经典论文-SqueezeNet论文及实践
SqueezeNet: AlexNet-Level Accuracy with 50X Fewer Parameters and *<*0.5MB Model Size
SqueezeNet: AlexNet级别精度50倍较少参数和< 0.5MB模型大小
- 作者:forresti, moskewcz, kashraf, keutzer, songhan, dally
- 单位:UC Berkeley, Stanford University
- 论文地址: https://arxiv.org/abs/1602.07360
- 项目地址:https://github.com/forresti/SqueezeNet
2016年发表
摘要
深层卷积神经网络 (CNNs) 最近的研究主要集中在提高精度。对于给定的精度级别, 通常可以确定多个 CNN 体系结构, 以达到该精度级别。同样的精度, 更小的CNN架构至少具有以下三优点:
- 更小的 CNNs 在分布式训练过程中跨服务器进行更少的通信;
- 更小的 CNNs 需要更少的带宽, 将一个新的模型从云端导出到自动汽车;
- 较小的 CNNs 提供了在 FPGA和其他内存有限的硬件上部署的可行性;
综上, 本文提出了一个小型CNN 架构SqueezeNet,SqueezeNet 在 ImageNet 数据集上能达到 AlexNet 级精度, 但参数减少了50倍。此外, 使用模型压缩技术, 可以将 SqueezeNet 压缩到小于 0.5MB,比AlexNet了小510倍
SqueezeNet 体系结构可在此处下载: https://github.com/DeepScale/SqueezeNet
简介和动机
最近,对卷积神经网络 (CNNs) 的研究主要集中在提高计算机视觉数据集上的精确度。对于给定的精度级别, 通常可以有不同的 CNN 体系结构来实现了该精度级别。而具有更少参数的 CNN 体系结构具有以下几个优点:
-
更高效的分布式训练。服务器之间的通信是分布式 CNN 训练的可扩展性的重要限制因素。对于分布式数据并行训练,通信开销与模型中的参数数目成正比 (Iandola 等, 2016)。简而言之, 小模型由于需要较少的通信量而得以快速地训练。
-
减少将新模型导出到客户端时的开销。对于自动驾驶技术, 特斯拉等公司会定期将新训练的模型从服务器复制到客户的汽车上,该操作通常被称为远程更新。《消费者报告,2016》发现,随着最近的无线自动驾驶系统的更新,特斯拉的半自动驾驶功能的安全性逐渐提高。然而, 现在典型的 CNN/DNN 模型频繁的远程更新会需要大量的数据传输。与 AlexNet相比, 这将需要从云服务器传输240MB的数据量到汽车上。较小的模型只需要传输较少的数据量, 这使得频繁更新变得更加可行。
-
可行的 FPGA 和嵌入式部署。 FPGA通常有小于 10MB的片装内存, 并且不存在外部存储。因此, 一个足够小的模型可以直接存储在FPGA上, 而不是被内存带宽所限制 (QIU等, 2016), 而视频流通过 FPGA 实时。此外, 当在特定于应用程序的集成电路 (ASICs) 上部署 CNNs 时, 足够小的模型可以直接存储在芯片上, 而较小的模型可以部署在适合于较小模型的ASIC上。例如, Xilinx Vertex-7 FPGA 的芯片内存最大为 8.5 mb (即 68 Mbits), 不提供外部存储空间。
如上所述,更小的 CNN 架构具有太多的优点。考虑到这一点, 我们的研究目标聚焦于在准确度不下降的情况下设计一个需要更少参数的CNN网络结构,我们发现这样的一个体系结构, 称为SqueezeNet。此外, 本文提出了一个更具有流程化的方法来搜索新的 CNN 架构的设计空间。
论文的余下部分结构如下。在第2部分中, 回顾相关的工作。然后, 在3和4节中, 介绍评估 SqueezeNet 体系结构。之后, 将注意力转向了解 CNN 对架构设计的选择如何影响模型的大小和准确性。通过探索 SqueezeNet 体系结构的设计空间来获得这种理解。在5节中, 设计了CNN 微体系结构的空间探索, 将其定义为各个层和模块的组织和维度。在6节中, 对CNN 宏观体系结构进行设计空间探索, 将其定义为 CNN 中层次结构的高层次组织。最后, 在7节进行总结。简而言之, 3 和4节对于 CNN 研究人员以及只想将 SqueezeNet 应用于新应用程序的从业者都很有用,其余的部分是针对那些打算设计他们自己的CNN架构的高级研究人员。
2 相关工作
2.1 模型压缩
工作的首要目标是确定一个模型, 它的参数很少, 同时保持精度。为了解决这个问题, 可行的做法是采取现有的 CNN 模型, 并以有损的方式压缩它。事实上, 在一些研究团体已经开始围绕着模型压缩这个思路进行探索,并发表了几种方法。由Denton等人提出的相当简单的方法,是将奇异值分解 (SVD) 应用于预训练CNN模型 (2014)。Han等人发明了一种网络修剪方法,从一个预训练模型开始, 然后用零替换低于某个阈值的参数, 形成一个稀疏矩阵, 最后在稀疏 CNN 上执行一些训练迭代 (han等, 2015b)。最近, han等人通过将网络修剪与量化 (8 比特或更少) 和霍夫曼编码结合在一起, 以创建一种称为深度压缩(Deep Compression)的方法 (Han, 2015a), 并进一步设计了一个名为EIE的硬件加速器,它直接运行在压缩的模型之上, 实现了提高模型运行速度和节省大量运算资源的效果。
2.2 CNN 微体系结构
从LeCun等人在二十世纪八十年代下旬推广CNNs 数字识别应用以来 (LeCun 等, 1989),卷积网络已在人工神经网络中使用了至少25年。在神经网络中, 卷积过滤器通常有3个维度, 以高度、宽度和通道为关键尺寸。当应用到图像时, CNN 过滤器通常在第一层 中有3个通道(即 RGB) , 并且在随后的每一层中,过滤器的通道数与 L i − 1 L_i −1 Li−1 CNN卷积的个数相同。早期的工作 LeCun使用的是5x5xChannels[1] 卷积, VGG (Simonyan & Zisserman, 2014)的体系结构使用3x3卷积模型, 如NIN (Lin等, 2013) 和 GoogLeNet (Szegedy) 在某些层中使用1x1 卷积。
而在CNNs网络结构越来越深的大趋势下, 手动选择每个层的过滤尺寸变得很麻烦。为了解决这一问题, 提出由多个卷积层组成的各种更高级别的构建块或模块。例如, GoogLeNet 文件提出了初始化模块, 它由许多不同的卷积组成, 通常包括1x1 和 3x3, 加上 5x5 (Szegedy et, 2014), 有时也会使用1x3 和 3x1 (Szegedy 等,2015)。然后将许多这样的模块组合起来, 也许还有其他的(ad-hoc)层来组成一个完整的网络。我们使用CNN 微体系结构【CNN microarchitecture】一词来指代单个模块的特定组织和维度。
2.3 CNN 宏观结构
虽然微体系结构是指单个层和模块, 但本文将CNN macroarchitecture定义为多个模块的系统级组织, 使其成为一个端到端的 CNN 架构。
在最近的文献中,广泛研究的 CNN架构的热点是网络深度(即层数)对性能 的影响。Simoyan 和 Zisserman 提出了层数在12到19层的VGG (Simonyan & Zisserman, 2014) 网络, 并在论文中指出, 更深的网络在ImageNet-1k 数据集上获得了更高的准确性 (Den等, 2009)。k. He et. 提出了更深层次的 CNNs ,网络层数多达30层, 同样在ImageNet数据集上也获得了更高的精度 (He等, 2015a)。
跨多个层或模块的连接选择是 CNN macroarchitectural 研究的一个新兴领域。残差网络 (ResNet) (He等, 2015b) 和HighwayNetworks (Srivastava等, 2015)都建议使用跳过多个层的连接, 例如将第3层的激活层连接到第6层的激活层上,将这些连接称为旁路连接。对于一个34层的CNN网络结构,ResNet 的作者提供了有旁路连接和没有旁路连接的比较,添加旁路连接使在ImageNet数据集上的Top-5准确度增加了2个百分点。
2.4 网络设计空间探索
神经网络 (包括深层网络和卷积神经网络) 具有很大的设计空间, 比如说microarchitectures、macroarchitectures的设计和其他超参数的选择。自然而然地, 很多研究机构希望凭借直觉得到关于这些因素如何影响神经网络的准确性 (即设计空间的形状)。神经网络设计空间探索的大部分工作都侧重于开发自动化的方法, 以找到更高精度的神经网络体系结构。这些自动化方法包括贝叶斯优化 (Snoek et, 2012), 模拟退火 (Ludermir 等, 2006), 随机搜索 (Bergstra & Bengio, 2012) 和遗传算法 (Stanley & Miikkulainen, 2002)。值得赞扬的是,每一篇论文都提供了一个案例,在这个案例中,提出的DSE方法产生了一个NN体系结构,与一个具有代表性的基础神经网络相比,它的精确度的确更高。然而, 这些论文并没有试图提供关于神经网络设计空间形状的直觉。在本文的后面, 避开了自动化的方法-相反, 通过重构 CNNs 的方式, 这样就可以做A/B的比较, 从而可以探索出CNN 架构是如何影响模型的大小和准确性的。
在下面的章节中, 首先提出和评估 SqueezeNet 网络结构, 并没有模型压缩。然后, 探讨微体系结构和 宏观体系结构中的设计选择对 SqueezeNet 型 CNN 架构的影响。
3 SQUEEZENET: 使用少量参数保持精度
在本节中, 首先概述了 使用少量参数的CNN 体系结构的设计策略。然后,介绍Fire模块这个新的构建块, 以构建整个CNN网络结构。最后, 使用设计策略来构造SqueezeNet, 它主要由Fire模块组成。
3.1 结构设计策略
本文的首要目标是确定在保持精度的同时, 具有少量参数的CNN架构。为了实现这一点, 在设计 CNN 架构时采用三个主要策略:
-
策略 1. 用 1 x 1 1x1 1x1 卷积核替换 3 x 3 3x3 3x3卷积核。考虑到一定数量的卷积的预算, 将选择大量使用1x1卷积, 因为1x1 卷积的参数比3x3 过滤器少了9倍.
-
策略 2. 减少3x3 卷积输入通道的数量。假设有一个卷积层, 它完全由3x3 卷积组成。此层中参数的总数量为:(输入通道数) * (卷积核数) * (3 * 3)。因此, 为了在 CNN 中得到更少的参数, 不仅要减少3x3 过滤器的数量 (参见上面的策略 1), 还要减少3x3 卷积中输入通道的数量。我们使用squeeze层减少输入通道的数量, 在下一节中将对其进行描述。
-
策略 3. 在网络中延迟下采样的时间, 以便卷积层具有较大的特征图。在卷积网络中, 每个卷积层输出一个特征图,其空间分辨率至少为1x1,通常远远大于1x1。 这些特征图的高度和宽度由以下内容控制: (1) 输入数据的大小 (如256x256 图像) 和 (2)在CNN 体系结构中缩减像素采样的层的选择。最常见的情况是, 下采样通过在某些卷积或池层中设置 ( 步长> 1) (例如 (Szegedy 2014; Simonyan & Zisserman, 2014; Krizhevsky 2012)。如果在网络的前面层就有很大的步长, 那么大多数层将有小的激活映射特征图。 反之, 如果网络中的前边的层都是1的步长, 并且超过1的步长集中在网络的后半部分 , 则网络中的许多层将具有大的激特征图。直觉是, 在其他不变的情况下,大的特征图 (由延迟下采样产生) 可以导致更高的分类精度 。的确, K.He和 h. Sun 对四种不同的CNN架构应用了延迟下采样,在每种情况下,延迟下采样都能获得更高的分类精度(He 2015)。
策略1和2都是关于在尽可能保持模型准确度地情况下减少 CNN 的参数数量,。策略3是关于在有限的参数数量下最大化精度。接下来, 描述的Fire模块, 将使我们能够成功地使用策略1, 2 和3。
3.2 Fire Model
定义Fire模块如下,一个Fire模块包括: 一个squeeze层 (只有1x1 卷积), 将其放入一个具有1x1 和3x3 卷积组合的expand层中(如图1所示)。**在Fire模块中随意使用1x1 卷积核是应用3.1节中的策略1。Fire模块中有三个超参数: s 1 x 1 s_{1x1} s1x1, e 1 x 1 e_{1x1} e1x1和 e 3 x 3 e_{3x3} e3x3。在Fire模块中, s 1 x 1 s_{1x1} s1x1是squeeze层 (所有 1x1) 中的卷积核数, e 1 x 1 e_{1x1} e1x1是1x1 卷积在expand层的数量, e 3 x 3 e_{3x3} e3x3是3x3卷积在expand层的数量。当使用Fire模块时, 设置 s 1 x 1 s_{1x1} s1x1 小于 ( e 1 x 1 + e 3 x 3 e_{1x1}+e_{3x3} e1x1+e3x3 ), 因此, expand层有助于限制3x3卷积中输入通道的数量即3.1节中的策略 2。
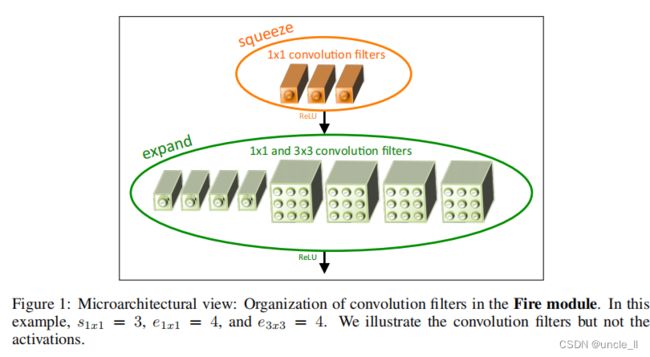
图 1:微观视图: 在Fire模块中组织卷积结构。在这个例子中, s 1 x 1 = 3 s_{1x1}=3 s1x1=3 , e 1 x 1 = 4 e_{1x1}=4 e1x1=4, e 3 x 3 = 4 e_{3x3}=4 e3x3=4。这里只展示卷积, 并没有展示激活层。
3.3 SQUEEZENET 体系结构
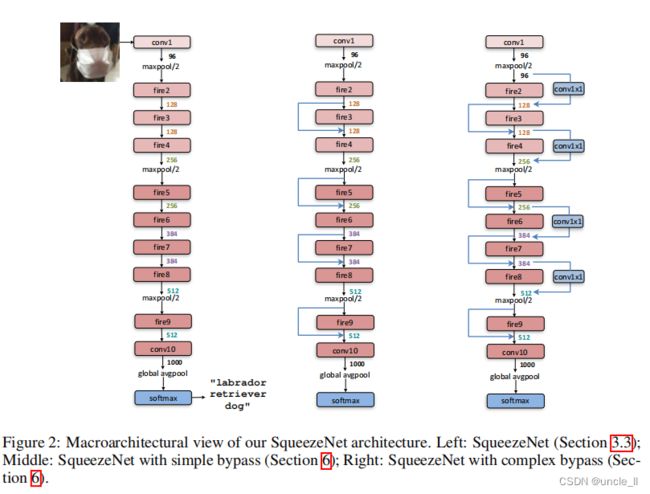
接下来描述 SqueezeNet CNN 的架构。在图2中说明了 SqueezeNet 从一个独立的卷积层 (conv1) 开始, 后跟8个Fire模块 (fire2-9), 最后 conv 层 (conv10) 结束。从开始到网络的末端,逐渐增加每个Fire模块的卷积的数量。
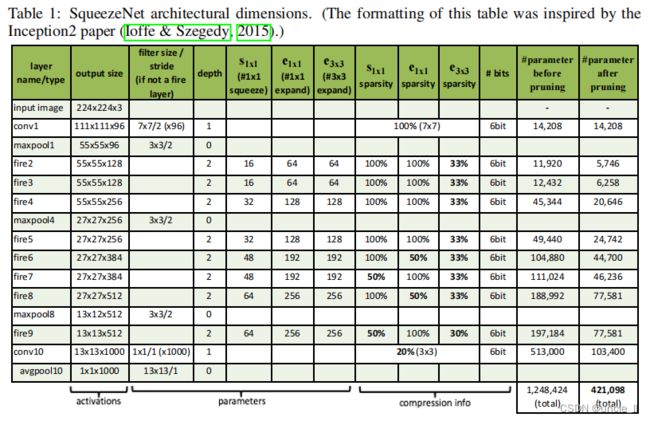
SqueezeNet 在层 conv1、fire4、fire8 和 conv10 之后执行最大池化, 其步长为 2,这些相对较晚地执行池化操作是在执行3.1节的策略3。表1展示了完整的 SqueezeNet 体系结构。
3.3.1 其他SQUEEZENET 细节
为了简洁起见, 省略了表1和图2中有关 SqueezeNet 的详细信息和设计选项的数量。我们提供以下这些设计选择。这些选择背后的灵感可以在下面引用的论文中找到。
- 为了使 1∗1和 3∗3filter输出的结果有相同的尺寸,在expand modules中,给3∗3 filter的原始输入添加一个像素的填充(zero-padding)
- squeeze 和 expand layers中都用ReLU作为激活函数
- 在fire9模块之后,使用Dropout,比例为50%
- 注意到SqueezeNet中没有全连接层,这借鉴了Network in network的思想 ,使用avgpool降低参数量
- 训练过程中,初始学习率设置为0.04,在训练过程中线性降低学习率。更多的细节参见本项目在github中的配置文件。
- 由于Caffee中不支持使用两个不同尺寸的filter,在expand layer中实际上是使用了两个单独的卷积层(1∗1 filter 和 3∗3 filter),最后将这两层的输出连接在一起,这在数值上等价于使用单层但是包含两个不同尺寸的filter。
在github上还有SqueezeNet在其他框架下的实现:
- MXNet
- Chainer
- Keras
- Torch
相关链接在参考文献中给出了github链接
4 评估SQUEEZENET
接下来,对SqueezeNet网络进行一个评估 。在2.1 节中提到的 CNN 模型压缩论文中, 目标是压缩一个 AlexNet 网络, 它是使用 ImageNet (Deng et al.2009) (ILSVRC 2012) 数据集训练后可以对图像进行分类。因此, 在评估 SqueezeNet 时, 使用 AlexNet[4] 和相关的模型压缩结果作为比较的基准。
在表2中, 将最近的模型压缩结果和SqueezeNet网络做一个对比。可以看到:SVD 方法可以将 AlexNet 模型压缩为以前的5倍, 同时会使top-1 数据集上的精度降低到 56.0% (Denton, 2014)。网络修剪实现了模型尺寸的9倍缩小, 同时保持了数据集上57.2%的top-1精度和80.3% top-5的精度 (Han, 2015b)。Deep Compression压缩达到35倍的模型尺寸压缩比率, 同时仍然保持以往的精度 (Han, 2015a)。现在, **使用 SqueezeNet网络, 实现了减少50倍 的模型压缩比率, 同时满足或超过 AlexNet 的 top-1 和 top-5 的准确性。**结果如表2所示:
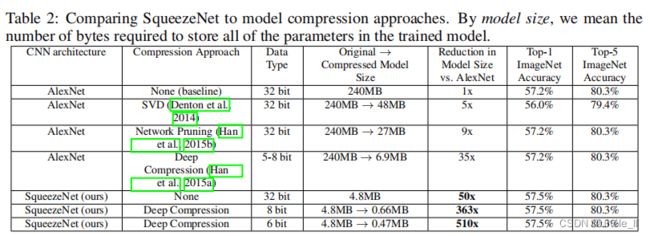
本文实现似乎已经超过了目前模型压缩所取得的最新成果: 即使使用未压缩的32位值来表示模型, SqueezeNet 也在保持或超过原本正确率的基础上有一个1.4倍 的模型压缩比,这相比于目前模型压缩所取得的最新成果还要好一些。直到现在, 一个开放的问题是:是易于压缩的小模型, 还是小模型“需要”密集浮点值所提供的所有表征能力?我们在SqueezeNet上应用了深度压缩 (Han, 2015a) , 使用33%稀疏[5]和8比特量化。这会生成一个 0.66 MB 的模型 (363× 小于32位 AlexNet), 并具有与 AlexNet 等效的精度。此外, 在 SqueezeNet 上应用6比特量化和33% 稀疏度的深度压缩,生成一个0.47MB 模型 (510× 小于32位 AlexNet), 具有等效的精度。我们的小模型确实可以进一步压缩。
此外, 这些结果表明, 深度压缩 (Han, 2015a) 不仅能应用在具有许多参数的CNN体系结构 (如 AlexNet 和 VGG), 而且它也能够压缩已经紧凑的SqueezeNet架构。通过深度压缩压缩SqueezeNet能降低10倍参数数量的同事保留基线精度。总而言之: 通过将 CNN 的体系结构创新 (SqueezeNet) 与最先进的压缩技术 (深度压缩) 结合在一起, 实现了模型大小减小510×的缩减,且与基线相比精确度没有降低。
最后, 请注意, 深度压缩 (Han, 2015b) 使用码书作为其方案的一部分, 将 CNN 参数量化为6或8位精度。因此, 在大多数处理器上, 使用在深度压缩中开发的方案, 以8比特量化或6比特量化的速度加速并不是线性的,比如从32比特到8比特速度并不能提升4倍。 但是Han开发的自定义硬件-有效推理引擎 (EIE) -可以更有效地计算码书量化 CNNs ( 2016a)。此外, 在发布 SqueezeNet 后的几个月中, p Gysel 提出了称为Ristretto的策略, 用于线性量化 SqueezeNet 为8比特 (Gysel, 2016)。具体地说, Ristretto 在8比特中进行计算, 并在8比特数据类型中存储参数和激活。在 SqueezeNet 推理中, 使用8比特计算的 Ristretto 策略, 在使用8比特而不是32位数据类型时, Gysel 观察到精度下降的小于1的百分比。
5 CNN 微体系结构设计空间探索
到目前为止, 已经提出了小模型的结构设计策略, 遵循这些原则来创建 SqueezeNet, 并发现 SqueezeNet 比 AlexNet 少了50倍大小的同时保持了相同的精度。然而,SqueezeNet和其他模型存在于CNN架构的一个广泛且基本上未被探索的设计空间中。在5和6节中, 探讨了设计空间的几个方面。将此体系结构探索分为两个主要主题: microarchitectural 探测(每个模块层的维度和配置) 和macroarchitectural 探测(模块的高级端到端组织和其他层)。
在本节中, 设计并进行实验, 目的是提供关于 microarchitectural 设计空间形状的直觉,在3.1 节中提出的设计策略而言。请注意, 这里的目标不是在每个实验中实现最大的精确度, 而是要了解 CNN 架构选择对模型大小和准确性的影响。
5.1 CNN 微体系结构参数
在 SqueezeNet 中, 每个Fire模块都有三个超参数, 即在3.2 节中定义的: s 1 x 1 s_{1x1} s1x1 , e 1 x 1 e_{1x1} e1x1 和 e 3 x 3 e_{3x3} e3x3 。SqueezeNet 有8个Fire模块, 共24个超参数。为了对 SqueezeNet 体系结构的设计空间进行广泛的遍历, 本文定义了以下一组更高层次的超参数 , 它控制了 CNN 中所有Fire模块的尺寸。
定义 b a s e e base_e basee作为 CNN 中第一个Fire模块中expand层卷积的数目。在之后的每个Fire模块(freq), 通过 i n c r e incr_e incre来增加expand层的数量。换句话说,对于第i层的FIre模块,expand层的卷积数目通过公式: e i = b a s e e + ( i n c r e ∗ i / f r e q ) ei=base_e+(incr_e ∗ i/freq) ei=basee+(incre∗i/freq) 来确定,同时,在每一层的 e i e_i ei,定义 e i = e i , 1 x 1 + e i , 3 x 3 e_i=e_i, 1x1+e_i, 3x3 ei=ei,1x1+ei,3x3的选择上,定义“pct_{3x3}”(相当于3x3在整个expand所占的概率)这个参数,换句话说,$e_{i,3x3}=e_i ∗ pct_{3x3} 和 和 和e_{i,1x1}=e_i ∗ (1− pct_{3x3}) $ 来确定。
最后,对于squeeze层,定义“squeeze ratio(SR)”参数,通过 s i , 1 x 1 = S R ∗ e i s_{i,1x1}=SR ∗ e_i si,1x1=SR∗ei来确定。
比如说,对于表1来说, SqueezeNet 具有以下超参数 (metaparameters): b a s e e = 128 , i n c r e = 128 , p c t 3 x 3 = 0.5 , f r e q = 2 , S R = 0.125 base_e=128, incr_e=128, pct_{3x3}=0.5, freq=2, SR=0.125 basee=128,incre=128,pct3x3=0.5,freq=2,SR=0.125
简单来说,公式的意义如下:
- 第一个模块中的expand层中包含base个卷积;每隔freq个fire模块,增加 i n c r e incr_e incre个卷积
- expand层中,3×3卷积占expand层中卷积比例为pct。
- squeeze层中卷积数与expand层中卷积数比例为SR。
5.2 压缩比(SR)
在3.1 节中, 建议通过使用squeez层减少3x3 卷积的输入通道数减少网络参数的数目。我们将压缩比率 (SR)定义为squeeze层中的卷积个数与expand层中的卷积个数之间的比值。现在设计了实验来研究压缩比对模型尺寸和精确度的影响。
在这些实验中, 使用图2中的SqueezeNet作为起点。与 SqueezeNet 中一样, 这些实验使用以下参数: b a s e e = 128 , i n c r e = 128 , p c t 3 x 3 = 0.5 , f r e q = 2 base_e=128, incr_e=128, pct_{3x3}=0.5, freq=2 basee=128,incre=128,pct3x3=0.5,freq=2。我们训练多个模型, 其中每个模型有一个不同的压缩比 (SR),SR在范围 [0.125, 1.0]内变化。 在图 3 (a) 中, 展示了这个实验的结果,图上的每个点都是一个独立的模型,并且是从头开始训练的。SqueezeNet是 S R = 0.125 SR=0.125 SR=0.125的那个点。 在SR= 0.125时增加SR可以进一步增加 ImageNet top-5 精度(从 80.3% (4.8MB)到86.0% (19MB)) 峰值在86.0% ( SR = 0.75 ,模型大小为19MB ), 并且当 SR=1.0时进一步增加了模型的大小,却没有提高准确性。
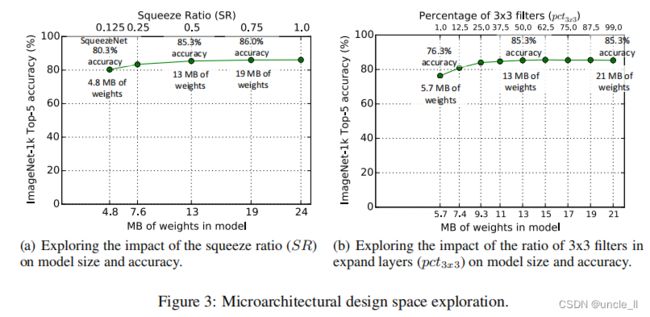
5.3 权衡1X1和3X3大小卷积核
在3.1 节中, 建议通过用1x1 卷积替换一些3x3 卷积来减少 CNN 的参数数目。一个开放的问题是, CNN 过滤器中的空间分辨率有多重要?
VGG (Simonyan & Zisserman 2014) 体系结构在大多卷积层中都使用的尺寸为3x3的卷积;GoogLeNet (Szegedy 2014) 和NIN (Lin 2013)在某些层里存在1x1的卷积。在 GoogLeNet 和NIN, 作者简单地提出了具体数量的1x1 和3x3 卷积没有进一步的分析。本文试图阐明1x1 和3x3 过滤器的比例对模型大小和精度的影响。
在本实验中使用以下参数 b a s e e = 128 base_e=128 basee=128, i n c r e = 128 incr_e=128 incre=128, S R = 0.5 SR=0.5 SR=0.5, f r e q = 2 freq=2 freq=2 , 并且让 p c t 3 x 3 pct_{3x3} pct3x3从1% 到99%变化 。换句话说, 每个Fire模块的expand层有一个预定义的数量的过滤器划分在1x1 和3x3 之间。
在这里,把“旋钮”从 “大多数是1x1卷积” 调节到 “大多数是 3x3卷积”。与以前的实验一样, 这些模型有8个FIre模块, 与图2中的层组织相同。在图 3 (b) 中显示这个实验的结果。注意, 图 3 (a) 和图 3 (b) 中的13MB 模型是相同的体系结构: S R = 0.500 SR = 0.500 SR=0.500 和 p c t 3 x 3 = 50 pct_{3x3}=50% pct3x3=50。在图 3 (b) 中看到, 当3x3 卷积占比为50%时,ImageNet数据集上的top-5精度会达到85.6% , 当进一步增加了3x3 卷积的百分比时,只增加了模型的大小, 但没有提高 ImageNet数据集上的准确性。
6 CNN 宏观体系结构设计空间探索
到目前为止, 已经探索了微体系结构层面的设计空间, 即CNN网络各个模块的内容。现在, 在宏观级别上探讨有关Fire模块之间高层连接的设计决策。灵感来自 ResNet (He 2015b), 探索三种不同的体系结构:
- Vanilla SqueezeNet (按前一节)
- SqueezeNet 在某些Fire模块之间进行简单的旁路连接
- SqueezeNet 在Fire模块之间使用复杂的旁路连接
图2中显示了这三种 SqueezeNet 的变体。
我们的简单旁路体系结构在3、5、7和9Fire模块附近添加旁路连接, 要求这些模块在输入和输出之间学习残差函数。与 ResNet 一样, 要实现围绕 Fire3 的旁路连接, 将输入设置为 Fire4 等于 (Fire2 + 输出 Fire3 的输出), 其中 + 运算符为元素级加法。这改变了应用于这些Fire模块的正则化参数, 并根据 ResNet的性能结果, 这样设计可以提升最终的准确度。
一个限制是, 在简单旁路体系情况下, 输入通道的数量和输出通道的数量必须相同;因此, 只有一半的Fire模块可以有简单的旁路连接, 如图2的中间图所示。当无法满足 “相同数量的通道” 要求时, 使用复杂旁路连接, 如图2的右侧所示。虽然一个简单的旁路是 “只是一个导线”,复杂的旁路作为旁路时, 包括一个1x1 卷积层使得输入数量等于输出通道的数量。需要注意的是, 复杂的旁路连接会向模型中添加额外的参数, 而简单旁路连接则不会。
除了改变正规化, 还可以比较直观地看到: 添加旁路连接将有助于缓解SqueezNet带来的表征瓶颈。例如:在 SqueezeNet中, 挤压比 (SR) 是 0.125, 这意味着每个squeeze层的输出通道比expand层少8倍。由于这种严重的通道数减少, 只有很少的信息可以通过expand层。但是, 通过将旁路连接添加到 SqueezeNet网络中, 打开了信息的通道, 使信息可以在不同的squeeze层之间传输。
按照图2中的三种结构训练 SqueezeNet网络, 并比较了精度和模型大小。结果如表3所示,在整个宏观架构探索过程中,固定微架构以匹配表1所示的SqueezeNet。复杂和简单的旁路连接相比于基础的SqueezeNet结构,准确性得以改善。有趣的是, 简单的旁路实现的准确率的提升比复杂旁路要更高。

7 总结
本文对卷积神经网络的设计空间探索提出了更有规律的方法。针对这个目标, 提出了 SqueezeNet这个 CNN 体系结构, 它的参数比 AlexNet少50×, 并且在 ImageNet 上保持了喝AlexNet 架构一样的准确性。此外还将 SqueezeNet 压缩到小于 0.5MB, 比不进行任何压缩的 AlexNet小510倍。自从在2016年发布这篇论文作为一份技术报告以来, Song han和其合作者对 SqueezeNet 和模型压缩进行了进一步的实验。使用一种新的方法, 称为Dense-Sparse-Dense (DSD) (Han, 2016b)。在训练过程中使用模型压缩作为正则化器以进一步提高精度, 在 ImageNet-1k 上生成一组压缩的 SqueezeNet 参数, 与表2相比,其精度提升了1.2 百分点, 而且还产生一组未压缩的 SqueezeNet 参数,其精度提升了4.3个百分点。
在本文的开头提到, 小模型更适于 fpga 上的芯片实现。自从 SqueezeNet 模型发布后, Gschwend 开发了 SqueezeNet 的变体, 并在 FPGA 上实现了它 (Gschwend, 2016)。正如所预料的那样, Gschwend能够在FPGA中完全存储一个类似于SqueezeNet的模型的参数,并消除了对芯片外的内存访问来加载模型参数的需要。
在本文的背景下, 主要是将 ImageNet 作为目标数据集。然而, 将 ImageNet 训练的 CNN 表示法应用于各种应用, 如细粒度对象识别, 图像标识 (Iandola 2015), 生成关于图像语义 (Fang 2015)等。基于ImageNet训练的CNNs也适用于一些有关自主驾驶的应用, 包括行人和车辆检测 (Iandola等) 以及道路分割 (Badrinarayanan 2015)。我们认为 SqueezeNet 将是CNN 架构的各种应用中一个很好的候选架构, 特别是那些对模型大小有要求时。
SqueezeNet 是我们在广泛探索 CNN 体系结构设计空间时发现的几种新的 CNNs 架构之一。希望 SqueezeNet 能激励读者考虑和探索 CNN 架构设计空间中广泛的可能性, 并以更系统的方式进行探索。
参考
-
Khalid Ashraf, Bichen Wu, Forrest N. Iandola, Matthew W. Moskewicz, and Kurt Keutzer. Shallow networks for high-accuracy road object-detection. arXiv:1606.01561, 2016.
-
Vijay Badrinarayanan, Alex Kendall, and Roberto Cipolla. SegNet: A deep convolutional encoder decoder architecture for image segmentation. arxiv:1511.00561, 2015.
-
Eddie Bell. A implementation of squeezenet in chainer. https://github.com/ejlb/squeezenet-chainer, 2016.
-
J. Bergstra and Y. Bengio. An optimization methodology for neural network weights and architectures. JMLR, 2012.
-
Tianqi Chen, Mu Li, Yutian Li, Min Lin, Naiyan Wang, Minjie Wang, Tianjun Xiao, Bing Xu, Chiyuan Zhang, and Zheng Zhang. Mxnet: A flflexible and effificient machine learning library for heterogeneous distributed systems. arXiv:1512.01274, 2015a.
-
Xiaozhi Chen, Kaustav Kundu, Yukun Zhu, Andrew G Berneshawi, Huimin Ma, Sanja Fidler, and Raquel Urtasun. 3d object proposals for accurate object class detection. In NIPS, 2015b.
-
Sharan Chetlur, Cliff Woolley, Philippe Vandermersch, Jonathan Cohen, John Tran, Bryan Catanzaro, and Evan Shelhamer. cuDNN: effificient primitives for deep learning. arXiv:1410.0759, 2014.
-
Francois Chollet. Keras: Deep learning library for theano and tensorflflow. https://keras.io, 2016.
-
Ronan Collobert, Koray Kavukcuoglu, and Clement Farabet. Torch7: A matlab-like environment for machine learning. In NIPS BigLearn Workshop, 2011.
-
Consumer Reports. Teslas new autopilot: Better but still needs improvement. http://www.consumerreports.org/tesla/tesla-new-autopilot-better-but-needs-improvement, 2016.
-
Dipankar Das, Sasikanth Avancha, Dheevatsa Mudigere, Karthikeyan Vaidyanathan, Srinivas Sridharan, Dhiraj D. Kalamkar, Bharat Kaul, and Pradeep Dubey. Distributed deep learning using synchronous stochastic gradient descent. arXiv:1602.06709, 2016.
-
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. ImageNet: A large-scale hierarchical image database. In CVPR, 2009.
-
E.L Denton, W. Zaremba, J. Bruna, Y. LeCun, and R. Fergus. Exploiting linear structure within convolutional networks for effificient evaluation. In NIPS, 2014.
-
Jeff Donahue, Yangqing Jia, Oriol Vinyals, Judy Hoffman, Ning Zhang, Eric Tzeng, and Trevor Darrell. Decaf: A deep convolutional activation feature for generic visual recognition. arXiv:1310.1531, 2013.
-
DT42. Squeezenet keras implementation. https://github.com/DT42/squeezenet_demo, 2016.
-
Hao Fang, Saurabh Gupta, Forrest Iandola, Rupesh Srivastava, Li Deng, Piotr Dollar, Jianfeng Gao, Xiaodong He, Margaret Mitchell, John C. Platt, C. Lawrence Zitnick, and Geoffrey Zweig. From captions to visual concepts and back. In CVPR, 2015.
-
Ross B. Girshick, Forrest N. Iandola, Trevor Darrell, and Jitendra Malik. Deformable part models are convolutional neural networks. In CVPR, 2015.
-
David Gschwend. Zynqnet: An fpga-accelerated embedded convolutional neural network. Master’s thesis, Swiss Federal Institute of Technology Zurich (ETH-Zurich), 2016.
-
Philipp Gysel. Ristretto: Hardware-oriented approximation of convolutional neural networks. arXiv:1605.06402, 2016.
-
S. Han, H. Mao, and W. Dally. Deep compression: Compressing DNNs with pruning, trained quantization and huffman coding. arxiv:1510.00149v3, 2015a.
-
S. Han, J. Pool, J. Tran, and W. Dally. Learning both weights and connections for effificient neural networks. In NIPS, 2015b.
-
Song Han, Xingyu Liu, Huizi Mao, Jing Pu, Ardavan Pedram, Mark A Horowitz, and William J Dally. Eie: Effificient inference engine on compressed deep neural network. International Symposium on Computer Architecture (ISCA), 2016a.
-
Song Han, Jeff Pool, Sharan Narang, Huizi Mao, Shijian Tang, Erich Elsen, Bryan Catanzaro, John Tran, and William J. Dally. Dsd: Regularizing deep neural networks with dense-sparse-dense training flflow. arXiv:1607.04381, 2016b.
-
Guo Haria. convert squeezenet to mxnet. https://github.com/haria/SqueezeNet/commit/0cf57539375fd5429275af36fc94c774503427c3, 2016.
-
K. He, X. Zhang, S. Ren, and J. Sun. Delving deep into rectififiers: Surpassing human-level performance on imagenet classifification. In ICCV, 2015a.
-
Kaiming He and Jian Sun. Convolutional neural networks at constrained time cost. In CVPR, 2015.
-
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. arXiv:1512.03385, 2015b.
-
Forrest N. Iandola, Matthew W. Moskewicz, Sergey Karayev, Ross B. Girshick, Trevor Darrell, and Kurt Keutzer. Densenet: Implementing effificient convnet descriptor pyramids. arXiv:1404.1869, 2014.
-
Forrest N. Iandola, Anting Shen, Peter Gao, and Kurt Keutzer. DeepLogo: Hitting logo recognition with the deep neural network hammer. arXiv:1510.02131, 2015.
-
Forrest N. Iandola, Khalid Ashraf, Matthew W. Moskewicz, and Kurt Keutzer. FireCaffe: near-linear acceleration of deep neural network training on compute clusters. In CVPR, 2016.
-
Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. JMLR, 2015.
-
Yangqing Jia, Evan Shelhamer, Jeff Donahue, Sergey Karayev, Jonathan Long, Ross Girshick, Sergio Guadarrama, and Trevor Darrell. Caffe: Convolutional architecture for fast feature embedding. arXiv:1408.5093, 2014.
-
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. ImageNet Classifification with Deep Convolutional Neural Networks. In NIPS, 2012.
-
Y. LeCun, B.Boser, J.S. Denker, D. Henderson, R.E. Howard, W. Hubbard, and L.D. Jackel. Backpropagation applied to handwritten zip code recognition. Neural Computation, 1989.
-
Min Lin, Qiang Chen, and Shuicheng Yan. Network in network. arXiv:1312.4400, 2013.
-
T.B. Ludermir, A. Yamazaki, and C. Zanchettin. An optimization methodology for neural network weights and architectures. IEEE Trans. Neural Networks, 2006.
-
Dmytro Mishkin, Nikolay Sergievskiy, and Jiri Matas. Systematic evaluation of cnn advances on the imagenet. arXiv:1606.02228, 2016.
-
Vinod Nair and Geoffrey E. Hinton. Rectifified linear units improve restricted boltzmann machines. In ICML, 2010.
-
Jiantao Qiu, Jie Wang, Song Yao, Kaiyuan Guo, Boxun Li, Erjin Zhou, Jincheng Yu, Tianqi Tang,
-
Ningyi Xu, Sen Song, Yu Wang, and Huazhong Yang. Going deeper with embedded fpga platform for convolutional neural network. In ACM International Symposium on FPGA, 2016.
-
Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv:1409.1556, 2014.
-
J. Snoek, H. Larochelle, and R.P. Adams. Practical bayesian optimization of machine learning algorithms. In NIPS, 2012.
-
Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: a simple way to prevent neural networks from overfifitting. JMLR, 2014.
-
R. K. Srivastava, K. Greff, and J. Schmidhuber. Highway networks. In ICML Deep Learning Workshop, 2015.
-
K.O. Stanley and R. Miikkulainen. Evolving neural networks through augmenting topologies. Neurocomputing, 2002.
-
Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. arXiv:1409.4842, 2014.
-
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. arXiv:1512.00567, 2015.
-
Christian Szegedy, Sergey Ioffe, and Vincent Vanhoucke. Inception-v4, inception-resnet and the impact of residual connections on learning. arXiv:1602.07261, 2016.
-
S. Tokui, K. Oono, S. Hido, and J. Clayton. Chainer: a next-generation open source framework for deep learning. In NIPS Workshop on Machine Learning Systems (LearningSys), 2015.
-
Sagar M Waghmare. FireModule.lua. https://github.com/Element-Research/dpnn/blob/master/FireModule.lua, 2016.
-
Ning Zhang, Ryan Farrell, Forrest Iandola, and Trevor Darrell. Deformable part descriptors for fifine-grained recognition and attribute prediction. In ICCV, 2013.
实现
基于torch1.8版本实现
import os
import sys
import numpy as np
import pandas as pd
from typing import Any
from matplotlib import pyplot as plt
import torch
import torch.nn as nn
import torch.nn.init as init
import torch.nn.functional as f
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
try:
from torch.hub import load_state_dict_from_url
except ImportError:
from torch.utils.model_zoo import load_url as load_state_dict_from_url
# 设置gpu参数
os.environ['CUDA_VISIABLE_DIVICES'] = '0'
# 设置网络超参数
batch_size = 256
num_works = 4
lr = 1e-4
epochs = 100
# 加载数据
from torchvision import datasets
train_data = datasets.CIFAR10(root='./', train=True, download=True, transform=data_transform)
test_data = datasets.CIFAR10(root='./', train=False, download=True, transform=data_transform)
# 准备数据
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True, num_workers=num_works, drop_last=True)
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False, num_workers=num_works)
# 预训练权重url
model_urls = {
"squeezenet1_0": "https://download.pytorch.org/models/squeezenet1_0-b66bff10.pth",
"squeezenet1_1": "https://download.pytorch.org/models/squeezenet1_1-b8a52dc0.pth",
}
# 构建Fire模块
class Fire(nn.Module):
def __init__(self, inplanes: int, squeeze_planes: int, expand1x1_planes: int, expand3x3_planes: int) -> None:
super().__init__()
self.inplanes = inplanes
self.squeeze = nn.Conv2d(inplanes, squeeze_planes, kernel_size=1)
self.squeeze_activation = nn.ReLU(inplace=True)
self.squeeze_batchnorm = nn.BatchNorm2d(inplace=True)
self.expand1x1 = nn.Conv2d(squeeze_planes, expand1x1_planes, kernel_size=1)
self.expand1x1_activation = nn.ReLU(inplace=True)
self.expand1x1_batchnorm = nn.BatchNorm2d(inplace=True)
self.expand3x3 = nn.Conv2d(squeeze_planes, expand3x3_planes, kernel_size=3, padding=1)
self.expand3x3_activation = nn.ReLU(inplace=True)
self.expand3x3_batchnorm = nn.BatchNorm2d(inplace=True)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.squeeze_activation(self.squeeze(x))
x = self.squeeze_batchnorm(x)
return torch.cat(
[
self.expand1x1_batchnorm(self.expand1x1_activation(self.expand1x1(x))),
self.expand3x3_batchnorm(self.expand3x3_activation(self.expand3x3(x)))], 1
)
# 基于Fire模块构建网络
class SqueezeNet(nn.Module):
def __init__(self, version: str = "1_0", num_classes: int = 1000, dropout: float = 0.5) -> None:
super().__init__()
self.num_classes = num_classes
self.num_classes = num_classes
if version == "1_0":
self.features = nn.Sequential(
nn.Conv2d(3, 96, kernel_size=7, stride=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(96, 16, 64, 64),
Fire(128, 16, 64, 64),
Fire(128, 32, 128, 128),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(256, 32, 128, 128),
Fire(256, 48, 192, 192),
Fire(384, 48, 192, 192),
Fire(384, 64, 256, 256),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(512, 64, 256, 256),
)
elif version == "1_1":
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(64, 16, 64, 64),
Fire(128, 16, 64, 64),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(128, 32, 128, 128),
Fire(256, 32, 128, 128),
nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True),
Fire(256, 48, 192, 192),
Fire(384, 48, 192, 192),
Fire(384, 64, 256, 256),
Fire(512, 64, 256, 256),
)
else:
raise ValueError("only support version 1_0 and 1_1")
final_conv = nn.Conv2d(512, self.num_classes, kernel_size=1)
self.classifier = nn.Sequential(
nn.Dropout(p=dropout),
final_conv,
nn.ReLU(inplace=True),
nn.AdaptiveAvgPool2d((1, 1))
)
for m in self.modules():
if isinstance(m, nn.Conv2d):
if m is final_conv:
init.normal_(m.weight, mean=0.0, std=0.01)
else:
init.kaiming_uniform_(m.weight)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.features(x)
x = self.classifier(x)
return torch.flatten(x, 1)
def _squeezenet(version: str, pretrained: bool, progress: bool, **kwargs: Any) -> SqueezeNet:
model = SqueezeNet(version, **kwargs)
if pretrained:
arch = "squeezenet" + version
state_dict = load_state_dict_from_url(model_urls[arch], progress=progress)
model.load_state_dict(state_dict)
return model
def squeezenet1_0(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> SqueezeNet:
return _squeezenet("1_0", pretrained, progress, **kwargs)
def squeezenet1_1(pretrained: bool = False, progress: bool = True, **kwargs: Any):
return _squeezenet("1_1", pretrained, progress, **kwargs)
# 模型初始化
model = squeezenet1_0(pretrained=True).cuda()
# 定义优化器和损失函数
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=lr)
# 记录
from torch.utils.tensorboard import SummaryWriter
writer1 = SummaryWriter('./runs2/loss')
writer2 = SummaryWriter('./runs2/acc')
# train和test过程
def train(epoch):
model.train()
train_loss = 0
for data, label in train_loader:
data, label = data.cuda(), label.cuda()
optimizer.zero_grad()
output = model(data)
loss = criterion(output, label)
loss.backward()
optimizer.step()
train_loss += loss.item() * data.size(0)
train_loss = train_loss / len(train_loader.dataset)
writer1.add_scalar('loss', train_loss, epoch)
print('Epoch: {} \tTraining Loss: {:.6f}'.format(epoch, train_loss))
def val(epoch):
# 设置评估状态
model.eval()
val_loss = 0
gt_labels = []
pred_labels = []
# 不设置梯度
with torch.no_grad():
for data, label in test_loader:
data, label = data.cuda(), label.cuda()
output = model(data)
preds = torch.argmax(output, 1)
gt_labels.append(label.cpu().data.numpy())
pred_labels.append(preds.cpu().data.numpy())
loss = criterion(output, label)
val_loss += loss.item()*data.size(0)
# 计算验证集的平均损失
val_loss = val_loss /len(test_loader.dataset)
writer1.add_scalar('loss', val_loss, epoch)
gt_labels, pred_labels = np.concatenate(gt_labels), np.concatenate(pred_labels)
# 计算准确率
acc = np.sum(gt_labels ==pred_labels)/len(pred_labels)
writer2.add_scalar('acc', acc, epoch)
print('Epoch: {} \tValidation Loss: {:.6f}, Accuracy: {:6f}'.format(epoch, val_loss, acc))
for epoch in range(1, epochs+1):
train(epoch)
val(epoch)
Epoch: 1 Training Loss: 1.161134
Epoch: 1 Validation Loss: 0.749824, Accuracy: 0.738900
Epoch: 2 Training Loss: 0.671054
Epoch: 2 Validation Loss: 0.608158, Accuracy: 0.795100
Epoch: 3 Training Loss: 0.548897
Epoch: 3 Validation Loss: 0.549548, Accuracy: 0.806000
Epoch: 4 Training Loss: 0.479198
Epoch: 4 Validation Loss: 0.507152, Accuracy: 0.827200
Epoch: 5 Training Loss: 0.430396
Epoch: 5 Validation Loss: 0.447047, Accuracy: 0.846700
Epoch: 6 Training Loss: 0.397328
Epoch: 6 Validation Loss: 0.430231, Accuracy: 0.852000
Epoch: 7 Training Loss: 0.369203
Epoch: 7 Validation Loss: 0.425394, Accuracy: 0.858600
Epoch: 8 Training Loss: 0.339981
Epoch: 8 Validation Loss: 0.446232, Accuracy: 0.850700
Epoch: 9 Training Loss: 0.315831
Epoch: 9 Validation Loss: 0.364299, Accuracy: 0.878600
Epoch: 10 Training Loss: 0.296542
Epoch: 10 Validation Loss: 0.354051, Accuracy: 0.879600
Epoch: 11 Training Loss: 0.279609
Epoch: 11 Validation Loss: 0.363835, Accuracy: 0.877100
Epoch: 12 Training Loss: 0.256978
Epoch: 12 Validation Loss: 0.372945, Accuracy: 0.875800
Epoch: 13 Training Loss: 0.238706
Epoch: 13 Validation Loss: 0.363534, Accuracy: 0.876000
Epoch: 14 Training Loss: 0.224254
Epoch: 14 Validation Loss: 0.401957, Accuracy: 0.872600
Epoch: 15 Training Loss: 0.211692
Epoch: 15 Validation Loss: 0.351218, Accuracy: 0.883800
Epoch: 16 Training Loss: 0.199347
Epoch: 16 Validation Loss: 0.378564, Accuracy: 0.881000
Epoch: 17 Training Loss: 0.184383
Epoch: 17 Validation Loss: 0.350295, Accuracy: 0.884400
Epoch: 18 Training Loss: 0.176478
Epoch: 18 Validation Loss: 0.363976, Accuracy: 0.887400
Epoch: 19 Training Loss: 0.161847
Epoch: 19 Validation Loss: 0.344011, Accuracy: 0.894400
Epoch: 20 Training Loss: 0.155745
Epoch: 20 Validation Loss: 0.346770, Accuracy: 0.888800
Epoch: 21 Training Loss: 0.144164
Epoch: 21 Validation Loss: 0.359279, Accuracy: 0.894100
Epoch: 22 Training Loss: 0.133399
Epoch: 22 Validation Loss: 0.354882, Accuracy: 0.894800
Epoch: 23 Training Loss: 0.129936
Epoch: 23 Validation Loss: 0.355741, Accuracy: 0.897400
Epoch: 24 Training Loss: 0.122892
Epoch: 24 Validation Loss: 0.388160, Accuracy: 0.888700
Epoch: 25 Training Loss: 0.110687
Epoch: 25 Validation Loss: 0.384494, Accuracy: 0.897300
Epoch: 26 Training Loss: 0.103126
Epoch: 26 Validation Loss: 0.376639, Accuracy: 0.886900
Epoch: 27 Training Loss: 0.096192
Epoch: 27 Validation Loss: 0.388155, Accuracy: 0.894100
Epoch: 28 Training Loss: 0.088122
Epoch: 28 Validation Loss: 0.374544, Accuracy: 0.898500
Epoch: 29 Training Loss: 0.090174
Epoch: 29 Validation Loss: 0.377643, Accuracy: 0.900300
Epoch: 30 Training Loss: 0.087488
Epoch: 30 Validation Loss: 0.387690, Accuracy: 0.895400
Epoch: 31 Training Loss: 0.077169
Epoch: 31 Validation Loss: 0.436552, Accuracy: 0.891900
Epoch: 32 Training Loss: 0.073913
Epoch: 32 Validation Loss: 0.417887, Accuracy: 0.895100
Epoch: 33 Training Loss: 0.073250
Epoch: 33 Validation Loss: 0.388603, Accuracy: 0.897000
Epoch: 34 Training Loss: 0.067034
Epoch: 34 Validation Loss: 0.389121, Accuracy: 0.897600
Epoch: 35 Training Loss: 0.066294
Epoch: 35 Validation Loss: 0.429104, Accuracy: 0.892100
Epoch: 36 Training Loss: 0.063878
Epoch: 36 Validation Loss: 0.447214, Accuracy: 0.894000
Epoch: 37 Training Loss: 0.054987
Epoch: 37 Validation Loss: 0.394924, Accuracy: 0.907000
Epoch: 38 Training Loss: 0.060007
Epoch: 38 Validation Loss: 0.406081, Accuracy: 0.895300
Epoch: 39 Training Loss: 0.051146
Epoch: 39 Validation Loss: 0.399729, Accuracy: 0.904700
Epoch: 40 Training Loss: 0.050248
Epoch: 40 Validation Loss: 0.459519, Accuracy: 0.893500
Epoch: 41 Training Loss: 0.056315
Epoch: 41 Validation Loss: 0.454875, Accuracy: 0.887600
Epoch: 42 Training Loss: 0.048497
Epoch: 42 Validation Loss: 0.509809, Accuracy: 0.888900
Epoch: 43 Training Loss: 0.048645
Epoch: 43 Validation Loss: 0.474307, Accuracy: 0.891000
Epoch: 44 Training Loss: 0.047940
Epoch: 44 Validation Loss: 0.488021, Accuracy: 0.898100
Epoch: 45 Training Loss: 0.042938
Epoch: 45 Validation Loss: 0.649888, Accuracy: 0.867500
Epoch: 46 Training Loss: 0.045620
Epoch: 46 Validation Loss: 0.505981, Accuracy: 0.888300
Epoch: 47 Training Loss: 0.040662
Epoch: 47 Validation Loss: 0.480871, Accuracy: 0.901400
Epoch: 48 Training Loss: 0.044712
Epoch: 48 Validation Loss: 0.435486, Accuracy: 0.903000
Epoch: 49 Training Loss: 0.040752
Epoch: 49 Validation Loss: 0.475266, Accuracy: 0.899700
Epoch: 50 Training Loss: 0.040597
Epoch: 50 Validation Loss: 0.468685, Accuracy: 0.901000
Epoch: 51 Training Loss: 0.032867
Epoch: 51 Validation Loss: 0.513628, Accuracy: 0.897100
Epoch: 52 Training Loss: 0.041446
Epoch: 52 Validation Loss: 0.433756, Accuracy: 0.898400
Epoch: 53 Training Loss: 0.041009
Epoch: 53 Validation Loss: 0.537028, Accuracy: 0.890100
Epoch: 54 Training Loss: 0.033371
Epoch: 54 Validation Loss: 0.462082, Accuracy: 0.902200
Epoch: 55 Training Loss: 0.038816
Epoch: 55 Validation Loss: 0.453074, Accuracy: 0.901400
Epoch: 56 Training Loss: 0.033128
Epoch: 56 Validation Loss: 0.497164, Accuracy: 0.899800
Epoch: 57 Training Loss: 0.039958
Epoch: 57 Validation Loss: 0.468227, Accuracy: 0.904200
Epoch: 58 Training Loss: 0.031927
Epoch: 58 Validation Loss: 0.495695, Accuracy: 0.896000
Epoch: 59 Training Loss: 0.033641
Epoch: 59 Validation Loss: 0.494528, Accuracy: 0.904600
Epoch: 60 Training Loss: 0.034346
Epoch: 60 Validation Loss: 0.468210, Accuracy: 0.904700
Epoch: 61 Training Loss: 0.029915
Epoch: 61 Validation Loss: 0.472975, Accuracy: 0.900600
Epoch: 62 Training Loss: 0.031851
Epoch: 62 Validation Loss: 0.524032, Accuracy: 0.900900
Epoch: 63 Training Loss: 0.033108
Epoch: 63 Validation Loss: 0.516820, Accuracy: 0.897500
Epoch: 64 Training Loss: 0.026359
Epoch: 64 Validation Loss: 0.480447, Accuracy: 0.905200
Epoch: 65 Training Loss: 0.031961
Epoch: 65 Validation Loss: 0.453561, Accuracy: 0.901500
Epoch: 66 Training Loss: 0.030446
Epoch: 66 Validation Loss: 0.527716, Accuracy: 0.899100
Epoch: 67 Training Loss: 0.028483
Epoch: 67 Validation Loss: 0.566404, Accuracy: 0.900700
Epoch: 68 Training Loss: 0.024495
Epoch: 68 Validation Loss: 0.517107, Accuracy: 0.894000
Epoch: 69 Training Loss: 0.033177
Epoch: 69 Validation Loss: 0.574917, Accuracy: 0.883800
Epoch: 70 Training Loss: 0.024088
Epoch: 70 Validation Loss: 0.497522, Accuracy: 0.902100
Epoch: 71 Training Loss: 0.030507
Epoch: 71 Validation Loss: 0.472474, Accuracy: 0.903400
Epoch: 72 Training Loss: 0.026772
Epoch: 72 Validation Loss: 0.538870, Accuracy: 0.892700
Epoch: 73 Training Loss: 0.022593
Epoch: 73 Validation Loss: 0.604523, Accuracy: 0.891900
Epoch: 74 Training Loss: 0.029629
Epoch: 74 Validation Loss: 0.497383, Accuracy: 0.902700
Epoch: 75 Training Loss: 0.018863
Epoch: 75 Validation Loss: 0.606116, Accuracy: 0.885000
Epoch: 76 Training Loss: 0.026518
Epoch: 76 Validation Loss: 0.497624, Accuracy: 0.902300
Epoch: 77 Training Loss: 0.023771
Epoch: 77 Validation Loss: 0.534106, Accuracy: 0.889400
Epoch: 78 Training Loss: 0.028059
Epoch: 78 Validation Loss: 0.530059, Accuracy: 0.898700
Epoch: 79 Training Loss: 0.023232
Epoch: 79 Validation Loss: 0.541592, Accuracy: 0.902600
Epoch: 80 Training Loss: 0.020749
Epoch: 80 Validation Loss: 0.528183, Accuracy: 0.906900
Epoch: 81 Training Loss: 0.027914
Epoch: 81 Validation Loss: 0.578075, Accuracy: 0.889800
Epoch: 82 Training Loss: 0.025096
Epoch: 82 Validation Loss: 0.642615, Accuracy: 0.896900
Epoch: 83 Training Loss: 0.024546
Epoch: 83 Validation Loss: 0.649724, Accuracy: 0.889600
Epoch: 84 Training Loss: 0.019140
Epoch: 84 Validation Loss: 0.529400, Accuracy: 0.902100
Epoch: 85 Training Loss: 0.024258
Epoch: 85 Validation Loss: 0.528399, Accuracy: 0.902500
Epoch: 86 Training Loss: 0.021393
Epoch: 86 Validation Loss: 0.547843, Accuracy: 0.901900
Epoch: 87 Training Loss: 0.022089
Epoch: 87 Validation Loss: 0.624171, Accuracy: 0.894200
Epoch: 88 Training Loss: 0.020587
Epoch: 88 Validation Loss: 0.567714, Accuracy: 0.897000
Epoch: 89 Training Loss: 0.024483
Epoch: 89 Validation Loss: 0.541198, Accuracy: 0.904100
Epoch: 90 Training Loss: 0.019882
Epoch: 90 Validation Loss: 0.714706, Accuracy: 0.879500
Epoch: 91 Training Loss: 0.024250
Epoch: 91 Validation Loss: 0.582254, Accuracy: 0.889400
Epoch: 92 Training Loss: 0.019551
Epoch: 92 Validation Loss: 0.569664, Accuracy: 0.900000
Epoch: 93 Training Loss: 0.020316
Epoch: 93 Validation Loss: 0.647165, Accuracy: 0.892900
Epoch: 94 Training Loss: 0.021071
Epoch: 94 Validation Loss: 0.523258, Accuracy: 0.898800
Epoch: 95 Training Loss: 0.022082
Epoch: 95 Validation Loss: 0.558140, Accuracy: 0.897400
Epoch: 96 Training Loss: 0.019449
Epoch: 96 Validation Loss: 0.529868, Accuracy: 0.907800
Epoch: 97 Training Loss: 0.022261
Epoch: 97 Validation Loss: 0.548686, Accuracy: 0.904700
Epoch: 98 Training Loss: 0.020398
Epoch: 98 Validation Loss: 0.562130, Accuracy: 0.895400
Epoch: 99 Training Loss: 0.019121
Epoch: 99 Validation Loss: 0.581560, Accuracy: 0.895300
Epoch: 100 Training Loss: 0.021838
Epoch: 100 Validation Loss: 0.586652, Accuracy: 0.902600
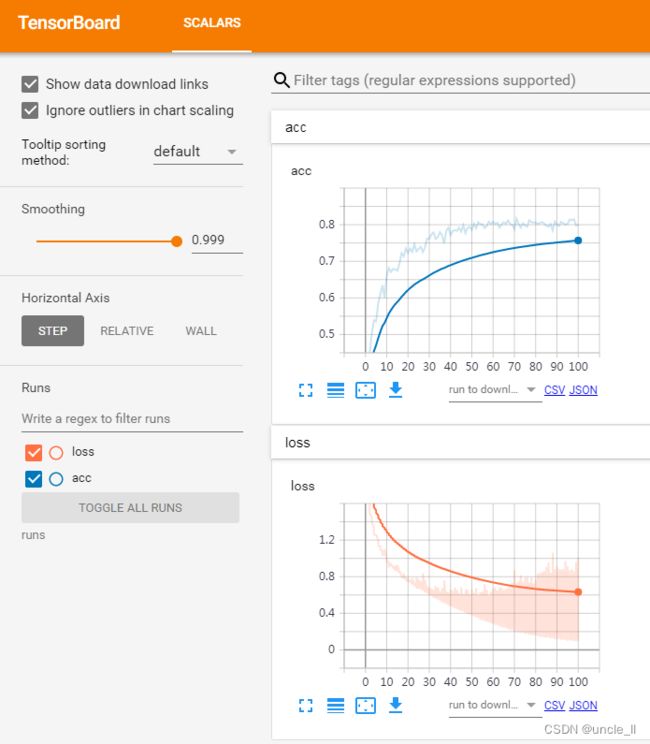
- 不使用预训练权重
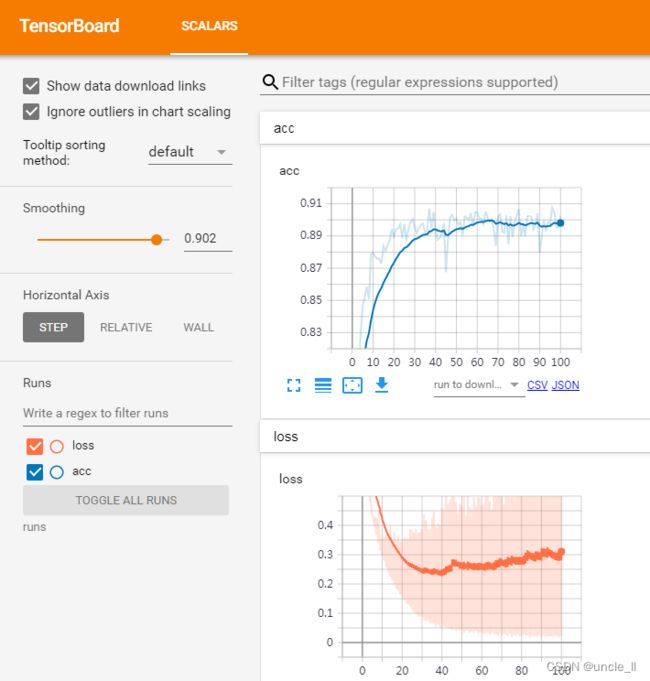
- 使用预训练权重后,效果要好一点,但有点出现过拟合现象,可以增大batchsize,以及加入bn等操作
参考
- https://zhuanlan.zhihu.com/p/49465950
- https://pytorch.org/vision/0.12/_modules/torchvision/models/squeezenet.html