推荐系统笔记(十六):推荐系统图协同过滤的深入理解:GDE
背景
在学习过SimGCL算法过后,我们发现过多的图增强操作反而不会有太大的提升,这就产生一个疑问,图卷积究竟为什么在推荐系统模型中有效?图卷积的特征嵌入往往有很多的特征,是否是各个特征都是有效影响模型结果的?
带着这些问题查阅了相关文献,就这个算法在今年的SIGIR中的一篇论文给出了答案,即:Less is More: Reweighting Important Spectral Graph Features for Recommendation。

论文链接:https://arxiv.org/pdf/2204.11346.pdf
论文认为:
-
前人的工作中,对图卷积中的领域聚合研究的不够透彻,所以作者在频域下对图卷积进行分析。
-
分析得到两个结论:a.只有少部分的邻居的平滑或者差异信息对推荐有促进,大部分的图信息都可以看作噪声;b.反复的图卷积操作只能促进邻居平滑,不能有效过滤噪声,并且低效。并且基于此进一步提出了一个高效的GCN(超图卷积),作为带通滤波器,此外动态调整negative sample的梯度加快收敛。
思想
基于图的协同过滤中,只有以下部分的特征起到作用,其他的特征可以被看作是噪声。作者将噪声由平滑到粗糙进行了规定。规定如下:对邻接矩阵求取特征值和特征向量,对于每个特征向量当中的方差var越大就越粗糙,反之则越平滑。
GDE算法(作者提出的算法)认为只有特别smooth和特别rough的特征才对最终的模型效果起作用,作者基于此进行了试验并证明这一点,并且实现了高通和低通滤波器进行有效特征提取。
原理
作者首先进行了一个实验,是在基于GCN和LightGCN推荐算法之上的,求解零阶矩阵的特征值和特征向量,计算每个特征向量的方差。防擦好越小表示每个节点和邻居节点的差别越小;反之节点之间的差别则越大。
在下图中我们可以发现NDCG的值在rough或者smooth处更高,包括准确度也是在smooth处就已经达到饱和,说明的确是这两部分的嵌入特征对模型的预测起到了主要作用。
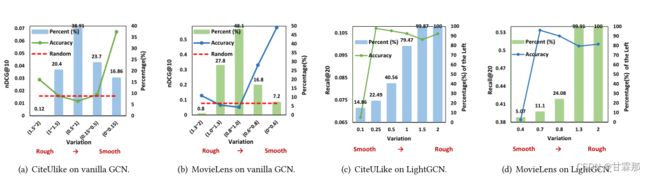
其中红色虚线是随机初始化邻接矩阵的推荐结果的精度,倘如去掉中间的特征反而会提高模型的表现,能拥有更加高效的结果。而在LightGCN模型的论文中推导可以发现,随着层数layer增加,smooth会逐渐拥有越来越平滑的特征,即整个模型总是在趋向于平滑化的,甚至压制住了rough特征向量的作用。
基于此作者实现了GCD来进行特征提取,提取rough和smooth的特征,过滤掉可以被视为noise的部分特征,进而提升协同过滤的效果。
那么具体是如何实现的呢?核心上来讲是特征提取,因此作者利用超图卷积,获取更强更有信息的嵌入,超图卷积的大致形式如下:

本文所说的超图卷积实际上就是先将超图转化为带权简单图后,再对简单图做GCN。如图为HyperGCN在某一个节点vv上的单次更新操作。

在本文中分别把item和user当超边,可以得到user和item的邻接矩阵。直观上来讲就是先聚合user或者item,得到超边的表示,再从超边聚合到user或者item,得到user或item的表征。
为了实现特征有效提取,作者设计将图G划分为三个子图Gs,Gr,Gn,分别代表的是平滑子图、粗糙子图、噪声子图,并设计了滤波函数对不同的子图有不同的卷积效果以达到特征提取的目的:
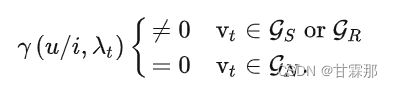
其中γ(u/i,λt)可以理解为频率响应函数,也可以理解为滤波器,也可以理解为第t个node feature重要性评估函数。
在提取了需要的特征过后就需要将特征进行聚合,作者使用的是pooling的方式对进行超图卷积过后的特征进行聚合:

user和item的超图表示经过GDE特征提取过后将smmoth和rough的特征分别进行聚合,最终将user和item的数据特征进行聚合得到最终的特征表示:
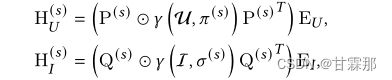
其中P(r)和π(r)分别是AU的特征向量和特征值的的最小(那就是最粗糙的)前m2个。Q(r)和σ(r)分别是AI的特征向量和特征值的的最小(那就是最粗糙的)前n2个。EU是user的embedding,EI是item的embedding。
重要性的评估将会关系到模型最终的特征提取效果,作者提出了两种特征重要性计算的方式。分别是动态特征学习,即注意力机制:

还有一种是设计一个静态的函数,有关于特征值的函数:

这是作者根据函数的泰勒展开重写图卷积的公式,详细推导请参考论文。
在作者提出了模型的特征提取和新的超图卷积计算方法过后,还对损失函数BPR Loss进行了优化,之前的损失函数是对付样本没有进行加权的,即服药本的权重都是一样的,这会导致收敛速度稍慢、收敛效果差,于是作者提出使用负样本动态加权方法:

其中 参数ξ=0.99,实验结果也表明,这种负样本带权的Loss可以加快收敛,其中的λ控制了正则化程度。如图:
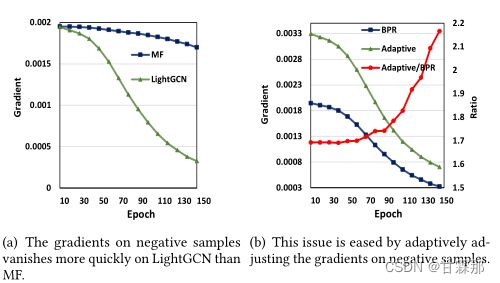
可见:(a) 在LightGCN上,负样本上的梯度比MF上消失得更快。(b) 通过自适应调整负样本上的梯度,可以缓解此问题。
总结
(1)作者研究了GCN的特征表示的主贡献部分是rough和smooth部分的特征,因此用超图分别卷积user和item,进行特征提取。(卷积又分为只用特征值最大的和特征值最小的一部分(看作两个卷积核),卷积核的参数可以动态学习也可以用函数映射特征值)。
(2)作者在本文的出发点是GCN本身,通过频域分析,证实了GCN其实是针对局部进行卷积,设计了多层的频率响应,而本文则只使用一层进行卷积,反而达到卷积到更远的视野的目的。
(3)关于为什么var高和低的特征能起到关键作用,其中的原理作者并未给出解释,只能从结果中得出结论:模型的精度是一小部分的高度平滑或者差异(粗糙)的特征决定,而且平滑的信号的作用比粗糙的信号更有作用,还需要进一步深思。
参考链接:
协同过滤和基于内容推荐有什么区别? - 知乎
超图卷积网络(HyperGCN: A New Method of Training Graph Convolutional Networks on Hypergraphs) - popozyl - 博客园