VAE及其代码解读
版权声明:本文为博主原创文章,未经博主允许不得转载。
这几天在看GAN模型的时候,顺便关注了另外一种生成模型——VAE。其实这种生成模型在早几年就有了,而且有了一些应用。著名黑客George Hotz在其开源的自主驾驶项目中就应用到了VAE模型。这其中的具体应用在我上一篇转载的博客comma.ai中有详细介绍。在对VAE基本原理有一个认识后,就开始啃代码了。在代码中最能直观的体现其思想,结合理论来看,有利于理解。理论介绍,网上资料很多,就不赘述了。
基本网络框架:
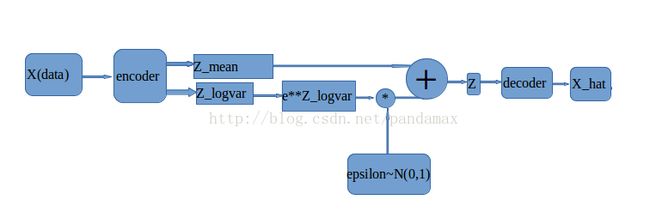
下面是基于keras的VAE代码解读:(自己加了一层,发现收敛的快一点了,附实验结果)
- <span style="font-size:14px;">from __future__ import division
- from __future__ import print_function
- import os.path
- import numpy as np
- np.random.seed(1337) # for reproducibility
- import tensorflow as tf
- from tensorflow.examples.tutorials.mnist import input_data
- mnist = input_data.read_data_sets('MNIST')
- input_dim = 784
- hidden_encoder_dim_1 = 1000
- hidden_encoder_dim_2 = 400
- hidden_decoder_dim = 400
- latent_dim = 20#(latent Variable)
- lam = 0
- def weight_variable(shape):
- initial = tf.truncated_normal(shape, stddev=0.001)
- return tf.Variable(initial)
- def bias_variable(shape):
- initial = tf.constant(0., shape=shape)
- return tf.Variable(initial)
- x = tf.placeholder("float", shape=[None, input_dim])##input x
- l2_loss = tf.constant(0.0)
- #encoder1 W b
- W_encoder_input_hidden_1 = weight_variable([input_dim,hidden_encoder_dim_1])##784*1000
- b_encoder_input_hidden_1 = bias_variable([hidden_encoder_dim_1])#1000
- l2_loss += tf.nn.l2_loss(W_encoder_input_hidden_1)
- # Hidden layer1 encoder
- hidden_encoder_1 = tf.nn.relu(tf.matmul(x, W_encoder_input_hidden_1) + b_encoder_input_hidden_1)##w*x+b
- #encoder2 W b
- W_encoder_input_hidden_2 = weight_variable([hidden_encoder_dim_1,hidden_encoder_dim_2])##1000*400
- b_encoder_input_hidden_2 = bias_variable([hidden_encoder_dim_2])#400
- l2_loss += tf.nn.l2_loss(W_encoder_input_hidden_2)
- # Hidden layer2 encoder
- hidden_encoder_2 = tf.nn.relu(tf.matmul(hidden_encoder_1, W_encoder_input_hidden_2) + b_encoder_input_hidden_2)##w*x+b
- W_encoder_hidden_mu = weight_variable([hidden_encoder_dim_2,latent_dim])##400*20
- b_encoder_hidden_mu = bias_variable([latent_dim])##20
- l2_loss += tf.nn.l2_loss(W_encoder_hidden_mu)
- # Mu encoder=+
- mu_encoder = tf.matmul(hidden_encoder_2, W_encoder_hidden_mu) + b_encoder_hidden_mu##mu_encoder:1*20(1*400 400*20)
- W_encoder_hidden_logvar = weight_variable([hidden_encoder_dim_2,latent_dim])##W_encoder_hidden_logvar:400*20
- b_encoder_hidden_logvar = bias_variable([latent_dim])#20
- l2_loss += tf.nn.l2_loss(W_encoder_hidden_logvar)
- # Sigma encoder
- logvar_encoder = tf.matmul(hidden_encoder_2, W_encoder_hidden_logvar) + b_encoder_hidden_logvar#logvar_encoder:1*20(1*400 400*20)
- # Sample epsilon
- epsilon = tf.random_normal(tf.shape(logvar_encoder), name='epsilon')
- # Sample latent variable
- std_encoder = tf.exp(0.5 * logvar_encoder)
- z = mu_encoder + tf.mul(std_encoder, epsilon)##z_mu+epsilon*z_std=z,as decoder's input;z:1*20
- W_decoder_z_hidden = weight_variable([latent_dim,hidden_decoder_dim])#W_decoder_z_hidden:20*400
- b_decoder_z_hidden = bias_variable([hidden_decoder_dim])##400
- l2_loss += tf.nn.l2_loss(W_decoder_z_hidden)
- # Hidden layer decoder
- hidden_decoder = tf.nn.relu(tf.matmul(z, W_decoder_z_hidden) + b_decoder_z_hidden)##hidden_decoder:1*400(1*20 20*400)
- W_decoder_hidden_reconstruction = weight_variable([hidden_decoder_dim, input_dim])##400*784
- b_decoder_hidden_reconstruction = bias_variable([input_dim])
- l2_loss += tf.nn.l2_loss(W_decoder_hidden_reconstruction)
- KLD = -0.5 * tf.reduce_sum(1 + logvar_encoder - tf.pow(mu_encoder, 2) - tf.exp(logvar_encoder), reduction_indices=1)##KLD
- x_hat = tf.matmul(hidden_decoder, W_decoder_hidden_reconstruction) + b_decoder_hidden_reconstruction##x_hat:1*784(reconstruction x)
- BCE = tf.reduce_sum(tf.nn.sigmoid_cross_entropy_with_logits(x_hat, x), reduction_indices=1)##sum cross_entropy
- loss = tf.reduce_mean(BCE + KLD)##average value
- regularized_loss = loss + lam * l2_loss
- loss_summ = tf.scalar_summary("lowerbound", loss)##Record the stored value of loss
- train_step = tf.train.AdamOptimizer(0.01).minimize(regularized_loss)##Optimization Strategy
- # add op for merging summary
- summary_op = tf.merge_all_summaries()
- # add Saver ops
- saver = tf.train.Saver()
- n_steps = int(1e5+1)##step:1000000
- batch_size = 100
- with tf.Session() as sess:
- summary_writer = tf.train.SummaryWriter('experiment',
- graph=sess.graph)##draw graph in tensorboard
- #if os.path.isfile("save/model.ckpt"):
- # print("Restoring saved parameters")
- #saver.restore(sess, "save/model.ckpt")
- #else:
- # print("Initializing parameters")
- sess.run(tf.initialize_all_variables())
- for step in range(1, n_steps):
- batch = mnist.train.next_batch(batch_size)
- feed_dict = {x: batch[0]}
- _, cur_loss, summary_str = sess.run([train_step, loss, summary_op], feed_dict=feed_dict)
- summary_writer.add_summary(summary_str, step)
- if step % 50 == 0:
- save_path = saver.save(sess, "save/model.ckpt")
- print("Step {0} | Loss: {1}".format(step, cur_loss))
- # save weights every epoch
- #if step % 100==0 :
- # generator.save_weights(
- # 'mlp_generator_epoch_{0:03d}.hdf5'.format(epoch), True)
- #critic.save_weights(
- # 'mlp_critic_epoch_{0:03d}.hdf5'.format(epoch), True)
- ##Step 999900 | Loss: 114.41309356689453
- ##Step 999950 | Loss: 115.09370422363281
- ##Step 100000 | Loss: 124.32205200195312 ##Step 99700 | Loss: 116.05304718017578
- #1000 encode hidden layer=1 Step 950 | Loss: 159.3329620361328
- #1000 encode hidden layer=2 Step 950 | Loss: 128.81312561035156
- span>
变分自编码器参考资料:
1.变分自编码器(Variational Autoencoder, VAE)通俗教程 – 邓范鑫——致力于变革未来的智能技术 http://www.dengfanxin.cn/?p=334
2.VAE variation inference变分推理 清爽介绍 http://mp.weixin.qq.com/s/9lNWkEEOk5vEkJ1f840zxA
3.深度学习变分贝叶斯自编码器(上下) https://zhuanlan.zhihu.com/p/25429082