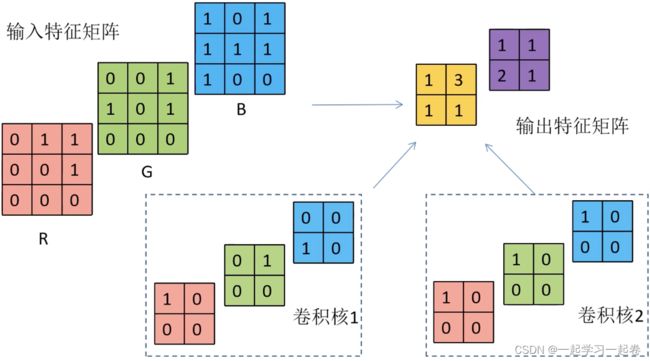
同核特征图相加,不同核特征图拼接。卷积核在RGB上移动,进行矩阵相乘,相加,得到输出矩阵。(相同颜色求卷积,最后再相加,得到输出矩阵,默认步长为1)
卷积核开始是随机生成的,然后经过不断迭代训练,会得到一个最优的卷积核。
1.卷积核的深度 channel 与输入特征层的 深度 channel相同
2.输出的特征矩阵channel与卷积核个数相同
思考?
加上偏移量bias该如何计算?
加上激活函数该如何计算?
如果卷积过程中出现越界的情况该怎么办?
为什么需要使用激活函数?
在计算过程是一个线性的计算过程,加入激活函数,是引入非线性因素,使其具备解决非线性问题的能力。 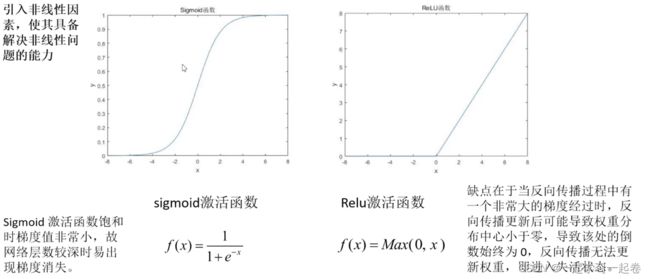
学习率又称超参数,是自己设定的。padding是为了处理越界情况,补0处理。

4.池化层
提取主要参数,池化层会丢失信息,
MaxPooling下采样层-找最大值提取出来,
 AveragePooling下采样层-取平均值
AveragePooling下采样层-取平均值

1.1卷积神经网络基础补充-反向传播过程
1.误差的计算
这是一个最简单的两层神经网络,包含输入层(0层),隐藏层(1层),输出层(2层)。
下标中前1是代表上一层的节点,后1是代表本层节点,上标的1是代表第几层;σ为激活函数。
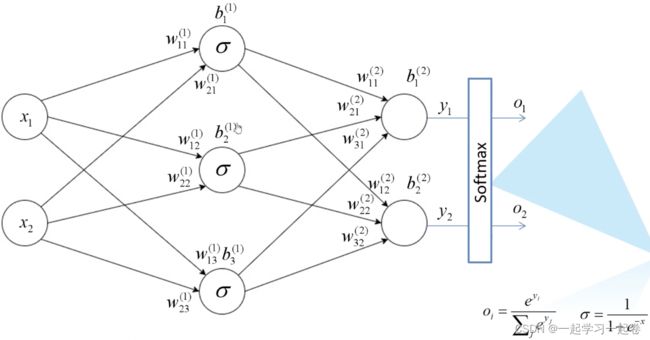
输入层 Input layer:众多神经元 Neuron 接受大量非线形输入讯息。输入的讯息称为输入向量。
输出层 Output layer:讯息在神经元链接中传输、分析、权衡,形成输出结果。输出的讯息称为输出向量。
隐藏层 Hidden layer:简称“隐层”,是输入层和输出层之间众多神经元和链接组成的各个层面。如果有多个隐藏层,则意味着多个激活函数。
同时,每一层都可能由单个或多个神经元组成,每一层的输出将会作为下一层的输入数据。每两个神经元之间的连接代表加权值,称之为权重 weight。不同的权重和激活函数,则会导致神经网络不同的输出。 
softmax处理将输出O1和O2的概率之和等于1;而sigmoid的输出则没有概率和为1的要求。softmax的所有输出概率和为1,例如进行图像分类时,输入一张图像,是猫的概率为0.4,是狗的概率为0.6。


损失是真实值与预测值的差距,
2.误差的反向传播

高数基础补充阅读:机器学习的数学基础-(一、高等数学) - 知乎
O1和O2满足概率分布:O2= 1 - O1

3.权重的更新

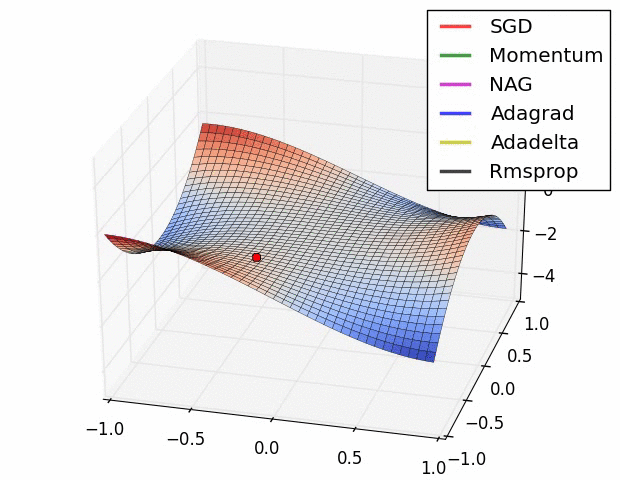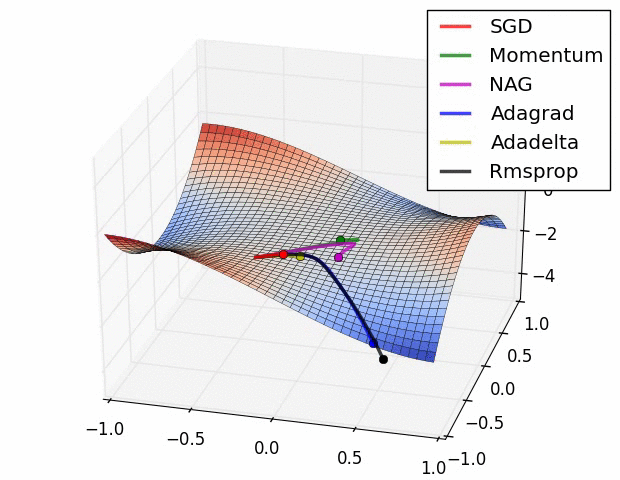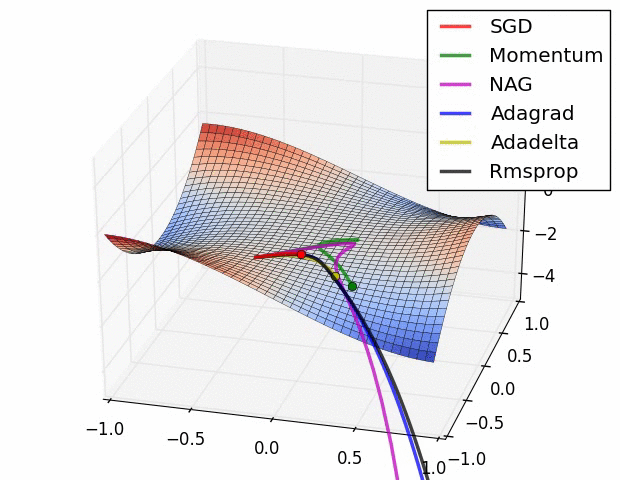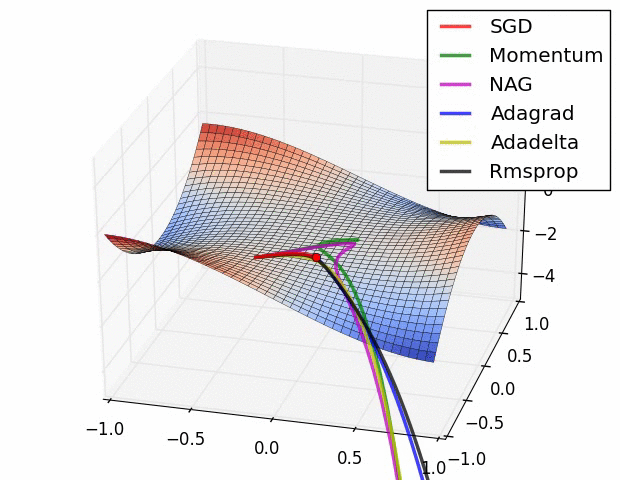
优化器(optimazer)目的:来优化梯度的求解过程,即让网络得到更快的收敛:

SGD是指随机梯度下降

当陷入局部最优时候如何解决,使用SGD+Momentum优化器。

Adagrad优化器,可能学习率下降的太快可能还没收敛就停止训练;使用RMSProp优化器:控制下降速度

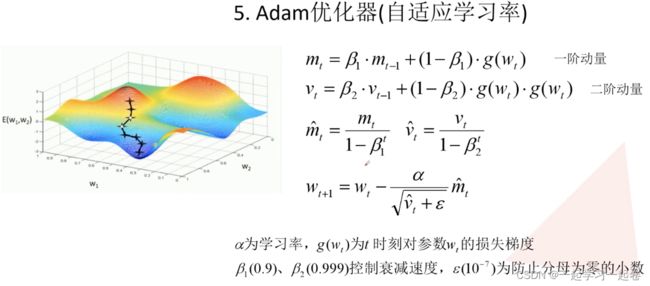
附图:几种优化器下降的可视化比较