pytorch09实践(刘二大人)
今天跟着刘老师继续学习pytorch第九节课,这节课主要将的是多分类问题,而刘老师在课件中举的例子是MNIST数字手写体识别这个入门但是很经典的数据集。之前我们所学的都是二分类问题,而MNIST是一个多分类问题,数据集的标签有10个,具体关于MNIST数据集的介绍可以看看这个连接:详解 MNIST 数据集
关于解决多分类问题,这节引入了softmax函数,公式为:
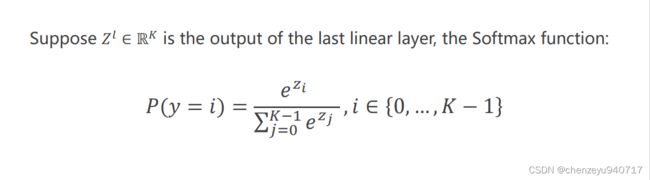
因为输出时一个概率分布,需要满足两个条件,第一个就每一项概率都要大于0,第二个就是概率之和等于1。

视频中也给了一个简单的例子来说明softmax的实现:
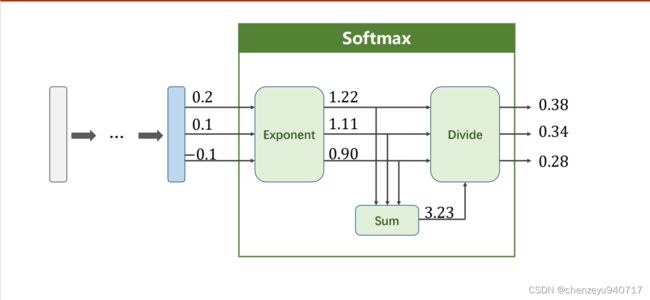
蓝色后面跟着的是最后一层全连接层的输出,三个输出分别是0.2,0.1,-0.1,分别将三个输出做一个取e操作,使得输出能够满足都大于0,然后将输出加起来求和,让每个结果除总和,这样得到的概率之和满足等于一。
pytorch中的损失函数torch.nn.CrossEntropyLoss,这个交叉熵函数中包括softmax操作,直接调用即可。下面是代码实现:
import matplotlib.pyplot as plt
import torch
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
# 准备数据集
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST(root='../data/mnist/', train=True, transform=transform, download=True)
train_loader = DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
test_dataset = datasets.MNIST(root='../data/mnist/', train=False, transform=transform, download=True)
test_loader = DataLoader(dataset=test_dataset, batch_size=64, shuffle=False)
# 定义模型
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.linear1 = torch.nn.Linear(784, 512)
self.linear2 = torch.nn.Linear(512, 256)
self.linear3 = torch.nn.Linear(256, 128)
self.linear4 = torch.nn.Linear(128, 64)
self.linear5 = torch.nn.Linear(64, 10)
self.relu = torch.nn.ReLU()
def forward(self, x):
x = x.view(-1, 784)
x = self.relu(self.linear1(x))
x = self.relu(self.linear2(x))
x = self.relu(self.linear3(x))
x = self.relu(self.linear4(x))
return self.linear5(x)
model = Net()
# 构建损失函数和优化器
Loss = torch.nn.CrossEntropyLoss()
Optim = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# 定义训练和测试
def train(epoch):
runing_loss = 0
for batch_idx, data in enumerate(train_loader, 0):
inputs, labels = data
Optim.zero_grad()
y_pred = model(inputs)
loss = Loss(y_pred, labels)
loss.backward()
Optim.step()
runing_loss += loss.item()
if batch_idx % 300 == 299:
print('epoch:{},batch_idx:{},loss:{}'.format(epoch,batch_idx+1,runing_loss))
runing_loss = 0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images,labels = data
outputs = model(images)
idx,predict = torch.max(outputs,dim=1)
total += labels.size(0)
correct += (predict == labels).sum().item()
acc = correct/total
print('test acc : {} %'.format(100*acc))
if __name__ == '__main__':
for epoch in range(20):
train(epoch)
test()
部分可视化结果为:

不难看出,在训练了20个epoch之后,最后在测试集上的正确率大概在97-98%。